
The technique I will use in this blog can be used to load a graph with existing data you have. In my blog Using a Modeling Tool To Draw and Import a Graph into SQL Server, I demonstrated how to use a free (and nicely featured) tool to draw a graph and then get that data into a set of tables using a Powershell script. Now the task is to get this (or any data) into edges and nodes.
To refresh you memory, using this query:
|
1 2 3 4 5 6 7 8 9 |
SELECT * FROM NodeStaging.Node WHERE Node.Filename = 'NodeType-DefaultEdgeType-Sample'; SELECT * FROM NodeStaging.Edge WHERE Edge.Filename = 'NodeType-DefaultEdgeType-Sample' ORDER BY Edge.FromNodeId,Edge.ToNodeId; GO |
You can see the data I am going to load:
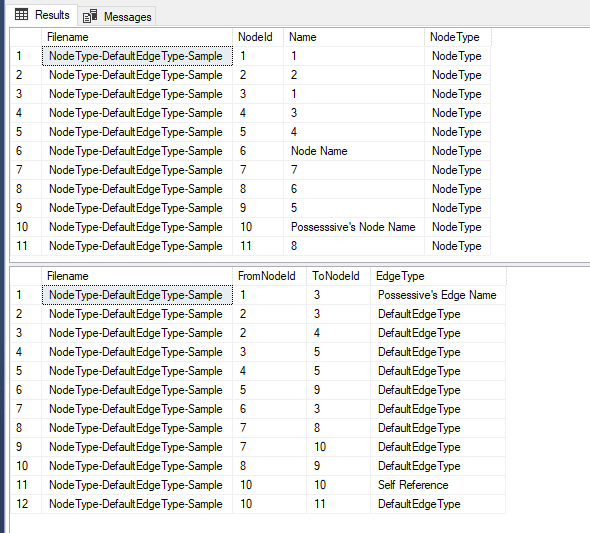
To load this data into a set of SQL Graph tables, I will create the next two tables:
|
1 2 3 4 5 6 7 8 |
DROP TABLE IF EXISTS NodeType, DefaultEdgeType; CREATE TABLE NodeType ( NodeId int NOT NULL UNIQUE, NodeName nvarchar(30) NOT NULL ) AS NODE; CREATE TABLE DefaultEdgeType AS EDGE |
The first method is to just load the data using straightforward joins. The nodes are simple, just take the nodes and insert them. Adding nodes to a set of graph tables is pretty simple. The tables are just tables, and all the graph internals are done for you.
|
1 2 3 4 5 |
INSERT INTO dbo.NodeType(NodeId, NodeName) SELECT NodeId, Node.Name FROM NodeStaging.Node WHERE FileName = 'NodeType-DefaultEdgeType-Sample' AND Node.NodeType = 'NodeType'; |
But the edges are where things get “complicated”, because you need to get the node_id values for the from and to nodes.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
WITH BaseRows AS ( --note, for this example it is technically not needed --to do this join, but you usually will need other data. SELECT FromNode.NodeId AS FromNodeId, ToNode.NodeId AS ToNodeId FROM NodeStaging.Edge JOIN NodeStaging.Node AS FromNode ON FromNode.NodeId = Edge.FromNodeId JOIN NodeStaging.Node AS ToNode ON ToNode.NodeId = Edge.ToNodeId --extra where stuff to deal with the fact that I am loading from my copy database WHERE Edge.Filename = 'NodeType-DefaultEdgeType-Sample' AND Edge.EdgeType = 'DefaultEdgeType' AND FromNode.FileName = 'NodeType-DefaultEdgeType-Sample' AND FromNode.NodeType = 'NodeType' AND ToNode.FileName = 'NodeType-DefaultEdgeType-Sample' AND ToNode.NodeType = 'NodeType') INSERT INTO dbo.DefaultEdgeType ($From_id, $to_id) SELECT FromNode.$node_id AS FromNode, ToNode.$node_id AS ToNode FROM BaseRows JOIN dbo.NodeType AS FromNode ON FromNode.NodeId = BaseRows.FromNodeId JOIN dbo.NodeType AS ToNode ON ToNode.NodeId = BaseRows.ToNodeId; |
Now though, you a set of nodes you can easily query:
|
1 2 3 4 5 |
SELECT FromNode.NodeName, ToNode.NodeName FROM dbo.NodeType AS FromNode, dbo.DefaultEdgeType, dbo.NodeType AS ToNode WHERE MATCH(FromNode-(DefaultEdgeType)->ToNode) |
This returns:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
NodeName NodeName ------------------------------ ------------------------------ 3 4 1 4 2 1 2 3 Node Name 1 4 5 6 5 7 6 7 Possesssive's Node Name Possesssive's Node Name 8 |
While this method is perfectly acceptable, due to the joins it may not be quite as fast if you are loading a lot of data. Luckily there is an easier way that is not super obvious, but actually makes loading a graph from existing data very easy.
