
SQL Server FileTables (built on top of FileStream, introduced in SQL Server 2012) provide a specialised table type where each row represents a file in a Windows folder – accessible both via T-SQL queries and directly through Windows file system APIs. This makes FileTables particularly useful when you need to treat file data as queryable rows (SELECT all .jpg files larger than 2MB modified this week) while still allowing users to drop files into a folder or drag them out to their desktop as normal.
This article walks through a hobbyist application – managing ~2,100 curated images for a Twitter posting workflow – covering: enabling FileStream on the SQL Server instance, creating a FILETABLE in a FILESTREAM-enabled database, loading files via Windows folder copy, querying file metadata with T-SQL, and combining the FileTable with relational tables for a posting-history application.
The same pattern scales to enterprise document management, media asset libraries, and any use case that needs both file-system and database access to the same files.
A feature I have never actually used professionally is filestream and filetable. We have a few file based solutions, but they are all packaged solutions. It is a feature that has intrigued me since it was released, but it has never been a fit for the kind of work I typically do (mostly transactions and data warehousing.) I have played with it some, but recently I started using it personally for a hobby I have that uses lots of image files. Currently I have about 2100 curated files in a directory, but my goal is to load a lot more files eventually.
A couple of years ago, I started posting pictures of Disney and Dollywood on a couple of Twitter accounts (@disneypicaday and @dollywoodp). When I started out, it was easy. Just grab a picture and write some cute, marketing sounding, comment…press tweet. After a while, it became a pain to keep up with what I had posted about so I made a database and several folders for pictures: new, posted pictures, special occasions, etc. Fast forward a year, and that solution was increasingly a pain to keep straight what pictures I had used, and I had a bunch of special occasions (FollowFriday, ThrowbackThursday, Christmas, Halloween, for example, that I was also trying to manage). As I was writing my database design book over the past year, I was revising the large object section, I realized I needed to try to use the filetable feature to take my picture database to the next level and put my pictures files into SQL Server. Being able to query with T-SQL to see the pictures I have used, and what pictures I still had available to post, and randomly return a few to post, would reduce the amount of “paperwork” that goes along with the tasks, and make more of the task creative.
As I said, I already had a database created to help pick what to post about, but keeping pictures organized was a mess. In this blog I want to show the basis of the filetable object that I have utilized that probably any photographer (even just a family photographer) might want to make use of. The code for the entire project is located here: https://github.com/drsqlgithub/TwitterManager and is still definitely a work in progress though it gets the job done well enough.
The first decision I had to make was how to get picture metadata into SQL Server. You don’t really get access to file metadata like tags from the filetable structure in SQL Server, so I landed on using a naming standard to transmit metadata:
|
1 |
YEAR_Area_Primary Asset_Space Separated Tag List_PIC0000000.jpg |
- “Year” is the year the picture was taken.
- “Area” is a broad container of things that I want to keep up with, in this case it is like the Magic Kingdom, or Hollywood Studios.
- “Primary Asset” is the attraction, or some aspect of the parks that best identifies what the picture is about.
- “Space Separated Tag List” is a set of Assets or descriptive words to help find pictures.
- “PIC0000000” is a picture number that I append to the end of the picture. Working on the local machine, Windows won’t let you do some things in File explore directly (like rename a file, though you can delete or move the file out of a directory in the filetable). So if you need to do something to a file (like fix the name to meet your standard, or add tags), you may have to copy it out of the folder, modify the filename, then put it back into the SQL Server file share. That is why I append PIC0000000 to the file name and will use it as my connection to the data. If you move the file from the filetable and put it back, it can have a different stream_id as the internal key but the PIC tag never changes.
Say I want to find a picture of Cinderella Castle, I have defined a tag “CinderellaCastle” that I could previously find in file explorer easily. (Using the search box in File Explorer without wildcards it will find values in values between _ or spaces. So it it would find Cinder, but not Castle. With wildcards, you could find Castle using *Castle*). Searching File Explorer is still important to me, as I want to keep a copy of the files outside of SQL Server for when I need them on my phone or tablet. But the real power of having them in SQL Server is that I can parse the file name and put these values into a proper database.
For example, filenames could be:
|
1 2 |
2010_MagicKingdom_CinderellaCastle_Front Dusk_PIC0020116.jpg 2019 MagicKingdom_HauntedMansion_Exterior CinderellaCastle ViewOtherAsset_PIC0000200.jpg |
Searching in File Explorer for CinderellaCastle would get both attractions, and I could search for ViewOtherAsset to see all of the assets where you can see another asset from it. In essence, the tagging process should be the hardest part of the process (and one day I will start to explore machine learning and see if I can auto-tag pictures, but that is WAY beyond what I am good at right now!)
Note: I am going to assume you have your server configured for filestream and access set up for filetables. If not, see this Microsoft Docs page (https://docs.microsoft.com/en-us/sql/relational-databases/blob/enable-the-prerequisites-for-filetable). I will use non-transactional access, using a 2019 Express Edition SQL Server, perfect for a single user hobby database. (As I refine the code, I will be configuring it for proper concurrency, in case anyone else wishes to use the project.)
To start, I will create a database with filestream:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
CREATE DATABASE [DemoFiletable] ON PRIMARY NAME = N'DemoFiletable', FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL15.THEMEPARK\MSSQL\DATA\DemoFiletable.mdf' , SIZE = 10000KB , MAXSIZE = UNLIMITED, FILEGROWTH = 10000KB ), FILEGROUP [FilestreamData] CONTAINS FILESTREAM DEFAULT ( NAME = N'FilestreamDataFile1', FILENAME = N'c:\sql\DemoFiletableFilestream' , MAXSIZE = UNLIMITED) LOG ON ( NAME = N'DemoFiletable_log', FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL15.THEMEPARK\MSSQL\DATA\DemoFiletable_log.ldf' , SIZE = 335872KB , MAXSIZE = 2048GB , FILEGROWTH = 65536KB ) WITH CATALOG_COLLATION = DATABASE_DEFAULT; ALTER DATABASE DemoFiletable SET FILESTREAM( NON_TRANSACTED_ACCESS = FULL, DIRECTORY_NAME = N'DemoFiletable' ) WITH NO_WAIT; |
Now, I will create the filetables I will use to hold the picture files, as well as one to hold pictures that have been searched for (this is a very cheap, but effective user interface!):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
--Used to hold the entire enventory of pictures CREATE TABLE [FileAssets].[Picture] AS FILETABLE ON [PRIMARY] FILESTREAM_ON [FilestreamData] WITH ( FILETABLE_DIRECTORY = N'Pictures', FILETABLE_COLLATE_FILENAME = Latin1_General_100_CI_AS, FILETABLE_PRIMARY_KEY_CONSTRAINT_NAME=[PK_Picture] ); --used to hold a set of pictures for viewing CREATE TABLE [FileAssets].[PicturePreview] AS FILETABLE ON [PRIMARY] FILESTREAM_ON [FilestreamData] WITH ( FILETABLE_DIRECTORY = N'PicturePreview', FILETABLE_COLLATE_FILENAME = Latin1_General_100_CI_AS, FILETABLE_PRIMARY_KEY_CONSTRAINT_NAME=[PK_PicturePreview] ); |
To get the process started, I will load a few files into this database. This is as easy as going to windows and dragging files in using File Explorer from my local file folders. I will just load in 12 pictures to make this simple:
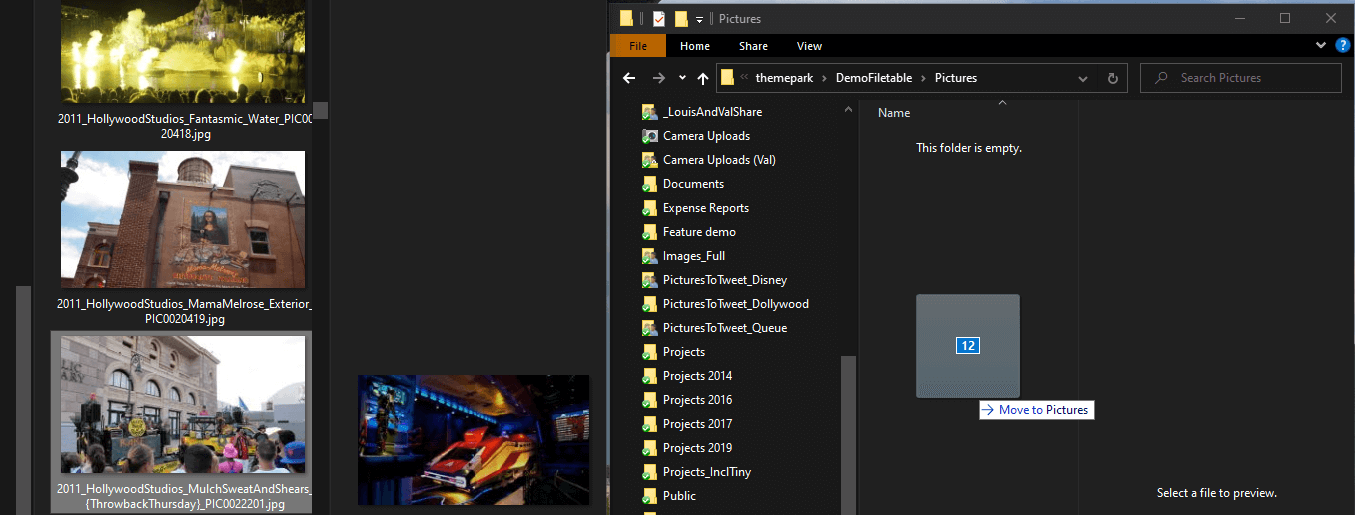
You may get a message about whether or not to copy the files without its properties. I was not using any of the properties from the image, so I said to allow it. Even after copying, the file had the details I typically care about, Date taken, dimensions, camera maker and model (helps me to know if I took the picture, or if it was mixed in and saved from online, but I post pictures I take, even if they aren’t always perfect!)
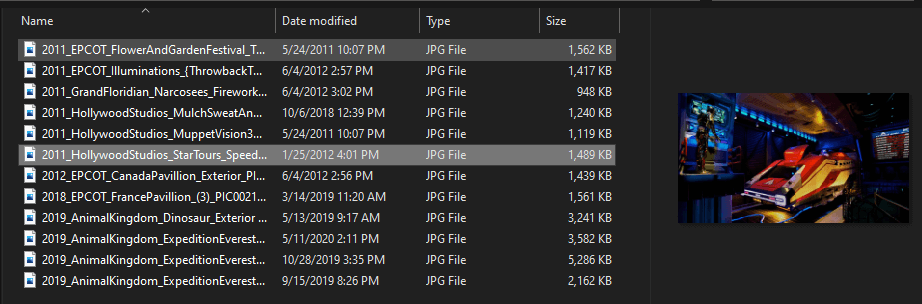
In Windows, the directory looks like any other Windows folder:
And in SQL, it looks like any other table object with a large binary value, with the fixed structure of a filetable:
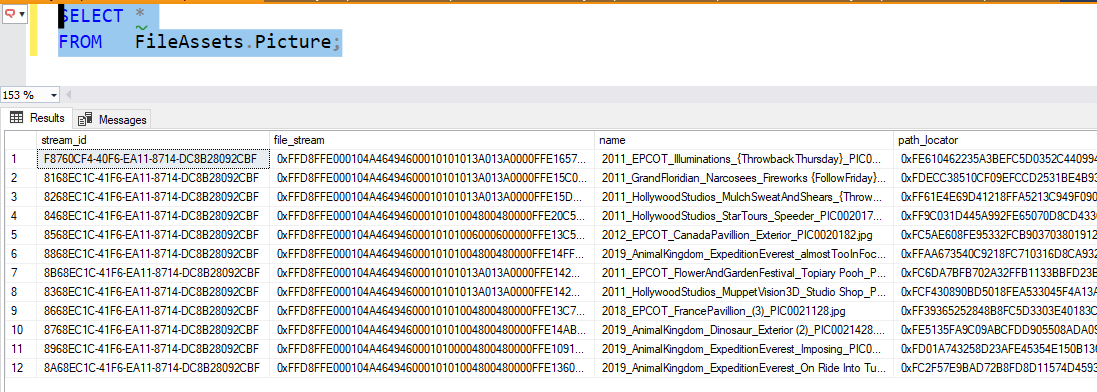
Even with just 12 files (and especially in my live “prod” db, with just over 2000 rows, it is noticeably slow to query the filetable object using SELECT *, but if you don’t include the binary column (file_stream, which in my case is 1-5MB each), it is extremely fast.
To make sense out of the name column, I will build the following view object to query the metadata. It uses a function I built to mimic functionality in other RDBMSs that will pull a value out of a string called SPLIT_PART. I do this using a function I wrote Tools.String$SplitPart (which you can find here on Github along with the numbers table I use as part of the process). The interface is:
Tools.String$SplitPart(
@inputValue nvarchar(4000), --value being split
@delimiter nchar(1) = ',', --the delimiter to split on
@position int = 1) --position in the value to get
Using that object, this is the code of the view object:
|
1 2 3 4 5 6 7 8 9 10 |
CREATE VIEW [FileAssets].[PictureDecoded] AS SELECT Tools.String$SplitPart(name, '_',1) AS Year, Tools.String$SplitPart(name, '_',2) AS ThemeParkAreaHashtag, Tools.String$SplitPart(name, '_',3) AS ThemeParkAssetHashtag, Tools.String$SplitPart(name, '_',4) AS Tags, CAST(REPLACE(Tools.String$SplitPart(name, '_',5),'.jpg','') AS varchar(10)) AS PictureNumber, name AS PhysicalFileName FROM FileAssets.Picture WHERE name LIKE '%.jpg'; |
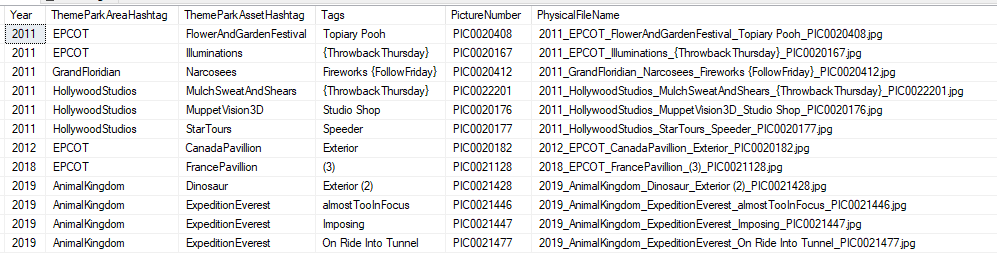
Query this view, and the output looks like this:
Using this metadata, I use it to load a database and use it to pick pictures. The database and a picture of the model, along with my most recent check-in from Red-Gate Source Control is here if you are interested. In the full version of the database, the tags are parse and normalized to their own table, naturally.
Just using this basic view object, I created a stored procedure object to let me do some quick random searches.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
CREATE PROCEDURE FileAssets.Picture$Search ( @TagLike varchar(50) = '%', @ThemeParkAreaHashTagLike varchar(50) = '%', @SamplePictureCount int = 2 ) AS --just clear the directory, so you can reload it TRUNCATE TABLE FileAssets.PicturePreview --insert into the preview directory, the binaries --that match INSERT INTO FileAssets.PicturePreview(stream_id, file_stream, name,path_locator, creation_time, last_write_time,last_access_time,is_directory, is_offline, is_hidden, is_readonly, is_archive, is_system, is_temporary) SELECT TOP (@SamplePictureCount) stream_id, file_stream, name,path_locator, creation_time, last_write_time,last_access_time,is_directory, is_offline, is_hidden, is_readonly, is_archive, is_system, is_temporary FROM FileAssets.PictureDecoded JOIN FileAssets.Picture ON Picture.name = PictureDecoded.PhysicalFileName --Picture name and path is an alternate key --and I am only using one dir in this part of --the process --a couple of like expression WHERE (ThemeParkAssetHashTag LIKE '%' + @TagLike + '%' --search for asset OR PictureDecoded.Tags LIKE '%' + @TagLike + '%') --or in the tags AND ThemeParkAreaHashTag LIKE @ThemeParkAreaHashTagLike --specify the location ORDER BY NEWID(); |
Now I can execute the procedure to give 5 random pictures::
|
1 |
EXECUTE FileAssets.Picture$Search @SamplePictureCount = 5; |
Go to the directory, and refresh, you see 5 files:
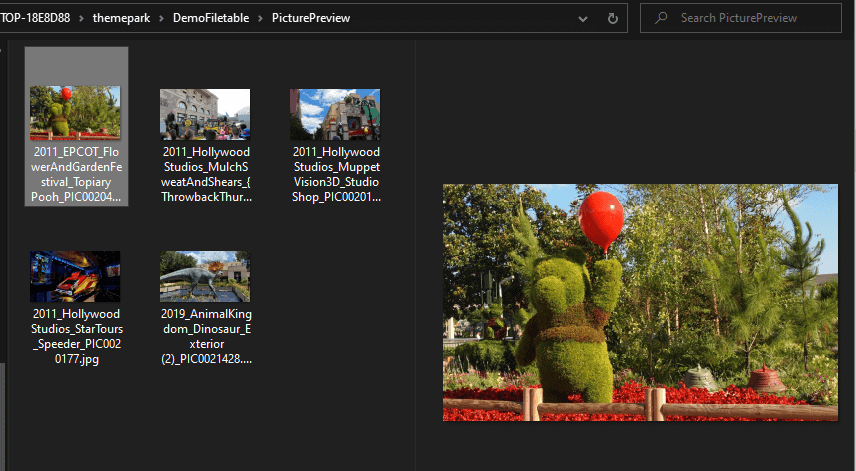
Execute it again, and you will see a different set of files. Nothing has changed in the Pictures directory or FileAssets.Picture table, so you can do what you want with these files without concern for your source data. Or using the other parameters, you can get random pictures of something specific, like my favorite roller coaster:
|
1 2 3 4 |
EXECUTE FileAssets.Picture$Search @ThemeParkAreaHashTagLike = 'AnimalKingdom', @TagLike = 'ExpeditionEverest', @SamplePictureCount = 2; |
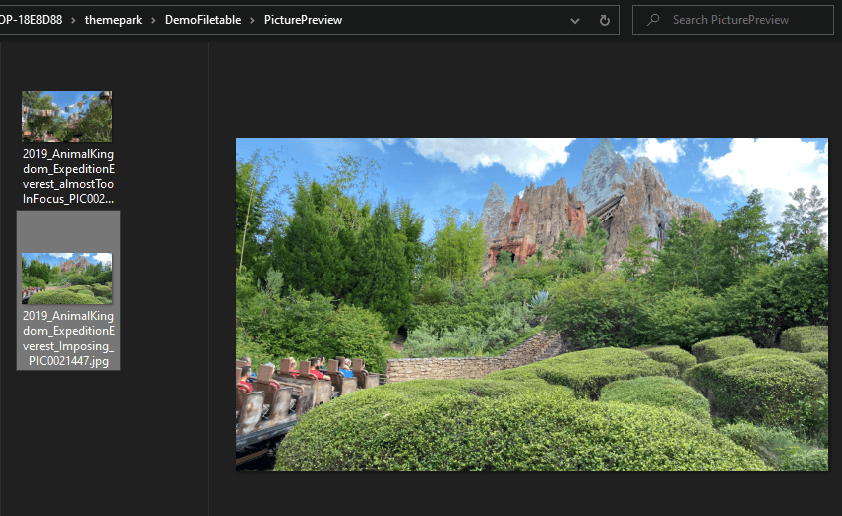
Now, my pictures are very manageable and searchable using SQL Server. The fact that the names are very standardized also helps me with searching the names in a file folder (I copy all of the files from the share into a Dropbox folder so I have access to the files everywhere I am as well.)
And additional cool thing is that even on my Express Edition local server, the filetable data is backed up with the database, so when I backup the database, it backs up my pictures in addition to the textual data. That extra backup, along with the copy of the files in Dropbox give me extra relief that I have a decent backup if something gets corrupted.
With just a little bit of configuration, and a little bit of code, I have a simple database of my images that I can search using T-SQL in a manner that is a lot more powerful that what I can reasonably do using File Explorer, along with the ability to keep history of how the pictures are used. This would be very useful for any photographer with a stock of pictures that they want to search and keep history of, even if it is just baby pictures…of the puppy.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved





Load comments