

In the fast-paced world of business, fast, effective data management is crucial. One of the places where this is the most evident is in the healthcare sector. From patient records to treatment data, every piece of information must be processed accurately and efficiently. But how do you ensure that each step of the data flow is executed in the right order, and errors are handled effectively? Enter Snowflake’s Parent-Child Tasks.
This article explores how to use Snowflake’s task features to implement parent-child data workflows. We will walk through a real-world scenario in which a healthcare organization manages patient records using a sequence of tasks for data ingestion, transformation, enrichment, and reporting. By setting up parent-child tasks, we can automate and control these steps, ensuring that each task is executed only after the successful completion of its predecessor.
What Is a Task ?
In Snowflake, in order to automate and schedule the business process we will utilize the Task feature. The Task infrastructure of Snowflake can run multiple types of resources such as:
- Single SQL Statement
- Call to a Stored Procedure
- Procedural logic using Snowflake Scripting
In this article, we will be using multiple tasks to call stored procedures to establish parent – child task relationships. To coordinate these tasks, we will be utilizing the Task Graph featured in snowflake to create sequences of tasks to implement a data pipeline for ingestion, transformation, enrichment and report generation.
The CREATE TASK statement will be used to create new tasks. You can see the syntax by following the link to the documentation. There are a lot of settings, many of which we will not touch on in this article.
What Is Parent – Child Task aka (Task dependencies)?
A task graph can be used to create what are commonly referred to as parent-child tasks. A parent – child task is the sequence of events where child task (dependent task) only execute after the parent task (root task) is completed it is job. It is commonly used in data engineering world to have data integrity within the tables. The relationship between the tasks are referred to as task dependencies, which is shown in the following diagram.
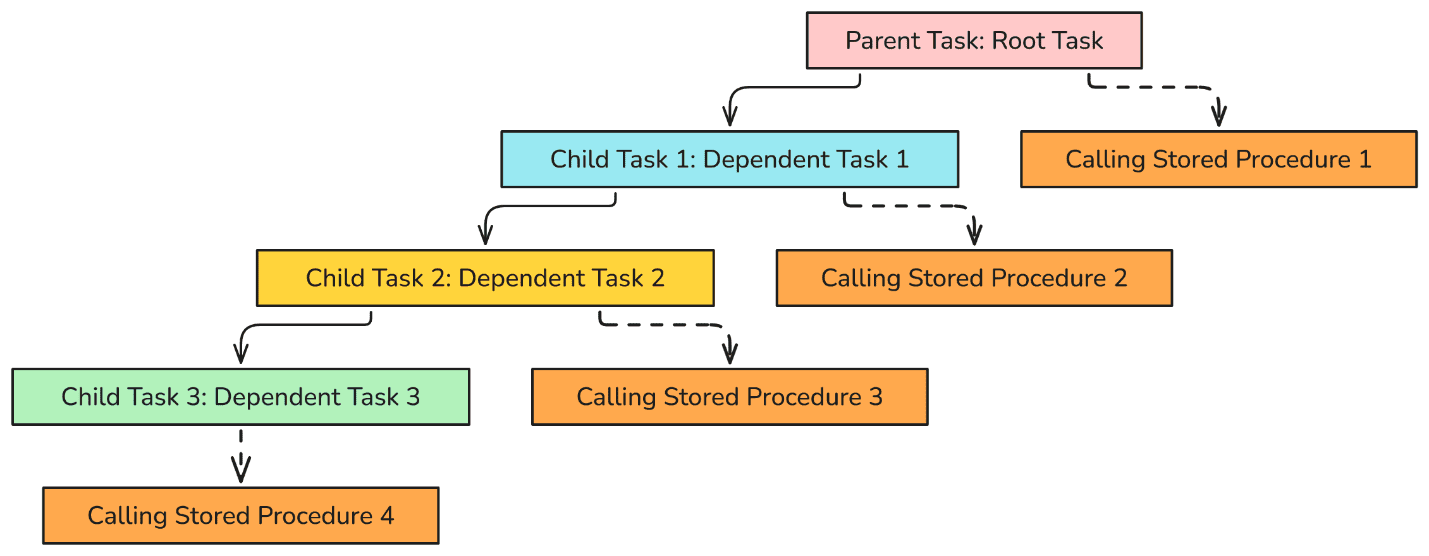
Parent Task
This will be the starting point (or the root of the graph) of the data pipeline workflow which can be executed to call SP1 (stored procedure 1). In this article, SP1 PREPROCESS_HEALTHCARE_LOGS will be used for pre-processing purpose to update the log table for removing null, so it can be ready for transformation in child task 2 HEALTHCARE_TRANSFORMATION_TASK.