The idea lies in the data structure of the values you see in the special columns. The node_id values look like this:
|
1 |
{"type":"node","schema":"dbo","table":"NodeType","id":0} |
As I demonstrated here, that value actually doesn’t exist in the database, but is really just shorthand for a few integer values (which is really annoying when error handling, hence the blog). But this shorthand is something you can exploit to load data because you can form the data yourself.
So I will clear the tables:
|
1 2 |
DELETE FROM NodeType ; DELETE FROM DefaultEdgeType; |
To create the string, we need to add several values together in our insert. You can do this with CONCAT and put together the value, but to simplify, I will create a user-defined function that will return the node mapping value that looks just the string you see in the values:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
IF NOT EXISTS (SELECT * FROM sys.schemas WHERE name = 'Tools') EXEC ('CREATE SCHEMA Tools') GO CREATE OR ALTER FUNCTION Tools.GraphTable$GenerateId( @Type sysname, --Node or Edge @SchemaName sysname , --Schema of the Node or Edge Table @tableName sysname, --Name of the Node or Edge Table @graphItemId int -- The id of the graph object ) RETURNS nvarchar(2000) AS BEGIN RETURN CONCAT('{"type":"', @Type , '","schema":"', @schemaName, '","table":"',@tableName, '","id":', @graphItemId,'}') END; |
For example, say you want a node for the table we are building, like for id =1:
|
1 2 |
SELECT Tools.[GraphTable$GenerateId] ('node','dbo','NodeType',1); |
This returns:
|
1 |
{"type":"node","schema":"dbo","table":"NodeType","id":1} |
And luckily, not only can you use this when querying for a value, but you can also create a new row’s graph surrogate value by providing your own. By taking control of the id values, things get a lot easier. Of course, while it will greatly simplify the edge loading, you have one easy step to take when loading a node, providing the id value:
So the insert becomes simply (I am including the id value because we needed it in the previous example and left it in the table):
|
1 2 3 4 5 6 7 |
INSERT INTO dbo.NodeType($Node_id, NodeId, NodeName) SELECT dbo.[GraphTable$GenerateId] ('node','dbo','NodeType',NodeId), NodeId, Node.Name FROM NodeStaging.Node WHERE FileName = 'NodeType-DefaultEdgeType-Sample' AND Node.NodeType = 'NodeType'; |
Loading the edge, since we have the integer values for the from and to values, and they match the id values we just created. we use the function and output the node values:
|
1 2 3 4 5 6 7 8 |
INSERT INTO dbo.DefaultEdgeType ($from_id, $to_id) SELECT dbo.[GraphTable$GenerateId] ('node','dbo','NodeType',FromNodeId) AS FromNode, dbo.[GraphTable$GenerateId] ('node','dbo','NodeType',ToNodeId) AS ToNode FROM NodeStaging.Edge WHERE FileName = 'NodeType-DefaultEdgeType-Sample' AND Edge.EdgeType = 'DefaultEdgeType'; |
Note: There was a bug with inserting your own nodes in SQL Server that was fixed in SQL Server 2019 CU 12.
Run the following code:
|
1 2 3 4 5 |
SELECT FromNode.NodeName, ToNode.NodeName FROM dbo.NodeType AS FromNode, dbo.DefaultEdgeType, dbo.NodeType AS ToNode WHERE MATCH(FromNode-(DefaultEdgeType)->ToNode); |
And you get the same output as before.
What is cool is that you can do this with any of your data that has integer ids. For example, you might load a set of graph tables to analyze your data. For a concrete example, consider the many-to-many relationship between customers and products. There is an example of this in the WideWorldImporters database. It isn’t a straight connection, of course, because the connection goes through a sales order. But once you do the join through the sales order and line items, the process is exactly the same because you have a from and to value ready made:
|
1 2 |
USE WideWorldImporters GO |
Then add the Tools function:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
IF NOT EXISTS (SELECT * FROM sys.schemas WHERE name = 'Tools') EXEC ('CREATE SCHEMA Tools') GO CREATE OR ALTER FUNCTION Tools.GraphTable$GenerateId( @Type sysname, --Node or Edge @SchemaName sysname , --Schema of the Node or Edge Table @tableName sysname, --Name of the Node or Edge Table @graphItemId int -- The id of the graph object ) RETURNS nvarchar(2000) AS BEGIN RETURN CONCAT('{"type":"', @Type , '","schema":"', @schemaName, '","table":"',@tableName, '","id":', @graphItemId,'}') END; |
Next create a couple of node and edge tables to hold the data:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
IF NOT EXISTS (SELECT * FROM sys.schemas WHERE name = 'AnalysisGraph') EXEC ('CREATE SCHEMA AnalysisGraph') GO CREATE TABLE AnalysisGraph.Customer( CustomerId int NOT NULL, CustomerName nvarchar(100) NOT NULL ) AS NODE; CREATE TABLE AnalysisGraph.Product( ProductId int NOT NULL, ProductName nvarchar(100) NOT NULL ) AS NODE; CREATE TABLE AnalysisGraph.Ordered ( OrderedQuantityCount int NOT NULL --included an attribute to see what product was --ordered most by the connected customer ) AS EDGE; |
Now load the data:
Clean the tables before starting, as you will want to refresh all the data, or build some ETL to handle changes for a real database..
