
Part 1: What is testable code, why is it important, and first glimpses on practices that can help
Anyone familiar with PL/SQL, the procedural language extension to Oracle SQL, knows that the code they are touching is usually business-critical, likely to be around for a long time, and may undergo many revisions in the future.
Oracle introduced this powerful language with Oracle 7 to extend the database’s programming capabilities beyond SQL-92 functionality. It is optimized to work closely and seamlessly with data, and this data usually persists through many changes in UI and middleware. The same is true for the associated business logic implemented in PL/SQL:
What you build will typically last for a long time.
While it’s great to know that what developers build will not be thrown away the next day, this fact also has several implications. Most developers will deal with “historically evolved” code, so there is a professional obligation to think, not only about now, but also about the future. Future development and future developers will make the code evolve even more.
This challenge is often increased because an awful lot of PL/SQL code, and relational database code in general, is written in a way to make testing more difficult than it has to be.
This two-part article will explain why aiming for testable PL/SQL is beneficial and the techniques and principles you can use to achieve it.
What is “testable code”?
The first question to probably address is: what is “testable code”, and what do I mean by this term in this article?
Words can shift the perspective, so I will rephrase the term “testable code” to “verifiable code” from here on. This might help to answer the question.
When writing software, developers have certain expectations about what the code will, and won’t, do. Verifiable code can be verified to see if the expectations are true or false, maybe by example, maybe by logic or deduction. It is code where you can verify that what you create matches the expectations you have.
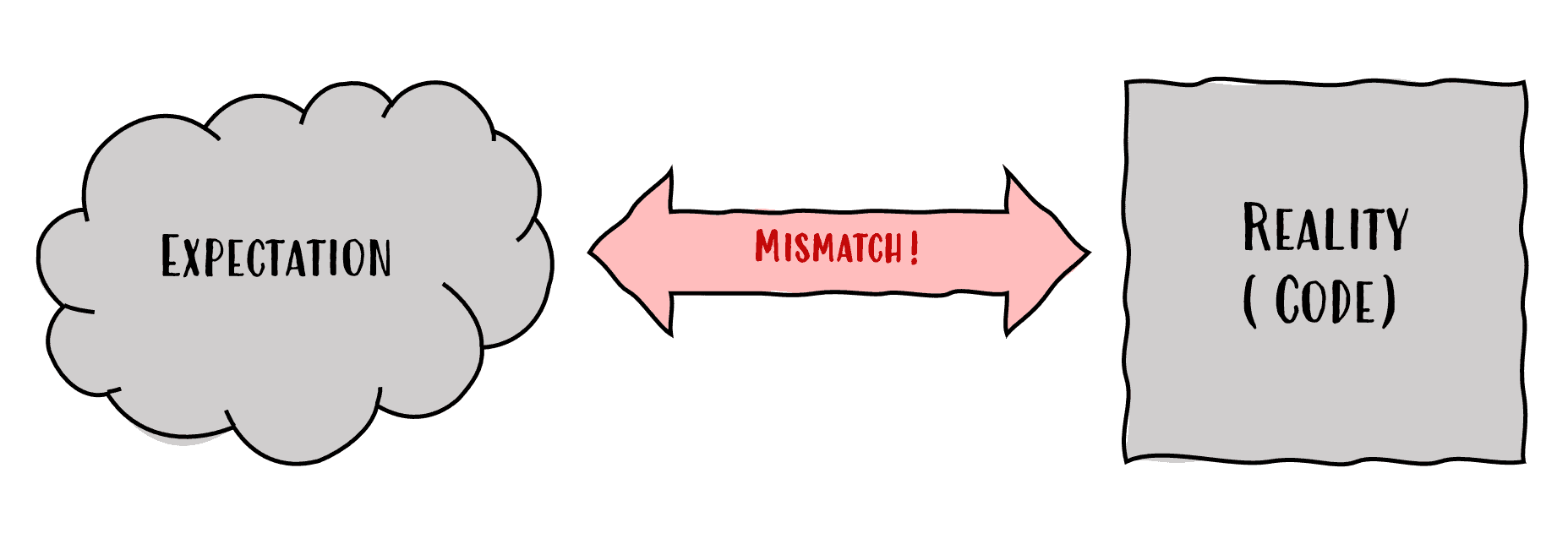
Unfortunately, when coding, sometimes a mismatch occurs between expectations and the reality of what the code is actually doing. This mismatch happens less when developers become more experienced, but even the most experienced developers will encounter this mismatch regularly.
What complicates this is that both sides can be the problem. The developer might have the wrong expectations about what should happen or might be missing context to really understand a problem. On the other hand, it’s also totally possible that the code has a defect or a limitation.

Neither case is very problematic if one notices the mismatch. If the developer notices that the expectations are different from reality, curiosity can kick in, and they can investigate the underlying issue.
It’s possible to improve knowledge, learn something new, or fix the code. The real problem arises when the mismatch is not noticed, which unfortunately happens a lot.
If the expectations are wrong and it’s not noticed, poor decisions may be made while coding or choosing the wrong solution. When the code has a defect, this might also cause problems in the future. In order to be able to notice these mismatches, developers need to be able to verify their expectations against reality.
In conclusion, code is testable when expectations can be verified.
This is true for almost all code, so what‘s the point here? The important thing is adding the word “easily”.
Code is testable when the expectations about it can be easily verified. When verifying expectations is easy, it’s done more frequently, more willingly and mismatches are spotted a lot earlier. This results in both fewer defects and a more accurate understanding of what the software is actually doing.
Quiz-time: expectations vs. reality
I want to invite you to take a little quiz to test your expectations versus reality.
If you’re short on time, you can skip this section without missing anything but a little bit of fun. Here are some questions that you can answer from your gut. Click to see the correct answer.
Question 1: There is a leap year every year divisible by 4
Question 2: Two time zones that differ will differ by an integer number of half hours.
Question 3: Okay, but quarter hours.
Question 4: “_D\@rth.V\@der!@deathstar.com” is a correct email address
Question 5: This equation in code will return true: 0.1 + 0.2 == 0.3
Question 6: A character can either be upper- or lowercase
There are a lot of expectations and assumptions that might or might not match with reality. Therefore it‘s very important to test and verify all assumptions.
But we have a good QA department
All software will be tested – if not by you and your team, then by the eventual users
Dave Thomas + Andrew Hunt, The Pragmatic Programmer 20th Anniversary Edition
In the past 20 years or so, there has been a huge shift in mindset with the agile and DevOps movements, but it’s still a widespread stance that there is a whole department of specialized people whose job is to find and report mismatches.
Let’s have a quick look at the problems of this approach:
The problem of time
For a long time, QA often happened at a much later state than development. This practice has thankfully changed, and, nowadays, QA is often involved right at the beginning of a project – and at the very end. Throughout the development process, it’s still not very common to have lots of testing and verification activity, which can lead to a number of difficulties:
- the context of a problem, a solution, or an implementation has already been forgotten when a mismatch is detected
- the stress level of all people involved increases immensely during classic test phases
- decisions are built upon decisions. When some mismatches are detected at the very end of the implementation phase, it might be harder to change them because they already influenced other parts of the software.
The biggest issue with time, however, is that there is never enough time to test and verify everything. At the same time, the time and effort needed to fix a problem often grow significantly over time.
A mismatch found when reading a requirement can be solved in 5 minutes.
Finding the same mismatch in a design specification might need 50 minutes to change.
When that mismatch is noticed during classic system testing, the time to fix it might be 5 hours, but fixing the same flaw in production could be huge.
The problem of complexity
Another problem of testing or quality assurance as a separate, disconnected activity at the end of the project cycle is that verifying is usually more complex at that stage.
Verifying at the end often means verifying larger chunks and combined systems, which have more dependencies and are, therefore, more complex. This might mean that verifying at this stage can be more expensive than doing it earlier, with smaller chunks and building blocks.
It’s important to state that a lot of this depends heavily on your specific context and environment. Verifying and testing late might be the right choice, depending on the context, and there is no scientific proof that doing that is always more expensive.
Some things are also only possible to test, or at least much easier when all pieces are connected.
However, expectations about software are generally more complex for a whole piece of software than for a single part of functionality, and therefore harder to verify. This is something to be aware of.
The problem of design
Detecting a mismatch does not necessarily mean that the code is wrong – there’s also the possibility that expectations and mental models are wrong. Detecting these mismatches helps deepen our knowledge and leads to making the right decisions.
When a lot of mismatches are detected at the end of the development cycle, and by people not involved in the development, this great advantage of deepening the understanding of the software, the context, and the problems to solve are lost.
The people who make the daily decisions might even end up having pretty inaccurate expectations about what the code they write does or should do.
This can lead to software that is built in a way not capable of solving the problems it‘s meant to solve.
This specific problem is even more impactful when thinking about the natural limitations of our expectations. The developer‘s environment, culture, and lived experience influence and limit what expectations they have. For example, many western developers would assume that last names should always have at least three characters, and that every person has exactly one last name. Both of these expectations are not true for many cultures and the whole concept of first and last names is very foreign in large parts of the world.
Verifying expectations early and often, with the help and collaboration of diverse perspectives, can help prevent a lot of the described problems and often lead to fewer defects, lower long-term costs, and better design. In order to be able to verify our expectations early and often, code should be easy to test.
Four practices for testable code
But how to achieve code that is easy to test?
I will introduce four general practices that will usually lead to code that is easier to test.
I say usually here, because everything depends on context. There is no silver bullet and not one right way to do it, which is why I describe them as practices.
The practices are related and will sometimes even look similar, but each provides a slightly different perspective that might help tackle a situation.
The practices are in no particular order, but to give you an overview, I will list them here:
- Reduce Dependencies
- Make Things Small
- Make Things Visible
- Set Clear Boundaries
The articles will look into each of these practices through one or more examples, but this article will cover the first two practices.
The Galactic Empire runs on Excel
I don’t know if you were aware, but like every large enterprise, the Galactic Empire runs on Excel. Of course, there is a database, but there are also so many sheets with different data, rules, and built-in knowledge.
Since all of the practices work for any piece of code, no matter the language or underlying system, let’s start with examples outside the database. Part 2 will have a closer look at concrete PL/SQL examples.
To organize the different projects and tasks, the Galactic Empire uses a number of Excel-files.
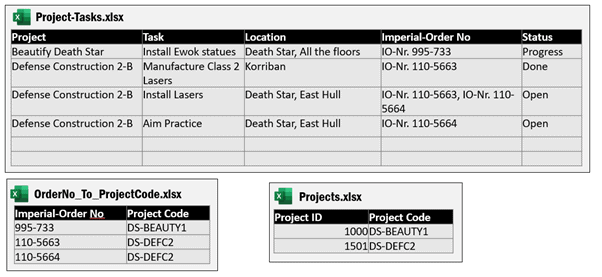
Unfortunately, the file with the tasks uses the Imperial Order Number but doesn’t contain the Project ID. There are two more Excel files, one that contains information which Imperial Order Number belongs to which Project Code and one that tells which Project Code has which Project ID.
To add the Project ID to the Excel file that contains the tasks, you must first look up the Project Code from file OrderNo_To_ProjectCode.xlsx and then look up the Project ID from Projects.xlsx.
It is totally possible to implement that, but to test such functionality, you’d need three files that can be found, are accessible, and will require a lot of lookup code.
Of course, the easiest way to solve this would be to replace these three files with three tables in a database, but let’s assume that this is our specific context.
The lookup of Project ID is currently difficult to test and a lot of things can go wrong.
Reducing Dependencies
To make it easier to implement and test this lookup, dependencies must be reduced.
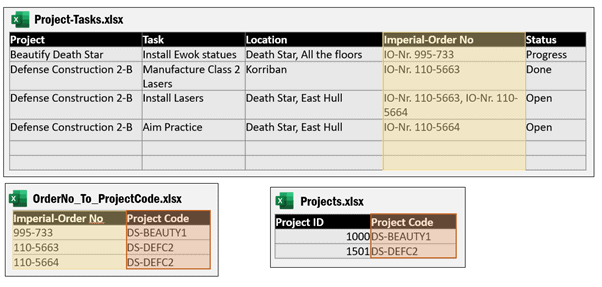
The most cumbersome dependency is the one that contains different physical files, so the first thing to do is to merge OrderNo_To_ProjectCode.xlsx and Projects.xlsx into the Project-Tasks.xlsx file as separate sheets.
Another useful thing to do is to combine the two lookups into one single sheet that contains all the required information:

You can still load the content of that Lookup-Table from an external data source, but, if necessary, you can also copy-paste the information manually.
The single Excel file can then be shared so that testing the formula to get the Project ID will be a lot easier.
This step is important to get into a position where there is easily verifiable code, in this case easily verifiable Excel formula code.
Looking up the Project ID
The Project ID is based on the Imperial Order Number, but, unfortunately, the according column is not very well-formed, which makes it a lot harder to deal with.
It could be possible to work on improving the data quality, but sometimes you have to deal with what you get, and the users really want to add all their order numbers in a comma-separated list inside this field.
Here’s the formula to look up the Project ID:
|
1 |
=VLOOKUP((IF(ISNUMBER(SEARCH(",";(RIGHT($D2; (LEN($D2)-SEARCH("IO-Nr. "; $D2)-6))))); LEFT((RIGHT($D2; (LEN($D2)-SEARCH("IO-Nr. "; $D2)-6)));SEARCH(",";(RIGHT($D2; (LEN($D2)-SEARCH("IO-Nr. "; $D2)-6))))-1); (RIGHT($D2; (LEN($D2)-SEARCH("IO-Nr. "; $D2)-6)))));Project_Lookup; 3; FALSE) |
Easy to understand, easy to test, easy to change, right?
Making Things Small
I gave a similar task to my trainee, and he was very optimistic that he would have the task completed by lunch. Late afternoon, he told me he was stuck.
The problem was that he tried to solve the problem all in one piece, in one single formula. Solving this is incredibly hard, especially when adding lines that contain no Imperial Order numbers to the mix.
It‘s just too big of a thing.
Maybe some folks can do this; I surely can’t because my brain capacity is limited.
What I did instead, and showed to my trainee, was to split this big, complicated formula into three separate, small chunks:
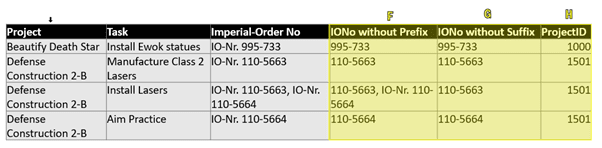
Column F (Imperial-Order No without Prefix):
|
1 |
=(RIGHT($D2; (LEN($D2)-SEARCH("IO-Nr. "; $D2)-6))) |
Column G (Imperial-Order No without Suffix):
|
1 |
=IF(ISNUMBER(SEARCH(",";$F2)); LEFT($F2;SEARCH(",";$F2)-1); $F2) |
Column H (ProjectID Lookup):
|
1 |
=VLOOKUP(G2; Project_Lookup; 3; FALSE) |
The formulas might still be a bit confusing, because it is Excel and most of us are probably not used to working in that language, but it is already a LOT easier to understand, change and verify.
Making things small is a useful, general practice to make your code more testable because big things are generally harder to verify – and understand – than small things.
With this separation in place, the code is easier to digest.
Problems are a lot easier to spot now because it’s easy to see at which step the problem occurs. When reality does not match with expectation, it’s easy to see which of the three steps doesn’t match.
The previous solution would only throw an error with no indication about the reason.
Conclusion
At this point, you might feel a bit of disappointment. You learned about the fundamental challenges around our assumptions, the potential mismatches with reality, and how often they occur. The article also looked into two of four practices to make it easier to verify assumptions, but didn’t touch any real PL/SQL code yet.
The interesting thing about the practices, however, is that they are not dependent on a specific language. They are universal and work for PL/SQL as they do for every other programming language, including Excel.
Part 2 of this article series will take a deep dive into several PL/SQL examples that highlight all of the four practices.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments