

In this first entry in a multipart series on indexes, I will cover the most important index type in MySQL, B-Tree Indexes. Applying indexes of any type in MySQL is nuanced task – they are used to speed up the performance of our search queries at the expense of having to be maintained when data is changed in the table. This in turn slows down INSERT, DELETE statements (though typically an index will also help with DELETE operations because the rows to be deleted do have to be located.) UPDATE operations may or may not be affected depending on whether you modify indexed data, but an index can help to locate data to be updated.
The readers of my articles here on Simple Talk will know that as there are many different database management systems you can employ to help you, there are just as many types of indexes to choose from, too – the types of indexes you can choose from heavily depend on your database management system. While some database management systems are known for their proficiency in data and index type offerings, some do have a less feature-rich choice menu. Regardless, indexes remain the pillar of performance for developers and DBAs alike.
MySQL offers seven index types you can employ in your operations. As noted in my article: The nuances of MySQL indexes, the Balanced Tree, or B-Tree, indexes, are their pillar.
The Upside of B-Tree Indexes
B-Tree indexes are short for Balanced Tree indexes. The secret is hidden in the title itself – balanced trees aren‘t the sort of trees that grow in your garden, but rather, they refer to a process that aims to sort data in a fashion that makes the search through that data significantly faster.
A B-Tree index uses pointers and nodes to locate data. This type of index consists of three nodes – the root node, intermediate nodes, and leaf nodes. This type of index is called a balanced tree index because the ideal version of this “tree“ holds all its “leaves“ (leaf nodes) at the same level (in the ideal state, but this may vary in a database tree as items are added and removed rapidly).
A B-Tree index consists of nodes that contain pointers to other nodes. For those still struggling to understand me, this illustration may help. Note that the intermediate levels can have many more items per node. The goal of the B-Tree structure is to have as few levels as possible. Hence the smaller the index keys, the fewer levels, the fewer reads needed. The diagram shows a very small example with only a few rows:
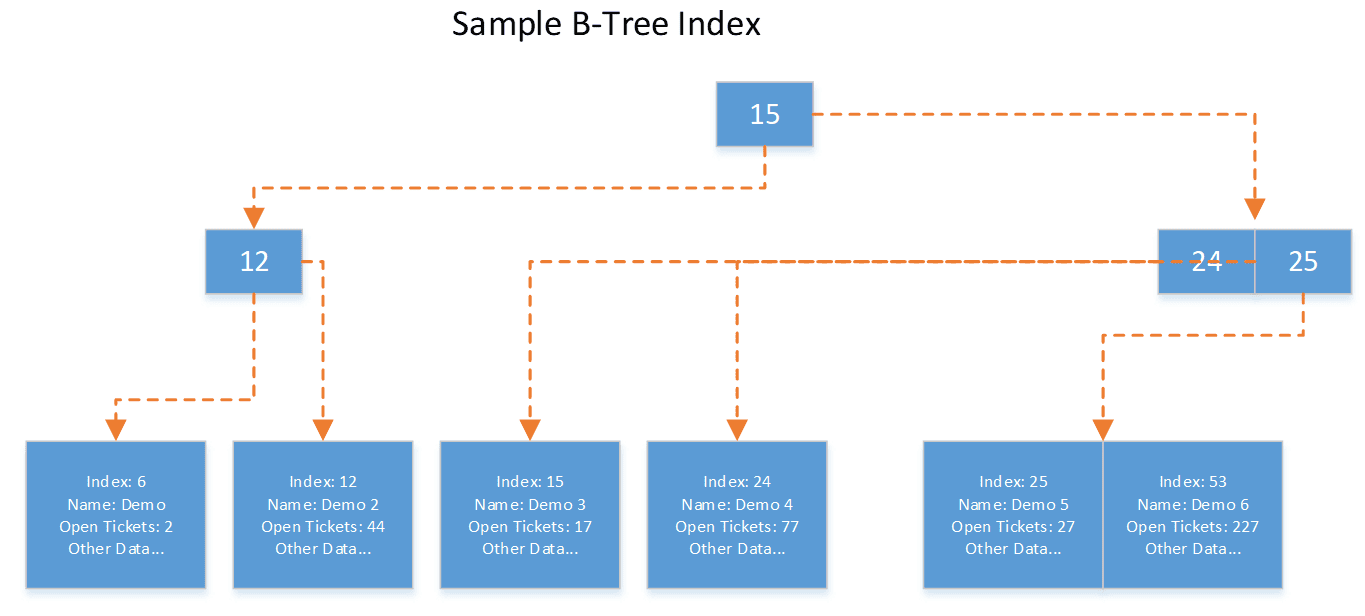
Image 1 – B-Tree Index Illustration
As you can probably already tell from the example above, our data is stored in the leaf nodes – leaf nodes store all of the rows of indexed data. The example above illustrates why B-Tree indexes are the cornerstone of query performance: once a B-Tree index is granted resident status in your database, the SELECT queries running in your database can use the index to quickly find rows.
