
Apache Cassandra database is a distributed, fault tolerant, linearly scalable, column-oriented, NoSQL database. Apache Cassandra is great at handling massive amounts of structured (table has defined columns), and semi-structured (table row doesn’t need to populate all columns) data. Cassandra is a distributed storage system that is designed to scale linearly with the addition of commodity servers, with no single point of failure. Cassandra can be easily scaled across multiple data centers (and regions) to increase the resiliency of the system.
Features of Cassandra
- Open Source – It is an open source project by Apache. Cassandra can be integrated with other source projects like Hadoop, Apache Pig, Apache Hive, etc.
- Peer-to-Peer Architecture – All nodes in the Cassandra cluster communicate with each other. There is no master-slave paradigm in Cassandra.
- No Single point of Failure – In a cluster, all nodes are created equal. Data is distributed across the nodes in the cluster and each node is capable of handling read and write requests.
- Highly Available and Fault Tolerant – Because of data replication across the nodes in the cluster, Cassandra is highly available and fault tolerant.
- Globally distributed – A Cassandra cluster may be deployed in multiple data centers, which may be globally distributed.
- Flexible Data Model – The concepts from DynamoDB and BigTable are built into Cassandra to allow for complex data structures. The model works for a wide variety of data modeling use cases.
- Linearly Scalable – When new nodes are added, the data is more evenly distributed across the nodes, which reduces the load each node handles.
- Tunable Consistency – Consistency level is number of nodes needed to agree on the data for reads and writes. The consistency level controls both read and write behavior based on your replication factor. The Consistency level could be zero, one, quorum, local quorum or all.
Layers of a Cassandra Cluster
- Cluster – Cassandra Cluster is a collection of nodes in a ring format that work together. It can span multiple physical locations. Data is distributed across nodes in the cluster using consistent hashing-based function.
- Node -Node is the basic infrastructure component of Cassandra and it’s where the data is stored. Each node contains a data replica.
- Keyspace – Keyspace is a collection of column families and is equivalent to a database in RDBMS. The definition of keyspace contains Replication factor, Replication strategy (simple or network topology) and Column families.
- Column Family – Column family is a container of a collection of rows. This is equivalent to a table in RDBMS.
- Row – Each row in Cassandra is identified by a unique key and each row can have different columns. The row key is a unique string and there is no limit on its size.
- Column– Each Column is a construct that has a name, a value and a user-defined timestamp with it. Each row can have a variable number of columns.
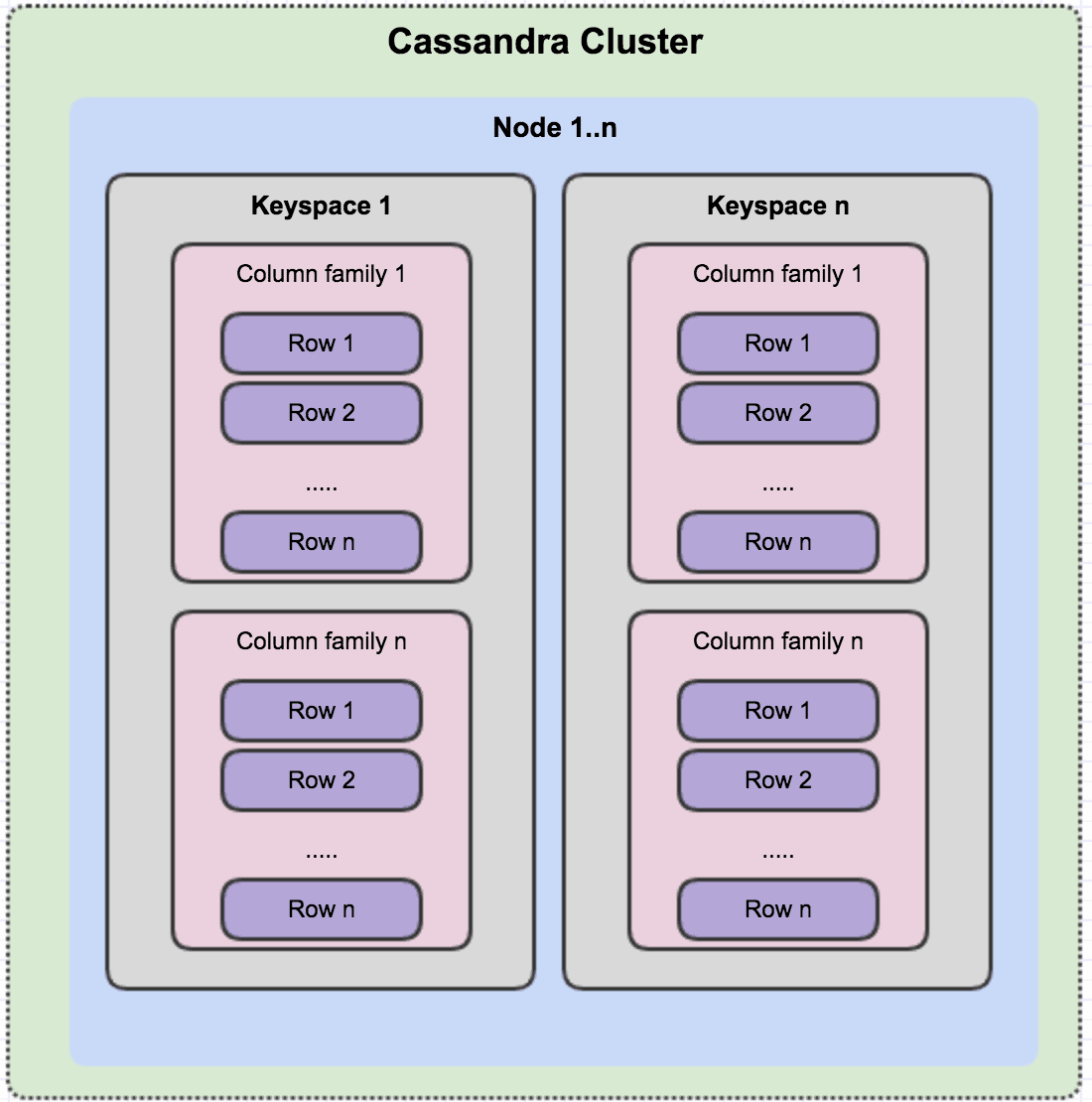
Layers of a Casandra Cluster
Cassandra Cluster in a Single DC
The client request is received by a coordinator node (any node in the cluster can be selected as a coordinator). The coordinator finds the node which has the matching token range and persists data in that node. The data is replicated to other nodes in the cluster based on the Replication Factor defined in the keyspace. If you choose the SimpleStrategy, it just selects consecutive nodes in the ring for replication.
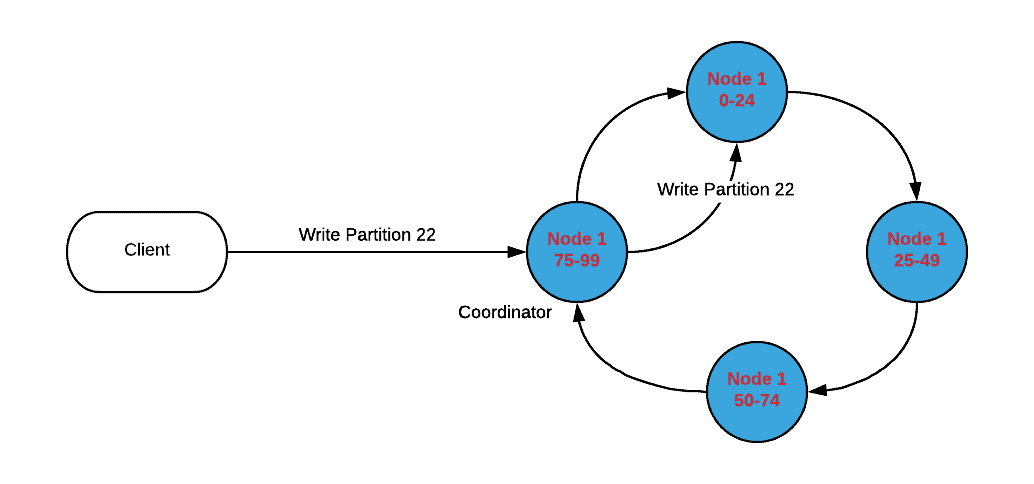
Single DC
Cassandra Cluster in Multi-DC
In Multi-data center replication, you need to define the number of replications per DC and Cassandra will replicate accordingly. NetworkTopologyStrategy is used as replication strategy for multi-DC replication.
