

If you’re a developer who had interactions with indexes in the past, you certainly know that indexes in MySQL come in a variety of shapes and sizes. Simple Talk readers will certainly not be alien to the nuances of indexes within MySQL – as we’ve already covered B-tree indexes in MySQL, and some readers may even be aware of the powers granted to them by database management systems such as PostgreSQL, as it’s known to be one of the most prolific database management systems for indexes and data types alike.
While most of you may be aware of the power that B-tree indexes help you unleash, you may not be aware of specific types of indexes that exist but often remain behind the spotlight – these are PRIMARY KEY indexes.
What are PRIMARY KEY Indexes?
Beneath the hood, PRIMARY KEY indexes are still B-tree indexes in InnoDB, but they are subject to stricter constraints (NOT NULL, UNIQUE). They are essential to the table structure and are used constantly in foreign key relationships, clustering, and lookups.
The purpose of a primary key index is to uniquely identify rows in a table thus, they serve a special purpose. In InnoDB, it physically orders the table data by the primary key (clustered index).
In MySQL, one can add primary key indexes to a column when creating a table like so:
|
1 2 3 4 5 6 7 8 |
CREATE TABLE `demo_table` ( `id` INT PRIMARY KEY, `message` VARCHAR(120) NOT NULL DEFAULT ‘’, `sender` VARCHAR(120) NOT NULL DEFAULT ‘’, `receiver` VARCHAR(120) NOT NULL DEFAULT ‘’, `timestamp` TIMESTAMP NOT NULL, … ); |
Or when modifying a table like so:
|
1 |
ALTER TABLE `demo_table` ADD PRIMARY KEY(`id`); |
DBAs/developers don’t usually refer to primary keys as “primary key indexes” – a primary key is always an index, but most of the industry folks refer to primary keys as primary keys – not as primary index keys or primary indexes. Just primary keys.
Rules of PRIMARY KEY Indexes
A PRIMARY KEY in MySQL is a type of B-tree index that uniquely identifies each row in a table. However, unlike regular indexes, a primary key comes with special constraints and behaviors:
- A
PRIMARY KEYcolumn cannot containNULLvalues.
By definition, a primary key must beNOT NULLandUNIQUE. MySQL enforces this automatically, even if you don’t explicitly declare the column asNOT NULL. Any attempt to insert aNULLvalue into a primary key column will result in an error like so:
1ERROR 1048 (23000): Column ‘colname’ cannot be null AUTO_INCREMENTallows you to omit the value for the column by specifyingNULL—but does not storeNULLvalues.
When a column is defined withAUTO_INCREMENT, you can insert a row without providing a value for that column. If you explicitly insertNULL, MySQL treats it as a signal to generate the next sequence value. However, the stored value will never beNULL—it will be a generated number. This piece of SQL query would insert aNULLvalue into the id column of a table named demo:
1INSERT INTO `demo` (`id`) VALUES (NULL);PRIMARY KEYSare often, but not always, integers.
While it’s common to use an integer column withAUTO_INCREMENTas a primary key, MySQL supports other data types too. For example, you can define a VARCHAR or even aCHARcolumn as a primary key. The key requirement is that the values be unique and notNULL.- A table can have only one
PRIMARY KEY.
This is a rule of the relational model. A primary key represents the unique identifier for each row, and allowing more than one would violate that principle. However, other uniqueness constraints can be defined usingUNIQUEindexes. - A
PRIMARY KEYcan span multiple columns.
MySQL supports composite primary keys, where two or more columns together form a unique identifier. In such cases, no individual column is necessarily unique on its own, but the combination must be. - MySQL will create a primary key automatically in some cases.
Starting with MySQL 8.0.30, if you don’t define any primary or unique key, MySQL may generate a Generated Invisible Primary Key (GIPK) behind the scenes. These internal keys aren’t visible in the table definition, but they serve the purpose of uniquely identifying each row and can be referenced programmatically.
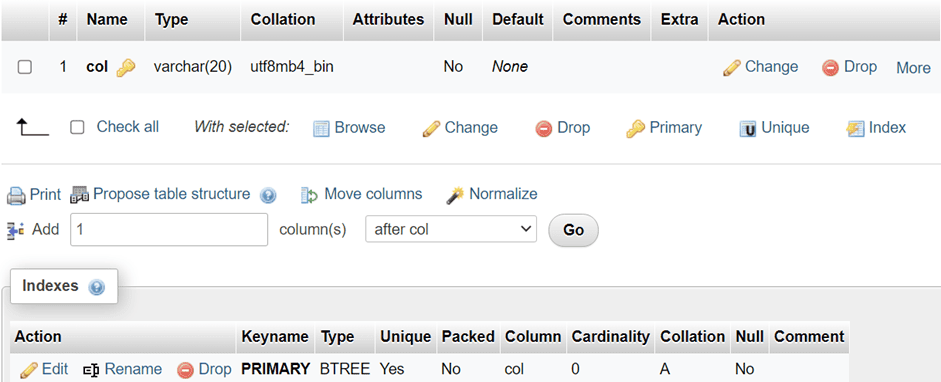

Working with PRIMARY KEYs
If there are no natural combinations of column values in the table that are unique, PRIMARY KEYs can be assigned that attributes that make them increment automatically and PKs having such attributes will be defined like so:
|
1 |
`column_title` INT PRIMARY KEY AUTO_INCREMENT |
Working with data inside of such columns isn’t hard – if we insert data, we need to insert NULL values into the column with a PK, or omit the PK column in the insert statement. This causes MySQL to insert the next available value from the auto-increment sequence.
Although inserting NULL will trigger AUTO_INCREMENT, it’s usually safer and clearer to omit the column entirely from your INSERT statement. Use NULL only if you’re relying on a feature like LAST_INSERT_ID(). Otherwise, you risk hitting errors like Duplicate entry ‘0’ for key 'PRIMARY', especially if a row with id = 0 was inserted before AUTO_INCREMENT was added. In such cases, MySQL may start the sequence at 1, but still encounter a conflict with the existing value. This is particularly common if the sql_mode setting treats 0 as a special value.

To solve this problem, we’ll have to define an auto_increment value and try again. This can be done through phpMyAdmin:
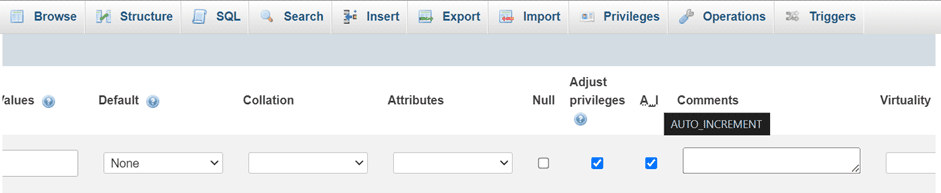
Or running a query like so:
|
1 |
ALTER TABLE `demo_table` CHANGE `id` `id` INT(11) NOT NULL AUTO_INCREMENT; |
Without moving far from here, I should also state that errors like the one related to duplicate entries in the third image can be avoided altogether if we specify an IGNORE clause in our SQL statement. The same statement written like so would ignore errors related to primary keys and insert the data regardless, which can be very useful if you need to insert the data for parsing or related operations:
|
1 2 |
LOAD DATA INFILE ‘C:/wamp64/tmp/data1/MOCK_DATA_1.csv’ IGNORE INTO TABLE `demo_table` FIELDS TERMINATED BY ‘,’ (message,sender,receiver,timestamp); |
However, IGNORE is not the cure to all of your problems. When running ALTER queries with auto_increment, you may also face errors such as:
|
1 2 |
ERROR 1062 (23000): ALTER TABLE causes auto_increment resequencing, resulting in duplicate entry '1' for key 'PRIMARY' |
This essentially says that one row already contains a value of “0”. This error typically arises because a value such as 0 or 1 was manually inserted before the AUTO_INCREMENT attribute was added. When MySQL attempts to re-sequence the column, it tries to begin from the lowest unused value — often 1 — and clashes with an existing row.
