
SQL Server computed columns let you define a column whose value is derived from other columns via an expression, optionally persisted (stored) and indexable. Combined with a user-defined scalar function, computed columns become a powerful pattern for precomputing text transformations – phonetic encodings, sort keys, normalised forms, identity-independent comparison keys – once per row rather than per query.
This article demonstrates the pattern using two worked examples: textonym detection (finding words that share the same phone-keypad digit sequence, like ‘cat’ and ‘act’ both mapping to 228) and anagram detection (finding words that share the same sorted-character string).
The same technique applies to case-insensitive search keys, accent-stripped search keys, phonetic match keys (Soundex, Metaphone), and any transformation where the cost of computing matters enough to precompute. Covers the pattern’s performance characteristics, indexability, and when to persist vs compute on read.
Textonyms
When you typed in words on a mobile phone’s digital pad to ‘text’ someone, there was always the possibility of a particular combination of digits being ambiguous in that it corresponds to more than one word. Either you had ‘autocorrect’ on, and you chose which word you want, or you had to press repeatedly to cycle through the characters as you typed the word.
These alternative words for the same string of numbers are called textonyms. What percentage of common words in English would suffer from this sort of ambiguity, what are the strings of numbers that represent a large number of textonyms? What ambiguous text strings match words where all the characters are different? What is the largest group of words represented by a texting digit string?
This a very easy problem to solve in SQL Server. The only irritation is that, although the code is relatively simple, and you can go on to make all sorts of interesting discoveries about possible misunderstandings when texting without checking the screen, the initial setup is not quick, because you are having to transform around 60,000 words. In truth this really doesn’t matter a bit but as we so often have to do other similar transformations on data when inserting it into a table, I thought it would be interesting to explore the process to see where one could speed this up.
We’ll assume that the digit keys are mapped to letters as follows:
|
1 2 3 4 5 6 7 8 |
2 -> ABC 3 -> DEF 4 -> GHI 5 -> JKL 6 -> MNO 7 -> PQRS 8 -> TUV 9 -> WXYZ |
Finding Textonyms using SQL
Creating the table
We’ll assume that you have a table with all the common words in it. If you haven’t got one of these, the data is in a zipped file with a link at the end of the article. One of the Blog posts linked to in the references section has some hints on how to read this into a database table of common words.
Our first task is to create the table with the 600,000 common words of the English language in it in one column, and the numeric ‘text’ version in the other
|
1 2 3 4 5 6 7 8 9 10 11 12 |
text_Version word ---------------------- --------------------------- 224 aah 22738275 aardvark 227382757 aardvarks 222287 abacus 22228737 abacuses 2225663 abalone 22256637 abalones 2226366 abandon 222636633 abandoned 2226366464 abandoning |
Now. Let’s consider how we convert a string into a text version. Doing a single string is pretty trivial.
|
1 2 3 4 5 6 7 8 9 10 11 |
DECLARE @word VARCHAR(2000);DECLARE @word VARCHAR(2000); SELECT @word = 'I do not like to get the news, because there has never been an era when so many things were going so right for so many of the wrong persons'; SELECT @word = REPLACE(@word, The_character, The_digit) FROM (VALUES (2, 'A'), (2, 'B'), (2, 'C'), (3, 'D'), (3, 'E'), (3, 'F'), (4, 'G'), (4, 'H'), (4, 'I'), (5, 'J') , (5, 'K'), (5, 'L'), (6, 'M'), (6, 'N'), (6, 'O'), (7, 'P'), (7, 'Q'), (7, 'R'), (7, 'S'), (8, 'T') , (8, 'U'), (8, 'V'), (9, 'W'), (9, 'X'), (9, 'Y'), (9, 'Z')) mapping (The_digit, The_character); SELECT @word AS TheTextVersion; /* Which gives 4 36 668 5453 86 438 843 6397, 2322873 84373 427 63837 2336 26 372 9436 76 6269 844647 9373 46464 76 74448 367 76 6269 63 843 97664 7377667 */ |
There is, of course, some disguised iteration here, and this is not a simple expression. Experienced database developers will, if nobody else is looking, get a faster transformation by doing many nested REPLACE functions, one for each letter of the alphabet. This turns it into a simple expression that is far more versatile.
