
In my article “Filetables, Great For Business, Great For Hobbyist”, I implemented the basis of a hobby database I use for my Twitter accounts (@disneypicaday and @dollywoodp), where I post daily pictures of theme parks.
As my inventory of prepped pictures has grown, one thing has become a major pain. Duplicates. I have tens of thousands of pictures, and I scan them occasionally to add to my directories. Perhaps not surprisingly, the same pictures often get chosen a second time. I use a naming standard that integrates the files into my database, as well as for the copies to go out for a given day. So the second (and third and fourth) time I choose the same picture, it looks different, though it has the exact same bits.
For example, consider the following 5 pictures. 4 are unique, but one is a duplicate of another.
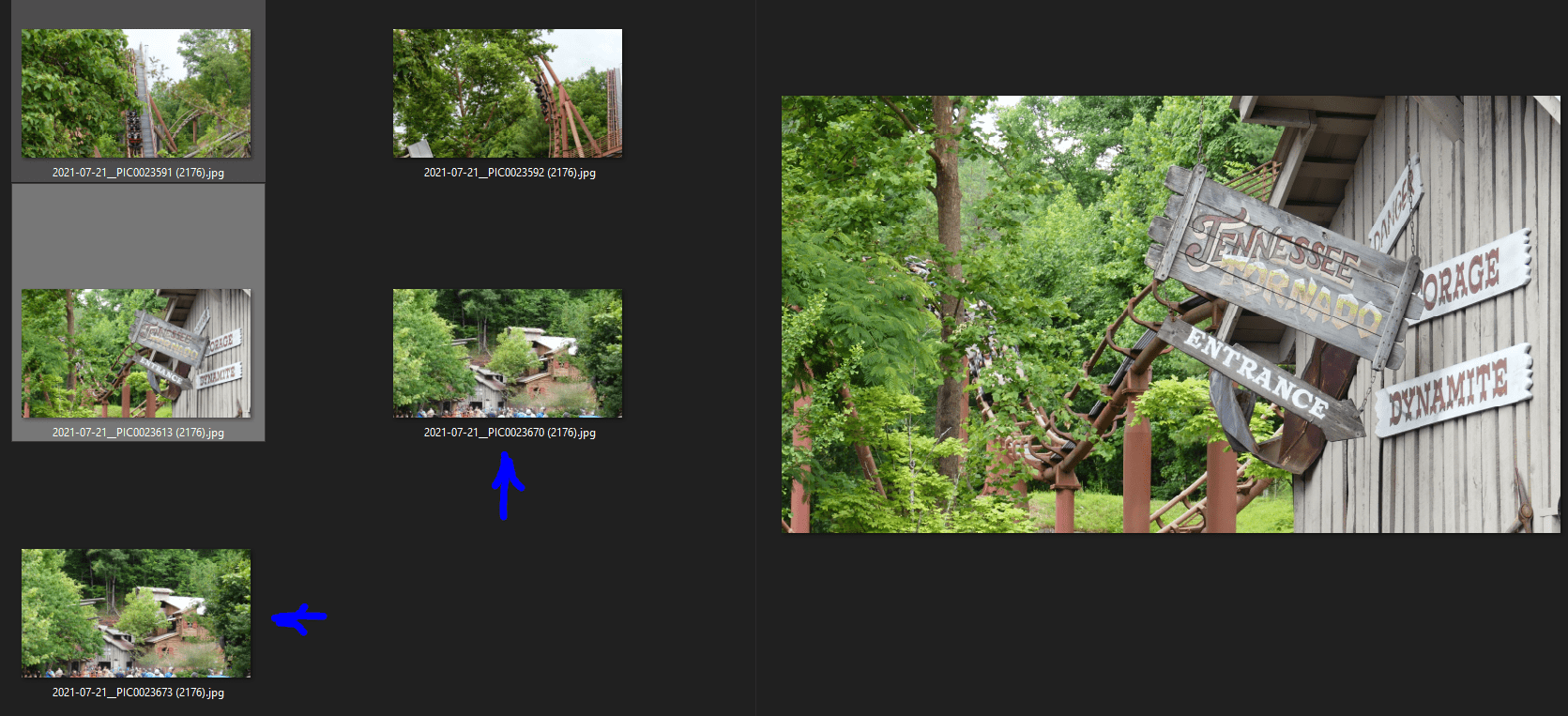
Figure 1. Five files I will use in this demo
(I know this because I pre-created the files. Sometimes the files are not perfect duplicates, like if I cropped a picture even a pixel, then it is a different physical picture. This cannot be solved easily, but exact copies definitely can.)
Using the following code, I will create a database that allows filestream. You may need to change directories, and you may have to configure your server to allow filestream. More on that here (https://docs.microsoft.com/en-us/sql/relational-databases/blob/enable-the-prerequisites-for-filetable):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
CREATE DATABASE [DemoFiletable] ON PRIMARY (NAME = N'DemoFiletable', FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL15.THEMEPARK\MSSQL\DATA\DemoFiletable.mdf' , SIZE = 10000KB , MAXSIZE = UNLIMITED, FILEGROWTH = 10000KB ), FILEGROUP [FilestreamData] CONTAINS FILESTREAM DEFAULT ( NAME = N'FilestreamDataFile1', FILENAME = N'c:\sql\DemoFiletableFilestream' , MAXSIZE = UNLIMITED) LOG ON ( NAME = N'DemoFiletable_log', FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL15.THEMEPARK\MSSQL\DATA\DemoFiletable_log.ldf' , SIZE = 335872KB , MAXSIZE = 2048GB , FILEGROWTH = 65536KB ) WITH CATALOG_COLLATION = DATABASE_DEFAULT; ALTER DATABASE DemoFiletable SET FILESTREAM( NON_TRANSACTED_ACCESS = FULL, DIRECTORY_NAME = N'DemoFiletable' ) WITH NO_WAIT; |
After creating this database, next create a filetable. I used the following code:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
USE DemoFiletable GO CREATE SCHEMA FileAssets; GO --Used to hold the entire enventory of pictures CREATE TABLE FileAssets.Picture AS FILETABLE ON [PRIMARY] FILESTREAM_ON FilestreamData WITH ( FILETABLE_DIRECTORY = N'Pictures', FILETABLE_COLLATE_FILENAME = Latin1_General_100_CI_AS, FILETABLE_PRIMARY_KEY_CONSTRAINT_NAME=PK_Picture ); |
Now, in windows you can go to the directory created by this Filetable. For me this directory is:
\\Desktop-18e8d88\themepark\DemoFiletable\Pictures
Or broken down:
\\ServerName\InstanceName\DatabaseDirectoryName\FileTableName
In that directory, I will drag the five files that were in Figure 1.You can see the files in Windows now, but also in SQL. To find the duplicate, you would think that we could just run the query and it would be obvious. These are 4 pretty different pictures. But his is not the case:
|
1 2 3 |
SELECT name, Picture.file_stream FROM FileAssets.Picture ORDER BY Picture.file_stream |
Returns:

The two pictures we know are duplicates are sorted together, but all the hex values up to there are exactly the same. But we can use just plain old SQL that we know and love:
|
1 2 3 |
SELECT file_stream, COUNT(*) FROM FileAssets.Picture GROUP BY Picture.file_stream |
The output of this statement shows us the duplicated image file’s textual values:
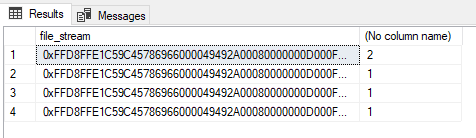
And then you can write something like the following to see the files that are duplicated:
|
1 2 3 4 5 6 7 8 9 10 |
SELECT Picture.stream_id, Picture.name, CHECKSUM(Picture.file_stream), ROW_NUMBER() OVER (PARTITION BY Picture.file_stream ORDER BY creation_time) FROM FileAssets.Picture WHERE Picture.file_stream IN ( SELECT file_stream FROM FileAssets.Picture GROUP BY Picture.file_stream HAVING COUNT(*) > 1 ) |
This returns the following. The CHECKSUM output can be handy if you are working with lots of data as it will give you a very simple representation of your data that is different.

Now, to remove the duplicates, all you have to do is delete the rows where that ROW_NUMBER value is greater than 1 (in my database, I also have to modify anywhere the #2 picture is historically used for tweets, but that isn’t the point here. Executing the following code:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
WITH BaseRows AS ( SELECT Picture.stream_id, Picture.name, ROW_NUMBER() OVER (PARTITION BY Picture.file_stream ORDER BY creation_time) AS Ordering FROM FileAssets.Picture WHERE Picture.file_stream IN ( SELECT file_stream FROM FileAssets.Picture GROUP BY Picture.file_stream HAVING COUNT(*) > 1 ) ) DELETE FROM BaseRows WHERE BaseRows.Ordering <> 1; |
And now the picture files are unique!
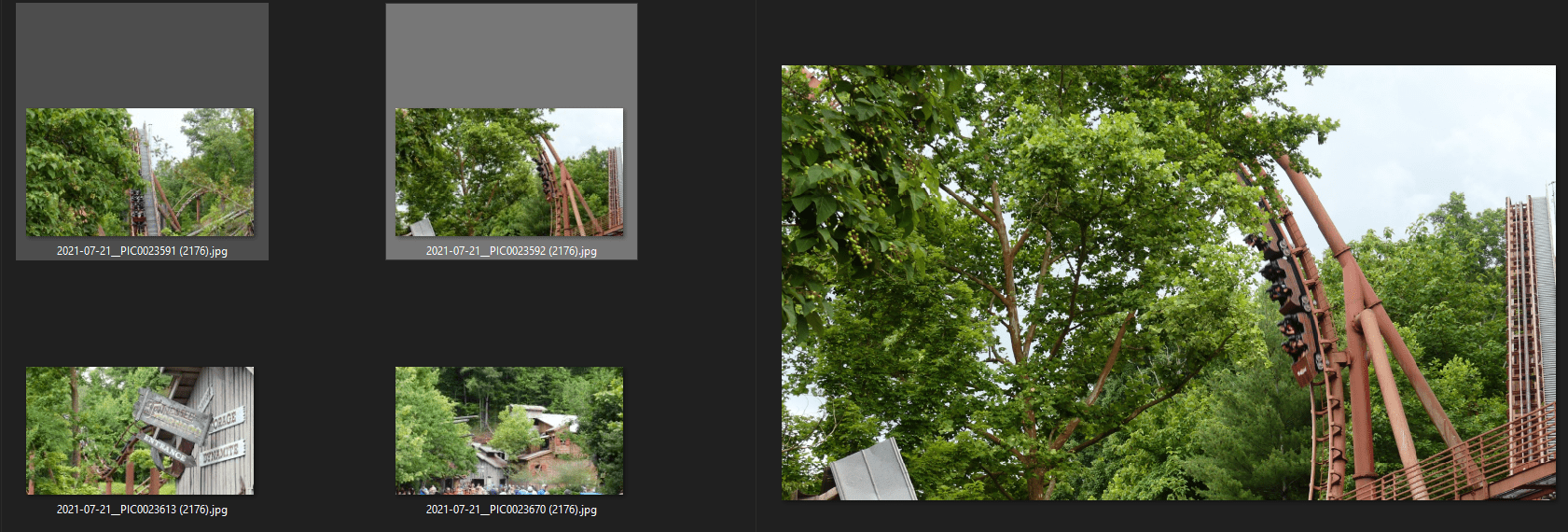
Figure 2. Duplicate picture is gone
The obvious, likely to the casual observer, issue with this could be performance. You cannot index a file_stream value (my image files are in the 2-4MB category,) so it is going to be disk intensive and not at all fast.
But it isn’t terrifyingly slow either. To run this query:
|
1 2 3 4 5 6 7 8 9 10 |
SELECT Picture.stream_id, Picture.name, CHECKSUM(Picture.file_stream), ROW_NUMBER() OVER (PARTITION BY Picture.file_stream ORDER BY creation_time) FROM FileAssets.Picture WHERE Picture.file_stream IN ( SELECT file_stream FROM FileAssets.Picture GROUP BY Picture.file_stream HAVING COUNT(*) > 1 ) |
On my local machine with a 3 year old i7, 32GB of RAM, and an nVME 1TB drive took around 2 minutes with a directory that has over 4000 image files to tell me there were no duplicates. When I first started the process, it took a bit longer as I had nearly 100 duplicates, mostly I suspect to return several hundred megabytes of results.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved





Load comments