
We owe a lot to Ralph Kimball and friends. His practical warehouse design and conformed-dimension bus architecture are the industry standard. Business users can understand and query these warehouses directly and gain valuable insights into the business. Kimball’s practical approach focuses squarely on clarity and ease of use for the business users of the warehouse. Kudos to you and yours, Mr. Kimball.
That said, can the mainstay Type 2 slowly changing dimension be improved? I here present the concept of historical dimensions as a way to solve some issues with the basic Type 2 slowly changing dimension promoted by Kimball. As we will see, clearly distinguishing between current and past dimension values pays off in clarity of design, flexibility of presentation, and ease of ETL maintenance.
Warehouse facts are inherently historical since transactions happen on a transaction date, balances are kept on a balance date, and so on. The values of Dimensions are either static (date and time, limited code sets) or change slowly. Not every dimension change needs to be recorded as history, but many do. When dimensions change, how should it be handled?
Kimball’s general answer is to choose between the standard slowly changing dimension (SCD) Types 1, 2, and 3. For each column in the dimension table, a determination should be made to 1) overwrite the old value, 2) insert a new row in the dimension with a new dimension key to record the new value, preserving the old, or 3) copy the old value to a previous value column in the row.
SCD Type 1 is a simple overwrite, and SCD Type 3 is somewhat special-purpose and limited. The workhorse of dimension history is, therefore, SCD Type 2. It is made possible by the use of a surrogate key on the dimension rather than the natural key. Historical fact rows are linked through the surrogate key to the version of the dimension row that was current when the fact was recorded. Usually, dimensions containing Type 2 history have effective and expiration dates, as well as a current indicator, which must be maintained as Type 2 SCD rows are inserted.
Limitations of Type 2 SCD
Type 2 SCD is usually presented as one of several choices as to how history is stored – a somewhat technical distinction that can be hidden from the business users. A designer might get the sense that he could present the first version of the warehouse using SCD Type 1 overwrites and add Type 2 SCD history in a later version. Since no structural changes are required, it should be able to drop right in, but this is not the case.
Storing Type 2 history in a dimension table fundamentally changes what that dimension contains. That leads directly to user confusion and incorrect results.
Consider how we treat fact tables. Kimball makes a strong point that one must declare the grain of the fact table, stating precisely what a fact table record represents. He writes that the most common error he sees is to not declare the grain at the beginning of the design process. Further, while the grain may be equivalent to the primary key of the fact table, the grain is properly declared in business terms first. Once the business definition is clear, the dimensional keys used in the fact become obvious.
Should we not treat dimension tables in a similar fashion? We must know exactly what a row in a dimension table represents, in business terms. While the primary key will always be the surrogate key of the dimension, both designers and users should be clear about what each row in the dimension table represents.
For example, what does each row in a Dim_Customer table represent? If SCD Type 1 overwrites are in place, we can say that it represents the latest information for each customer. If SCD Type 2 inserts are in place, the row now represents customer information at a certain point in time. Therefore, a business user must be fully aware of the history technique before he can understand what he is looking at in that dimension.
We can imagine the business user who is attempting to answer the question, “How many different customers have we had?” A simple
|
1 |
SELECT COUNT(*) FROM Dim_Customer |
provides that answer for an SCD Type 1 table, but one would need to use
|
1 |
SELECT COUNT(DISTINCT Customer_Id) FROM Dim_Customer |
(assuming Customer_Id is a natural key of the customer from the operational system) or
|
1 |
SELECT COUNT(*) FROM Dim_Customer WHERE Current_Indicator = ‘Y’ |
to answer that simple question in an SCD Type 2 table.
SCD Type 2 introduces complications because it is trying to be both the current view and the historical view at the same time. It is like an actor on a stage who is trying to play two characters in the same scene. The audience is confused, and so is the actor.
Let’s examine another limitation of SCD Type 2. What happens if we wish to use current dimension values when examining historical facts? For example, we may wish to send emails to all customers who bought certain products in the previous quarter. We use the fact table to obtain the list of distinct Customer_Keys, but those keys refer to potentially historical records in the Type 2 Dim_Customer table. We cannot simply pull the email address from the dimension matching that key, because the customer may well have updated their email address since the last transaction we have recorded. In this case, we don’t want historical customer values; we want current customer values. Going back into the dimension to retrieve the current rows requires some tricky SQL that is likely beyond our business users.
One more irritation of SCD Type 2 arises with accumulating snapshot fact tables. This kind of fact table tracks statistics of a dimensional entity (e.g. a customer) as it changes over time. When our dimension is using SCD Type 2, there are several dimension keys that point to the same dimensional entity. We must ensure that we update the accumulating snapshot’s dimension key with the latest SCD Type 2 dimension key to avoid double-counting the rows.
Historical Dimensions Add Clarity
There’s nothing wrong with the basic SCD Type 2 technique of inserting new rows with a new surrogate key. The problems stem from having our only copy of current values mixed in with the historical values in the same table. So to clarify our design and solve the limitations of SCD Type 2 dimensions, we simply keep a copy of the current values separate from the historical and clearly label the two.
To that end, we make the following definitions:
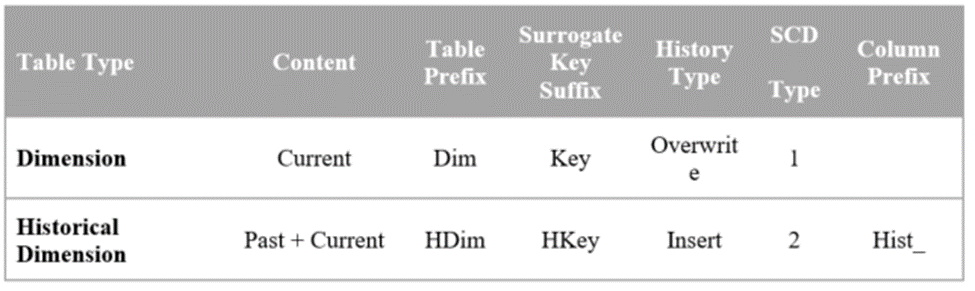
Now, each Dimension that supports history will do so with a Historical Dimension table. The Historical Dimension is distinguished from the Dimension through a different table prefix (or suffix if that is your naming convention). Further, we make the logical distinction that a Key is used to link to a Dimension table, while an HKey is used to link to a Historical Dimension. This allows both a Key and an HKey to exist in the same fact table. One may prefer HistKey over HKey and HistDim rather than HDim; the important point is that the names unambiguously distinguish the two types of tables.
Dimensions are always maintained with overwrite logic, while Historical Dimensions track historical changes through SCD Type 2 inserts. Exactly how this is done is explained shortly.
Historical Dimensions contain every column found in the Dimension table, plus a few more (see Figure 1). Most importantly, they have their own surrogate primary key with a suffix of HKey. We also add an effective date and expiration date as well as the current indicator. The Historical Dimension keeps a complete set of current data (those rows have the current indicator set true), so it is a superset of the Dimension both in its structure and in its content. We may choose to prefix the Dimension attributes in the Historical Dimension with Hist_, to distinguish them from the current value columns in the Dimension table.
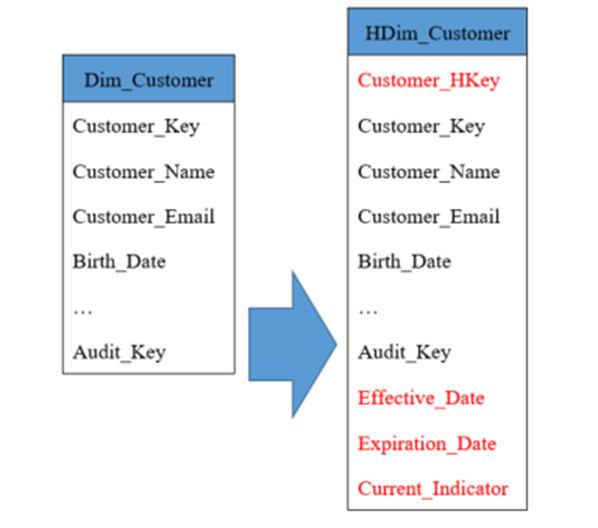
Figure 1: Historical Dimensions contain all the columns of the Dimension, including its key.