|
1 2 3 |
TRUNCATE TABLE AnalysisGraph.Customer; TRUNCATE TABLE AnalysisGraph.Product; TRUNCATE TABLE AnalysisGraph.Ordered; |
Just as before, using keys from the table, load the customer and product tables.
|
1 2 3 4 5 6 7 8 9 10 11 |
INSERT INTO AnalysisGraph.Customer($Node_id, CustomerId, CustomerName) SELECT Tools.[GraphTable$GenerateId] ('node','AnalysisGraph','Customer',CustomerId), CustomerId, CustomerName FROM Sales.Customers; INSERT INTO AnalysisGraph.Product($Node_id, ProductId, ProductName) SELECT Tools.[GraphTable$GenerateId] ('node','AnalysisGraph','Product',StockItemId), StockItemId, StockItems.StockItemName FROM Warehouse.StockItems; |
In the Edge insert, the CTE aggregates all the orders of the database, so we can pick the related customer that has the most ordered items for a related product.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
WITH AggregatedRows AS ( SELECT Customers.CustomerID, OrderLines.StockItemID, SUM(OrderLines.Quantity) AS OrderedQuantityCount FROM Warehouse.StockItems JOIN Sales.OrderLines ON OrderLines.StockItemID = StockItems.StockItemID JOIN Sales.Orders ON Orders.OrderID = OrderLines.OrderID JOIN Sales.Customers ON Customers.CustomerID = Orders.CustomerID GROUP BY Customers.CustomerID, OrderLines.StockItemID) INSERT INTO AnalysisGraph.Ordered ($from_id, $to_id,OrderedQuantityCount) SELECT Tools.[GraphTable$GenerateId] ('node','AnalysisGraph','Customer', AggregatedRows.CustomerId) AS FromNode, Tools.[GraphTable$GenerateId] ('node','AnalysisGraph','Product', AggregatedRows.StockItemId) AS ToNode, AggregatedRows.OrderedQuantityCount FROM AggregatedRows; |
Loading these tables on my SQL Server 2019 on my local computer takes around 3 or 4 seconds. It is not a very beefy computer, so this is pretty awesome. There are: 663 customers, 227 products, and 115140 edges created, so this is no slouch. Now you can execute the following query:
|
1 2 3 4 5 6 7 8 9 10 |
SELECT TOP 10 Product.ProductName, customer2.CustomerName,Ordered2.OrderedQuantityCount FROM AnalysisGraph.Customer, AnalysisGraph.Ordered, AnalysisGraph.Product, AnalysisGraph.Ordered AS Ordered2, AnalysisGraph.Customer AS Customer2 WHERE MATCH(Customer-(Ordered)->Product<-(Ordered2)-Customer2) AND Customer.CustomerName = 'Wingtip Toys (Mauldin, SC)' ORDER BY Ordered2.OrderedQuantityCount desc; |
From this query you get the following result, showing top 10 products that customers had in common with ‘Wingtip Toys (Mauldin, SC)’ that made the same product orders:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
ProductName CustomerName OrderedQuantityCount -------------------------------------------------- -------------------------------- -------------------- Black and orange fragile despatch tape 48mmx100m Kumar Naicker 1800 Black and orange fragile despatch tape 48mmx75m Manca Hrastovsek 1584 Black and orange fragile despatch tape 48mmx75m Wingtip Toys (Straughn, IN) 1548 Black and orange fragile despatch tape 48mmx75m Tailspin Toys (Hodgdon, ME) 1476 Black and orange fragile despatch tape 48mmx75m Kertu Sokk 1440 Black and orange fragile despatch tape 48mmx100m Tailspin Toys (Kalvesta, KS) 1440 Shipping carton (Brown) 500x310x310mm Wingtip Toys (Bourneville, OH) 1400 Black and orange fragile despatch tape 48mmx100m Wingtip Toys (Jamison, IA) 1332 Black and orange fragile despatch tape 48mmx75m Anindya Ghatak 1260 Black and orange fragile despatch tape 48mmx100m Tailspin Toys (Larose, LA) 1260 |





Load comments