Child Task 1
Once the data ingesting and cleaning is completed from parent task HEALTHCARE_PREPROCESSING_TASK, the next task which is our child task 1 HEALTHCARE_TRANSFORMATION_TASK to call SP2 (stored procedure 2). The SP2 TRANSFORM_HEALTHCARE_DATA will basically perform transformation such as categorizing the patient event.
Child Task 2
After completing cleaning and transformation task with SP1 PREPROCESS_HEALTHCARE_LOGS and SP2 TRANSFORM_HEALTHCARE_DATA respectively, our next action item is to add the data. Therefore, child task 2 HEALTHCARE_ENRICHMENT_TASK will call SP3 (Stored Procedure 3). In Stored Procedure 3 SP3 ENRICH_HEALTHCARE_DATA we will be adding provider details, providers are basically the one who provide healthcare services to patients such as medication, surgery and medical devices.
Child Task 3
In this final task, we would generate summary report based on processed and transform data. The child task 3 HEALTHCARE_REPORTING_TASK will call stored procedure 4 SP4 GENERATE_HEALTHCARE_REPORTS to produce final output of the healthcare data.
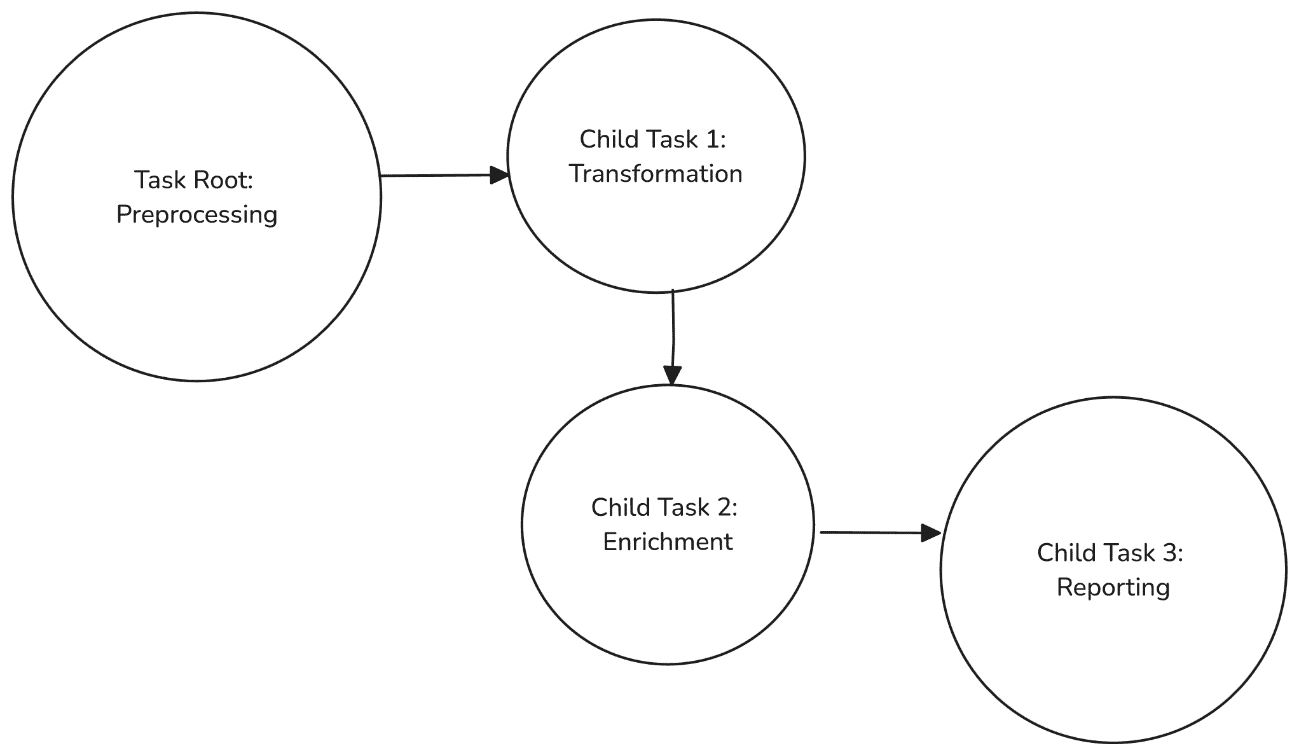
Parent – Child Task Data Flow or Task Graph Flow
The below figure showing a parent – child task data flow (task graph flow) within the healthcare environment. It starts with preprocessing task via sp1 (stored procedure 1) PREPROCESS_HEALTHCARE_LOGS to clean and normalize data. Next, we will apply child task 1: transformation task with stored procedure: TRANSFORM_HEALTHCARE_DATA (sp2) to categorize patient events for data analytics. Furthermore, we will implement child task 2 and 3 with sp3 ENRICH_HEALTHCARE_DATA and sp4 GENERATE_HEALTHCARE_REPORTS respectively, which will be utilized to insert additional data and producing final output for data analysis.
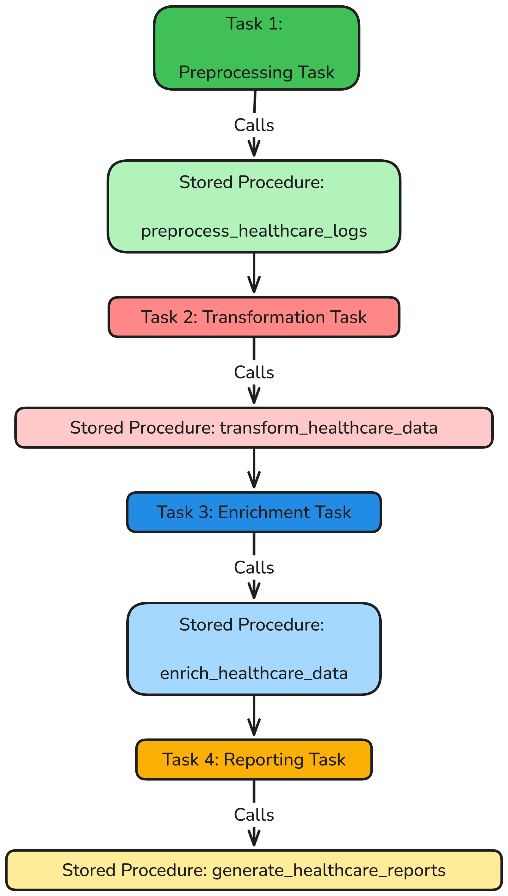
Parent Child Task Implementation
In this section, we will perform step-by-step process for task (parent – child) implementation in Snowflake. We will start with creation of database which we have already covered in this article. Afterwards, we will start with the development of 4 stored procedures along with the relationship reasoning of parent child concept within this article. We then progress to setup task graph with parent-child built in feature from SQL to automate the store procedures, as a result, it will create out final output, Daily_Reports.
Stored Procedures Creation
We will build a healthcare database in Snowflake at this stage. Start by creating a new database:
The two tables represented in the following screenshot can be created and populated from this SQL file if you want to follow along on Snowflake.
We will proceed to create four stored procedures represented on the following diagram that will be used for various purposes when processing our data.
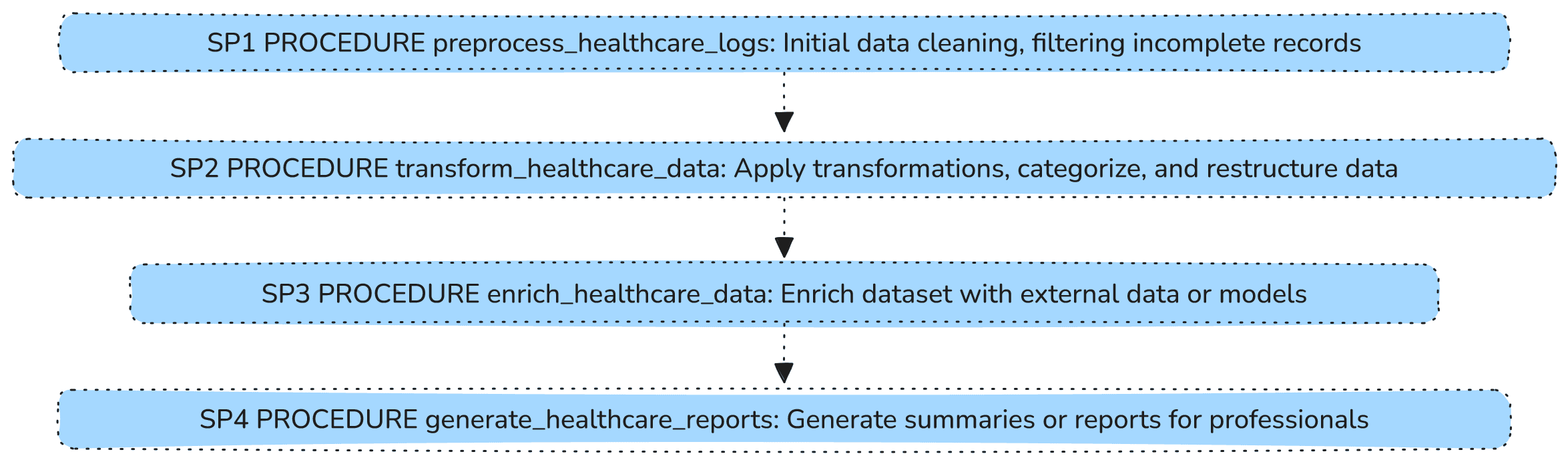
SP1 preprocess_healthcare_logs
Create the procedure by using following code:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
CREATE OR REPLACE PROCEDURE PREPROCESS_HEALTHCARE_LOGS() RETURNS STRING LANGUAGE SQL AS $ BEGIN -- Ensure timestamps are properly formatted UPDATE HEALTHCARE_LOGS SET EVENT_TIME = TO_TIMESTAMP(EVENT_TIME) WHERE EVENT_TIME IS NOT NULL; -- Remove incomplete records DELETE FROM HEALTHCARE_LOGS WHERE PROVIDER_ID IS NULL; RETURN 'Preprocessing Completed'; END; $; |
In the above code, we will ensure timestamps are correctly formatted using a standard format (YYYY-MM-DD HH24:MI:SS), it transforms the EVENT_TIME column into the appropriate TIMESTAMP data type. This is crucial because date values are frequently entered as plain text by raw ingestion processes, which, if improperly formatted, can lead to problems when sorting, filtering, or time-based aggregations.
Secondly, we will be removing NULL values from provider information is null because we want accurate reporting for healthcare compliance
SP2 transform_healthcare_data
Create the procedure by using following code:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
CREATE OR REPLACE PROCEDURE transform_healthcare_data() RETURNS STRING LANGUAGE SQL AS $ BEGIN -- Example: Categorize patient events based on type UPDATE Healthcare_LOGS SET PATIENT_EVENT = CASE WHEN PATIENT_EVENT LIKE '%Checkup%' THEN 'Routine Checkup' WHEN PATIENT_EVENT LIKE '%Surgery%' THEN 'Surgical Procedure' WHEN PATIENT_EVENT LIKE '%Emergency%' THEN 'Emergency Procedure' ELSE 'General Consultation' END; RETURN 'Transformation completed successfully'; END; $; |
Note: For demonstration purposes, this transformation overwrites the original PATIENT_EVENT value. In a production environment, it is advisable to write categorized values to a separate column to preserve the original data.
SP3 enrich_healthcare_data
Create the procedure by using following code. This procedure enriches the data, which in this sample case is just updating the PROVIDER_ID value to the same value (which basically validates that the Healthcare_LOGS.PROVIDER_ID value is in the ProviderDirectory table), but typically you might be pulling in additional columns.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
CREATE OR REPLACE PROCEDURE enrich_healthcare_data() RETURNS STRING LANGUAGE SQL AS $ BEGIN -- Example: Enrich data with provider details UPDATE Healthcare_LOGS AS H SET H.PROVIDER_ID = p.PROVIDER_ID FROM (SELECT PROVIDER_ID --, PROVIDER_NAME FROM Provider_Directory) p WHERE h.PROVIDER_ID = p.PROVIDER_ID; RETURN 'Enrichment completed successfully'; END; $; |
SP4 generate_healthcare_reports
Create the procedure by using following code. This code will create the report table by creating or recreating the Daily_Reports object using the data that has been manipulated in the previous steps.:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
CREATE OR REPLACE PROCEDURE generate_healthcare_reports() RETURNS STRING LANGUAGE SQL AS $ BEGIN -- Example: Aggregate data to create daily reports CREATE OR REPLACE TABLE Daily_Reports AS SELECT DATE_TRUNC('day', EVENT_TIME) AS Report_Date, COUNT(*) AS Total_Events, COUNT(DISTINCT PATIENT_ID) AS Unique_Patients FROM Healthcare_LOGS GROUP BY DATE_TRUNC('day', EVENT_TIME); RETURN 'Reports generated successfully'; END; $; |
Automating Stored Procedures via Task Graph (Parent – Child Task)
After creating the stored procedures, the next step is to create the task for each store procedure to create a parent – child process. The stored procedures relationship within the parent-child concept in Snowflake tasks, as applied to our content (the healthcare data processing workflow), is fundamentally about task dependencies and the sequential execution of stored procedures, where each task (child) depends on the successful completion of the previous task (parent).
In the context of a healthcare data pipeline, processing patient records in stages such as preprocessing, transformation, enrichment, and reporting is crucial. In a real-world scenario, these stages must be executed sequentially to ensure the integrity of the data at each step.
Therefore, snowflake’s task graph built with parent-child task offer a seamless way to automate these workflows. These tasks are executed sequentially, ensuring that each task completes before the next begins, thus preserving the logical flow of the data pipeline.
Here’s how we break down the automation process using task graphs:
Define the Root Task (Preprocessing)
The root task is responsible for the initial preprocessing of healthcare logs from stored procedure preprocess_healthcare_logs.
Create the task by using following code:
|
1 2 3 4 5 |
CREATE OR REPLACE TASK healthcare_preprocessing_task WAREHOUSE = 'compute_wh' SCHEDULE = '10 MINUTE' AS CALL preprocess_healthcare_logs(); |
In the task creation, there are a few parameters that have been defined.
|
1 |
WAREHOUSE = 'compute_wh' |
Specifies the virtual warehouse to execute the task. This user-managed warehouse provides the compute power needed to run the SQL in our procedure.
|
1 |
SCHEDULE = '10 MINUTE' |
This defines how often the task should run — every 10 minutes. It ensures our data is cleaned regularly without needing manual intervention.
|
1 |
CALL preprocess_healthcare_logs(); |
Invokes the stored procedure that standardizes date formats and removes invalid records (like null patient IDs) from our Healthcare_LOGS table.
What Happens if this Task Graph Takes Longer Than 10 Minutes?
Snowflake tasks do not overlap by default. If the task hasn’t finished before the next scheduled start, that run will be skipped. This helps avoid data conflicts, but repeated skips may cause processing delays. Hence it is good to monitor your processes to make sure that you have the interval time set to a reasonable level.
Create the First Child Task (Transformation)
Once the preprocessing task is complete, the transformation task takes over. This task uses the results of the preprocessing step and categorizes the patient data from transform_healthcare_data
|
1 2 3 4 5 |
CREATE OR REPLACE TASK healthcare_transformation_task WAREHOUSE = 'compute_wh' AFTER healthcare_preprocessing_task AS CALL transform_healthcare_data(); |
Create the Second Child Task (Enrichment)
The transformation task is followed by the enrichment task (enrich_healthcare_data), which pulls in external data like provider details.
Create the task by using following code:
|
1 2 3 4 5 |
CREATE OR REPLACE TASK healthcare_enrichment_task WAREHOUSE = 'compute_wh' AFTER healthcare_transformation_task AS CALL enrich_healthcare _data(); |
Create the Final Child Task (Reporting)
The final step is to generate healthcare reports from stored procedure generate_healthcare_reports. This task only runs after the data has been enriched.
Create the task by using following code:
|
1 2 3 4 5 |
CREATE OR REPLACE TASK healthcare_reporting_task WAREHOUSE = 'compute_wh' AFTER healthcare_enrichment_task AS CALL generate_healthcare_reports(); |
Task Monitoring and Report Verification
Before executing the sequence of tasks created above. Let’s examine our healthcare_logs table before making any updates.
Next, navigate to the task list to see the list of tasks. Note that tasks are in suspended state by default. So we will need to enable them.
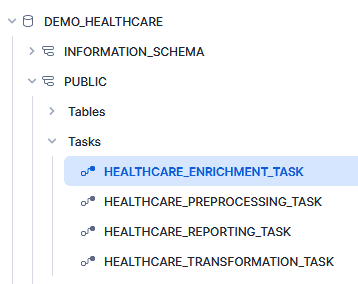
Once we click on graph section on DEMO_HEALTHCARE /PUBLIC / HEALTHCARE_PREPROCESSING_TASK you can see it is the root task which we have developed above.
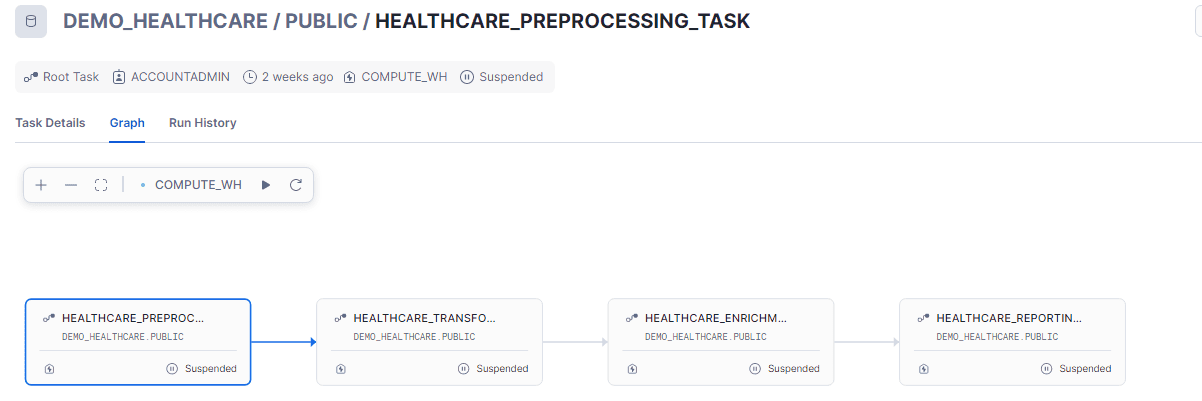
In order to navigate to child task we can navigate to DEMO_HEALTHCARE /PUBLIC / HEALTHCARE_TRANSFORMATION_TASK
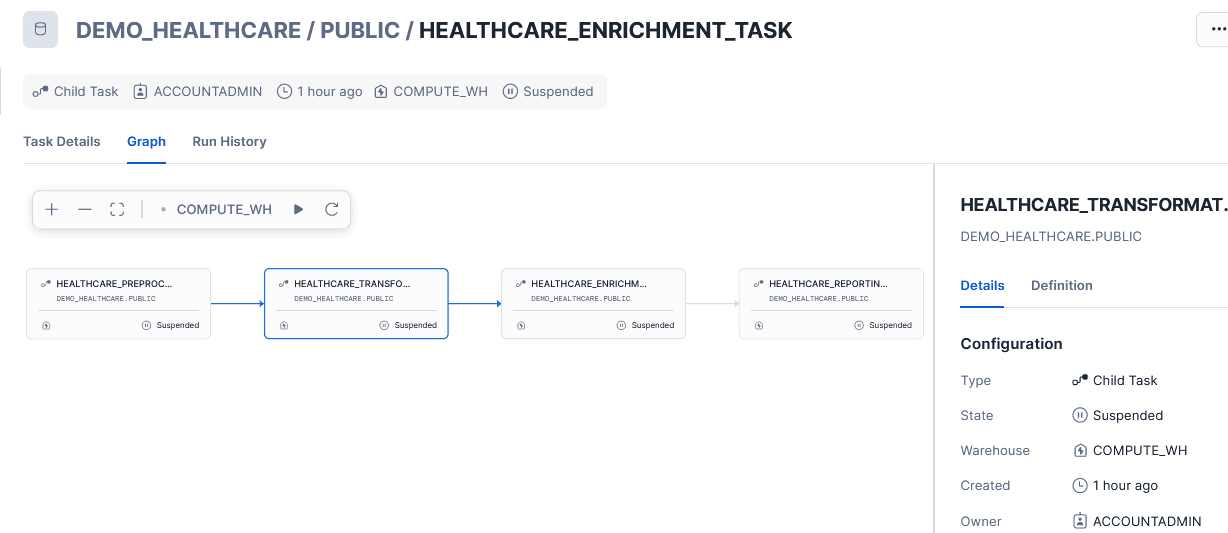
After examining the pre-task execution, now, the next step is to restart it. Snowflake tasks are stopped by default when created and must be explicitly resumed to become active. Do this by executing the following script:
|
1 |
SELECT SYSTEM$TASK_DEPENDENTS_ENABLE('DEMO_HEALTHCARE.PUBLIC.HEALTHCARE_PREPROCESSING_TASK'); |
Now you can start the tasks as noted. Then after executing all the tasks, the next thing to do is to verify the task execution. Now let’s proceed to monitor the task which we have executed. In Snowsight, the snowflake web interface, you can easily visualize and monitor task graphs:
Navigate to the Tasks section in Snowsight.
Here, you will see all active tasks and their respective statuses. For parent-child tasks, the interface shows the relationship between tasks in a tree structure, allowing you to view dependencies.

You can view details like the last execution time, status (Success, Failed, or Skipped), and the scheduled interval.`
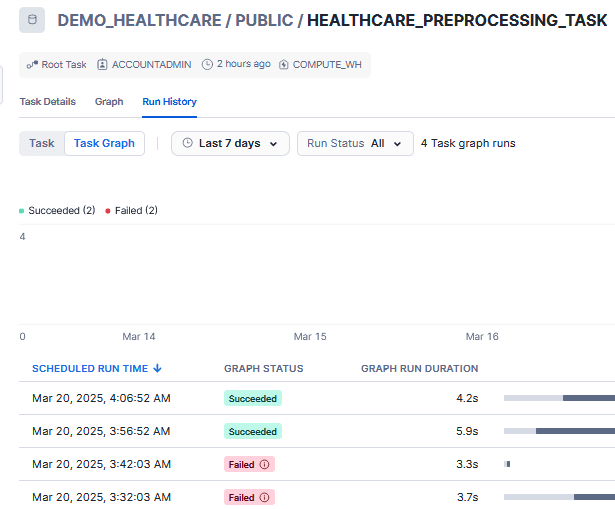
Prior to the task graph status as “succeeded”, we have received failure as well, when executing the task with the following error.

Note: This is an error I forced to occur by changing the stored procedure to reference H.PROVIDER_NAME, which does not exist in the table.
We double click on latest scheduled run time, it will open the task graph:
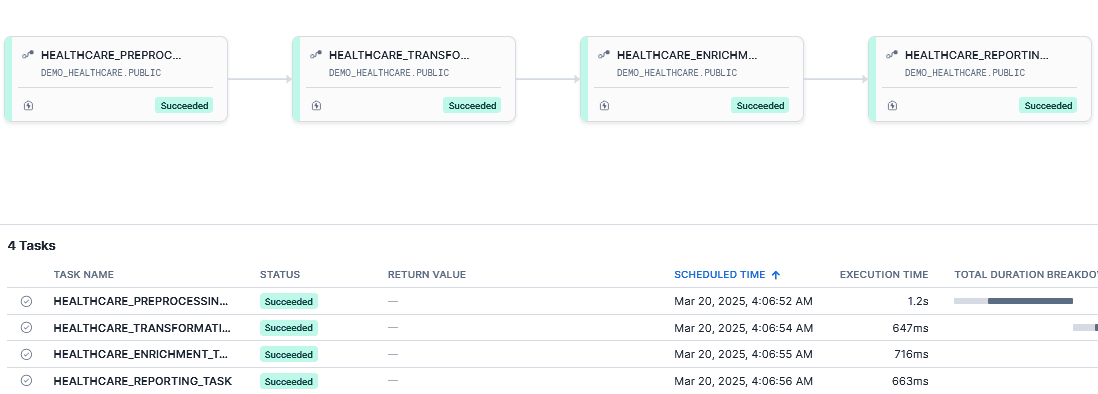
As you have noticed, all the task’s status is “Succeeded”.
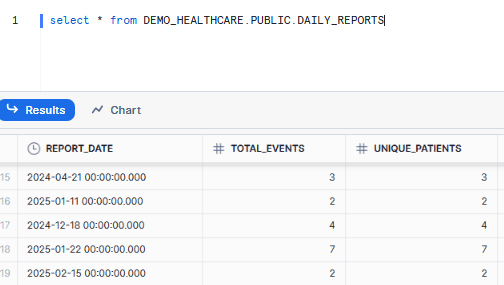
In the next step, we will check the data was populated for the report by the stored procedure SP4 generate_healthcare_reports via the healthcare_reporting_task task. To do this, I will execute the following query.
|
1 2 |
select * from DEMO_HEALTHCARE. PUBLIC. DAILY_REPORTS |
The output should look something like the following:
Conclusion
In this article, we focused on how to automate and simplify the processing of healthcare data by implementing parent-child tasks in Snowflake. We began by discovering tasks and how parent-child relationships enable the correct execution sequence of stored procedures.
Firstly, in order to ensure accuracy and efficiency, we built stored procedures for preprocessing SP1 preprocess_healthcare_logs, transformation SP2 transform_healthcare_data , enrichment SP3 enrich_healthcare_data, and reporting SP4 generate_healthcare_reports, which are the various steps of the data pipeline.
We then discussed about task graphs, which show the connections between parent-child task in an organized workflow graphically. We processed healthcare data step-by-step by automating the execution of stored processes using parent-child dependencies via SQL scripting.
This process shows that Snowflake can effectively manage patient data, making it easier for healthcare providers to access the latest and most accurate information.

Load comments