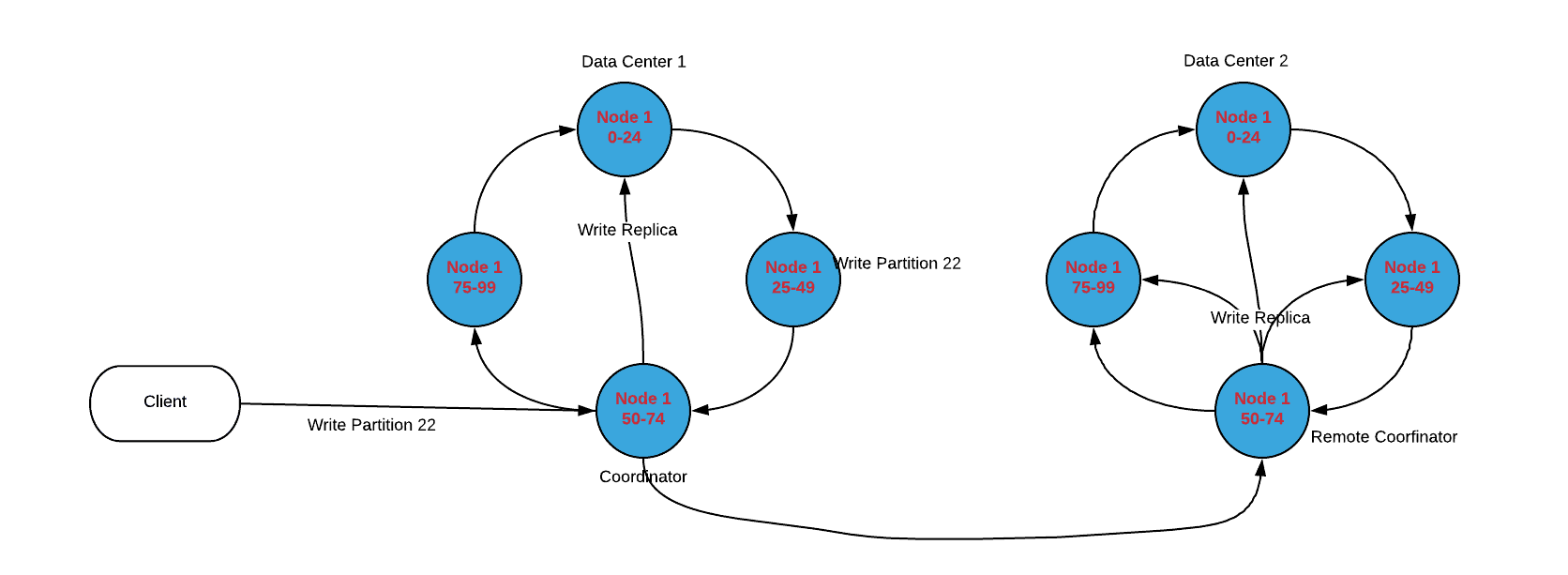
Multi-data center
Is Cassandra the Right Choice for Your Application Workload?
Before using Cassandra as a database for your application, you may need to evaluate whether Cassandra database is the right choice for your application needs. Writes are very fast in Cassandra due to the log-structured design, and written data is persisted with a Commit Log and then relayed to Memtable and SSTables(Sorted String Tables).
- Commit Log – When data is written to the Cassandra node, the data is stored in in-memory cache, the Memtable, and also appends writes to commit log.
- Memtable – Memtable is an in-memory cache that holds data rows before they are flushed to SSTable. For a given Column Family, usually there exists one Memtable.
- SSTable – SSTable is a file that stores a set of immutable data rows (key-value) sorted by row key. When Memtable data is flushed, a new SSTable is created.
Cassandra database is a good choice for the following use cases:
- Very high write throughput and a smaller number of reads.
- Ability to linearly scale the database by adding commodity servers.
- Multi-region and multi-data center replication.
- Ability to set Time-to-live time on each record row.
Cassandra isn’t a good choice for following use cases:
- Application needs ACID properties from a database.
- Application needs Joins (JOIN is not supported in Cassandra).
- Application needs many secondary indexes. Secondary indexes degrade query performance.
- Queue like designs: Writing and then deleting data at scale results in large number of tombstones, which degrades the performance. Instead use native queueing technologies such as ActiveMQ, RabbitMQ, Kafka, etc.
- If your application needs very high read concurrency, then MongoDB may be a better choice
The Cassandra Data Model
The Cassandra data model and on disk storage are inspired by Google Big Table and the distributed cluster is inspired by Amazon’s Dynamo key-value store. Cassandra’s flexible data model makes it well suited for write-heavy applications.
Cassandra Data Modeling – Best Practices
Picking the right data model helps in enhancing the performance of the Cassandra cluster. In order to come up with a good data model, you need to identify all the queries your application will execute on Cassandra. You should model Cassandra data model around your queries, but not around objects or relations.
Choose the Proper Row Key
The critical part of Cassandra data modeling is to choose the right Row Key (Primary Key) for the column family. The first field in Primary Key is called the Partition Key and all other subsequent fields in primary key are called Clustering Keys.
