
Introduction
In my last article we explored the basics of Azure networking, including virtual networks, subnets, and network security groups. Although networking is usually a bit outside the realm of responsibility for SQL Server DBAs, it’s nonetheless important to make sure you have a basic understanding of how things work. Now, with that out of the way, we can focus on another area of Azure networking that interacts heavily with SQL Server: load balancers.
In a traditional on-premise environment, a DBA’s experience with load balancers is likely to be limited to certain specific cases. For example, if we are deploying a number of servers hosting Reporting Services in a scale-out configuration, we’ll likely use some form of load balancer to allow for traffic to be split between the servers, as well as ensuring that if a server goes offline it is removed from the pool of available endpoints. In Azure, however, load balancing takes on a much larger role, especially for those who are going to deploy highly-available solutions.
To begin with, let’s review how a typical setup utilizing AlwaysOn Availability Groups might look in an on-premise environment. Then, we’ll contrast that with how things are configured in Azure. Finally, we’ll look at the specific components and configurations of a complete setup.
On-Premise versus Azure AlwaysOn
When we configure an AlwaysOn Availability Group (or AG for short), a necessary component of the group is what’s known as a Listener. Listeners serve as an endpoint for clients to connect to, such that when the AG moves between servers, the clients are transparently redirected as well. Listeners have two components: a network name, which serves as a DNS lookup point for clients, and an IP address, which is registered in DNS and is used by SQL Server as an endpoint.
Behind the scenes, both the availability group, network name, and IP address are managed by the Windows Server Failover Cluster subsystem. If the cluster detects that the server currently hosting the availability group is offline, then it will move the group to the designated automatic failover replica (if one is configured). Since the IP address and virtual network name are part of this group, once they come online on the secondary (now primary) replica clients will transparently be directed to the new server.
In Azure, everything works exactly the same way, with one major difference: due to limitations in how the Azure platform handles address routing, clients cannot use the virtual IP address to connect to the replica. To clarify a bit more, the IP address and cluster network name are still part of the WSFC group containing the availability group, and they will still move when the groups moves to different replicas. However, no matter where the group currently resides, anything trying to connect to the virtual IP address will not be able to, at least not without some involvement from a load balancer resource. If this makes your head tilt slightly, that’s good! It’s easily one of the more confusing parts of utilizing Windows Server Failover Clustering in Azure, be it for AlwaysOn Availaiblity Groups, Failover Clustered Instances, or any other highly-available solution.
Because of this limitation, it’s extremely important that DBAs have a good understanding of how Azure load balancing technology works. Otherwise, when things don’t quite work the way you think they will, you might be in for a long night. Let’s get started by looking at the different parts of Azure load balancers.
Components of Azure load balancers
Load balancers have four main parts (when it comes to working with SQL Server, there’s a fifth that isn’t relevant for our discussion today):
- Front end configurations
- Back-end configurations
- Probes
- Load balancing rules
Front end configurations
A front end configuration links a load balancer to an IP address, either public (Internet facing) or private (accessible only within the Azure virtual network). This defines how clients will connect to the load balanced resource.
In general, you would want to use an internal (VNet only) front end configuration with SQL Server. This is true for a number of reasons, but the most important one is that, more than likely, there is no need for your server to be accessible publicly. True, you can carefully control what IP addresses can access the server, even when exposed publicly, however there’s no advantage to having a public-facing load balancing configuration unless your clients will actually connect over the public network (and there’s a whole host of possible disadvantages to that approach; ever heard of SQL Slammer?).
Back-end pools
Back-end pools in Azure load balancing define what virtual machines are part of the load balanced pool. Virtual machines are added to pools by associating their virtual NIC with the pool (one virtual NIC can be part of more than one back-end pool). However, there are a few limitations:
- Virtual machines in a back-end pool must be part of the same Availability Set
- Back-end pools for a single Azure load balancer can only be associated with a single Availability Set
In other words, you can’t have one Azure load balancer that serves multiple sets of virtual machines.
Probes
A Probe defines the port the Azure load balancer will use to determine whether or not a virtual machine should be part of the set of servers currently active in the load balanced pool. Think of this as a “health check” of sorts. The load balancer will routinely check to see if a virtual machine responds on a given port: if it does, then the load balancer will send traffic its way; if not, the machine is excluded from the pool. You can configure several aspects of a Probe, such as:
- The port the probe will use
- The protocol the port will use
- How often the probe will run
- How many failed or successful attempts must occur before the VM is added or removed from the back-end pool
Load balancing rules
Rules are the core of Azure load balancing, in that they tie together all the other components. A Rule connects a front end configuration to a back-end pool, and defines the health probe that will be used to determine if a server should be part of the active pool. In addition, rules determine:
- The front and back-end ports the rule serves (which may or may not be the same, but in the case of SQL, usually are)
- Whether or not ‘direct server return’ is used. When enabled, this prevents the load balancer from using Network Address Translation, and instead sends traffic to the VM directly using the front end IP as the destination IP address. (From a DBA perspective, it’s sufficient to know that this must be enabled for all rules serving AlwaysOn traffic.)
Now that we have an understanding of the various pieces of Azure load balancing, let’s show how they would be used in a real-life scenario involving SQL Server.
Using Azure load balancing with AlwaysOn Availability Groups
As we previously discussed, within the Azure networks we cannot rely on vanilla network routing to allow traffic to come to secondary IP addresses attached to virtual machines, such as those assigned as part of Windows Server Failover Clustering. As a result, if we were to create an availability group listener, we would not be able to connect to it. Instead, we must rely on Azure load balancing to determine where the availability group currently resides, and route traffic there. When a failover occurs, the load balancer must detect this, and route traffic to the new primary replica.
The requirements to accomplish this are as follows:
- All virtual machines that are part of the AlwaysOn topology (both primary and secondary replicas) must be part of the same Availability Set.
- The primary network interface cards assigned to these virtual machines must be part of the same load balancer back-end pool. Even if you have multiple AlwaysOn Availability Groups, you can utilize the same back-end pool, so long as all replicas for the group are contained in the pool.
- The listener for the AlwaysOn group must be configured to use the same IP address as the front end configuration of the load balancer. If there are multiple AlwaysOn groups, you must have multiple front end configurations (and multiple corresponding rules).
- The listener IP cluster resource must be configured with a Probe Port; this is a port that the WIndows Cluster Service will listen on, and allows for health checks to determine if the resource is online on a given member of the cluster.
- The load balancer must have a Health Probe that uses the same port as the Probe Port of the AlwaysOn listener cluster resource. This is how the load balancer can determine where the group currently resides.
- A load balancing rule must be configured that links the front end configuration, back-end pool, and probe components.
Once these are in place, here’s how actual connections are routed:
- The load balancer periodically probes all virtual machines in the back-end pool, checking to see which ones are responding on the configured Probe Port. At any given time, only a single one should be, since the AlwaysOn group can reside only on a given replica.
- When an incoming packet comes to the load balancer, by way of the configured front end IP address (either public or private), the load balancer routes the packet to the virtual machine that currently hosts the Availability Group.
With these in mind, there is one final topic we need to cover, namely how to properly secure our AlwaysOn Availability Groups from a network perspective.
Securing databases in AlwaysOn groups
As we discussed in the previous article, networks in Azure are wide open (privately) and closed off (publicly) by default. That is, any traffic originating within the current (or any connected) VNets are allowed by default, and any traffic originating from outside the private network (i.e. the internet) is blocked. In most cases, the private portion of that isn’t sufficient to properly secure our SQL servers, so we need to add a few rules. To review, here’s how we might set things up in a typical three tier design:
- Allow traffic from the internet on ports 80 and 443 to the web servers
- Allow traffic on port 443 from the web servers to the application server
- Allow traffic on port 1433 from the application server to the SQL Server(s)
- Deny all other inbound traffic
However, if we set things up this way, and our SQL servers are configured in an AlwaysOn topology and utilizing an Azure load balancer, we’ll quickly discover that we cannot connect to the load balanced AlwaysOn listener IP. Before I reveal why this is the case, I’d like you to form a hypothesis about why this is true. Think back to earlier sections (re-read if necessary), and consider how Azure load balancing determines which server currently hosts the AlwaysOn AG cluster group. Do you have an idea of what might be happening here?
If you thought “Self! This is because the Azure load balancers need to be able to probe the SQL Server virtual machines to determine where the cluster group resides, based on the configured Health Probe”, congratulations! You are correct.
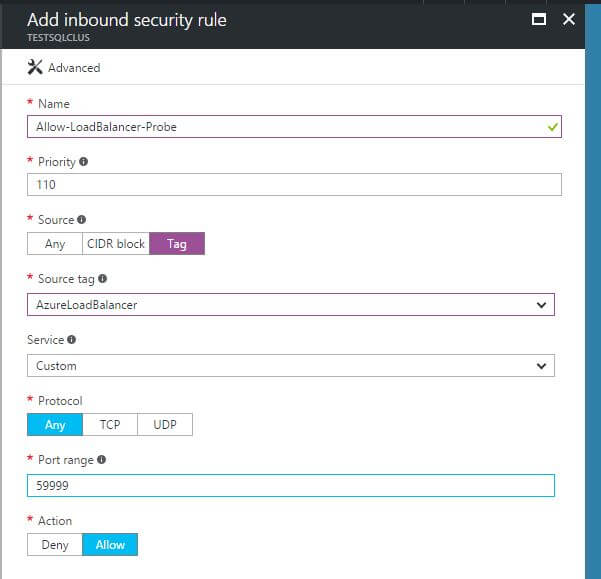
In the default setup of internal Azure networks, this would not be a problem, as a default rule exists allowing all traffic that is tagged as coming from a load balancer. However, since we added our own “Deny all incoming” rule, that overrides any of the default network security group rules, thereby blocking the probe traffic. Therefor, we must add a new rule, with a lower priority number (thus being evaluated first) than the “Deny all incoming” rule, allowing traffic with a tag of “AzureLoadBalancer” (this is how we know the traffic is coming from the load balancer itself, versus some external source connecting to a load balanced IP address), for the configured Probe Port on the Windows cluster resource. Here’s an example screen shot of how that might be configured:
Conclusion
In this article, we’ve introduced Azure load balancers, and discussed how they are integral to the setup of highly available SQL Server instances. Even if you aren’t responsible for setting these up or maintaining, them, it’s important that you still have a firm grasp of how they work in relation to routing connections to SQL. Just as with many other tertiary technologies that interact with SQL (Active Directory, networking, storage), we must know enough that we can provide the responsible parties with specific requirements.
In the next article in the series, we’re going to start the actual work of configuring a highly available SQL Server instance, from configuring disks and setting up the Windows cluster to the necessary network rules and load balancing setup. As you’ll see, there are a number of moving pieces, but thanks to some useful tools we have available through the Azure platform, configuration can be mostly automated. It’ll be great fun, and I hope to see you there!
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments