




I often fall back to the tried-and-true methods to understanding Oracle environments. Yes, sometimes the older ways are best, but understanding where Oracle has been and where it’s going is essential to us building the best products to support this enterprise, robust RDBMS platform.
I was disappointed by many of the documents out on the Oracle support site, etc., so this is an internal document to help understand how a seasoned Oracle DBA might navigate, learn and understand Oracle.
In this document I will share an overview of Oracle’s architecture that isn’t complete, but it will give you a basic understanding of how the architecture works, especially if you are coming from other database platforms.
It’s What You Know
Offer an Oracle Database Administrator a database host and say, “Here, you figure out what databases are out there and the configuration. We don’t know anything else about this server other than the Oracle password. You’re on your own after that.” There are some traditional methods most DBAs use, if left with just a terminal and a keyboard.
Let’s dive in on how it might likely go down…
Single Instance Identification
Prerequisite: Log into the server via a terminal session/putty/emulator
How do you find out about the environment?
Windows we can view the task manager and Windows services to identify everything, but Linux is going to be the environment most in question and most common:
What is the name of the host I’m running on?
|
1 |
hostname -a |
What is the IP Address?
|
1 |
ifconfig -a |
View the /etc/hosts file, which will have the long name and short name of the Linux server, along with the IP address.
What user are you logged in as?
|
1 |
whoami |
What databases are running on the host?
|
1 |
ps -ef | grep pmon |
This command, (along with most others on Linux/Unix) can be run inside of a SQLPlus command line session by adding a “!” before the Linux command:
|
1 |
!ps -ef | grep smon |
We’ll dig into this further on how we can capture more information inside the database, but if we have no access outside of the OS, this is a common way we can see what’s going on.
The SID is the last part of the process monitor (PMON) or System Monitor(SMON) process name:
|
1 |
oracle 31 1 0 23:23 ? 00:00:00 db_pmon_ORADB1 |
View the oratab file for entries. All databases residing on the host or have run on the host are listed. It’s not that all the databases ARE on the machine or running, but they at least existed at one time. This is why we trust the “ps -ef” command, as it tells us what is currently RUNNING on the host.
|
1 |
view /etc/oratab |
Inspect the entry(entries) past the commented-out sections of the file, (those that begin with a # sign):
|
1 2 3 |
ORADB1:/opt/oracle/product/19.0.0/dbhome1:N DWDB1:/opt/oracle/product/19.0.0/dbhome2:Y |
The entries also shows you the ORACLE_HOME directory, which is the Oracle software installation that this database is using, including the bin files. The “N” at the end signals on reboot to NOT start the database as part of the autostart script, where a “Y” signals that it should be started.
It’s Linux, Check Your Environment
You now know three things about the environment:
- The name of the database instance or instances.
- The
ORACLE_HOMEand from this, theORACLE_BASE(/opt/oracle). - If the database is running, (
PMONis up, database background processes can be viewed.)
Now it’s time to set up your environment. I’m going to demonstrate the default way to do it and the manual way, too…
Environment Setup Using ORAENV Script
|
1 2 3 |
. oraenv ORACLE_SID = [DB listed in ~/.bashrc] <enter SID here> |
Script sets the ORACLE_BASE, ORACLE_HOME and LD_LIBRARY_PATH if entry is in /etc/oratab file.
Manual Setup
|
1 2 3 4 5 |
export ORACLE_SID=ORADB1 export ORACLE_HOME=/opt/oracle/product/19.0.0/dbhome1 export LD_LIBRARY_PATH=$ORACLE_HOME/lib:/usr/lib:/usr/dt/lib:/usr/openwin/lib:/usr/ccs/lib |
Notice that I used the command “export” before each of the environment settings to ensure that I’ve exported the variables for my session.
Checking Environment Settings
How to check if the environment is set up correctly:
Use the ECHO command:
|
1 2 3 |
echo $ORACLE_SID echo $ORACLE_HOME |
These commands should return the values that were entered as part of the script or manual setup.
Now that you’ve verified the environment and may have required this to log into SQL Plus or other tool, (vs. verifying environment variables set) you can now log in:
|
1 2 3 |
sqlplus / as sysdba sqlplus user@service |
The above two commands are using the sqlplus utility, which is the most common utility any DBA uses. It comes with Oracle and has been around for several decades. The other two most popular ways to log into an Oracle database is SQLcl which is new as Oracle 18c and is lighter weight if installed on a desktop. The other is Oracle SQL Developer, which is a UI, but has significant additional support packages and some monitoring capabilities for developers and DBAs.
The first connection command is a bequeath connection. It uses the ORACLE_SID environment variable to fulfill the database name information. It is logging in as SYSDBA as the OS user, which must have OS level privileges, (owner/DBA) to do so. As I’m ORACLE on this container, I’m able to do just that. The WHOAMI command earlier verified this for us as we were inspecting the environment.
The second login command is for a user and uses a service name. It will not be a bequeath connection but will use a TNS names/EZ Connect via the Oracle listener and will require this set up on the database. If the listener isn’t running, then this type of connection, which is the most common for Oracle, will fail.
Main Architectures for Oracle
Oracle has been around for over forty years. The first release was Oracle 2.0, which was released in the 1978. Claims of being the most widely used database begun during Oracle 7.34 days in the 1990’s. Many databases you see today may have started out on this version and have been upgraded, patched and modernized throughout the decades. Due to this and the mission critical nature of these systems, the organizations and DBAs are quite risk averse and tend to not change anything unless it’s absolutely necessary.
Versioning
Oracle database versions have changed from release numbers to release years, starting with Oracle 18c. Terminal releases are the final release of that iteration and the ones that will be supported long-term. They are the release version targeted by organizations.
Release numbers in italics are no longer supported by Oracle or require extended support.
- 10.2.0.4 (10g terminal)
- 11.2.0.4 (11g terminal)
- 12.1.0.2 (12c release 1)
- 12.2.0.1 (12c terminal)
- 13c (Oracle Enterprise Manager ONLY)
- 18c
- 19.24 and 19.3 (terminal)
- 21c
- 23ai (terminal)
Architecture
There are multiple variations in architecture to meet customer needs when architecting on-premises.
The architecture options in italics are rarely seen in real-life scenarios and will be covered at a later date. The goal is to cover the most common scenarios and create diagrams for easy translations.
- Single Instance
- Real Application Clusters (RAC)
- Single-node RAC
- Multitenant, single pluggable database
- Multitenant, 2+ pluggable databases
- Globally Distributed Database
- Data Guard, passive or active configuration secondary
- Goldengate replication secondary
- Goldengate peer-to-peer active/active configuration
- Exadata database, (along with Exadata engineered system monitoring)
- Oracle Database Appliance, (ODA) with or without RAC
Database Terminology
Oracle has unique terminology that may use term definitions that mean something different in other platforms. This is the correct definition for Oracle in the following statements.
SID: Site Identifier. This essential value can be set using the ORACLE_SID environment variable. Most DBAs set the SID to be the same as the instance name and/or the service name, but the service name can be a unique name, too. To query this from SQLPlus:
|
1 |
select instance from v$thread; |
The SID can be changed for the database and can be the same as other databases. There is also a unique identifier(GUID) for the database, called the DBID or in some views, DB_ID.
Database Name: As this can be different from the SID, you can query the database to verify:
|
1 |
select name from v$database; |
Service Name: Is often used to describe the alias used to connect to a RAC database, but it has become the standard for connecting to an Oracle database vs. using the SID. When viewing the TNSNAMES.ora file, the option to use SID= or SERVICE= will be seen in the file entries interchangeably.
|
1 2 3 |
select name from v$services; select name from v$active_services; |
Oracle Instance: The service, memory allocation (aka SGA) and background processes for the database.
ASM: Automatic Storage Management – Oracle’s own file manager, allowing the DBA to manage all file storage. ASM will have its own database instance, that is running and maintains all file management for the databases that reside on the database host. There are ASM utilities to manage storage, datafiles, etc. that are part of ASM.
Single Instance: Traditional architecture, where the Oracle database owns all background processes and files. There’s no container database connected to the architecture. This architecture is obsolete in Oracle 23ai.
Multitenant: Oracle’s container database architecture. Consists of a container database (CDB) and various pluggable databases (PDBs) which can easily be unplugged and plugged into a new CDB on a new host or cloned, etc. Any database with a CDB architecture is multitenant, but licensing doesn’t go into effect until 4+ database are housed under one CDB.
RAC: Real Application Cluster for Oracle. A highly scalable and instance resilient architecture for Oracle databases with multiple nodes (database servers) sharing a single copy of the database with shared storage.
DG: Oracle Data Guard is a replication technology with a primary and a secondary, offering a passive or active, (read-only) configuration. Multiple secondaries can be configured for reporting, disaster recovery and backup, even high availability for cloud datacenters.
GG: Goldengate transactional/log replication for Oracle. Very flexible and self-service type product that works on multiple platforms to Oracle, too.
RMAN: Oracle Recovery Manager, the go-to for all physical Oracle backups. Incredibly flexible, allowing for flashing back databases with flashback features, cold/hot backup, incremental backup, transportable tablespace and other features.
Datapump: Oracle’s import and export utility. As databases get larger, used less often due to slow performance. Import/export tuning of datapump is commonplace these days, but the ability to create a logical export is attractive to many customers.
Connecting to a Single Instance
Single instance Oracle databases were once the default architecture for Oracle. Each Oracle database owned all its own background processes, which means if you ran the following command on a Linux/Unix server which housed multiple Oracle databases on it:
|
1 |
ps -ef | grep pmon |
You would receive something like the following as part of the results:
oracle 31 1 0 23:23 ? 00:00:00 ora_pmon_ORADB1oracle 47 1 0 12:11 ? 00:00:00 ora_pmon_DWDB1oracle 89 1 0 04:18 ? 00:00:00 ora_pmon_PRDDB2
The above results would mean that there are THREE Oracle single instance running on the host:
ORADB1DWDB1PRDDB2
For each single database instance, there is a process where user sessions connect using various means, but most commonly use a connection string for TCP connections to the Oracle Listener, connect to the database, which has all it’s own processes, redo logs, undo tablespace, schema tablespaces and temp tablespace. If the database is set up for point in time recovery (PIT), then it is in archive log mode and it will also write the redo logs to archive logs for retention required to perform PIT recoveries when needed.
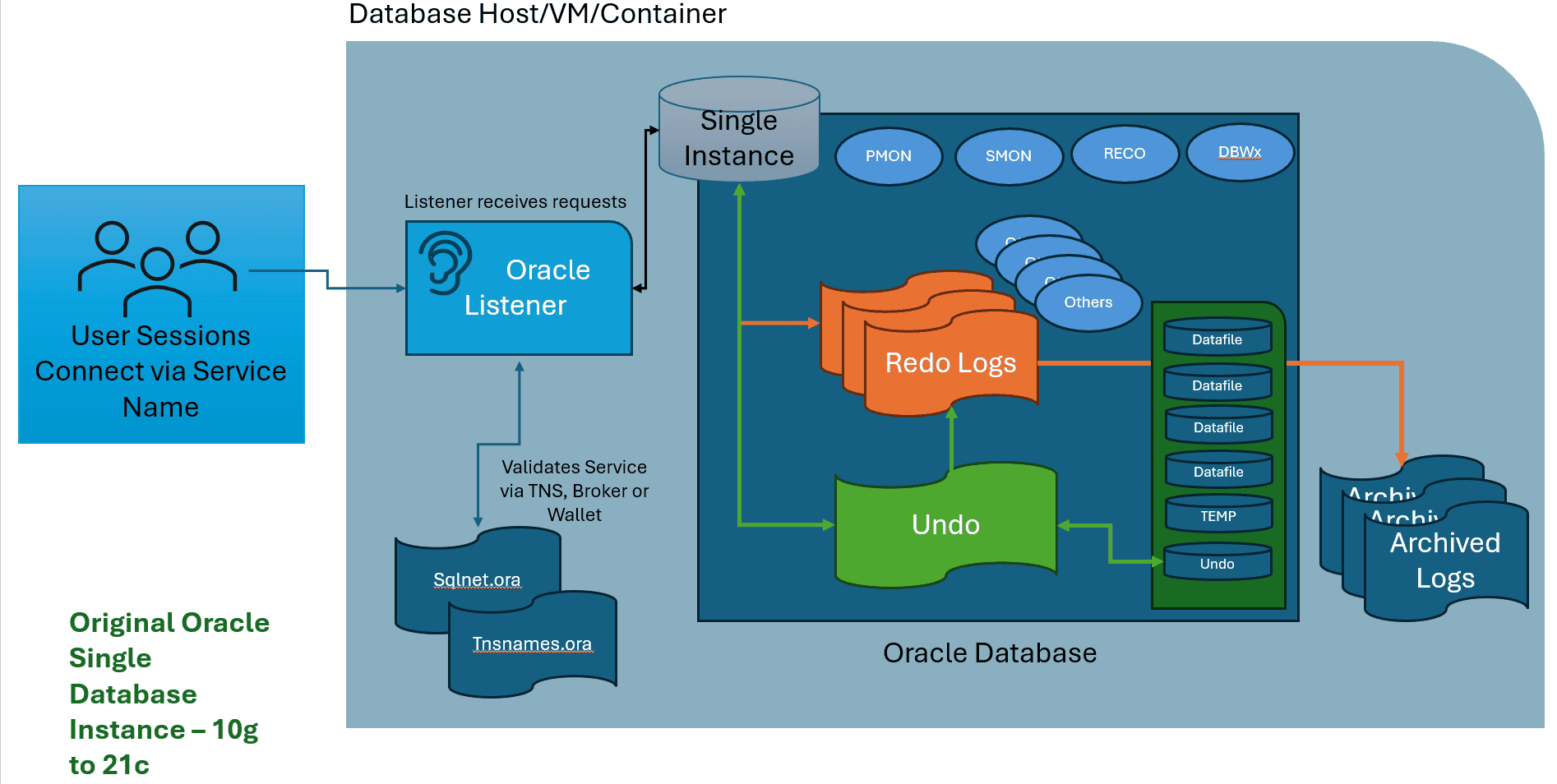
The architecture above is quite high level, but the focus is on the differences around database architecture in Oracle, while giving similarities to compare each diagram with as we proceed into the next architecture configuration.
Connecting to Multitenant
As the DBA begins to understand the environment, the host and the databases they are going to be managing, a picture begins to develop. For a multitenant database, we can visualize users logging in with their username, password and service name, the listener picking up the request and then the session connecting to the database once it is authenticated.
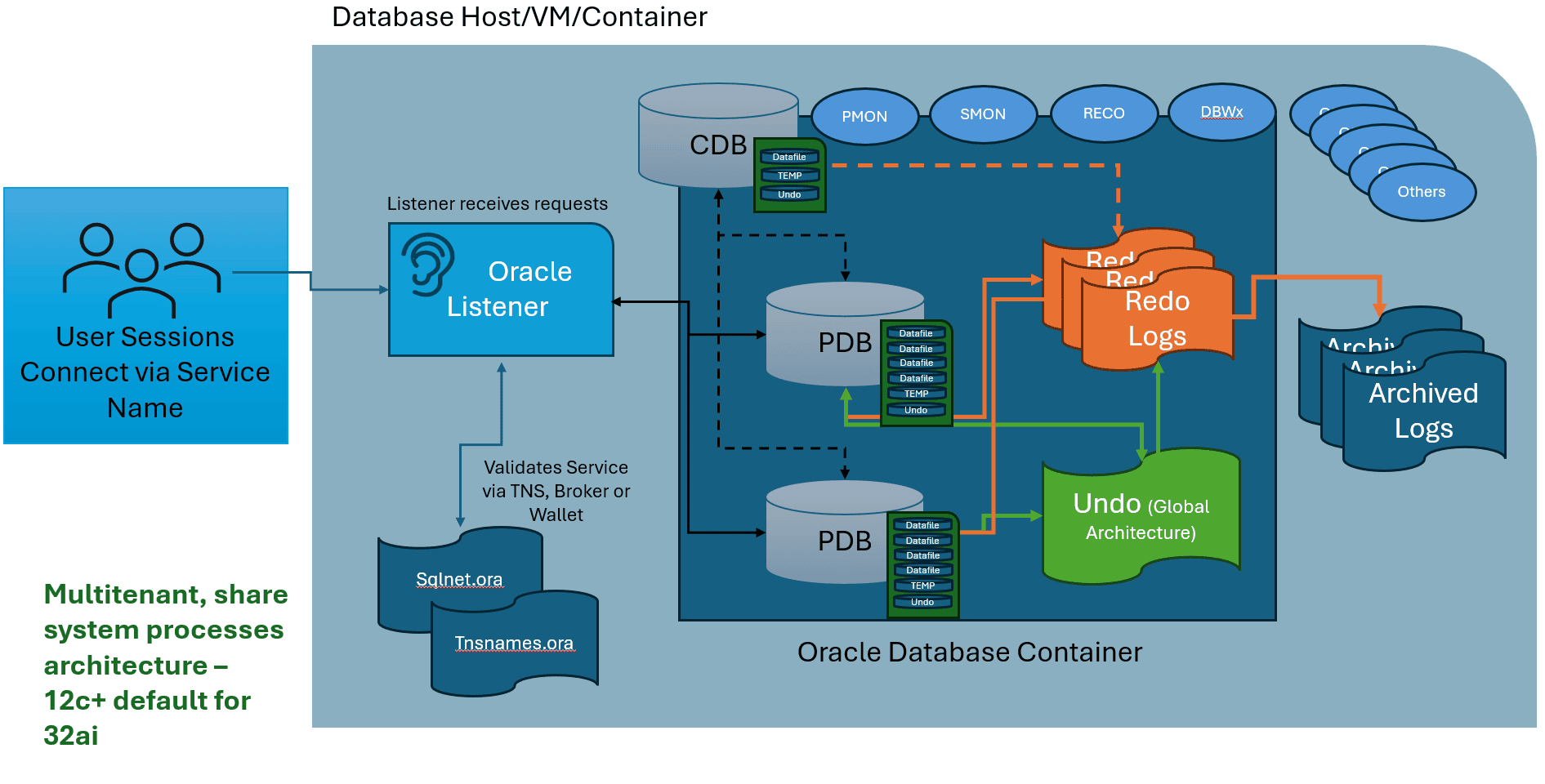
Once connected to a pluggable database (PDB), SQL statements are executed, returning results and/or making changes to data, which are written to the undo if there is a need to roll back and also to the redo logs, in case we need to roll forward or back as part of any type of recovery step. Redo information is written to the archive logs for Point in Time recovery needs and stored along with our backups to create a complete recovery strategy.
Notice that in multitenant architecture, the background processes are shared among the CDB and PDBs to save resources. Undo can be configured globally or PDB (this is a newer capability) level. The ability to archive and do point in time recovery is at a PDB level, but redo logs are owned by the Container Database (CDB) and must be configured at this higher level in the hierarchy.
Connecting to a RAC Database
The second most common type of database for Oracle is Real Application Cluster, (RAC). This offers extensive scalability and instance resiliency, allowing the database to scale more than one host or virtual machine, while sharing storage between all hosts, referred to as nodes, of the RAC database. Each node of the RAC database has its own background processes, along with numerous others that are managing the connections and global cache processes that keep each node aware of what the other node or nodes are doing.
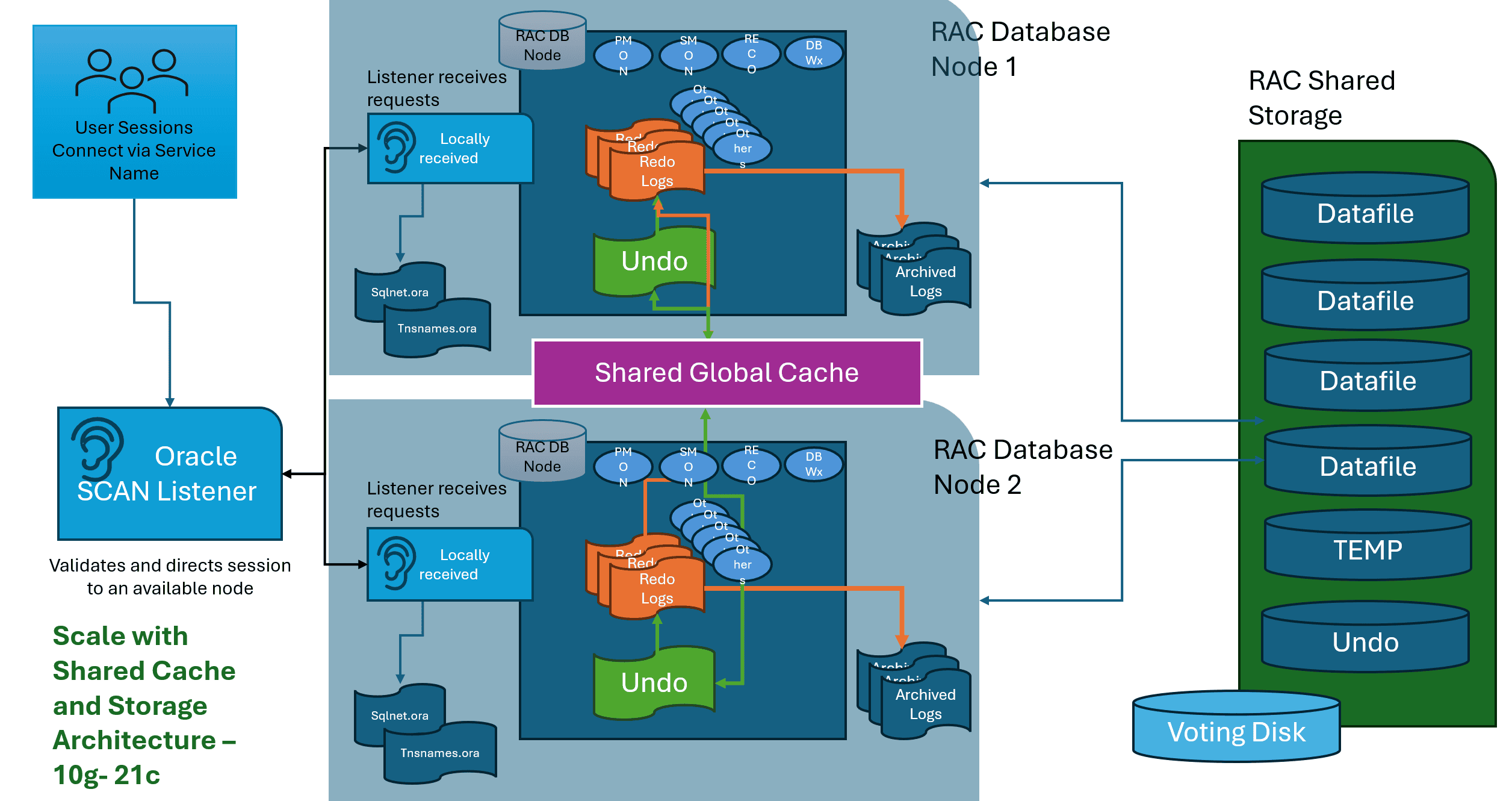
A RAC database via RMAN, can produce a single backup and perform point in time recoveries and if the application is “RAC aware” can even restart a process on an available node if one node fails. RAC is not a true high availability solution, as it does have shared storage and all nodes reside in the same data center, which means if there is a power outage, the database will still suffer downtime. Oracle DBAs still embrace RAC as part of their high availability solution for its ability to offer instance resiliency due to the ability to recover if there are one or more database node failures.
User sessions connecting to a RAC instance, in single instance or multitenant, will connect via a scan listener, which will have multiple port configurations, directing the process to a dedicated node per service, or a round-robin availability choice. There are both automatic and resource managed isolation that can be configured as part of a scan listener administration.
For true high availability, Oracle has two other solutions, Oracle Data Guard and Oracle Goldengate, which we’ll dig into this farther into the documentation. For those in the SQL Server world, it’s best to consider Oracle Data Guard as very similar to Always-on Availability Groups and Oracle Goldengate as similar to log replication, but again, we’ll dig into that later on.
Oracle Networking
In each of the architecture diagrams, user sessions have been clearly displayed as connecting via the Oracle Listener, but what is it?
The Oracle listener is a separate utility and process in Oracle. It is configured as part of the NETCA, (Network Configuration Assistant) and is either done at the time of the installation, database creation or on its own. A listener can be 1:1 with a database or shared across databases.
Configuration information is dynamic to the Listener, but in older versions, a listener.ora file contained the configuration information in a flat file format.
Two of three common secondary files that are configured as part of the network configuration for the Listener are:
sqlnet.oratnsnames.ora
The SQLNET.ora file consists of connection configuration for timeouts, packet sizes, advanced security, wallet location, etc.
The TNSNAMES.ora is the transparent network substrate file, which has connection information for each service, including databases. Each connection string will consist of the following for each of the databases:
- Alias identifier, (can be anything, so multiple entries for the same database can exist in a single file)
- service name (SID for older databases)
- host name
- port
- type of connection (TCP, EZConnect, etc.)
These files are in the $ORACLE_HOME/network/admin directory. If not there, check for a global file that may be using a $TNS_ADMIN environment variable.
The TNS file can be promoted from older installations, some back to Oracle 8, so older files hopefully have been cleaned up from the early days when this file was manually edited.
There are other files that may be present in this the $ORACLE_HOME/network/admin directory:
listener.oracman.ora
The LISTENER.ora file was the predecessor to the dynamically configured listener and contained all configuration information for the Oracle Listener. The CMAN.ora is used for the Oracle connection manager for logging configuration.
Managing the Oracle Listener
To check of the listener is running, you can check its status with the following command:
|
1 |
lsnrctl status |
To check what databases (services) are supported by the listener, the following command will return all information about each one the listener is managing:
|
1 |
lsnrctl services |
to stop or to start a single listener:
|
1 |
lsnrctl stop/start |
If there are multiple listeners on an ORACLE_HOME, (software installation) then the listener name must be supplied as part of any command:
|
1 |
lsnrctl <listener name> stop |
Just as with other Oracle utilities, the environment must be set for the above command to complete successfully.
Oracle’s Next Level, Globally Distributed Databases
I touched on the limitations of Oracle single instance and RAC as part of this discussion. With the introduction of the cloud, Oracle needed to find a way to span across multiple datacenters and the globe, not just a single datacenter.
As with MongoDB, CosmosDB and PostgreSQL hyperscale clustering, Oracle has its own globally distributed database, formerly known as Oracle Sharded Database. This architecture can shard data across multiple nodes and even replicate data one different nodes to offer high availability when one node is unavailable.
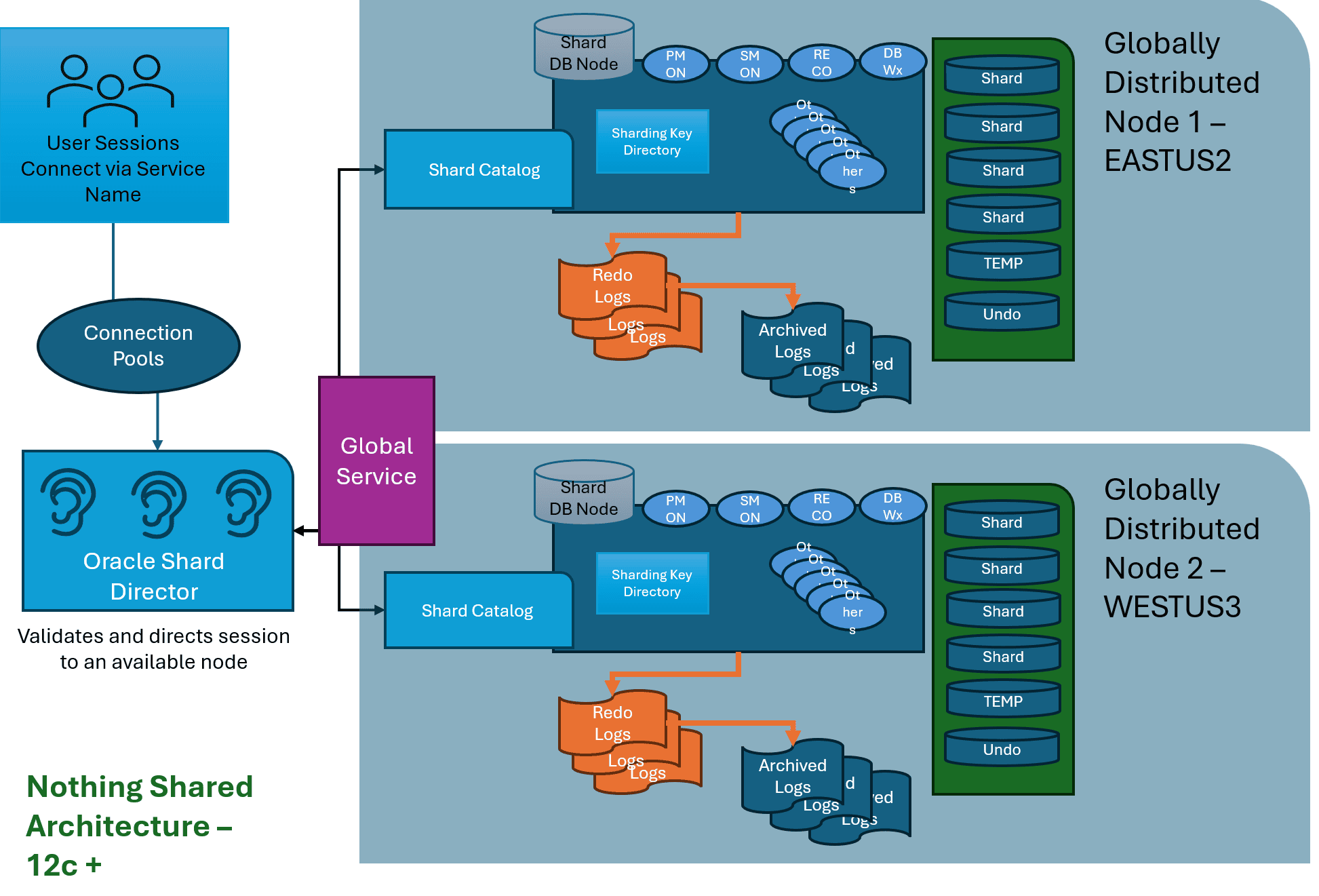
Unlike the other architectures demonstrated here, an Oracle globally distributed database doesn’t use a dedicated Listener, but multiple listeners that are part of the Oracle Shard Director. It connects to the Global Service that directs user requests, along with the Shard catalog, to the correct node and shard or shards to satisfy the request.
Per information over recent months, there is speculation that Globally Distributed Database architecture may very well replace both Oracle RAC and Oracle Data Guard as the defacto high availability solution for Oracle in tomorrow’s world. It is infinitely scalable, has both high availability and disaster recovery architected into the solution, and along with Oracle’s automatic process for sharding data, this could revolutionize this very resource heavy challenge to sharding existing Oracle databases.
High Level Checking Services/SIDs
There’s a high-level utility for TNS connections included with the Oracle Network products, called TNSPING.
|
1 |
tnsping <service/sid name> |
Example output is shown below. Notice that the utility identifies the sqlnet.ora/tnsnames file location, (if used for the tnsnames) as part of the utility check.
|
1 |
tnsping FREE |
Example output:
TNS Ping Utility for Linux: Version 23.0.0.0.0 - Production on 12-NOV-2024 00:56:14
Copyright (c) 1997, 2024, Oracle. All rights reserved.
Used parameter files:
/opt/oracle/product/23ai/dbhomeFree/network/admin/sqlnet.ora
Used TNSNAMES adapter to resolve the alias
Attempting to contact (DESCRIPTION = (ADDRESS = (PROTOCOL = TCP)(HOST = 0.0.0.0)(PORT = 1521)) (CONNECT_DATA = (SERVER = DEDICATED) (SERVICE_NAME = FREE)))
OK (0 msec)
The output clearly shows the host, port, service and configuration used. This doesn’t mean you are guaranteed to connect. What this signifies is that there is a listener that is listening and can ping this service and it responds OK.
V$Views and Environments
There are considerable internal views that are accessible, residing over the data dictionary metadata providing detailed information about everything in Oracle. Some of these views are free, some require additional licensing.
Reference Page: https://docs.oracle.com/en/database/oracle/oracle-database/21/refrn/static-data-dictionary-view-descriptions.html
Free views that can be used:
- DBA_* – DBA Data View
- ALL_* – All Data View
- USER_* – Schema Level/User Level
- V$_ – Dynamic Performance, Single Instance Views
- GV$_ – RAC Database Global Views
- CDB_* – CDB Views
- PDB_* – PDB Views
- RC_ * – RMAN backup views
Additional Licensed views are:
- DBA_HIST* – AWR/ASH history from V$ data
- AWR_* – AWR specific Data
The above views require the diagnostic and tuning management pack to be licensed for each database, (not a global license, but per database.)
Understanding Oracle Internal Terminology
Understanding Oracle terminology and how it may not translate from other database platforms is important.
A SINGLE Oracle instance (not Multitenant) is the:
- Service
- Background processes
- Memory allocation for the database
At the command line, this is how to start an Oracle instance once the environment has been set:
|
1 |
startup nomount; |
In this command, we haven’t started the database, and we haven’t mounted any of the files connected to the database. Only the service, the initial background processes and the memory for the database have been started.
We can then mount the Oracle database files:
|
1 |
alter database mount; |
This will initialize the controlfiles, the datafiles and redo logs. All must be present and synchronized with the controlfiles.
At the last step, we can then choose to open the database or set it up as a secondary for disaster recovery or replication, etc., but for this example, we’ll simply open the database:
|
1 |
alter database open; |
The database is now in an open state and is ready for receive process requests from directed from the listener or direct connections.
Background Processes
Reference Page: https://docs.oracle.com/en/database/oracle/oracle-database/21/refrn/background-processes.html
Oracle requires certain background processes to be up and running for an Oracle instance to run. These processes:
- PMON – Process Monitor
- SMON – System Monitor
- RECO – Recovery Monitor
- LGWR – Log Writer
- DBWR – DB Writer
There are significant number of other background processes, that if killed inadvertently or intentionally, will simply reinitiate and continue, but ones like the SMON or PMON, when killed, will crash the database.
Performance data for the Automatic Workload Repository (AWR) and Active Session History (ASH) have their own background processes and memory allocation buffer. The processes:
- MMON – AWR Monitor
- MMNL – MMON Lite for ASH
Locating Processes for Oracle Internally
The following query can locate processes and the OS process from inside Oracle:
|
1 2 3 |
select pname, spid from v$process where pname like '%SMON%'; |
Example output:
PNAME SPID
----- ------------------------
SMON 87
From the OS Level Command:
|
1 |
ps -ef | grep 87 |
Example output:
oracle 87 1 0 Nov11 ? 00:00:00 db_smon_FREE
As you can see, the command from inside Oracle to locate the SMON process matches what is seen in the ps (process) command at the Linux command line. The master process for the Oracle database is 1, with the child process for the SMON for the PDB is #87, which matches both commands.
Memory Allocation in Oracle
There are two main memory areas in Oracle that are used to perform all memory tasks.
The SGA
The System Global Area (SGA) is the main memory allocation for Oracle. It is comprised of segmented memory management to address the specific needs of the RDBMS.
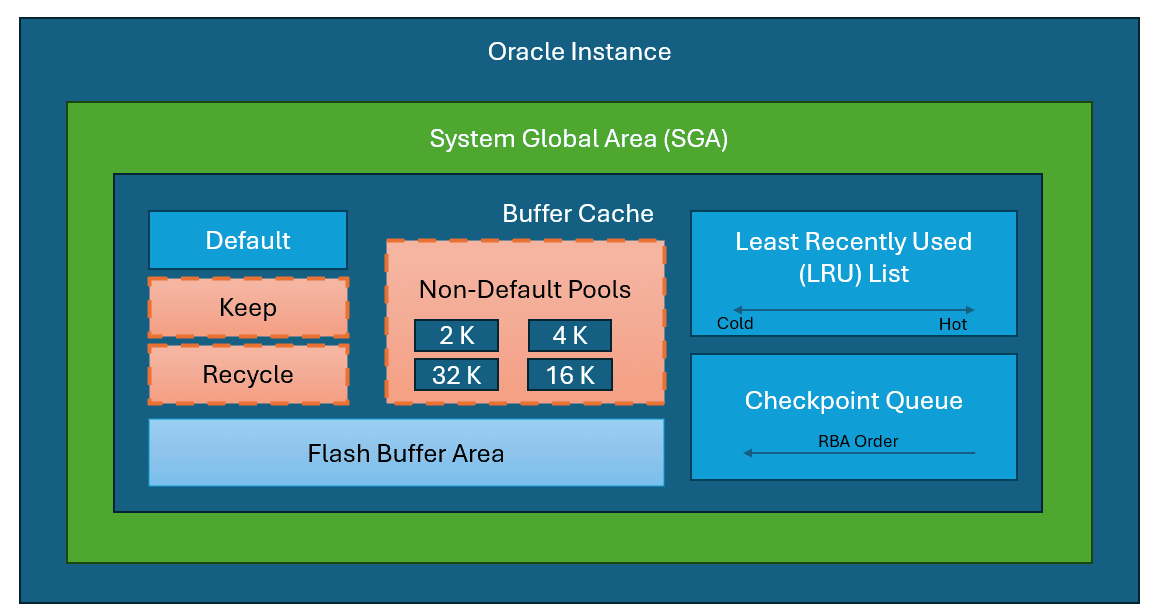
The database buffer cache, part of the system global area (SGA), is shared memory that stores data blocks read from data files to minimize disk I/O and keep frequently accessed blocks accessible. When a user requests data, the system first searches the buffer cache; a cache hit allows direct memory access, while a cache miss loads the data from disk.
Buffers in the cache are managed using an LRU algorithm to prioritize frequently accessed blocks, minimizing disk access. The buffer cache can be divided into pools:
- Default Pool: Stores blocks by default, with an 8 KB block size.
- Keep Pool (Optional): Retains frequently accessed blocks to reduce I/O operations.
- Recycle Pool (Optional): Holds infrequently accessed blocks to conserve space.
- Nondefault Pools (Optional): Accommodates blocks with non-standard sizes (e.g., 2 KB, 4 KB).
There is one more cache which isn’t included in the diagram, called the Database Smart Flash Cache (Optional) extends the buffer cache using flash memory, which stores frequently accessed blocks for faster retrieval than disk. When enabled, the flash cache stores clean buffers evicted from main memory, using its own LRU chains (DEFAULT and KEEP) to manage these entries.
Flash cache buffers are consistent across RAC nodes through Oracle RAC Cache Fusion, and dirty buffers are excluded from flash cache as they must undergo checkpointing in main memory.
There are other areas of memory, aka pools that should be mentioned:
- Java Pool – Handles Java calls
- Streams Pool – Oracle Streams
- Fixed SGA – Fixed tables in Oracle
- Large Pool – Response Queues
- Shared Pool
- Library Cache
- Shared SQL Area
- Private SQL Area
- Data Dictionary Cache
- Server Result Cace
- Reserved Pool
There is also the REDO Log Buffer that is part of the memory allocation in the database instance that is running as part of the Oracle database. These various memory areas each manage specific demands on the Oracle database.
The PGA
The Program Global Area (PGA) is non-shared memory outside of the SGA. PGA is sized as a TARGET, with a max allocation that was only implemented in recent years.
PGA handles sorting, hashing and PL/SQL table work in Oracle. The Oracle optimizer can calculate the amount of sorting and hashing that is required of any step in an execution plan and due to poor statistics or other changes, the allocation isn’t correct, the process will “swap” to the TEMP tablespace for anything over the memory in the PGA allocated. The goal is to perform as much sorting and hashing inside of the PGA, as memory is much faster than the TEMP tablespace, which is on disk and much slower.
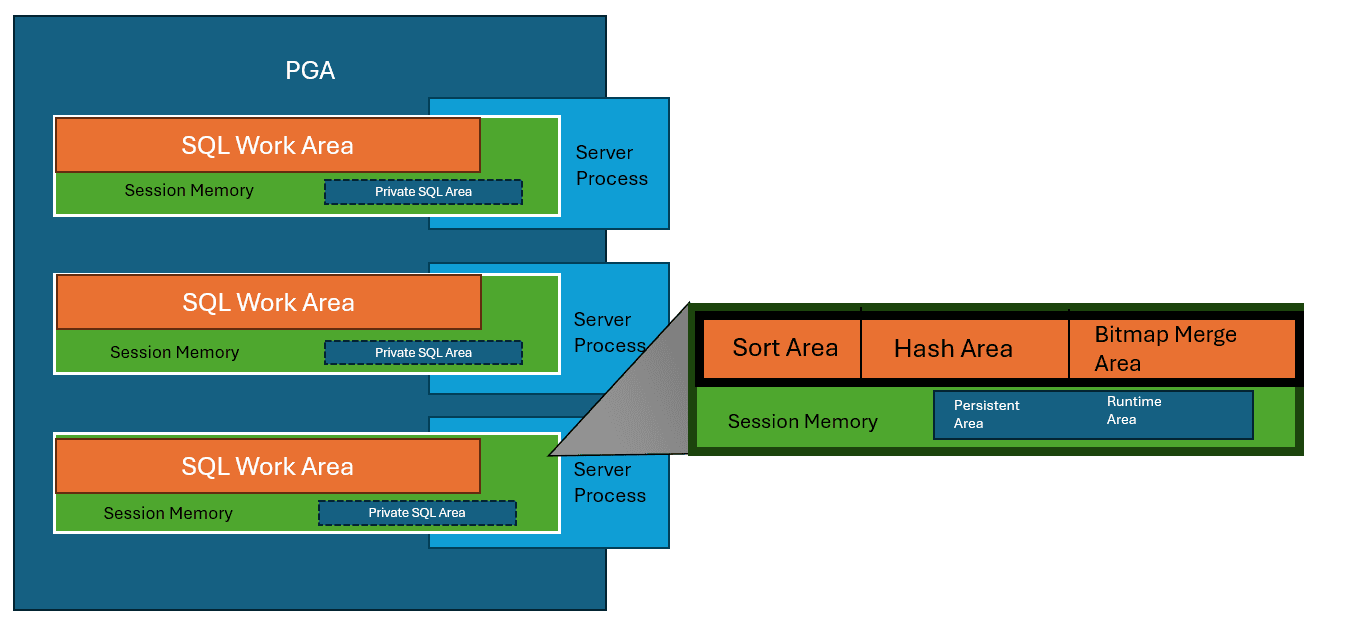
The PGA cache hit is based off how many times the PGA allocation was not enough to perform a task and had to go to TEMP to complete, (passes). DBAs use this cache hit percentage to determine if optimization is required of SQL, stats or PGA sizing.
The UGA
The User Global Area (UGA) is memory allocated for session variable information, such as logons and database sessions, including session state. It handles the PL/SQL session information and isolates it from other UGA processes, including OLAP page pools. It is only available during the life of a user session and is only part of the SGA when using a shared server connection configuration.
Datafiles in Oracle
Now that we’ve covered the database instance and memory, it’s time to cover the physical files in Oracle. Oracle data is broken down by the following:
- Byte
- Block
- Extent
- Segment
- Tablespace
- Datafile
Reversing this, you can then understand what you are viewing when you look at physical datafiles. Other physical files are:
- the
temptablespace (which is a workspace tablespace) - the
UNDOtablespace to retain undo processing - the redo logs, multiple members as part of groups which holds the changes not yet written to the datafiles.
Controlfiles, which keep track of configurations, sequential change number (SCN) tracking the state of the database and all other pertinent data.
Secondary files that are important:
SPFILE.ora, has all configuration information and used to start the database instance. This file is retained in the$ORACLE_HOME/dbsdirectory. It is backed up to a text version called theinit<sid>.orafile.PWD<sid>.orafile configures local and remote connections to the database and is created with theorapwdutility
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved




Load comments