

This article offers technical guidance on automating updates and tracking changes of data examples using Snowflake’s CDC capabilities. The examples will be using healthcare type data, but the basic tenets apply in most use cases.
Introduction
This article discusses how to use Snowflake’s streaming features to implement Change Data Capture (CDC). Using the framework of managing healthcare patient records, we will look at how to update current records, make a capture log table, and automate the process using Snowflake’s task functionality.
In healthcare, it’s important to have the most recent data available. Using Snowflake’s CDC, we can automatically record every change made to data in typical tables. This method involves setting up stream objects, Snowflake’s features, that capture any changes inside the data.
We will explain how to set up these streams, how they capture data changes, and how they use something called offset storage to keep track of data changes accurately. The article will also show how these streams help in processing and updating data regularly through a process we will create called the apply_healthcare_changes task. This task takes the captured changes and updates the a history table named: healthcare_logs_history, ensuring that all records are current and reflect the latest information.
By the end of this article, you’ll know how to use CDC in Snowflake to manage healthcare data effectively, ensuring that the data is always updated and correct.
What Is Change Data Capture?
In the change data capture process, we create stream objects to keep a record of changes made to source tables, such as updates, deletions, and inserts. The stream objects basically keep a real-time log of all the changes made to the data.
The following example code shows the basic syntax for creating a stream object.
|
1 |
create or replace stream my_stream on table my_table; |
Every change in the my_table table will be copied to my_table and timestamped, which will be our checkpoint for all the changes that have been processed and acknowledged. This is referred to as offset storage, which is shown in the following diagram.
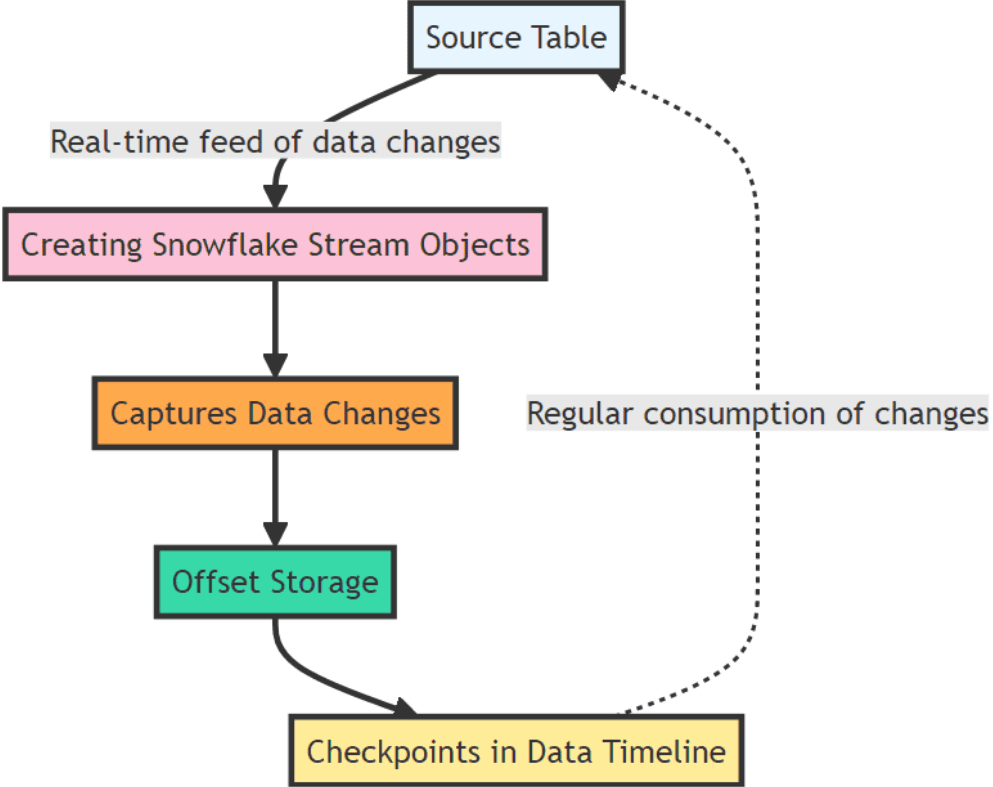
Each of the steps in the diagram are outlined in the following subsections, along with the objects that we will be using later in the process.
Source Table Insert/Update/Delete (healthcare_logs)
The starting point for data updates is the source table, which we will create later in the demo, that holds the logs for a healthcare system. Imagine it like a central log in a hospital, where patient information is constantly being refreshed. Whenever new test results arrive, medications are adjusted, or any details are added, removed, or modified, it triggers a specific set of procedures to ensure everything is documented and up to date.
Creating Snowflake Stream Objects and Capture Data Changes (healthcare_logs_stream)
Snowflake’s stream objects are like digital note takers, constantly monitoring the source data for updates. They record every addition, modification, or removal of information, ensuring a complete history is maintained. In a hospital setting, this might involve capturing new diagnoses, adjustments to medication plans, or changes to patient details.
Offset Storage in Stream Creation
The healthcare_logs_stream (can be kept as the original term for technical accuracy) keeps a watchful eye on the data, recording every update the moment it happens. It adds a offset, like a personalized mark and a time stamp, to each change. This offset ensures no update gets processed twice, and it helps the healthcare_logs_stream remember exactly where it left off. This is crucial for making sure the data stays accurate and follows the correct sequence throughout the entire process.
Checkpoints in Stream Processing
The healthcare_log_stream utilizes checkpoints to guarantee that data processing can pick up again from the last point known to be functioning correctly. This eliminates the need to reprocess everything from the very beginning. Imagine, for instance, a processing task encounters an issue after some changes have been made. The system can then simply revert to the most recent checkpoint and restart processing from there. This ensures that the data remains consistent and reliable throughout the entire process
CDC Data Pipeline Flow
This diagram depicts a CDC Data Pipeline Flow in an example healthcare setting, where data activities such as inserts, updates, and deletes are sent to the healthcare_logs Table. From there, a stream object, healthcare_logs_stream, is constructed to capture and record these changes, as well as the associated metadata. The apply_healthcare_changes task processes these collected changes and applies the results.
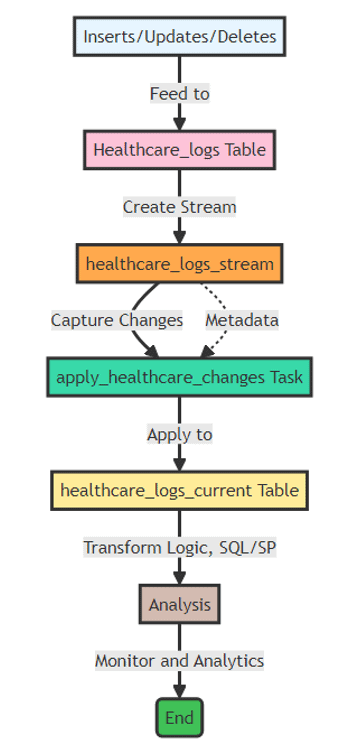
In the following sections, we will examine in a bit more detail some of what is involved with these steps.
Inserts/Updates/Deletes:
The process begins with data modifications happening at the Source Table, which includes inserts, updates, and deletes of data entries. This is typically where changes to patient records or healthcare logs begin in the system.
Create Stream (healthcare_logs_stream):
Following the data changes in the source table, these changes need to be captured in real-time. This is achieved by the “Create Stream” step, which sets up the healthcare_logs_stream. This stream is specifically designed to observe and log all changes (metadata and data modifications) occurring in the source table.
Healthcare_logs_stream (Capture Data Changes):
Within the healthcare_logs_stream, every alteration made to the source table—be it an insertion, update, or deletion—is captured. This stream acts like a continuous feed that records each change along with relevant metadata (like timestamps and the nature of the change). This is the critical phase where data capture happens, ensuring that no modification is overlooked.
Apply_healthcare_changes Task:
Once changes are recorded by the stream, the next step involves processing these changes. The apply_healthcare_changes Task automates the application of these changes to another dataset, specifically the healthcare_logs_current Table. This task essentially processes and integrates captured data changes into this historical data table, ensuring the data is up-to-date and accurately reflects all modifications.
Transform, Analysis, Monitor and Analytics:
After changes have been applied and the data is stored in the healthcare_logs_current Table, it undergoes further transformations (if necessary) to prepare it for analysis. This step might involve SQL queries or stored procedures to format or clean the data for effective analysis. Following transformation, the data is used for monitoring and analytics, providing insights and decision support based on the latest data.
CDC Practical Implementation
In this section, we will perform practical step-by-step implementation of CDC in Snowflake, starting with the creation of databases, tables, and initial data insertion. We then progress to setting up Streams and Change Tables to capture data modifications, followed by automating the ingestion of updates into the healthcare_Logs_Current table using Snowflake Tasks. Finally, we cover the processes involved in updating and verifying the data to ensure accuracy and reliability for downstream analysis.
Creating Database, Tables, and Inserting a Data
We will build a healthcare database in Snowflake at this stage. Start by creating a new database:
After the database is created, you may notice that there are two schemas already created in the database for you. PUBLIC and INFORMATION_SCHEMA. INFORMATION_SCHEMA contains views that you can used to get information about
As per standard practice in snowflake, you create your views, tables, task, and stream under public schema.
Following the creation of the database, the following columns will be added to the healthcare log table: This healthcare log table serves as a source table in addition to storing patient data. The SQL code is shown below.
|
1 2 3 4 5 6 7 8 |
CREATE OR REPLACE TABLE healthcare_logs ( log_id INT DEFAULT seq_log_id.nextval PRIMARY KEY, patient_event VARCHAR, patient_id VARCHAR, event_time TIMESTAMP, provider_id VARCHAR, deleted BOOLEAN DEFAULT FALSE ); |
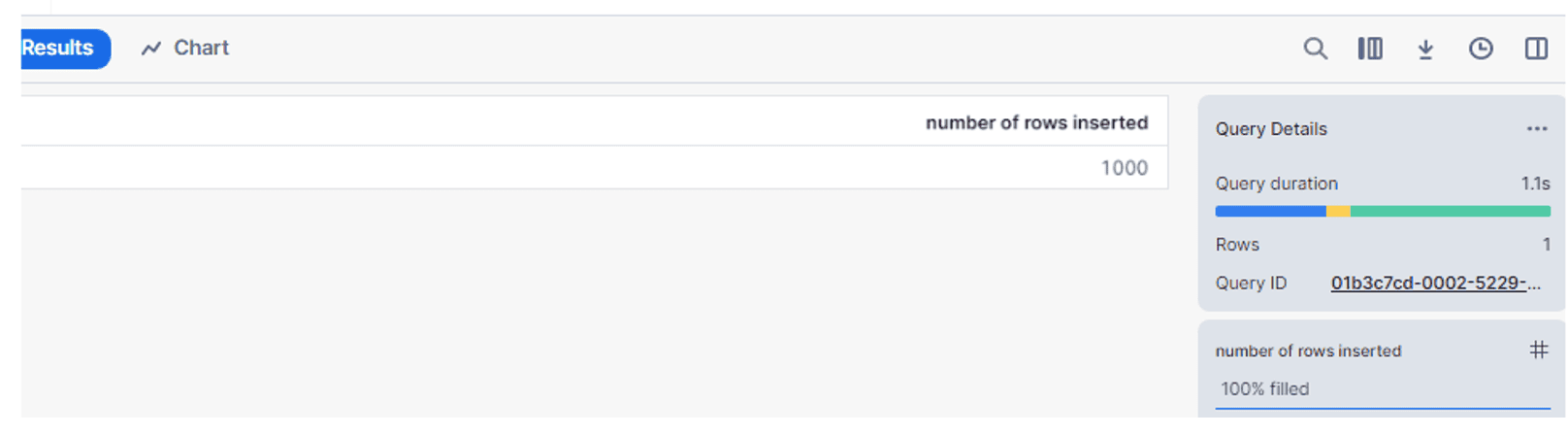
After creating the table, we will use the following SQL code to insert the data: Note that this is sample data, not actual, useful data from the real world. The healthcare log table now contains 1000 records that we have added.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
INSERT INTO HEALTHCARE_LOGS (patient_event, patient_id, event_time, provider_id) SELECT ARRAY_CONSTRUCT('Checkup', 'Surgery', 'Consultation', 'Emergency', 'Routine Visit') [FLOOR(RANDOM()*5)+1] AS patient_event, UUID_STRING() AS patient_id, DATEADD('day', -UNIFORM(1, 365, RANDOM()), CURRENT_TIMESTAMP()) AS event_time, UUID_STRING() AS provider_id FROM provider_locations, TABLE(GENERATOR(ROWCOUNT => 1000)) |
Executing this should show the following result:
Creating Stream and Change Table
During this phase, we will establish a stream on the healthcare_logs table to ensure that any modifications to the patient journey are reflected in the healthcare_logs_stream. We will also create a table named healthcare_logs_current to store these changes.
Create this stream using the following code:
|
1 2 |
CREATE OR REPLACE STREAM HEALTHCARE_LOGS_STREAM on table HEALTHCARE_LOGS; |
The healthcare_logs_current table will then be created, capturing the modifications made to the source table. Please take note that the task functionality provided in Snowflake will be used to generate the change log table.
As a result, we won’t be entering any data because an automated activity will handle that, which we will discuss in more detail later in this post.
|
1 2 3 4 |
-- Create a table that will reflect the latest state -- after applying changes CREATE OR REPLACE TABLE Healthcare_LOGS_CURRENT AS SELECT * FROM Healthcare_LOGS WHERE DELETED = FALSE |
Automation of Healthcare_Logs_Current Table Ingestion via Task
In a real-world electric health record scenario, we will typically see constant changes in patient journeys such as medical and laboratory tests, prescriptions, and drug prescriptions. Therefore, for data engineers and data administrator, it becomes cumbersome to maintain all those changes in our data. As a result, Snowflake has introduced “Task,” an easy-to-use automated functionality within Snowflake. There are multiple tasks that can be utilized in Snowflake; a few of them are the following
- Event Driven
- Time Driven
In our healthcare scenario, we will use Snowflake’s time-triggered activities to manage ongoing changes in the patient journey. These activities will ensure regular updates to reflect the latest patient interactions and treatment records. These tasks will load the change data and pertinent metadata into the healthcare_logs_current table for a consolidated view after capturing DML updates from the source table via a Snowflake stream. For further information on this implementation, see the code that is included below.
|
1 |
CREATE OR REPLACE TASK APPLY_HEALTHCARE_CHANGES</code> <code>warehouse= ‘COMPUTE_WH’</code> <code> schedule= '1 MINUTE'</code> <code> as MERGE INTO Healthcare_LOGS_Current AS target</code> <code>USING (</code> <code> SELECT * FROM healthcare_logs_stream</code> <code> WHERE METADATA$ACTION != 'DELETE' AND DELETED = FALSE</code> <code>) AS changes ON target.PATIENT_ID = changes.PATIENT_ID</code> <code>WHEN MATCHED THEN UPDATE SET</code> <code> target.PATIENT_EVENT = changes.PATIENT_EVENT,</code> <code> target.EVENT_TIME = changes.EVENT_TIME,</code> <code> target.PROVIDER_ID = changes.PROVIDER_ID</code> <code>WHEN NOT MATCHED THEN INSERT (</code> <code> PATIENT_EVENT, PATIENT_ID, EVENT_TIME, PROVIDER_ID, DELETED</code> <code>)</code> <code>VALUES (</code> <code> changes.PATIENT_EVENT, changes.PATIENT_ID, </code> <code> changes.EVENT_TIME, changes.PROVIDER_ID, changes.DELETED</code> ); |
After establishing the task, the next step is to restart it. Snowflake tasks are stopped by default when created and must be explicitly resumed to become active. Do this by executing the following script:
|
1 2 |
-- Start the tasks ALTER TASK apply_healthcare_changes RESUME; |
Data Update and Verification
First, let’s examine our healthcare_logs_current table before making any updates. You will notice that, currently, this table contains no records.
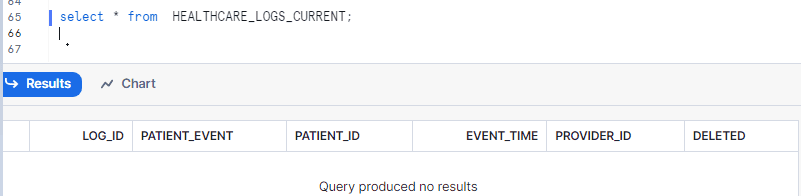
Now, let’s proceed to update the patient records using the SQL code provided below. In this update, we have changed the patient_event to ‘Checkup’ for the first record at the top of the healthcare_logs table. One row is updated due to the LIMIT clause in the subquery.
|
1 2 3 4 5 |
UPDATE healthcare_logs SET patient_event = ‘Checkup’ WHERE patient_id = (Select patient_id FROM healthcare_logs LIMIT 1) ; |
As previously mentioned, any updates to the source table are reflected in the change log table through the task. Next, to verify the successful automation, you should click on ‘task run history’ and then view the ‘show query profile’ to monitor the task.
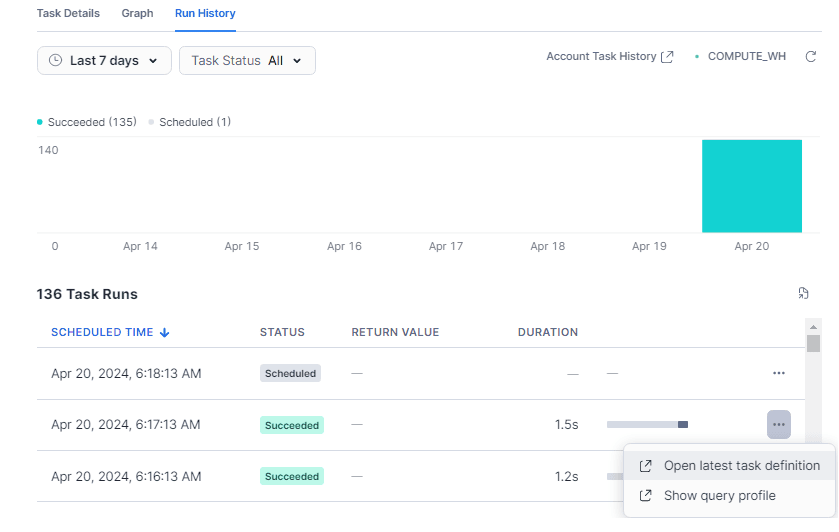
When you click on ‘show query profile,’ you will see that one update has been made to the healthcare_logs_current table.
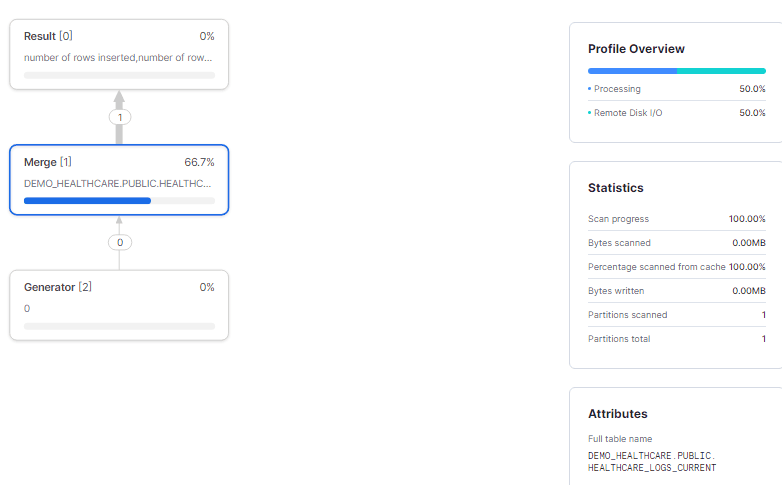
Afterwards, we’ll check our change log table using the query provided below and examine the output result.
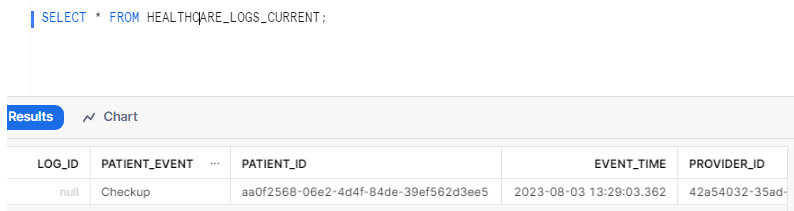
As you can see, the update we made to the patient event in the healthcare logs table is now stored in the healthcare_logs_current table.
Conclusion
In this article, we defined a complete method to deploying Change Data Capture (CDC) in Snowflake for healthcare data management. It routinely collects and logs patient records, assuring data integrity and speeding changes.
In addition, we discussed how to set up and use Snowflake’s features to manage healthcare data. We started by creating a database and setting up tables like the healthcare_logs table to keep track of patient information. We then showed how to automatically capture changes to this data using Snowflake’s streaming feature with the healthcare_logs_stream.
We explained the importance of using tasks in Snowflake, such as the apply_healthcare_changes task, to automatically update the healthcare_logs_current table with new data from the healthcare_logs table. This helps keep patient records up to date without needing manual updates.
Finally, we checked our work by updating records and reviewing these changes in Snowflake to make sure everything was working correctly. This process shows that Snowflake can effectively manage patient data, making it easier for healthcare providers to access the latest and most accurate information.
By following these steps, healthcare organizations can improve how they manage patient data, leading to better care and more efficient operations.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved

Load comments