Of course, they must be written properly – I‘ll get to that in a second – but the illustration above should make the upsides of a B-Tree index as clear as day. An illustration of how you might use a B-Tree indexes to find a row can be seen below. In it I am searching for the row with the value 15:
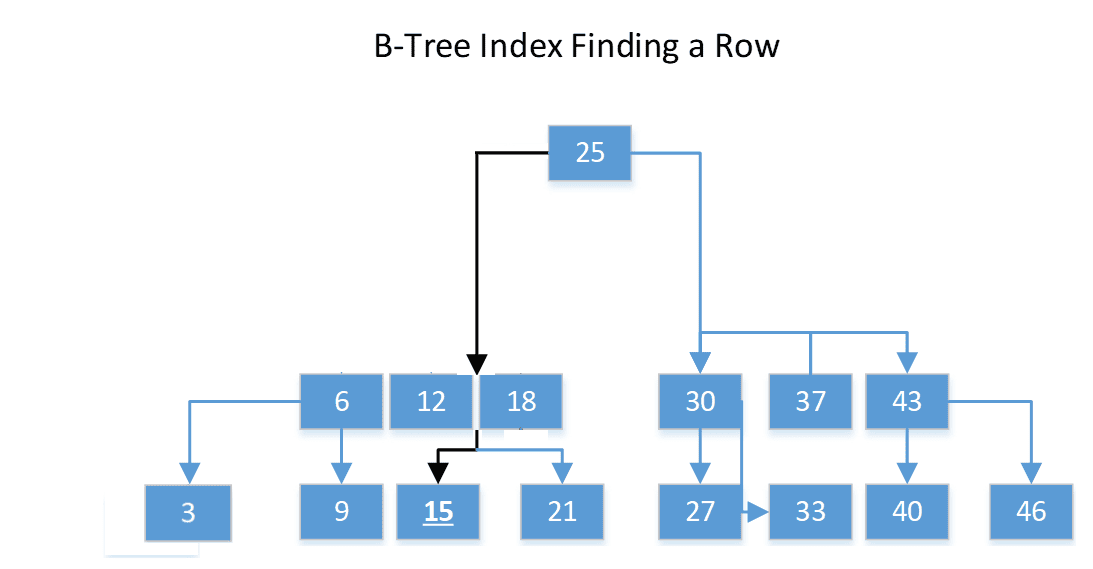
Image 2 – B-Tree Index Finding a Row
In the diagram, say you are looking for the value 15. You start at the root node. 15 is less than 25, so you go to the left. In the intermediate node, there are three values. Since 15 is greater than 12, but less than 18, so you go down that path, and find 15. (Or if you were looking for 14, you would have known you found nothing.) This whole index could be just in the root node, but as you add millions of entries, it grows over time
Once you find yourself using indexes, the terms “index scan” and “index seek” may also be familiar to you. An index scan refers to your database scanning the leaf data or index pages to find relevant rows while index seek refers to your database retrieving selective rows.
As an example, consider the following diagram:
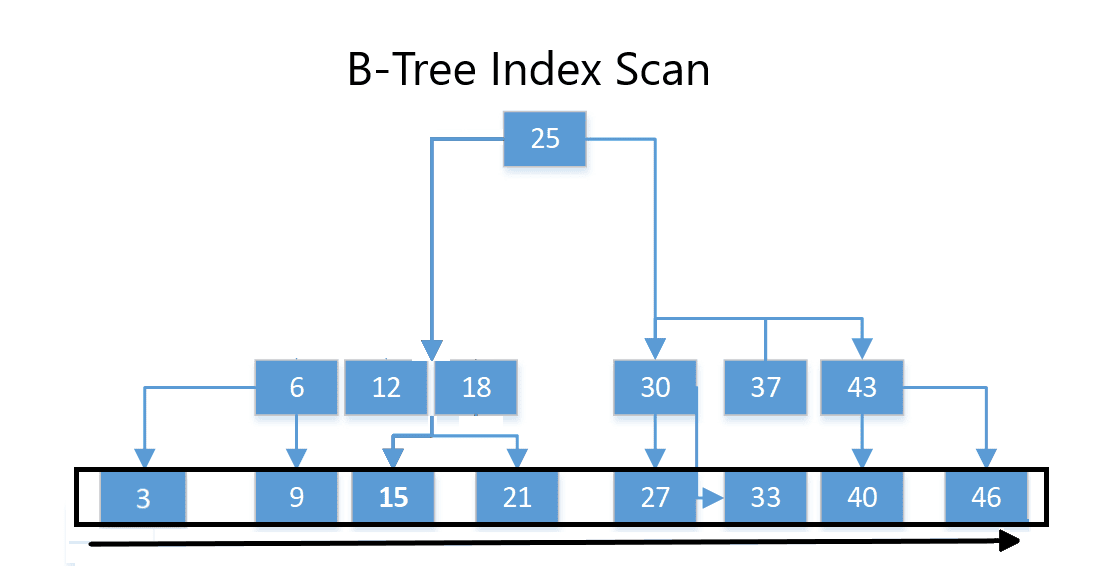
Image 3 – Index Scan
For an index scan, you would only touch the leaf nodes. So, if you needed only the data that is in this column that has been indexed, the query processor can scan the index and fetch data here. The data is sorted, which can come in handy in some cases, but often an index scan is simply the same as a table scan, just with the more narrow data structure.
The Downsides of B-Tree Indexes
Of course, significant upsides rarely come without some downside: attentive readers will be aware that such types of indexes often have a negative effect performance of three types of SQL queries – INSERTs, UPDATEs, and DELETEs. The reason why becomes apparent after you‘re familiar with how these types of queries function internally. For reference, INSERT queries have to:
- Start.
- Check whether the user running that type of query has the necessary permissions to run this type of query.
- Open tables.
- Initialize.
- Act on any locks.
- Update data:
- Create the data in the row.
- Modify data in indexes (and partitions if they exist) individually.
- End.
- Close all of the necessary tables.
- Free up the items that have been used.
- Clean up.
I‘ve emboldened step #6 because it refers to the step that B-Tree indexes are the most concerned with – the updating of data. INSERT queries insert data, but the process is similar for updating and deleting data too.
When an index is in use, it doesn‘t only make the search for certain data quicker and more effective, but it also has its role when data is inserted, updated, or deleted, and that‘s because when data is updated in any way, the index helping find that data must be updated as well.
The index must be updated because it acts just like an index in a book – you skip to a specific page and then read things that are of interest to you. What would happen if you skipped to a page to read about an event, and that event would be located on a completely different page?
Correct – the index would essentially be useless. Queries that modify data rather than read it will be slower than usual because they have to ensure that other users of the index can find the modified data.
Indexes work by ordering data in a column they’re placed on in such a way that maximizes the efficiency of search queries. Indexes are particularly effective for queries involving the WHERE clause because this clause specifies what we’re searching for, and after that’s known, the database (and the indexes within it) knows how best to help us. An index is a data structure that gets traversed through whenever we’re searching for a specific row.
Creating B-Tree Indexes
As far as MySQL is concerned, B-Tree indexes can be created in two ways – when building a B-Tree index, we can either employ a CREATE INDEX or an ALTER TABLE query. Before creating an index on a table, always keep in mind that you have to have some free space on the disk: if that’s not the case, you risk running out of disk space and the operation being aborted by none other than your almighty database herself.
Once that’s out of the way, you can elect to use a CREATE INDEX query to create a B-Tree index on a column in a table like so:
|
1 2 |
CREATE INDEX idx_name [USING BTREE] ON demo_table (demo_column); |
Where:
- idx_name is the name of your index. This name should be unique for every index and should not be a reserved keyword. A list of reserved keywords in MySQL can be found here.
- demo_table is the name of the table you‘re building an index on.
- demo_column is the name of the column that the index will reside on. (This can be more than one column, and how this changes the index will be expanded on in the next entry in this series.)
B-Tree indexes can also be built when creating a table (in this case, we index the username column and title our index user_idx):
|
1 2 3 4 5 6 7 |
CREATE TABLE `demo_table` ( `id` INT(5) AUTO_INCREMENT PRIMARY KEY, `username` VARCHAR(25) DEFAULT NULL, --INDEX Name (ColumnName[(length)]) --Note: Just indexes the first 10 characters INDEX user_idx(username(10)) ) ENGINE = InnoDB; |
One can also create a partial index (also referred to as a prefix index) that covers a part of the values in a column (in our example, 10 characters out of 25 to save disk space. That can be done by defining the length of the index upon its creation like shown above.
Note when defining an index inline with the table creation, you do not have to supply an index name, and one will be assigned for you. This is great for ad hoc table creation, but you may not get the name you desire. In the previous example, if you change the index creation to:
|
1 |
INDEX (username(10)) |
It chose the name ‘username’. This may not be the name you want (especially since it is a partial index), so it is greatly suggested to give a proper name to the indexes so you can know what they are when you see them again.
If you are new to MySQL, you may wonder if you can use a partial or filtered index. If you have not seen these, some database management systems (in this example, SQL Server) will allow you to create a partial index with an SQL query like the one below:
|
1 2 |
CREATE INDEX `partial_idx` ON `table_name` (`column_name`) WHERE column = 'value'; |
This is useful for queries that use a similar WHERE condition. Interesting, yeah? No matter if you add a partial index or not, after you’ve made your choice, you will have a B-Tree index helping your queries find accessible data faster.
Modifying Data in a Table That’s Using a B-Tree Index
A CREATE INDEX statement is one of the easiest ways to create B-Tree indexes in MySQL. What’s created may also need to be modified as time goes on – and this is where you must be aware of a couple of important things: indexes solve issues, but as data is being modified, they can also become the primary cause of headaches for you and your database.
One of the headaches you may want to keep an eye on is related to the length of your data – a B-Tree index is likely to get bigger and bigger once more data is introduced into your table. That happens because of index cardinality – the number of unique values covered by your index. The bigger this number will be, the more effective your search queries will become, but at the same time, the more space on the disk your indexes will occupy.
This is why when building an index or modifying data in a column that has an index, you have to be aware of the length of your index leaf structures. Indexes can become very expensive if you neglect this fact: an index is a structure on top of your data, and its size directly depends on:
- The number of rows in the index.
- The number of columns in the index.
- How many indexes exist on your table or column.
- The size of column values themselves.
Dig around and you won’t have a hard time finding a formula to calculate the sizes of indexes in a database either. To calculate the approximate maximum size of an index, OpenEdge suggests this formula:
A * (7 + B + C) * 2
Where:
- A is the number of the rows in your column.
- B is the number of columns in your index.
- C is the average number of bytes in the column.
The formula to calculate index sizes may differ for those using other database management systems and for those running MySQL, it may look something more similar to the one below instead:
|
1 2 3 4 5 6 |
SELECT database_name, table_name, index_name, ROUND(stat_value * @@innodb_page_size / 1024 / 1024, 2) size_in_mb FROM mysql.innodb_index_stats WHERE stat_name = 'size' AND index_name != 'PRIMARY' ORDER BY size_in_mb DESC; |
This query will return index sizes for every table in every database in megabytes. It will also include partitions if any exist:
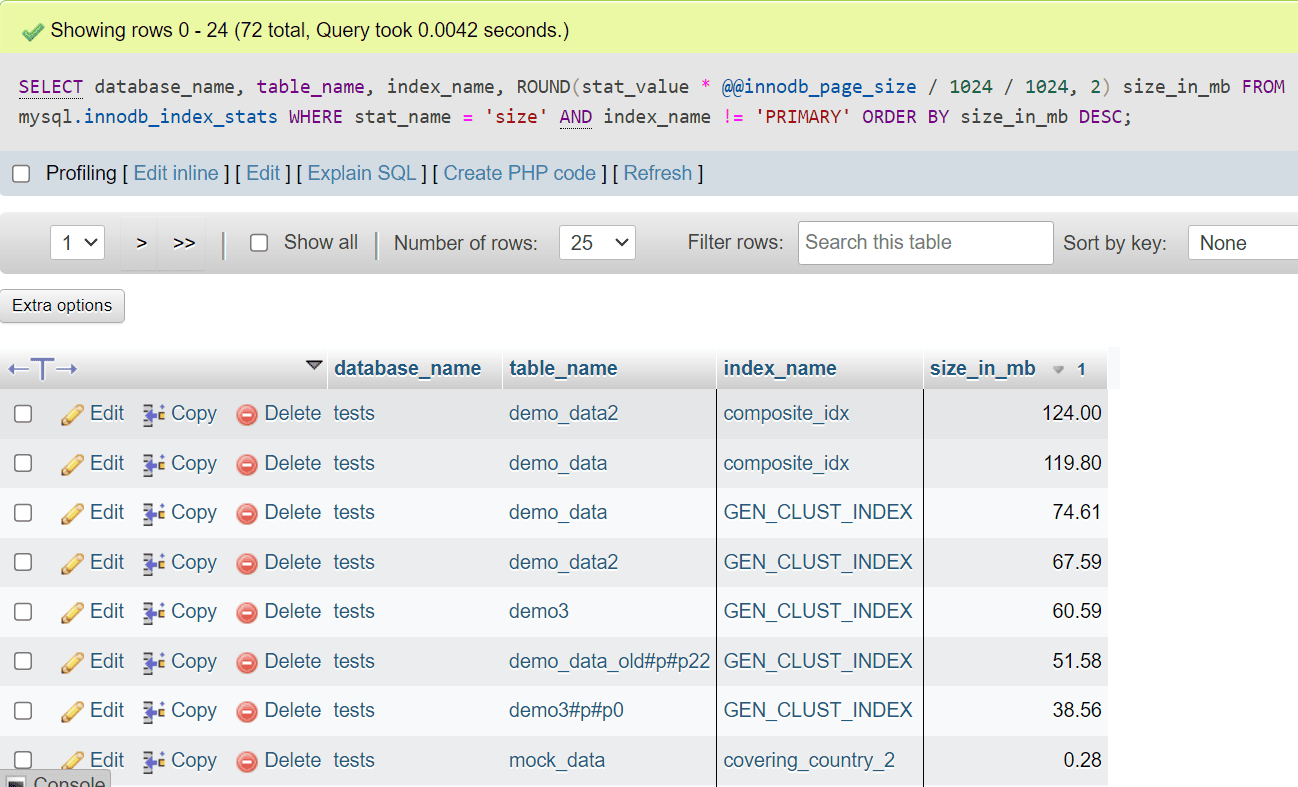
Image 4 – Calculating index sizes in MySQL
One index weighs 61MB and another index on one partition weighs 39 – you will see bigger values too! Smell a problem?
This problem may be very prevalent for those running big data-based search engines or anything in the big data realm: the more data you have, the more space on the disk your indexes will occupy. To lessen the weight of the B-Tree index, consider:
- Making the length of the data type smaller (e.g. use 50 characters if using 255 isn‘t necessary – indexing 50 characters is likely to occupy way less space than indexing 255.)
- Using prefix indexes to only index some of the data as specified above. If you’re using other database management systems, explore other index types too – SQL Server has filtered indexes that allow you to apply specific conditions that cover a subset of rows in a table, other database management systems may already have introduced new types of indexes depending on when you’re reading this article.
Using B-Tree Indexes in MySQL
Index length is not the only risk you have to be aware of when modifying your data that‘s using B-Tree indexes – since MySQL leverages indexes to find specific rows, chances are that if you‘re not searching for a specific row, your index won‘t be used in the first place. We will back that theory up by performing some basic EXPLAIN procedures on our queries. Scroll up and look at the drawing of how indexes find rows (or look at the drawing below for the basic path through a few levels) – I’ll help you understand it.
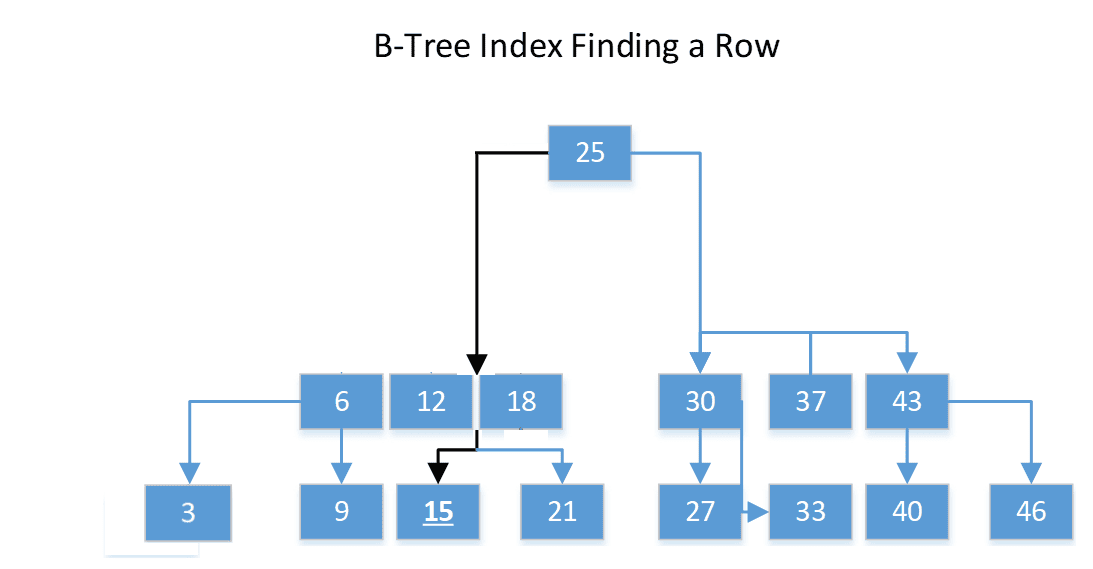
Image 5 – Indexes Finding Rows
First, we‘ll build a simple table that depicts the items customers have purchased, their quantities, and whether they‘ve been delivered or not. The query that creates our table looks like this:
|
1 2 3 4 5 6 7 8 |
CREATE TABLE `demo_table` ( `customer_id` int(20) NOT NULL AUTO_INCREMENT, `item_purchased` varchar(120) NOT NULL DEFAULT '', `quantity_purchased` varchar(50) NOT NULL DEFAULT '0', `delivered` varchar(5) NOT NULL DEFAULT 'No', PRIMARY KEY (`customer_id`), KEY `idx_purchased` (`item_purchased`) ) ENGINE=InnoDB; |
The table can be recreated by running an SQL snippet available here.
Our index is emboldened – it‘s called idx_purchased (short for “index_purchased“) and resides on the column item_purchased.
We insert some data into our table, then search for it:
|
1 2 3 4 |
EXPLAIN SELECT * FROM `demo_table` WHERE `item_purchased` LIKE ‘%iPhone X%’; EXPLAIN SELECT * FROM `demo_table` WHERE `item_purchased` = ‘iPhone X’; |
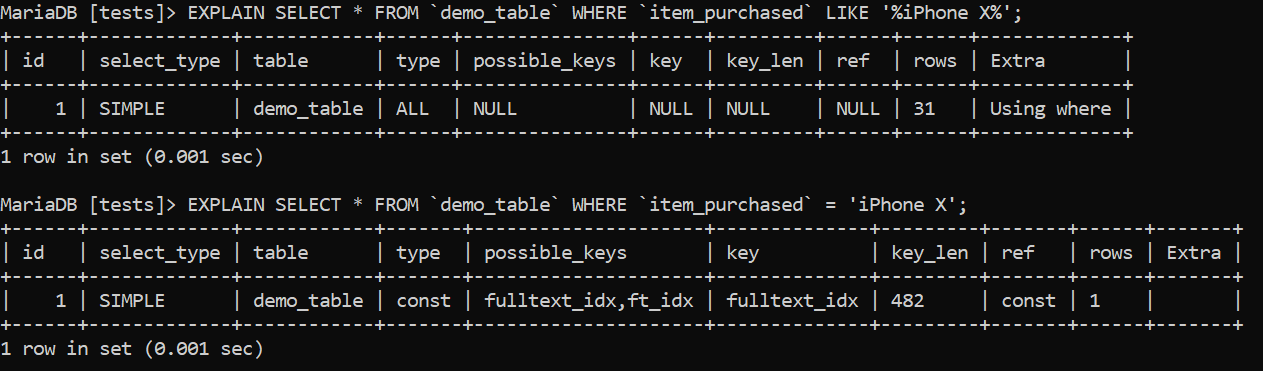
Image 6 – EXPLAINing a SELECT Query

Image 7 – MySQL Using Indexes with Wildcards
As you can see from the first example above, only the second query uses our B-Tree index. There may be multiple reasons why MySQL may not use the B-Tree indexes you define:
- Your queries search for values starting with a wildcard. Look at the first query – we use the LIKE clause and tell our database to search for something that has „iPhone X“ in between. The second query searches for an exact value, so MySQL is able to provide it with an index to use – the first one does not. Look at the last example too – we’re searching for anything starting with iPhone X, so our query is able to use the index, whatever it may be.
- The MySQL query optimizer will always pick the fastest way to provide you with data. If your index is defined but is not being used, that means that your database has elected to use a better method to find your precious data. It has chosen another method because it has determined that it would be faster than using the index. An index will impose an ordering on the rows within a table to quickly find values and it will be used if it makes sense – if 40% of the values in your column are the same, is there much sense in using an index?
- Your index wasn‘t even considered for use. Look at the query involving wildcards – if you search for something that starts with a wildcard, your index won‘t be used. To add to that, perhaps you have two indexes on the same column and MySQL only chose the first one because the other one barely has cardinality?
- You have multiple indexes on a column and you‘re searching for something that cannot use the leftmost prefix. If MySQL cannot use the index, perhaps there‘s no leftmost prefix in place?
Avoid indexing a column when the size of your data doesn‘t warrant indexing – indexes will speed up search operations, but slow down updates, inserts, and deletes, and they should be considered when you have a big enough data set that your indexes can help order. Index columns you use in a WHERE clause, use indexes if you work with bigger data sets, and keep in mind that they speed up ORDER BY operations too because indexes create an ordered structure that your database can use to fetch rows in a pre-ordered manner.
Caring for B-Tree Indexes
Once a B-Tree index is a resident on any of your columns, it needs to be accounted for. Be mindful of the fact that all indexes occupy storage space and that an index is not an Oraculus either – best practices suggest that you should look after your indexes and consider rebuilding them once their fragmentation starts hovering above 25-30 percent.
Account for fragmentation if you update your rows frequently and check for fragmentation with this query (source: StackOverflow) – if you have multiple indexes, be mindful that each one of them can have multiple levels of fragmentation:
|
1 2 3 4 5 |
SELECT ENGINE, TABLE_NAME,Round( DATA_LENGTH/1024/1024) as data_length, ROUND(INDEX_LENGTH/1024/1024) as index_length, round(DATA_FREE/ 1024/1024) as data_free from information_schema.tables WHERE DATA_FREE > 0; |
Aside from fragmentation, be mindful of the size of your columns if you index them in full, make sure you index columns that are in a WHERE clause in your queries, and make sure to isolate your columns to enable your database to use them. Your database will not use indexes on columns if you don’t leave the column after the WHERE clause alone meaning that queries like the one below won’t fly:
|
1 |
SELECT * FROM `demo_table` WHERE `column` + 15 = 207; |
Keep an eye on your index cardinality – the higher index cardinality, the higher read performance (if index cardinality is higher, there are fewer records your database has to scan through.)
To understand how best to index your columns, profile your queries, and use the recommendations in this blog as a starting point – refer to the most recent version of the documentation of your DBMS for updates.
Finally, you also want to ensure that you’re not using redundant or duplicate indexes since MySQL does not “protect you” from making such mistakes.
Take advice cautiously too – 5 indexes on a table with 5 columns may be a good decision if all those columns are searched through! Or 1 index on a table with 10 may not if it is never searched but always used in aggregate.
Finally, beware of index fragmentation – index fragmentation means free space in the pages of the index and happens when data is inserted, updated, or deleted. The more often your data is updated, the higher the chance of fragmentation.
Unfortunately, MySQL won’t notify you once your data is fragmented – you’d have to keep an eye on your tables and figure that out yourself. Some DBAs advise to use this query to obtain the data length, index length, and free data bytes:
|
1 2 3 4 5 |
SELECT ENGINE, TABLE_NAME, ROUND(DATA_LENGTH/1024/1024) AS data_length, ROUND(INDEX_LENGTH/1024/1024) AS index_length, ROUND(DATA_FREE/1024/1024) AS data_free FROM information_schema.tables WHERE DATA_FREE > 0; |
Once MySQL returns results, get the fragmentation ratio by using this formula:
|
1 |
(data_free / (data_length+index_length)) * 100 |
The result is the fragmentation percentage. If the percentage is big (perhaps bigger than 20-30%, what you consider “big” depends on you), consider rebuilding the table. Taking a quick backup of the table and restoring it should do the trick.
Key Takeaways and Summary
A B-Tree index is an incredibly powerful force in your database, but it has to be accounted for and cared for properly. We hope that this blog enabled you to better understand its internals, understand its upsides and downsides, and decide whether it is the type of index for you.
If you‘re using B-Tree indexes in your MySQL database, make sure that you search for exact matches of data (i.e. use the operators „=“, „<=“, „>=“), avoid searching for something that starts with a wildcard, and make sure indexing makes sense in the first place (i.e. make sure you have a good amount of data to search through – MySQL can always decide that it doesn‘t make sense for it to use the B-Tree index you defined.)
Aside from that, remember that B-Tree indexes come with a purpose: that purpose is to speed up reading operations (SELECT queries), but it doesn‘t come without a price – your INSERT, UPDATE, and DELETE operations will be slower as a result.
We hope that this blog was informational and useful, come back to the Simple Talk blog for blogs on other index types in the future, and until next time.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved





Load comments