The Partition Key is useful for locating the data in the node in a cluster, and the clustering key specifies the sorted order of the data within the selected partition. Selecting a proper partition key helps avoid overloading of any one node in a Cassandra cluster.
|
1 2 3 4 5 6 7 8 9 |
CREATE TABLE Employees ( emp_id uuid, first_name text, last_name text, email text, phone_num text, age int PRIMARY KEY (emp_id, email, last_name) ) |
Here the Primary Key has three fields: emp_id is the partition key, and email and last_name are clustering keys. Partitioning is done by emp_id and within that partition, rows are ordered by the email and last_name columns.
Determine queries first, then model it
In relational databases, the database schema is first created and then queries are created around the DB Schema. In Cassandra, schema design should be driven by the application queries.
Duplicate the data
In relational databases, data normalization is a best practice, but in Cassandra data duplication is encouraged to achieve read efficiency.
Garbage collector
Garbage collection (GC) is the process by which Java removes objects that don’t have any references in the heap memory. Garbage collection pauses (Stop-the-world events) can create latencies in read and write queries. There are two major types of garbage collection algorithms, G1 garbage collector and CMS (Concurrent Mark and Sweep) garbage collector. G1 GC gives better performance than CMS for large heap sizes but the tradeoff is longer GC times as better explained in this page. Choose right GC for your use case.
Keyspace replication strategy
Use SimpleStrategy for single data center replication. Use NetworkTopologyStrategy for multi-data center replication.
Payload
If your query response pay load size is over 20 MB, consider additional cache or change in query pattern. Cassandra is not great at handling larger payloads.
Cassandra Queries – Best Practices
There are several things to keep in mind when designing the queries:
Prepared statements
- Prepared statements are highly recommended when interacting with Cassandra as they remove overhead compared to simple Statements.
- Prepared statements get pre-compiled and cached. It is an optimization that allows parsing a query only once but execute it multiple times with different values.
- Don’t bind “null” values on prepared statements and don’t insert “null” values into a column value as both of these cases create tombstones.
Batch statements
- If you need atomicity, you may use batches. Make sure the statements in the batch have a minimal number of partitions. Ideally, use single partition batches from the same table and same partition key because they are executed faster than statements having multiple partition keys.
- Batching statements with different partition keys force the coordinator to scan across multiple nodes to find data, and this impacts query performance.
- Batch Size: Batching a large number of statements into a single batch will negatively impact the coordinator. Instead, split the statements into multiple batches. It is recommended to honor the batch size (batch_size_fail_threshold_in_kb) limit configured in the cassandra.yaml configuration file
- Batching too many statements into a single batch, may result in a runtime exception InvalidQueryException (com.datastax.driver.core.exceptions.InvalidQueryException: Batch too large.)
- Don’t use Batches for performance optimizations. Batches are never meant to improve performance.
ALLOW FILTERING in queries
- If possible, avoid ALLOW FILTERING in Cassandra queries as latencies will be high and performance will be impacted.
- When using Allow Filtering in queries, you may get warnings such as “xxx Statement have unpredictable performance.” When Allow Filtering is used, Cassandra skips over the data, rather than using an index to seek the data. Without Allow Filtering, the data read through scales linearly with the amount of data returned.
- Using Allow Filtering in queries is fine if you are returning most of the data fetched from the Column Family, but if you are skipping over most of the data, this will be a performance hit.
Indexing
- An index provides a means to access data in Cassandra using a non-partition key. You may reduce or avoid the usage of secondary indexes as they impact read and write performances.
- Use materialized views with automatic updates to make reads faster.
Decide on proper TTL
- In Cassandra, TTL (time-to-live) is set at a per column value but is not defined per row or column family. Once the TTL is set, it’s hard to change, and it’s also hard to update TTL for an existing row column(s). The only way you can change the TTL is to read the complete row and re-insert the row with a new TTL.
- If you run an update query on existing row with only few column updates (on already TTL set row), the life of these columns is extended by TTL time while other columns expire sooner. When you query, it’s possible to receive only a few columns data as other columns data might have already expired. To avoid this inconsistency, make sure you read the full row before updating to have consistent TTL on all columns.
Miscellaneous considerations
- Don’t range scan the Cassandra Column family. Scan the table only by a specific partition key for better performance.
- Lower or Disable retry policies. Speculative Retry and read_repair_chance is being deprecated in later versions of Cassandra. If the initial request fails, further requests will highly likely fail and thus cascade into wider issues.
- Use token aware in java driver. With this, the client maintains the token range and location of data, so the coordinator node doesn’t have to do this work on select queries.
- Querying too many tables at once can be expensive and increases the latency.
Summary
Strong understanding of Cassandra architecture and identification of all query patterns in advance help in creating an optimal data model in a Cassandra Cluster. This Article covered some of the use cases around when to use and when not to use Cassandra database. Also, several best practices and tips around how to create right Cassandra data model, and how to optimize queries to achieve better performance are covered.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments