
In the first two articles in this series we listed a couple of methods for generating or retrieving execution plans and learned a few extra steps that could increase our confidence that we were using the right environment to investigate any problems we might have with a plan. In this article we’re going to become acquainted with a basic (though, as we will see in part 5, incomplete) guideline for interpreting the overall shape of the plan. We won’t worry about the use of the predicate section until we get to part 4.
The shape of a plan
We’ll start with a simple example – building a couple of tables, joining them, and then reviewing the questions we need answered when we examine an execution plan. So here’s the data creation script:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
create table t1 as with generator as ( select --+ materialize rownum id from dual connect by level <= 1e4 ) select rownum id, mod(rownum,1000) n_1000, lpad(rownum,6,'0') v1, rpad('x',100,'x') padding from generator ; alter table t1 add constraint t1_pk primary key(id); create index t1_i1 on t1(n_1000); begin dbms_stats.gather_table_stats( ownname => user, tabname =>'T1', method_opt => 'for all columns size 1' ); end; / |
I’ve created a table t2 in exactly the same way – so I won’t repeat the code. I’m going to use explain plan with a simple “literal string” SQL statement as my first example to introduce a couple of points about execution plans.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
explain plan for select t1.v1, t2.v1 from t1, t2 where t1.n_1000 = 1 and t2.id = t1.id and t2.n_1000 = 100 ; select * from table(dbms_xplan.display); select id, parent_id, position, depth, level – 1 old_depth, rpad(' ',level - 1) || operation || ' ' || lower(options) || ' ' || object_name text_line from plan_table start with id = 0 connect by parent_id = prior id order siblings by id, position ; |
I’ve used two different methods for producing the execution plan – a basic call to dbms_xplan.display(), and a simplified version of the type of query we used to use on the plan table in version 9 and earlier. Here are the two sets of results:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
-------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | -------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 10 | 300 | 22 (0)| 00:00:01 | |* 1 | HASH JOIN | | 10 | 300 | 22 (0)| 00:00:01 | | 2 | TABLE ACCESS BY INDEX ROWID| T1 | 10 | 150 | 11 (0)| 00:00:01 | |* 3 | INDEX RANGE SCAN | T1_I1 | 10 | | 1 (0)| 00:00:01 | | 4 | TABLE ACCESS BY INDEX ROWID| T2 | 10 | 150 | 11 (0)| 00:00:01 | |* 5 | INDEX RANGE SCAN | T2_I1 | 10 | | 1 (0)| 00:00:01 | -------------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 1 - access("T2"."ID"="T1"."ID") 3 - access("T1"."N_1000"=1) 5 - access("T2"."N_1000"=100) Id Par Pos DEPTH OLD_DEPTH TEXT_LINE ---- ---- ---- ----- --------- -------------------------------------------------- 0 22 0 0 SELECT STATEMENT 1 0 1 1 1 HASH JOIN 2 1 1 2 2 TABLE ACCESS by index rowid T1 3 2 1 3 3 INDEX range scan T1_I1 4 1 2 2 2 TABLE ACCESS by index rowid T2 5 4 1 3 3 INDEX range scan T2_I1 |
The reason I’ve included the old-style approach to reporting an execution plan is to allow you to connect the visual presentation with some of the details in the plan table that are hidden by the modern approach. We always see execution plans with some sort of pattern of indentation, and this pattern is supposed to tell us something about the relationship between operations in the plan. What it’s showing us is a visual impression of the relationship between the id, the parent_id, and the position columns.
Each operation in the plan has an id; this actually tells us the order in which lines should be reported. Each line may be the parent of one or more “child” operations, and the parent_id column of each line will hold the id of its parent. In this example we see that lines 2 and 4 both have line 1 as their parent. Where a line has several child operations the position column will list the order of child operation within parent; looking again at lines 2 and 4 we see that line 2 is the first child of line 1, and line 4 is the second child of line 1. In the dbms_xplan presentation of an execution plan we don’t see the parent_id and position columns, we have to infer the parent/child relationships from the ordering and indentation of the various operations.
Listing the lines in order of id has always given us the correct order of presentation of the plan (which is NOT the same as the order in which data is acquired and manipulated); but the method for calculating the level of indentation changed between 9i and 10g. Historically the derived column level from the hierarchical connect by query allowed us to add a suitably sized indent to the text – but when Oracle allowed us to access the in-memory version of execution plans (v$sql_plan) this coding strategy turned out to be horrendously inefficient so a pre-calculated level column (differing by 1 from the level, and called depth) was included in the dynamic performance view, and eventually added to the plan table, with its value being derived at the time of optimization. (Unfortunately there are still a few cases – even in 12c – where the generated value is incorrect so it’s worth remembering how to write the connect by query.)
First Rule for Reading Plans
We’re going to ignore the predicate section in this article – even though it’s a very important part of an execution plan – and focus on how to walk through the body of the execution plan to understand the order in which Oracle will acquire and manipulate data.
Each line of a plan represents an operation that generates a set of “rows” – called a “rowsource”. I have put the word rows in quotes because, for example, a “row” may be nothing more than a rowid fetched from an index. An operation takes some action to generate a rowsource and passes the rowsource to its parent. If a parent operation has multiple child operations, it will (optionally) call each of its children in turn to supply a rowsource and then do some work to combine those rowsources. One of the most important things you have to learn is what each operation does, and what it means for that operation to “combine” rowsources. There’s also the slight complication that although a parent calls its children “in turn”, it may call each child more than once, and the way in which the repeated calls are made varies with parent operation.
Inevitably this description doesn’t cover all the variations and anomalies, but if we ignore the special cases for a while the basic method for reading execution plans can be summed up in the soundbite: “first child first, recursive descent”. Let’s take a look at the plan for the hash join above to see how this works.
Line zero tells us that we have a select statement. To generate the rowsource for this select statement we have to identify its children and operate them in order. The old-style code for reporting an execution plan tells us that line 1 is the first (and only) child of line 0. But if we didn’t have the parent_id and position to help us we could use the visual approach: the first child of an operation is the next line in the plan (and it will be indented one step), and you can find any subsequent children – in order – from there by dropping a vertical line and picking up any lines at the same indentation until you hit the bottom of the plan or a line that has moved back towards the left margin.
Line 1 reports a hash join operation and at this point we may need to look at the manuals to discover what a hash join is, and how it works, before we start looking for the child operations – conveniently some of the graphic tools for generating execution plans will have a pop-up, or hover, option if you need to check. Again the old-style report makes it easy to see that lines 2 and 4 are the children of the hash join operation while the visual approach tells us that line 2 is the first child and a vertical drop from line 2 hits the T of “table access” at line 4, identifying it as the second child. This is enough information to tell us that we’re going to build an in-memory hash table from some rows from t1 (first child) and probe that hash table with rows from t2 (second child) to find matches then, when we find a match, construct a result row and return it to line zero (the parent of line 1). The serial hash join is a good example of why we have to consider the children in order – the physical ordering in the plan tells us which table is the build table and which the probe.
It’s worth noting at this point that we don’t yet know (or care) how we manage to identify the rows from t1 and t2 – all we’ve done is pick out part of the plan at the highest level as an initial step in understanding the total work load. We haven’t yet got to a point where we can say: “this is the first data set that Oracle acquires / this is the first table that Oracle visits”. But we can get to that point by repeating the approach we’ve taken so far.
We’re going to build an in-memory hash table with the rowsource from line 2, and probe the hash table with the rowsource from line 4; so let’s examine the first child first. Starting from line 2 we can identify the entire “sub-plan” whose end-product is the rowsource we need; here it is:
|
1 2 3 4 5 6 |
-------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | -------------------------------------------------------------------------------------- | 2 | TABLE ACCESS BY INDEX ROWID| T1 | 10 | 150 | 11 (0)| 00:00:01 | |* 3 | INDEX RANGE SCAN | T1_I1 | 10 | | 1 (0)| 00:00:01 | -------------------------------------------------------------------------------------- |
Viewed in isolation we can see that line 2 has a single child to call, and the operation in that child is an index range scan. Conveniently we realize that the rowsource produced from an index range scan is likely to contain rowids, and that line 2 is doing a table access by rowid – sanity checks like this that compare the demands of the parent with the supply from the child are very useful when trying to understand more subtle execution plans.
Similarly we can look at the sub-plan that delivers the rowsource for line 4
|
1 2 3 4 5 6 |
-------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | -------------------------------------------------------------------------------------- | 4 | TABLE ACCESS BY INDEX ROWID| T2 | 10 | 150 | 11 (0)| 00:00:01 | |* 5 | INDEX RANGE SCAN | T2_I1 | 10 | | 1 (0)| 00:00:01 | -------------------------------------------------------------------------------------- |
Again we see it’s a very simple plan, we call line 5 to do an index range scan that supplies the rowids that we use to visit the table in line 4.
Putting all the pieces together we can number the steps of the plan as follows:
|
1 2 3 4 5 6 7 8 9 10 |
------------------------------------------------------ | Id | Operation | Name | Order | ------------------------------------------------------ | 0 | SELECT STATEMENT | | 6 | |* 1 | HASH JOIN | | 5 | | 2 | TABLE ACCESS BY INDEX ROWID| T1 | 2 | |* 3 | INDEX RANGE SCAN | T1_I1 | 1 | | 4 | TABLE ACCESS BY INDEX ROWID| T2 | 4 | |* 5 | INDEX RANGE SCAN | T2_I1 | 3 | ------------------------------------------------------ |
We read the plan as follows:
- Line 0 calls line 1 (first child)
- Line 1 calls line 2 (first_child)
- Line 2 calls line 3 (first child)
- Line 3 produces a row source – the first line to do so – by doing an index range scan, and passes it up to line 2
- Line 2 uses the rowids to visit table t1 producing a rowsource – the second line to do so – of columns from table t1 and passes if up to line 1
- Line 1 uses the rowsource to build an in-memory hash table (no new rowsource produced yet), then calls line 4 (second child) to start supplying a rowsource that can be used as the probe table.
- Line 4 calls line 5 (first child)
- Line 5 produces a row source – the third line to do so – by doing an index range scan, and passes it up to line 4
- Line 4 uses the rowids to visit table t2 producing a rowsource – the fourth line to do so – of columns from table t2 and passes if up to line 1
- Line 1 probes the in-memory hash table, looking for matches, producing the fifth rowsource from any survivors, and passing them up to line 0 – which passes the result to the client program.
There’s more to the plan than this – in particular we need to think a little more about the detailed timing of operations: some are “bulk”-processing some are “single row”-processing; and we need to bring in the predicate section and consider the relevance of the terms “access” and “filter”; and those details are what we’ll be looking at in the next article.
Closing thoughts
I’d like to emphasize the convenience of breaking complex execution plans down into simple pieces. Our example was so small that the potential benefit of handling it in pieces wasn’t obvious; but think about how we took the whole plan, picked out the high-level view from the first few lines, and then examined a couple of sub-plans. We can do this with any plan, no matter how complex it seems to be, and examine small sections of a plan in isolation.
Most (if not all) the various graphic tools that you can get to display execution plans help us in this approach; here, for example is a partial screenshot from an OEM display showing the execution plan from 11.2.0.4 for the query:
|
1 2 3 4 5 6 7 8 |
select owner, object_type, count(*) from dba_objects group by owner, object_type order by owner, object_type |
Note particularly the little triangular markers holding the minus signs at the left hand end of each line of the plan:
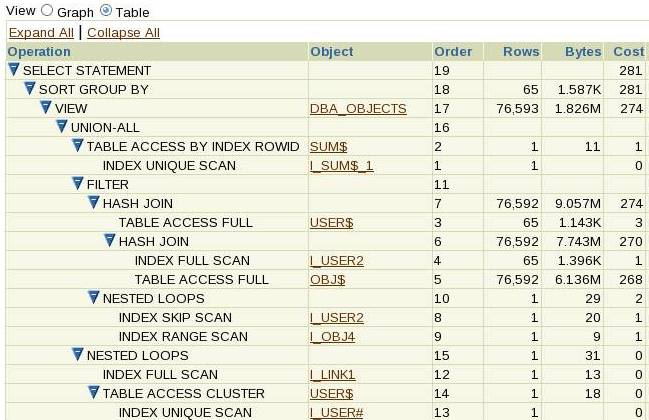
Descending through the first child rule, we see that it’s a select statement, that calls a sort group by, that calls a view (we’ll discuss that operation in a future article), that calls a union-all that has three children that we will have to call in order. Click on the minus by the union-all and all its children and their descendants disappear, and the minus will turn to a plus; click on the plus and its child lines will re-appear (without their descendants), giving us this:
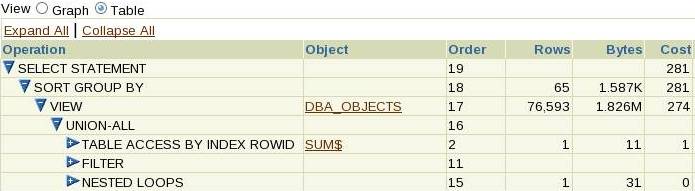
We have the big picture of the execution plan – we can now decide to look at the three pieces separately; for example we could expand out the filter operation, ignoring the table access above it and the nested loops below:
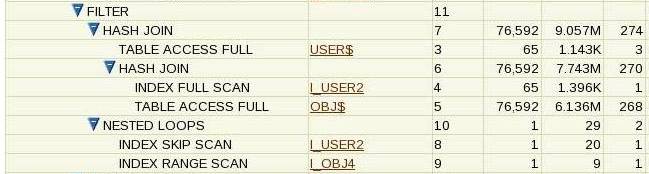
Any time we think an execution plan is intimidating, we can pick (fairly arbitrary) pieces of it to examine, then hide them once we understand what they do. A comment I often make in my seminar on execution plans is that “there are no hard plans, there are only long plans”. Once you’ve grasped the significance of “first child first” you realize that the “first child” can be a single line in its own right, or a one-line summary of an entire sub-plan that you can understand and then hide while you concentrate on some other part of the plan.
Load comments