
Having spent a lot of my working life trying to preserve the integrity of data, there was a certain intriguing novelty in the idea of pseudonymizing data. One of the standard techniques of pseudonymization is that of shuffling data columns as though you are shuffling cards. The original values are kept but placed in the wrong rows. The problems come with uncommon values. If you are pseudonymizing a medical database that is required for research purposes on people with potentially embarrassing diseases, and it appears on the dark web, anyone with a rare or unusual surname or first-name comes up on the list, so the shuffle doesn’t help the privacy of Fortescue Ceresole, or whatever his name may be.
If you are spoofing data entirely, you don’t necessarily have this problem because your constructed value will have no relationship to the original value. If it comes from a list of common names or if you randomly create a name ‘Thomas’, it will have no relationship to the original names in the database as long as you did things correctly and shuffle the list. Although a Markov string can produce an identical name that is uncommon, it can be eliminated from the list by an outer join with the original data.
After you shuffle data, you ‘zip’ it. Zipping lists is something you come across in procedural programming, and Linq has a good example. A .net array has an order, and all you are doing is to join by the order of the element in the list. If you randomize that order, you get a shuffle.
There are several ways to randomize the order of a list in SQL Server. Probably the easiest is to use the ORDER BY NewID() trick. This produces a different order every time. Here is a worked example using the superior window function.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
SELECT TheFirstName.FirstName + ' ' + TheLastName.lastName AS TheName FROM ( SELECT Person.FirstName, Row_Number() OVER (ORDER BY NewId()) AS TheKey FROM AdventureWorks2016.Person.Person ) AS TheFirstName(FirstName, TheKEY) INNER JOIN ( SELECT Person.LastName, Row_Number() OVER (ORDER BY NewId()) AS TheKey FROM AdventureWorks2016.Person.Person ) AS TheLastName(lastName, TheKEY) ON TheFirstName.TheKEY = TheLastName.TheKEY; |
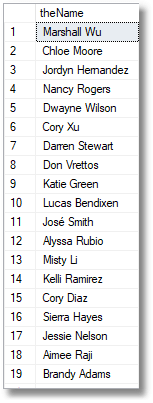
You can, of course, use static lists as tables that you keep for the purpose. (Yes, sir: I’m an avid collector). We’ll add an address.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
SELECT TheFirstName.FirstName + ' ' + TheLastName.lastName + '; ' + TheTown.Town + ', ' + TheCity.city + ', ' + Thecounty.county + ', UK' COLLATE DATABASE_DEFAULT AS TheNameAndAddress FROM ( SELECT Person.FirstName, Row_Number() OVER (ORDER BY NewId()) AS TheKey FROM AdventureWorks2016.Person.Person ) AS TheFirstName(FirstName, TheKEY) INNER JOIN ( SELECT Person.LastName, Row_Number() OVER (ORDER BY NewId()) AS TheKey FROM AdventureWorks2016.Person.Person ) AS TheLastName(lastName, TheKEY) ON TheFirstName.TheKEY = TheLastName.TheKEY INNER JOIN ( SELECT town.town, Row_Number() OVER (ORDER BY NewId()) AS TheKey FROM dbo.town ) AS TheTown(Town, TheKEY) ON TheFirstName.TheKEY = TheTown.TheKEY INNER JOIN ( SELECT city.city, Row_Number() OVER (ORDER BY NewId()) AS TheKey FROM dbo.city ) AS TheCity(city, TheKEY) ON TheFirstName.TheKEY = TheCity.TheKEY INNER JOIN ( SELECT county.county, Row_Number() OVER (ORDER BY NewId()) AS TheKey FROM dbo.county ) AS Thecounty(county, TheKEY) ON TheFirstName.TheKEY = Thecounty.TheKEY; |
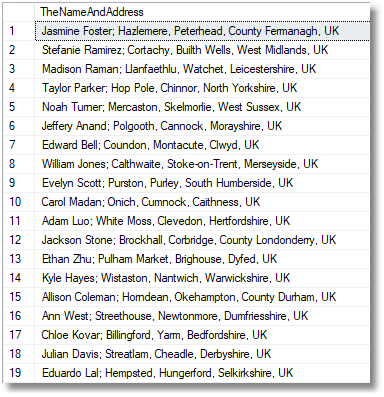
It is actually much easier to do this type of process in SQL Data Generator from text lists if you are creating entirely new data for tests. The complication of doing it in code is that you need more of every list than the rows you have in the dataset. In this case we only produced only ninety-four items because there are only that many counties. You could of course produce a table of 94000 counties easily enough, but it is a bit clunky.
|
1 2 3 4 5 6 |
SELECT county.county, Row_Number() OVER (ORDER BY NewId()) AS TheKey FROM dbo.county CROSS JOIN (VALUES (1),(2),(3),(4),(5),(6),(7),(8),(9),(10))f(number) CROSS JOIN (VALUES (1),(2),(3),(4),(5),(6),(7),(8),(9),(10))g(number) CROSS JOIN (VALUES (1),(2),(3),(4),(5),(6),(7),(8),(9),(10))h(number) CROSS JOIN (VALUES (1),(2),(3),(4),(5),(6),(7),(8),(9),(10))i(number) |
We will end by simply pseudonymizing a table. I know that the Adventureworks person.person table isn’t real data but it will do as a demonstration, and it allows you to play along. Here we simply shuffle all the elements in the name and leave everything else so that keys are intact. Because we are just shuffling data, we get the correct number of rows.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 |
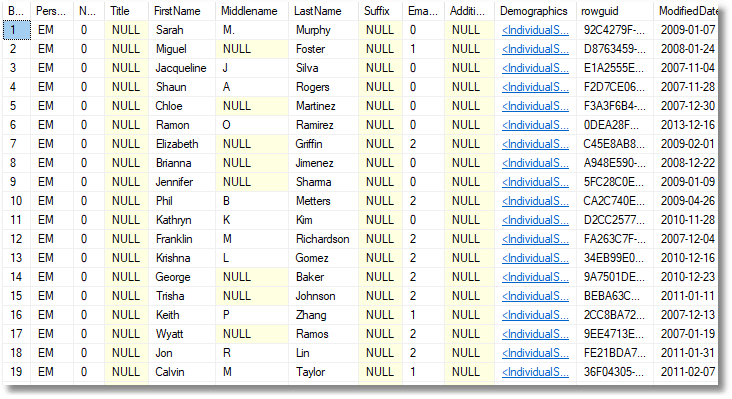
DECLARE @Title TABLE (title NVARCHAR(80) NULL, TheKey INT NOT NULL PRIMARY KEY); DECLARE @FirstName TABLE (FirstName NVARCHAR(50) NOT NULL, TheKey INT NOT NULL PRIMARY KEY); DECLARE @MiddleName TABLE (MiddleName NVARCHAR(50) NULL, TheKey INT NOT NULL PRIMARY KEY); DECLARE @LastName TABLE (LastName NVARCHAR(50) NOT NULL, TheKey INT NOT NULL PRIMARY KEY); DECLARE @Suffix TABLE (Suffix NVARCHAR(10) NULL, TheKey INT NOT NULL PRIMARY KEY); INSERT INTO @Title (title, TheKey) SELECT Person.Title, Row_Number() OVER (ORDER BY NewId()) FROM Person.Person; INSERT INTO @FirstName (FirstName, TheKey) SELECT Person.FirstName, Row_Number() OVER (ORDER BY NewId()) FROM Person.Person; INSERT INTO @MiddleName (MiddleName, TheKey) SELECT Person.MiddleName, Row_Number() OVER (ORDER BY NewId()) FROM Person.Person; INSERT INTO @LastName (LastName, TheKey) SELECT Person.LastName, Row_Number() OVER (ORDER BY NewId()) FROM Person.Person; INSERT INTO @Suffix (Suffix, TheKey) SELECT Person.Suffix, Row_Number() OVER (ORDER BY NewId()) FROM Person.Person; -- SELECT BusinessEntityID, PersonType, RowsWithoutName.NameStyle, TheTitle.title, TheFirstName.FirstName, TheMiddlename.MiddleName, TheLastName.LastName, TheSuffix.Suffix, RowsWithoutName.EmailPromotion, RowsWithoutName.AdditionalContactInfo, RowsWithoutName.Demographics, RowsWithoutName.rowguid, RowsWithoutName.ModifiedDate FROM ( SELECT Person.BusinessEntityID, Person.PersonType, Person.NameStyle, Person.EmailPromotion, Person.AdditionalContactInfo, Person.Demographics, Person.rowguid, Person.ModifiedDate, Row_Number() OVER (ORDER BY NewId()) AS TheKey FROM Person.Person ) AS RowsWithoutName INNER JOIN @Title AS TheTitle ON RowsWithoutName.TheKey = TheTitle.TheKey INNER JOIN --add the randomised firstname field @FirstName AS TheFirstName ON RowsWithoutName.TheKey = TheFirstName.TheKey INNER JOIN --add the randomised MiddleName field as well @MiddleName AS TheMiddlename ON RowsWithoutName.TheKey = TheMiddlename.TheKey INNER JOIN --and the randomised lastname field @LastName AS TheLastName ON RowsWithoutName.TheKey = TheLastName.TheKey INNER JOIN --and lastly the randomised suffix field as well @Suffix AS TheSuffix ON RowsWithoutName.TheKey = TheSuffix.TheKey ORDER BY RowsWithoutName.BusinessEntityID; |
Which gives a different result, but of the right number of rows, every time!
Summary
Shuffling and zipping are techniques that have a great value in pseudonymization but they aren’t sufficient to produce spoof data. Shuffling is fine until you come across uncommon values which could give a clue to someone attempting to reverse the process. Remember that someone only needs to unmask just a few names to hit the headlines, especially if they include the medical records of the governor of Massachusetts. However, zipping is a great way of inserting completely spoofed data into a table.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved






Load comments