The fix is usually straightforward: delete or update the conflicting row, or explicitly set the starting point for auto-increment with a statement like ALTER TABLE demo_table AUTO_INCREMENT = 100. If the conflict involves 0, and it’s being treated as a request for an auto-generated value, setting sql_mode = 'NO_AUTO_VALUE_ON_ZERO' will restore clarity by ensuring that 0 is treated as a literal value.
To avoid this sort of error, run a query like SET SESSION sql_mode=' NO_AUTO_VALUE_ON_ZERO':

Using Primary Keys
Let’s now take a look into cases necessitating the usage of our primary keys:
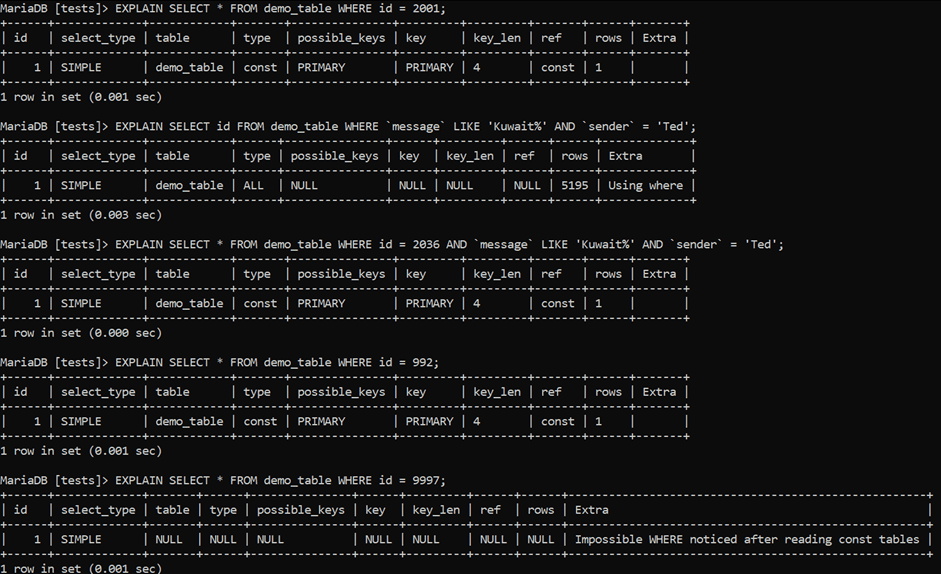
- The first query makes use of a primary key because we only select the
idcolumn after theWHEREclause – quite self-explanatory. - The second query doesn’t even consider our primary key because we don’t use it after a
WHEREclause. - The third query uses our primary key because we know which
idwe’re searching for. - The fourth query behaves the same way – it uses the primary key to locate a specific row.
- The last query says
“Impossible WHERE noticed after reading const tables”which isn’t an error (running such a query is possible and it would return an empty result set), but it denotes that theWHEREclause doesn’t quite make sense (in this case, most likely because theidof 9,997 doesn’t even exist – there are around 5,000 rows in the table).
To explain the thinking of our database in operations involving primary keys, we run an ordinary SQL query and add EXPLAIN in front of it. The way EXPLAIN works in different relational database management systems differs from DBMS to DBMS, but in a nutshell, it tells us how and why our query is executed in the way it is. EXPLAIN lets us in on multiple things:
- The key column refers to the index actually chosen by MySQL.
- The type of our SQL query (whether our query is using any
JOIN/UNIONoperations or runs as-is): that’s theselect_typecolumn. - The table our SQL query runs on – that’s the
tablecolumn. - The
typecolumn shows the type of the query that was executed: a value ofconstmeans that MySQL finds at most one row in the table. - The
possible_keyscolumn refers to the indexes considered to use by MySQL. - The
keycolumn refers to the index actually chosen by MySQL. - The value of the
key_lencolumn refers to the length of the index that was chosen by MySQL. - The
refcolumn refers to the column or value that MySQL uses to find rows in the table. - The value in the
rowscolumn refers to the number of rows examined by MySQL. Extrarefers to anything “extra” MySQL feels like telling us.
After we understand the internals of our queries, we can see that operations with PK indexes seem to be similar to operations with ordinary B-tree indexes. At the same time,, we should keep in mind that in InnoDB, the primary key is the clustered index — it defines the physical order of the rows. This makes its use significantly different from a secondary index, which contains a copy of the key and a pointer to the clustered index.
Strings as Primary Keys
While the use of string values may have a slight performance cost, natural keys, which are often strings, are perfectly valid, and more maintainable than surrogate keys. Their great advantage is that rows that are referenced by their primary keys are retrieved extremely efficiently. However, it isn’t a good practice to store GUIDs as string values for primary keys. How is that value generated and how do you ensure that it will always be unique? And, if the need arises, how would you compare and search for data?
Given the fact that many universally unique identifiers look like 550e8400-e29b-41d4-a716-446655440000, why do you need a GUID rather than an integer to act as a primary key in the first place? This comes at a cost: larger keys mean more storage, slower joins, and heavier indexes.
Optimizing Operations with Primary Keys
Primary keys aren’t just about enforcing uniqueness — they’re a performance lever. In InnoDB, the table is physically ordered by the primary key (a clustered index), which means smart primary key design can make lookups, joins and range queries lightning fast. But it cuts both ways: a poorly chosen key can drag everything down.
A few golden rules:
- Keep it short – Smaller keys mean faster indexes and leaner foreign keys.
- Keep it stable – Changing primary keys is like moving the foundations of a house.
- Avoid bulky composites – Use them only when truly necessary.
- Think downstream – Every foreign key referencing your PK inherits its baggage.
Treat your primary key like the backbone of your table — strong, lightweight, and unchanging.
Since primary keys in InnoDB are B-tree indexes, most of the same performance advice applies, so I’d advise you to also apply advice relevant to B-tree indexes.
Generated Invisible Primary Keys (GIPKs)
In the PRIMARY KEY world, some of you may come across terms such as GIPK – as briefly mentioned earlier, such a term stands for a Generated Invisible Primary Key. If a table doesn’t have any defined primary keys and it has no unique indexes with column values defined as NOT NULL, it has a GIPK.
Generated Invisible Primary Keys have a couple of limitations unique to themselves:
- Generated Invisible Primary Keys are only available for tables running the InnoDB storage engine.
- The creation of GIPK can be controlled by turning system variables such as
sql_generate_invisible_primary_keytoON. If this value is set toON(the default value isOFF), MySQL will build primary key values automatically (this variable is not available in MariaDB). - A generated primary key cannot be altered, but it can be set to be visible or invisible. To make a generated primary key visible or invisible, make use of the
ALTER TABLEstatement after confirming the column name by inspecting the table structure:ALTER TABLE 'demo' ALTER COLUMN 'my_row_id' SET VISIBLE/INVISIBLE; - Generated Invisible Primary Keys can be skipped during backup operations. This can be done by specifying the
mysqldumpoption of--skip-generated-invisible-primary-key.
By default, the InnoDB storage engine will always create a hidden Primary Key if one isn’t provided (see explanations above), but by providing this feature, MySQL aims to make primary keys visible and usable to the end user. The downside of GIPK is that they’re only available in newer versions of MySQL – they’ve been deployed in MySQL 8.0.30 and act as special kinds of invisible columns. Users of MySQL can get them to work by setting the sql_generate_invisible_primary_key variable to ON, but MariaDB won’t find this value at the helm:

Regardless, users of MySQL can make use of Generated Invisible Primary Keys like so:
- Set the variable of
sql_generate_invisible_primary_keytoONby runningSET sql_generate_invisible_primary_key=ON - Create a table without an explicit Primary Key:
CREATE TABLE `demo_table`(`column` VARCHAR(50)); - Check the table schema by running a
SHOW CREATE TABLEquery:SHOW CREATE TABLE demo_table\G
You will see something like so:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
mysql> SHOW CREATE TABLE demo_tableG *************************** 1. row *************************** Table: demo_table Create Table: CREATE TABLE `demo_table` ( `my_row_id` bigint unsigned NOT NULL AUTO_INCREMENT /*!80023 INVISIBLE */, `column` varchar(50) DEFAULT NULL, PRIMARY KEY (`my_row_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci |
The my_row_id column has an invisible auto-incrementing primary key! That also means three things for you as a developer/DBA:
- If you’re using MySQL 8 or newer with the variable
sql_generate_invisible_primary_keyset toON, none of your tables can have a column with the name ofmy_row_id. - The
my_row_idGIPK will always have a data type and it will always beBIGINT UNSIGNED. This is formally documented and stable as of 8.0.30. - The column will always have an
AUTO_INCREMENToption set up.
All this also means that if you insert rows into your table, you will finally be able to select the My_row_id column and see all of the applicable values:
|
1 2 3 4 5 6 7 8 9 10 11 |
mysql> SELECT `my_row_id`, `name` FROM `demo_table`; +-----------+------+ | my_row_id | name | +-----------+------+ | 1 | Demo | | 2 | Jack | | 3 | Josh | | 4 | ... | | 5 | ... | +-----------+------+ 5 rows in set (0.00 sec) |
Keep in mind that as the column is invisible, you are unlikely to see the column in a result set if you use SELECT * FROM `your_table` or similar queries.
More information on Generated Invisible Primary Keys can be found in the MySQL documentation.
Summary
Primary keys are at the heart of relational database design. In MySQL, especially with the InnoDB engine, they’re not just identifiers – they define how your data is stored, retrieved, and related. A well-chosen primary key improves performance, ensures data integrity, and forms the basis for efficient joins and lookups.
While AUTO_INCREMENT integers are popular, MySQL supports a wide range of data types for primary keys, including strings – provided they’re unique, non-null, and thoughtfully chosen. One table, one primary key – but that key can span multiple columns if needed.
And if you forget to define a primary key? MySQL 8.0.30 or later may create one automatically behind the scenes, using a GIPK – helpful, but worth understanding.
Choose wisely. Your future queries will thank you.
PRIMARY KEY Indexes – Frequently Asked Questions
Q: What is a primary key?
A: A primary key is a column or set of columns that uniquely identify each row in a table. It must be unique and not null, and it’s backed by an index.
Q: Can a table have more than one primary key?
A: No. A table can only have one primary key constraint – but it can involve multiple columns. A primary key that involves multiple columns is called a composite primary key.
Q: Can primary keys contain NULL values?
A: No. By definition, primary keys are always NOT NULL. MySQL enforces this even if you forget to declare it.
Q: Do primary keys have to be integers?
A: Not at all. MySQL allows CHAR, VARCHAR, and other data types. Use what best fits your data – just keep it unique and stable.
Q: What’s the deal with Generated Invisible Primary Keys (GIPKs)?
A: In MySQL 8.030+, if no primary or unique key is defined, MySQL may silently create an invisible BIGINT primary key (my_row_id) to ensure every row has a unique identifier. This helps replication and storage, but it’s best not to rely on it unless you understand the trade-offs.
Q: How do primary key indexes help performance?
A: In InnoDB, the primary key determines the physical row order. That means faster lookups, efficient joins, and good use of caching – especially when your queries filter or join on the PK.
Appendix – Table Structure & Data
The example data show in this article was generated using Mockaroo. The table structure used for most queries looked like this:
|
1 2 3 4 5 6 7 |
CREATE TABLE demo_table ( id INT PRIMARY KEY AUTO_INCREMENT, message VARCHAR(120) NOT NULL DEFAULT '', sender VARCHAR(120) NOT NULL DEFAULT '', receiver VARCHAR(120) NOT NULL DEFAULT '', timestamp TIMESTAMP NOT NULL ); |
Note: While the column is called timestamp, the sample values were simply time-like strings rather than precise SQL timestamps. Always check and validate generated data types when mocking tables.





Load comments