Just to save space, we will imagine for a moment that there were only seven letters in the alphabet. If this were the case it would look like this
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
SELECT REPLACE( REPLACE( REPLACE( REPLACE( REPLACE( REPLACE( REPLACE( 'Gee. A gaffe. A faded bad dad effaced a facade', 'A', '2' ), 'B', '2' ), 'C', '2' ), 'D', '3' ), 'E', '3' ), 'F', '3' ), 'G', '4' ); /* giving 433. 2 42333. 2 32333 223 323 3332233 2 322233.*/ |
The language has become rather weird when restricted to these seven characters but the full expression for the entire alphabet is tiresome to display in the article. Incidentally, we can find just those words that use these seven characters very simply with this expression.
|
1 |
Select word from commonwords where word not like '%[^abcdefg]%'--words that just use these characters |
Now, can this first method translate easily to around 60,000 common words in the English language?
We convert both of these into a function and fill the table
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
IF EXISTS ( SELECT * FROM INFORMATION_SCHEMA.ROUTINES WHERE ROUTINE_NAME LIKE 'ConvertToNumbers' AND ROUTINE_SCHEMA = 'dbo' ) SET NOEXEC ON; GO -- if the routine exists this stub creation stem is parsed but not executed CREATE FUNCTION ConvertToNumbers (@word VARCHAR(2000)) RETURNS VARCHAR(2000) AS BEGIN RETURN @word; END; GO -- the following section will be always executed SET NOEXEC OFF; GO ALTER FUNCTION ConvertToNumbers (@word VARCHAR(2000)) RETURNS VARCHAR(2000) AS BEGIN SELECT @Word = REPLACE(@word, The_character, The_digit) FROM (VALUES (2,'A'),(2,'B'),(2,'C'),(3,'D'),(3,'E'),(3,'F'),(4,'G'),(4,'H'), (4,'I'),(5,'J'),(5,'K'),(5,'L'),(6, 'M'),(6, 'N'),(6, 'O'),(7,'P'), (7,'Q'),(7,'R'),(7,'S'),(8, 'T'),(8, 'U'),(8, 'V'),(9, 'W'), (9, 'X'), (9, 'Y'), (9, 'Z'))mapping(The_digit,The_character) RETURN @Word; END; GO if exists (select * from tempdb.sys.tables where name like '#CommonWordsAndTexting%') Drop table #CommonWordsAndTexting; go select isnull(convert(varchar(22),string),'') as word, convert(varchar(22),dbo.ConvertToNumbers(string)) as Text_Version into #CommonWordsAndTexting from commonwords alter table #CommonWordsAndTexting add primary key (word) |
Hunting for Textonyms in SQL
Once we have our table, the rest is trivial. We can do all sorts of analysis on the results. First we’ll find what percentage of common words of the English language are unique in terms of their text digits.
|
1 2 3 4 5 6 7 8 9 10 11 |
/* now we can find what percentage of text versions map to only one string */ Select Count(*)*100 /(Select count(*) from #CommonWordsAndTexting) as PercentageUnique from ( Select max(word), Text_Version from #CommonWordsAndTexting group by Text_Version having count(*) =1 --51547 )Unique_Textonyms(word,textonym) /* PercentageUnique ---------------- 85 */ |
85% is a pretty high proportion which is why ‘Texting’ became so popular with phone users.
You can easily find the text digits with the most ambiguity, which represent the most textonyms. The SQL is a bit more complex because there could be more than one in first place.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
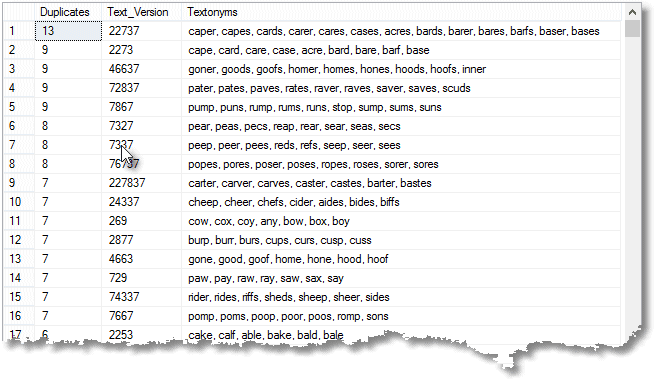
SELECT duplicates, Text_Version, STUFF( ( SELECT ', ' + word FROM #CommonWordsAndTexting t WHERE t.Text_Version = ProblemTextonyms.Text_Version FOR XML PATH(''), TYPE ).value('.', 'varchar(max)'), 1, 2, '' ) AS Textonyms FROM ( SELECT COUNT(*), text_version FROM #CommonWordsAndTexting GROUP BY text_version HAVING COUNT(*) = ( SELECT TOP 1 COUNT(*) FROM #CommonWordsAndTexting GROUP BY Text_Version HAVING COUNT(*) > 1 ORDER BY COUNT(*) DESC ) )ProblemTextonyms(duplicates, Text_Version); /* duplicates Text_Version ---------- ------------ ------------------------------------------------------------------------------------------ 13 22737 acres, bards, barer, bares, barfs, baser, bases, caper, capes, cards, carer, cares, cases */ |
You can list all the ambiguous strings of text digits if you wish.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
SELECT Duplicates, Text_Version, Textonyms FROM ( SELECT Duplicates, Text_Version, STUFF((SELECT ', ' + word FROM #CommonWordsAndTexting t WHERE t.Text_version = ProblemTextonyms.Text_version FOR XML PATH(''), TYPE ).value('.', 'varchar(max)'), 1, 2, '' ) AS Textonyms FROM (SELECT COUNT(*), Text_version FROM #CommonWordsAndTexting GROUP BY Text_version HAVING COUNT(*) > 2 ) ProblemTextonyms(Duplicates, Text_Version) UNION ALL SELECT 2, Text_version, MAX(word) + ', ' + MIN(word) FROM #CommonWordsAndTexting GROUP BY Text_version HAVING COUNT(*) = 2 ) f ORDER BY Duplicates DESC; |
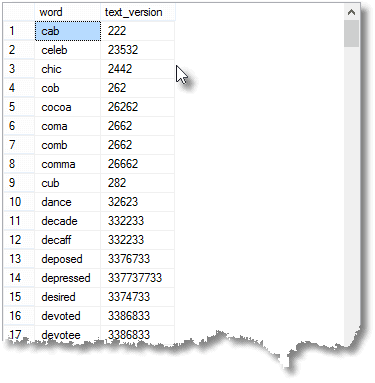
We can find all palindromic text versions for words that aren’t palindromes.
|
1 2 3 |
SELECT word, text_version FROM #CommonWordsAndTexting WHERE text_version = REVERSE(text_version) AND word <> REVERSE(word); |
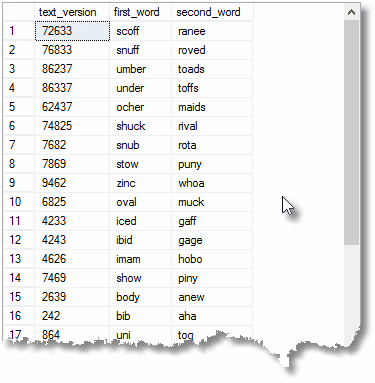
We can find all the duplicates that do not have a single letter in common …
|
1 2 3 4 5 6 7 8 9 |
SELECT text_version, first_word, second_word FROM (SELECT Text_Version, MAX(word), MIN(word) FROM #CommonWordsAndTexting GROUP BY Text_Version HAVING COUNT(*) = 2 ) duplicates(text_version, first_word, second_word) WHERE first_word NOT LIKE '%[' + second_word + ']%' ORDER BY LEN(text_version) DESC; |
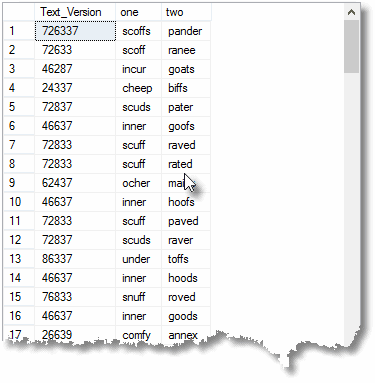
… or we can find every pair of textonym that have no character in common.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
SELECT Text_Version, one, two FROM ( SELECT The_first.Text_Version, CASE WHEN The_first.word > The_Second.word THEN The_first.word ELSE The_Second.word END AS one, CASE WHEN The_first.word < The_Second.word THEN The_first.word ELSE The_Second.word END AS two FROM #CommonWordsAndTexting The_first INNER JOIN #CommonWordsAndTexting The_Second ON The_first.Text_Version = The_Second.Text_Version WHERE The_first.word NOT LIKE '%[' + The_Second.word + ']%' ) NothingLike(Text_Version, one, two) GROUP BY Text_Version, one, two ORDER BY LEN(Text_Version) DESC; |
Alternative ways of doing data transformations.
There is a lot we can do once we have our table. Before we got started with exploring textonyms, we weren’t bothered about performance as it was a one-off process and though it took several seconds, it was of little concern. The same goes for the SQL that explored the textonyms. However, what is the speediest way of creating a table of common words and their text digits? I didn’t like that function: it seemed as if it would be slow. I’m often creating ETL routines for importing text and doing transformations on them so now we have a decent-sized sample, I thought it would be amusing to find out.
To time an import routine, you really have to time the whole period that it takes from the creation of the table to getting a result. In my case, I needed to time the entire period from start, having nothing but the table of common words, to the point at which we have it confirmed that 85% of them are unique and unambiguous. I tried out five different approaches to the task, but I’ve kept the code separate as a download because it is otherwise a bit distracting. (I actually tried out some other approaches such as a Quirky Update and XML-based approach that were both impossibly slow.)
The first thing to try out was to take away the function entirely, and do the transformation within the SQL expression that inserted the words into our table.
Remember that expression that only did the first seven letters of the alphabet? We expand it to do them all. It’s big and it’s ugly, but it reduces the end-to-end time by around 20%. We reckon that we can do better by doing this simple expression in a table-valued function. Well, it is actually about the same time.
What about moving the logic of the data transformation into the table itself as a calculated column? We can do this easily with a simple expression and by doing so we deduce the time by a half. This is a saving worth pursuing. You can, of course, use a user-defined function in a computed column expression but the drawback to this is that SQL Server chooses a sequential plan rather than the faster parallel plan. Also they are difficult in temporary tables and you have to make them deterministic so that you can then specify constraints on the column or make them persisted. All in all, it is better to keep them to sql scalar expressions if possible. However, scalar functions can be made to work.
Using scalar functions in computed columns
Here is a simple example of this technique
Imagine that we want to have postcode information extracted from an address. We could use a calculated column to do the work so that the column automatically remains correct after any type of changes to the data.
We might do this
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 |
/* extract a UK postcode from an address string, returning the address string */ /* first we tear down any existing version */ IF EXISTS (SELECT * FROM INFORMATION_SCHEMA.Tables WHERE TABLE_NAME LIKE 'Addresses' AND TABLE_SCHEMA = 'dbo' ) DROP TABLE addresses; GO IF EXISTS ( SELECT * FROM INFORMATION_SCHEMA.ROUTINES WHERE ROUTINE_NAME LIKE 'PostcodeFrom' AND ROUTINE_SCHEMA = 'dbo' AND ROUTINE_TYPE = 'FUNCTION' ) DROP FUNCTION dbo.PostcodeFrom; GO CREATE FUNCTION dbo.PostcodeFrom(@Address VARCHAR(200)) RETURNS VARCHAR(10) WITH SCHEMABINDING AS BEGIN DECLARE @postcode VARCHAR(10); SELECT TOP 1 @postcode = SUBSTRING(@address, start, Thelength) FROM ( SELECT Thelength, PATINDEX([matched], @Address) AS start --there may be more than one FROM ( VALUES('%', 0), ('%[A-Z][0-9][ ][0-9][A-Z][A-Z]%', 6), ('%[A-Z][A-Z0-9][A-Z0-9][ ][0-9][A-Z][A-Z]%', 7), ('%[A-Z][A-Z][0-9][A-Z0-9][ ][0-9][A-Z][A-Z]%', 8) ) possibilities( matched, Thelength ) ) f WHERE start > 0 ORDER BY Thelength DESC; RETURN @postcode; END; GO CREATE TABLE Addresses ( Address_ID INT IDENTITY PRIMARY KEY, [Address] VARCHAR(200) NOT NULL, Postcode AS dbo.PostcodeFrom(Address) PERSISTED NOT NULL ); INSERT INTO Addresses(Address) -- insert some sample data SELECT [address] FROM ( VALUES('The Lodge. U Cathedral Avenue. Belfast CN88 9RR UK'), ('76 High St, Molesey, West Molesey KT8 2LY, UK'), ('11 Lordsfield Gardens, Overton, Basingstoke RG25 3EW, UK'), ('2124 Market Way, Gateshead NE11 0RE, UK'), ('2 Nant-Y-Patrick, Saint Asaph LL17 0BN, UK'), ('40 Milner Rd, Heswall, Wirral CH60 5RZ, UK'), ('1 B2082, Tenterden TN30 7LJ, UK'), ('Dean Ln, York YO43 4UN, UK'), ('2 Parkgate Rd, Wallington SM6 0AE, UK'), ('34-40 A474, Pontardawe, Swansea SA8 4SL, UK'), ('21 Greenslade Rd, Walsall WS5 3QH, UK'), ('1 Vine St, Lincoln LN2 5HZ, UK'), ('16B Wrottesley Rd, London NW10 5YL, UK'), ('25 Delamere Rd, Birmingham B28 0EP, UK'), ('1 Monkwell Square, London EC2Y 1WP, UK'), ('28 Main St, Glengarnock, Beith KA14 3AT, UK'), ('53 Northgate St, Devizes SN10 1JJ, UK'), ('35B Crouch Hill, London N4 4AP, UK'), ('3 Blandford Ave, Luton LU2 7AX'), ('387 Daiglen Dr, South Ockendon RM15 5AJ, UK'), ('18 Invertiel Terrace, Kirkcaldy KY1 1TF, UK'), ('92 Cleave Ave, Hayes UB3 4HB, UK'), ('11 Mutley Rd, Plymouth PL3 4SA, UK'), ('2 Butchers Ln, Walton on the Naze CO14 8QU, UK'), ('Unnamed Road, Llangadog SA19 9SS, UK'), ('10 Howards Way, Rustington, Littlehampton BN16 2LT, UK'), ('Lilac Cottage. 903 Lower Acacia Lane. Leeds WP 6AZ UK'), ('The Barn. 52 Cathedral Road. Wakefield RHCI 1JR UK') ) addresses( [address] ); SELECT * FROM Addresses; |
We’ve made the function deterministic by using WITH SCHEMABINDING and this has allowed us to persist the calculated data. We could put an index on this column as well.
Trying out the Technique to find Anagrams
We can us the technique to find words that are anagrams of each other. From end to end is a ten-second wait, but once you have the table then there there is a lot of ways you can explore the results. I was somewhat surprised to find that the longest number of words that are all anagrams of each other is seven.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 |
----- IF EXISTS (SELECT * FROM sys.tables WHERE name LIKE 'CommonWordsAndLetters%') DROP TABLE CommonWordsAndLetters; GO IF OBJECT_ID(N'dbo.SortedVersionOfWord') IS NOT NULL DROP FUNCTION dbo.SortedVersionOfWord; GO CREATE FUNCTION dbo.SortedVersionOfWord(@anUnsortedword VARCHAR(22)) RETURNS VARCHAR(24) WITH SCHEMABINDING, EXECUTE AS CALLER AS BEGIN RETURN ( SELECT SUBSTRING(@anUnsortedword, numbers.number, 1) AS TheCharacter FROM (VALUES(1), (2), (3), (4), (5), (6), (7), (8), (9), (10), (11), (12), (13), (14), (15), (16), (17), (18), (19), (20), (21), (22), (23),(24) ) numbers(number) WHERE numbers.number < = LEN(@anUnsortedword) ORDER BY TheCharacter FOR XML PATH(''), TYPE ).value('.', 'varchar(max)'); END; GO CREATE TABLE CommonWordsAndLetters ( word VARCHAR(22) NOT NULL, letters AS dbo.SortedVersionOfWord(word) PERSISTED NOT NULL ); ALTER TABLE CommonWordsAndLetters ADD PRIMARY KEY(word); INSERT INTO CommonWordsAndLetters SELECT String FROM commonwords; SELECT f.Anagram_List FROM ( SELECT Anagrams.duplicates, STUFF((SELECT ', ' + t.word FROM CommonWordsAndLetters t WHERE t.letters = Anagrams.letters FOR XML PATH(''), TYPE ).value('.', 'varchar(max)'),1,2,'') AS Anagram_List FROM (SELECT COUNT(*) AS duplicates, letters FROM CommonWordsAndLetters GROUP BY letters HAVING COUNT(*) > 2 ) Anagrams(duplicates, letters) UNION ALL SELECT 2, MAX(word) + ', ' + MIN(word) FROM CommonWordsAndLetters GROUP BY letters HAVING COUNT(*) = 2 ) f ORDER BY f.duplicates DESC; |
Which will give this…

Conclusion.
With any functionality that you put into a database, you have a number of possibilities. Even with this very simple task, importing a table of common words and doing a transformation on it, there were many different ways of doing it. In this case, the use of a computed column turned out to be the best approach but you can’t assume that this is necessarily the general case. If there is a general rule it is that one should avoid duplicating functionality if it can be avoided. However, if code like this goes into a trigger or a computed column, it can be exasperatingly tricky to find in a hurry. The great advantage, though, is that data can be entered via a simple sql expression without any thought to applying the transformation to each row as part of the process. It happens auto-‘magically’. My instinct is to place this type of transformation as close as possible to the data.
References

This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved






Load comments