Does keeping the current set of values in the Historical Dimension lead us back to the same issues as with SCD Type 2? No. The current values in the Historical Dimension are just the latest revision in a series of revisions for the Dimension. The separate copy of the always-current Dimension table makes all the difference.
Separating the tables prevents clouding the business user’s understanding of the dimension by sourcing current and historical values from the same table. They intuitively grasp that Dimensions keep current “as now” values and Historical Dimensions hold the “as of” values that associate with facts.
Historical Dimensions Add Flexibility
Fact tables can now include both the Key and the HKey to relevant dimensions. The Fact_Sales table, for example, would contain both Customer_Key and Customer_HKey (see Figure 2). If the user wishes to see “as was then” values, the join to HDim_Customer is made through Customer_HKey. If the user wishes to see “as is now” values, the join to Dim_Customer is made through Customer_Key. One could even join to both if it was necessary to compare “as was then” to “as is now” values. In the case that a particular dimension row has not been updated since the fact was recorded, both the Historical Dimension and the Dimension return the same data values.
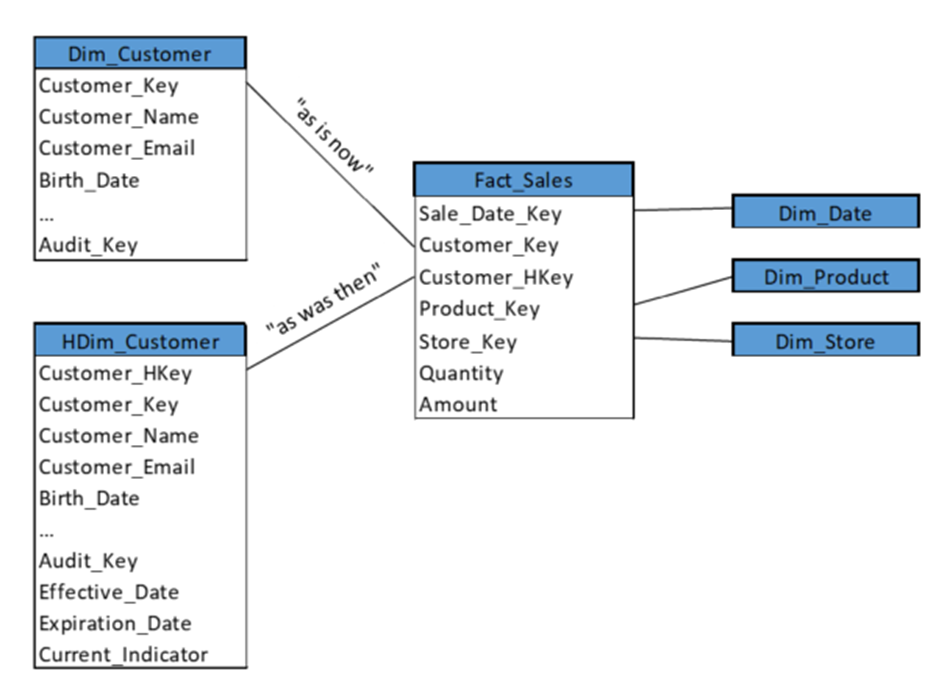
Figure 2: Users decide if they want sales transactions with historical values of the customer (join to HDim_Customer through Customer_HKey) or current values (join to Dim_Customer through Customer_Key).
Going back to the previous example, pulling the current email address from historical transactions is now easily handled by the BI front end software. Simply get the distinct list of email addresses from Dim_Customer for the fact table rows in question. Users readily understand this because they know that Dimensions always contain the current values.
Similarly, Historical Dimensions solve the problem of changing SCD Type 2 dimension keys in an accumulating snapshot table. These fact tables can now store the Dimension Key value, which always represents the current value and does not change. An accumulating snapshot fact table would not need to store the HKey value since potentially many Historical Dimension rows apply over the life of the accumulating snapshot fact row.
The Historical Dimension can be browsed on its own to track changes through time, right up the most current value. There is a link to the Dimension table through the Dimension Key, so there is no need to rely on a natural key such as Customer_Id to identify the same customer throughout its history. Relying on the standard key mechanism means such queries are easy for BI tools and users alike.
Historical Dimensions Ease the ETL Burden
One may wonder if committing to both SCD Type 1 for Dimensions and SCD Type 2 for Historical Dimensions adds to the complexity of the ETL layer. That is an appropriate concern since ETL can be the largest and most difficult technical portion of warehouse development.
Actually, making a consistent separation between current and historical dimensions also clarifies and simplifies the ETL process considerably. With a little setup, SCD Type 2 logic can be encapsulated in a single stored procedure that is called during the Dimension load. Write it once, call it for each Dimension, and never worry about it again.
What is involved in the afore-mentioned setup? First, we should have a way to identify all rows changed by the dimension load process. Kimball recommends an Audit Key in each fact table whose Audit Dimension tracks when the load started and finished, the number of rows inserted or updated, the number of rows rejected, and similar statistics. I have found the Audit Key concept useful for both facts and dimensions. If we do not have a similar key that tracks instances of a data load event, we could use a date changed timestamp if all rows contained the same value. As long as all inserted and changed rows in the same session have the same value, the requirement is met.
Second, define in metadata what kind of update should be performed for each dimension column. Each non-technical column should be marked as “Overwrite” (no need to keep a history of changes for this particular column) or “Insert” (if this column changes, keep its history). This can be done within a data modeling tool that supports custom attributes for columns. For example, in PowerDesigner, define an Extended Attribute for dimension table columns, then set the columns at design time. Next, export the values from the modeling tool to the database, in either a standard database table or your database’s extensible metadata tables.
With that setup in place, simply call the procedure to maintain history just before committing changes from the dimension load. The call might look like this:
|
1 |
EXECUTE Maintain_History (Dim_Table_Name, HDim_Table_Name, Audit_Key); |
The Maintain_History procedure pseudocode logic is the following:

The procedure can read the structure of the Dimension and Historical Dimension tables from the database catalog and execute dynamic SQL to process the changes. The call performs well since the Audit_Key is an indexed value that quickly identifies changed rows. The procedure does not perform a final commit transaction to the data – that is the responsibility of the calling Dimension load. This preserves the Historical Dimension load as part of the all-or-none load of the Dimension.
As a result, developers need only worry about getting Type 1 overwrite logic to work. The more difficult SCD Type 2 logic is completely abstracted away. Separating the history from the current allows us to put the power of SQL to use in identifying changed values and recording them as a separate and repeatable process.
Figure 3a shows two rows in the Dimension, and three in the Historical Dimension. John Doe has changed his email address on Feb 6 2019. Figure 3b shows the same two rows subject to more changes. We had entered an incorrect Birth Date for John Doe, while Mary Smith got married and changed her name and email address to reflect her new last name. The Maintain_History procedure would see the Birth Date was the only changed column for John Doe, and since the metadata indicates Overwrite, the Historical Dimension Birth Date column is overwritten. Mary’s changes to Customer_Name and Customer_Email are defined as Insert columns in metadata, so that triggers the insert of a new row to the Historical Dimension.
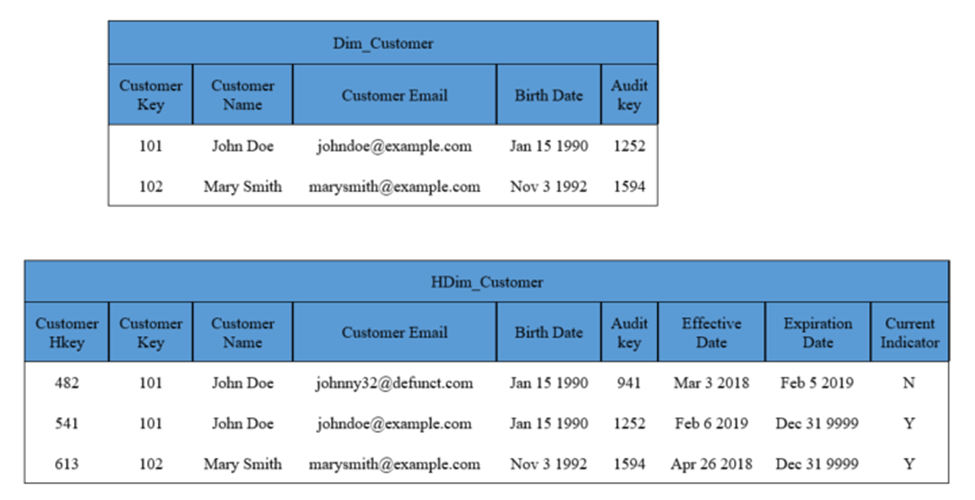
Figure 3a: Key 101 has had a change of Customer Email value in the past.
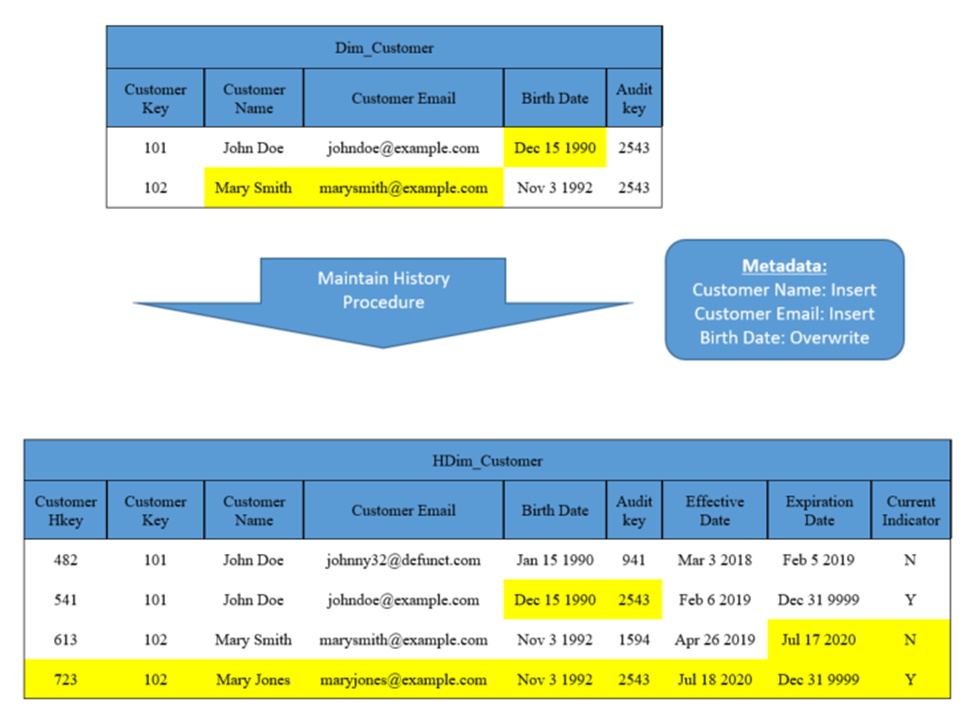
Figure 3b: Result of Maintain_History procedure on highlighted Dimension changes. Key 101 has Birth Date overwritten, Key 102 gets a new row due to name and email change.
How to Keep the Structure of Dimensions and Historical Dimensions in Sync
We’ve seen that maintaining the Type 2 SCD logic can be done in a single stored procedure, but what about the burden of maintaining a duplicate set of columns as the structure of our Dimension table evolves over time? This can be a challenge to keep up with manually, but it can be automated. If we have a flexible data modeling tool that supports scripting, spend a little time to script the creation of the Historical Dimension from the Dimension. Or, write the code in SQL or your favorite scripting language to generate the required DDL. It’s not hard, and it only needs to be done once. An effort like this pays off quickly over the long life of the warehouse.
Add Historical Dimensions at Your Own Pace
Recall that moving a dimension from Type 1 SCD to Type 2 SCD was not as simple as it seemed. Though the structure of the dimension table does not change, the meaning of each row does. And that affects existing queries, as they now need to add filters or distinct clauses to get the same results as before. Since we have been allowing our users to query the tables directly, we can’t identify all the code that would need to change. Effectively, adding Type 2 history to an existing dimension is a breaking change.
In contrast, Historical Dimensions can be added gracefully when the design team is ready for it. Nothing about the use of the Dimension table or existing queries will change when a Historical Dimension is added. A new HKey only needs to be added to existing Fact tables. If history values are available, the Historical Dimension can be loaded with them, or it can start as a duplicate of the Dimension table and grow from there. The Maintain_History procedure can recognize an empty Historical Dimension, and copy all Dimension rows to it to “prime the pump”.
If adding the new HKey to the dimension presents practical issues, even that may be avoided. The Historical Dimension has value on its own as the record of changes to the Dimension. It can be browsed independently of any fact tables for analytical and audit purposes. Historical values from the fact table are also easily obtained by querying the Historical Dimension using the Key value, and constraining the fact’s main date value to between the effective date and expiration date of the Historical Dimension.
Historical Dimensions Compared to Kimball SCD 7 and Wikipedia SCD 4
Kimball’s Design Tip #152 refers to SCD Type 7 as dual Type 1 and Type 2 Dimensions. This sounds promising, but it has the critical flaw of not separating the two dimensions. The Current Product Dimension referred to is simply a view over the Product Dimension, where the Current Indicator is true. Renaming the columns in this current dimension view to have a Current_ prefix reinforces this notion. If the Type 2 historical dimension is considered the “real” dimension, the confusion over what the dimension means will linger over the design. A concept of a Durable Key is presented, though it is confusing because it is not the primary key of a table.
In general, using views to avoid duplicating current dimension rows is a questionable idea. Remember that the disk space taken by dimensions is a drop in the bucket compared to facts. Since we have automated the loading of the Historical Dimension, we are no more concerned about that duplication than we are with duplicated descriptions inside the dimension. Views have their own performance characteristics that vary among and within DBMSs. It seems best to keep views for renaming columns in role-playing dimensions and materialized views for aggregate usage.
The Wikipedia Slowly Changing Dimension article calls the history table SCD Type 4. (However Kimball’s SCD Type 4 is an entirely different technique of “Add Mini Dimension”). This technique seems to capture the flavor of the Historical Dimensions presented here but falls short in the implementation. In the example given, the newly added historical row’s surrogate key is used to update the key of the current dimension. This would prevent us from using the stable key of the current dimension to provide current dimension values to any fact row. The power of the clear separation between current and history is lost.
Put Historical Dimensions to Work
Star schema designs are effective because they are clear and easy to query. SCD Type 2 tables muddy that clarity if they are not overtly labelled as historical. Once we take the step to separate current values in the Dimension from historical values in the Historical Dimension, simplicity is maintained. Users will be grateful to choose whether to see historical or current values in their queries. That choice might even be crucial for some business requirements, and developers will appreciate the “write once, use many” approach to history maintenance that Historical Dimensions provides. Project managers will welcome the ability to add history to existing current-only dimensions without breaking existing queries.
Add Historical Dimensions to your data warehouse toolkit, and your data won’t be forced to live in the past.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments