
This is part of an ongoing series of post by Grant as he takes his vast knowledge of SQL Server and applies it to adding PostgreSQL and shares it with you so you can skip learn from his triumphs and mistakes. For more you can go to the Learning PostgreSQL with Grant series home page
When I decided that the next topic to cover would be data types, little did I know what I was getting into. According to the official documentation for PostgreSQL, there are twenty categories of data types. SQL Server only has 35 data types total. I thought about how to go about both learning the data types and writing this article. I’ve decided this article will be just about the categories of data types, and then any interesting bits within those categories. Likewise, I’m not going to drill down on specific data types now. There’s simply too much to cover.
This would also be a good time for a note about my process for learning PostgreSQL and my ability to translate that learning process to you. Understand that while I truly am just learning PostgreSQL, I have a large amount of experience with, and knowledge in, relational data structures. I started out in Paradox back in the 1980s before progressing to work professionally with Sybase, Oracle, Access, and SQL Server. So, while I am learning PostgreSQL from scratch, I’m not learning a lot of the concepts from scratch. As such, I may gloss over information that would be vital to you if this is your first RDBMS.
So, for the data types, I’m going to discuss the 20 categories and call out some interesting facts. However, even at this level, there’s probably some more fundamental aspects of data types you’ll need if you’re just learning for the first time.
One point I want to make up front, and it’s been true about every single data platform I’ve worked with, you really should use the data types as they are intended and not try to force behaviors where they are not appropriate. What do I mean? I mean that a string is a string and that is different from a date, which is different from a number. Can you interchange these reliably? Yes. Should you? No. Stick to using the appropriate data type. That’s as important in PostgreSQL as it is anywhere else.
With that, let’s get started.
Overview of PostgresSQL data types
Numeric types
The numeric types are very straightforward. There are three integer types for holding whole numbers: smallint, integer, and bigint. There are two precision decimal types: numeric and decimal. Then there are the floating types: real and double precision, which map to the mathematical constructs of singles and doubles. Finally, there is a set of numeric data types called serial, which are not really data types. These are just automatically incrementing integers but set up so you can easily use them when defining a table. They’re based on using a SEQUENCE operation, which is available within PostgreSQL.
I love the explanation that, even though these are auto-incrementing columns, you can, and likely will, see gaps. It’s good for that information to be clear right up front.
Except for the serial type, the Numeric data types are very straightforward.
Monetary types
Well, that’s misleading. There is exactly one, money. The only interesting thing here is that the decimal in money is fixed, but you can change it. It’s a database level setting you can adjust within a set range.
Character types
I expected a very long list here and ended up with three: char, varchar and text. The char data type is fixed length with padding. This means if you define a column as pettype char(50) and you put in the value cat, there will be 47 spaces added. The varchar data type is the same as variable character in other database systems. The column pettype varchar(50) and a value of cat means it stores just cat without padding. The varchar data type has a variable length as opposed to a fixed length string (another term for character). It’s also possible to omit the size for the varchar data type. In this case, it can hold any number of characters up to 1 GB.
The text type is meant for unlimited data up to 1 GB. It comes with a bunch of wrinkles, same as the similar data type in SQL Server.
The most interesting thing is that there are not separate Unicode data types. Instead, each of these three data types supports Unicode. That’s it. Easy. Honestly, I love this. I’ve always found the VARCHAR/NVARCHAR found in SQL Server construct to be a pain.
Binary Data types
Again, there is only one, the bytea data type. I think I see where this is going. Some of the “types” are simply going to be a “type”. Someone decided that defining them this way was better than just listing “Other” as a type with a bucket full of disparate data types.
Anyway, it’s a binary string called bytea. There are some rules and behaviors around escape characters, but basically, it’s for storing binaries like images within your database.
Date/Time types
I like the naming standards in PostgreSQL. It makes things much more straightforward than other systems I’ve worked with (<cough>SQL Server</cough). The timestamp data type stores both date and time. The date data type stores dates, but not times. The time data type stores time, but not dates. Finally, there is an interval data type. The interval data type stores a time interval.
I could spend the rest of this article talking about the interval data type. It’s fascinating. You can define the precise interval, from microseconds to millennia. You can also add a direction by adding ago to the input, effectively making it a negative interval.
There are a number of configuration settings for controlling time zone, special values and other behaviors. There are also date and time specific functions as well as date/time mathematics.
This is one of those data types that frequently get abused. People want a specific format on their dates. Rather than fixing that at the server or application level, they store dates as strings, which is a bad mistake; it removes tons of functionality. Use these data types as intended.
Boolean type
There is one Boolean type. Bool. It’s on or it’s off. It’s 1 or it’s 0. That’s it.
Enumerated types
This one is interesting. There is only one enumerated type, or there are an infinite number of enumerated types, depending on your point of view. Basically, this is an enum, an enumerated list. Let’s define one:
|
1 2 3 |
CREATE TYPE pets AS ENUM ('cat', 'dog', 'horse', 'cockroach'); CREATE TABLE mypets (mypet pets) |
You can define a data type as a defined list. In this case, only values that make up the enum pets can be inserted into the mypet column.
I’m going to have to spend some time with this one. It could be amazing, or it could be a performance hellscape. It’s unclear which, but maybe it’s both.
Geometric types
The geometric types make up another interesting category. There are a several, from point, to line segment, to circle, to the really fun one, path. You have a number of choices. There are also a several geometric functions that go with these data types. Not much to add to this one. These are only two-dimensional types though. All the types are built off an X/Y coordinate system.
Network Address types
This is fascinating. Up to this point in the article, all the data types we’ve seen have been pretty standard across database systems I’ve worked with. Oh sure, a few small additions, but nothing quite like these network address types. They’ve defined IPv4, IPv6 and MAC addresses as distinct data types. That ensures that you’ll always input them correctly because of type checking. However, you also get specialized networking functions, built right into the database.
Honestly, this is cool. Actually, I’ll go one further, this is what you get from open source software. Sure, you could probably build rules and user-defined data types into, say, a SQL Server database to emulate this. However, the work is on you to do it. There may also be software packages out there to help. Instead, built right into the database is a pretty standard set of needs for computer people.
You get three types:
- inet: This is for IPv4 and IPv6 host addresses with an optional netmask
- cidr: IPv4 and IPv6 network specification
- macaddr: This stores MAC addresses, such as your ethernet card and others.
I honestly don’t have an immediate need for these data types, but I’m intrigued at what it might open up in terms of data processing.
Bit String types
Another interesting one. There are two, bit(n) and bit varying(n). Similar to a regular string, char or varchar, you then get a padded fix length column, or a variable, but limited, length column. The goal of the data type is to store and/or visualize bit masks. I’m not sure if I’d put this to work much, but it’s good to know it’s a possibility.
Text Search types
This is interesting. There is a text data type, mentioned earlier, as a part of the Character Types. However, evidently, you can’t put full text search capabilities onto that column type. Instead, you need to use one of the two text search types, tsvector and tsquery.
These concepts get complicated quickly.
The tsvector consists of a list of lexemes (basically, words stored, but variants of the same word are merged together). Take a phrase like this one:
‘I do not like green eggs and ham. I do not like them Sam-I-Am’
It would be stored as such:
‘and’ ‘do’ ‘eggs’ ‘green’ ‘ham’ ‘I’ ‘like’ ‘not’ ‘Sam-I-Am’ ‘them’
You can see that the second set of ‘I do not like’ was eliminated, and the words have been alphabetized. That’s all done in the background. Oh, and it gets more complicated. There are also ways to define location within the string for proximity searches. You can also update your lexemes to provide them with weight to change what gets output from full text queries and what gets eliminated. You then get to the functions for dealing with the searches.
Speaking of searches, tsquery is where they get stored. This one stores the lexemes, as above, but then puts together groupings using logical operators $ (AND), | (OR), and ! (NOT). You can also control the logic with parenthesis.
I could go down this rabbit hole for a long time. I’ll leave it here for now since there is more to cover.
UUID type
Universally Unique Identifiers (UUID) which is the same as a Globally Unique Identifier (GUID). Interestingly, the database system itself can’t generate UUID but instead relies on external modules to do the work.
JSON types
What? No YAML?
There are two, json and jsonb. There are two key differences between them, both on the jsonb side. Jsonb is stored as a binary instead of as a string, making it slower to store and retrieve, but making it much faster to process JSON searches. Speaking of searches, jsonb also supports indexes.
The recommendation in the documentation is that jsonb will be better for most use-cases. The json data type keeps all formatting in place and doesn’t allow for any reordering of the keys within a JSON document. For most people, most of the time, I can see why none of that would matter.
The jsonb storage also works with primitive data types within the JSON documents, so you can ensure that text is text, numerics are, you know, numbers, bools are Booleans and a null value is, not null but (none) because null means something else entirely in SQL.
In addition to the indexing, jsonb also has the capability to determine containment, meaning one JSON document is stored within another.
There are also a ton of functions supporting JSON as well.
Array types
The documentation just says “Arrays”, being the only one without the word “Type” next to it. I put it back in there.
Honestly, I’d look upon this as the equivalent of SQL Server’s VARIANT data type. In short, poison.
Basically, you can now define a column in your database as a variable-length, multidimensional array, including all built-in, user-defined, enum and composite types. It gets better.
The documentation says: “The syntax for CREATE TABLE allows the exact size of arrays to be specified…”. It then follows that up with “However, the current implementation ignores any supplied array size limits…”
If you recall earlier, I said that the Network Types were an example of the benefits you can receive from open-source software. I’d say this bit of functionality is an example of the punishment you can receive from open-source software. Oh, I get it. We want to store anything, anywhere, at any time, any way we can, because it makes things “easy”. This is great until you have to maintain that stuff, performance tune it, ensure data integrity, clean up the mess made by poorly disciplined developers who can put any sized array they want to with anything in it, and there’s almost nothing we can do to stop them.
Look. Don’t do this.
The examples of using arrays I keep finding online are “Hey, you know what you can do instead of normalizing your data structures…” Yeah, watch performance tank. OK, maybe not. There are Generalized Inverted Indexes (GIN). These allow for indexing values such that the internals are composites.
There’s a lot to unpack here. However, I stand by my assessment, especially after doing searches to see if people have problems with performance using arrays. They do. I found this quote: “Why don’t you normalize your data? That will fix all problems, including many problems you didn’t encounter yet.”
As I get into this deeper, at some point, lots of testing will be needed to understand if this is good or bad.
Composite types
This type is another odd one.
When you create a table, you also get a composite type created at the same time. You can then use the composite type as a column in another table. Then, that other table gets, effectively, a table in its column. Now, if that sounds a lot like an array, I think I’d agree. Further, no constraints, even if they’re defined in your original table, will be enforced within a composite type. Also, you can’t create any new constraints for a composite type.
You can also create a composite type as a standalone object. I had to see this in action, so I ran the following script:
|
1 2 3 4 5 6 7 8 9 10 11 |
CREATE TYPE microphone AS ( waterproof boolean, speaker boolean, earpiece boolean ); CREATE TABLE radio ( radioname VARCHAR(50), mic microphone ); INSERT INTO radio (mic,radioname) VALUES ('(1,1,0)','Yaesu 8900'); SELECT * FROM radio; |
The result is here:
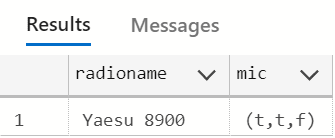
OK. That’s pretty interesting. Again, what happens with indexing? Performance? Lots more to learn here.
Range types
This is another really interesting one. You can create a range of values based on a subype, another data type. There are a number of built-in range types, and you can create your own. The built in ones are:
- int4range – a range of integers
- int8range – a range of big integers
- numrange – a range based on numeric
- tsrange – timestamps, date/time, but without a time zone
- tstzrange – same as above, but with a time zone
- daterange – range of date
Once you define ranges, then you get range functionality, upper bound, containment, overlap, intersection, stuff like that. It’s another fascinating data type. It’s also another array-style data type. I see why PostgreSQL is sometimes referred to as an object database. It’s mostly relational, but it has a lot of this kind of stuff in it that is clearly meant to work more with objects.
Object Identifier types
These are meant to be internal identifiers for system tables. It’s only a four-byte integer, so they don’t recommend its use as a primary key. However, you can use it to refer to system tables and system table identifiers within your tables. There several of these types, all referring back to objects within the database. For example:
- regproc – stored procedures and functions
- regrole – roles
- regtype – data types, our topic today
Interestingly, there are warnings in the documentation about the use of the oid and various types that will lead to “sub-optimal planning”. Based on the information around that, I think it means that the optimizer will make some poor choices when using these.
Domain types
A domain type is simply a user-defined data type. You can create the specified object type, but also add restrictions to it. The example shown in the documentation is defining a new data type as a positive integer. There’s no suggestion of restrictions, so I’m assuming any of the data types listed here would be supported as a domain type.
pg_lsn type
I’m not sure why they don’t just call this what it is, the Log Sequence Number (LSN) type. You can store pointers to the actual LSN in the logs. Further, you can do functions on them, like determine which LSN is greater (newer) and other functions, all related to the log and the transactions stored there.
Psuedo types
These are, for want of a better way to explain it, not quite data types. You can’t use them in column definitions. You can however use them as function arguments and result types. It’s a really wide list of behaviors. Let me give you a few examples:
- anyarray – a function will accept any array type
- void – a function that doesn’t return any value at all
- record – this function will take any kind of unspecified row
Some interesting caveats appear in the documentation. Evidently you can only use these for internal processing, except for void and record. That’s because most procedural languages don’t recognize these types.
PostgreSQL data types
I’m so glad I decided to walk through all these different data types. I can now see substantial differentiation between PostgreSQL and other relational data stores. I also see why others have referred to PostgreSQL as an object database. I don’t believe that to be the case, but you can absolutely see where that’s coming from, heck, creating a type for a table, automatically. I also found the generally mundane data types reassuring, that I can get the standard work done, as well as crazy stuff like defining data ranges within a single column. Finally, it was interesting that, despite this very wide variety of data types, there was no geography type. Looking it up, sure enough, there’s an extension you can add that supports it, so, that means, there are likely extensions for all sorts of other data types as well.
Remember, the code for this series is available on GitHub.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved





Load comments