




What is First Normal Form (1NF), and can you break its rules? First Normal Form is the foundation of database normalization, requiring each column to store atomic values with no repeating groups. This guide explores when strict 1NF improves data integrity and query performance. It’ll also cover when modern database design may justify bending traditional rules for flexibility, speed, or real-world use cases.
First Normal Form (1NF) is the most widely known rule in database normalization. It requires that tables contain no repeating groups and that each column holds atomic values. But, in real-world database systems, developers often intentionally break this rule when modeling complex data. Let’s find out why.
What is the First Normal Form (1NF) rule in database design?
Proper data normalization is a critical concern in database design, controlled by a set of data modeling rules known as the “normal forms”. While even the best developers may struggle to explain the difference between some of the higher normal forms, the one rule we all know is First Normal Form. Generally referred to as ‘1NF’, the rule is often expressed in a simple three-word phrase: no repeating groups.
A repeating group is a set of columns, each of which holds one value from a list or multi-valued attribute. A set of phone numbers for a client, for example, or a tally of products on a shipping manifest. These aren’t stored as a group of columns in the parent table. Instead, you create a child table containing one row per value. No repeating groups. Not ever. It’s a simple, instinctive rule we never break. Or is it?
The goal of this article is to explain why 1NF is both more and less of a rule than it is normally thought to be. More, because it applies more widely, to additional situations. Less, because there are many cases for which you’ll want to intentionally disregard the rule.
When a technical 1NF violation transforms into an actual problem
Let’s start with an example that at first glance seems trivial: a database table containing a column for a person’s eye color. Just one column because, even though everyone has two eyes, they’re not always the same color.
This rare genetic condition – known as heterochromia – would be ignored in most databases. Technically, this means we’re collapsing instances of multi-valued data (e.g. the colors “blue and green”, or “brown and blue””) into a single, stored value.

Though commonplace, such attribute collapsing is a technical violation of 1NF. The additional color isn’t stored in a repeating group – it’s simply discarded outright. Since these exceptions are rare, it’s not a problem in most cases. But what about an application tracking genetic variations? Suddenly rare exceptions matter, and our technical 1NF violation transforms into an actual problem. Ponder that distinction as we move on.
A more practical example of a 1NF violation transforming into an actual problem
Now we tackle a more practical example: vehicle exterior color. Automobiles painted two or more colors are much more common than cases of heterochromia, so this exception is harder to ignore. How can we best represent multiple colors in a table of vehicles? Our options are:
- Store only the primary color (collapse multi-valued data, as with eye color).
- Use a repeating group, i.e. multiple columns per row, such as “Color1”, “Color2”, or “PrimaryColor”, “SecondaryColor”.
- Normalize to 1NF by moving color data to a child table. An auto painted three colors would be represented by four rows: one in the main table and three in the child.
- Replace our scalar color field with a complex value. This could be a composite value like “red/white”, a text field allowing a free-form description, or structured data in XML or JSON format.
The interesting point here is that there’s no one right answer. The best approach simply depends on how a specific application defines color. A used car website might define it as “a description provided to potential buyers”, making a free-form text field the optimal choice (“white with black top and dual red stripes on hood”).
However, a manufacturer might store color data in a 1NF-compliant child table. In this instance, each row may also contain pigment amounts, color tint codes, areas of application, etc. A police bulletin, on the other hand, might store only the most prominent color noted by eyewitnesses.
As an example, the graphic below shows different ways a garment database might represent color:
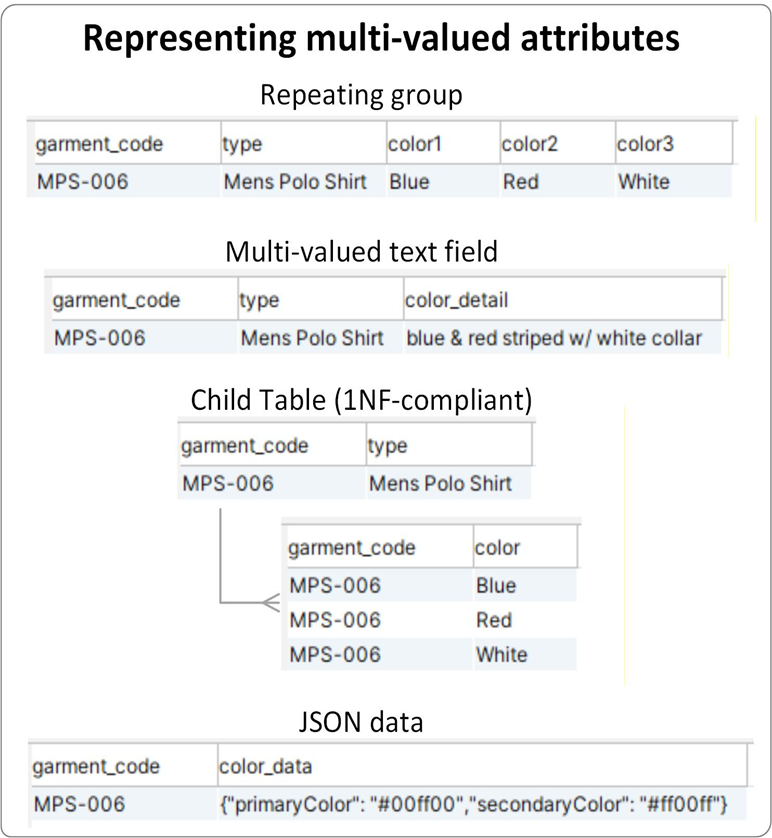
How does 1NF handle complex data objects?
1NF bans complex data types. Column values must be scalars: simple types that cannot be broken down into smaller components. What exactly makes a column complex? This actually isn’t a simple matter.
Consider the name “John Smith”. In a table of employees, this is a two-part value which should be split into first and last name. But, when representing a person’s signature on a legal document, it may be a scalar that should remain as is.
As an extreme example, an application tracking spelling variations over time might require the names themselves to be broken down and stored as individual characters. In this case, “John” would be converted into four values: “J”, “O”, “H”, “N”. The meaning of “complex type” is relative!
Sometimes the rules don’t depend on the application, but the capabilities of the database product being used. For instance, when recording the geographic coordinates of a map location, 1NF instructs us to store the latitude and longitude separately. But, if your database has geospatial capabilities, the values would be stored together as a ‘point’ or ‘geometry’ type, as these complex types can be handled natively.
Accelerate and simplify database development with Redgate
Repeating groups or 1NF – how to know which to use
Our eye color example wasn’t very realistic, so let’s instead consider ophthalmology data. An eye exam gives different readings for each eye, values which must be stored separately. Placing both sets of values in the same table is technically a repeating group (eye 1 value, eye2 value) but it is often done this way, rather than in a 1NF-compliant child table.
Why is this violation OK, whereas a repeating group of, say, phone numbers, is not? To answer these questions, we need to delve into why 1NF exists, and what sorts of problems it’s intended to combat.
Why do we even need 1NF?
Relational databases are required to perform many different tasks, all of which are affected by how the underlying data is structured. Let’s examine how 1NF violations impact these tasks.
Querying. Locating a value held within a larger complex type is slow and difficult, and often involves decomposing the entire type. Querying a repeating group is also difficult. For example, in a table containing four columns for color, a query for rows that contain red, white, and blue (regardless of order) involves complex logic.
Indexing. Indexing on individual values in a complex type generally isn’t possible. While a repeating group can be, it requires an index for each column in the group. Many types of queries won’t be able to utilize these multiple indexes.
Editing data. Updating a value within a complex type means rewriting the entire type, including values that didn’t change. Repeating groups are even worse: adding a new value means altering the table structure to include a new column, while deleting might require moving other members of the group to fill the gap. For example, if “color1” is deleted, color2 becomes color1, color3 becomes color2, etc.
Maintaining relationships. Values within a complex type can’t act as primary or foreign keys. A repeating group can’t be a primary key, and using it as a foreign key requires duplicating references.
Enforcing uniqueness. Is a row that contains a repeating group of the cities: “Boston, Detroit, Dallas”, the same as one containing “Dallas, Boston, Detroit”? Is the complex type “blue/green” the same as “green/blue”?
Why are some of these violations problematic, but others are not?
This list tells us why some violations are problematic, while others are not. In our ophthalmology database, individual diagnostic values for each eye wouldn’t be used as table keys. Nor would we likely sort patient rows by eye readings. And, unlike a list of children’s names or phone numbers, the size of this repeating group will always be fixed at two elements. Unless a patient grows a third eye, we’ll never need to add another column to the table.
Similarly, a geospatial database allows complex objects like longitude-latitude points to be directly indexed and queried, as well as adding edit constraints beyond those enforced if these were stored as separate numeric values. And for text fields that store complex types, the full text search capabilities of many DBMSs might be sufficient to locate individual elements within the field.
In these cases, violating 1NF may not only result in a structure that more naturally fits the data, but it eliminates a child table and associated index. The result is a potential increase in performance, reduced storage needs, and less development complexity.
Remember though: while non-compliant options may have other advantages, 1NF remains the most flexible format. So consider not only the needs of your application today, but how those needs may evolve over time.
What about XML and JSON data?
As fast as the use of XML and JSON-encoded data is growing, it surprises some to learn that these data types are always a technical violation of 1NF. But working developers are less concerned with theory and more with practice. So, when – if ever – should we be concerned about the use of these types?
Well, we use the same criteria for these types as we do any other complex object, so consider what operations your database will perform on the values within the object. This includes what custom support your particular DBMS product has for searching, ordering, and updating these types. In many cases, a database may never need “peer into” the internal values of an XML or JSON column. If these types are always manipulated as a single monolithic value, they’re no longer complex types. We can ignore 1NF concerns entirely.
Summary: why violating 1NF is sometimes beneficial
What seems to be the simplest, most concrete rule of data modeling is actually anything but. 1NF applies more widely than many realize. And yet, paradoxically, it is also widely disregarded. While intentionally violating this rule should always be approached with caution, there are many times where the benefits outweigh the disadvantages. When modeling a new table, don’t just consider the meaning of the data, but what the data means in the context of your application.
In Part II of this series, we’ll explore the higher order forms of database normalization; when they’re important, and when they can be safely disregarded.
Enjoying this article? Subscribe to the Simple Talk newsletter
FAQs: First Normal Form (1NF)
1. What is First Normal Form (1NF) in a database?
First Normal Form (1NF) is a database design rule that requires each column in a table to hold atomic (indivisible) values and forbids repeating groups. It ensures tables are structured consistently and efficiently.
2. Why is First Normal Form (1NF) important?
1NF is important because it makes querying, indexing, editing, and maintaining relationships easier. Without 1NF, tables can contain complex or multi-valued data that slows performance and introduces errors.
3. Can you break First Normal Form (1NF) in practice?
Yes, developers sometimes intentionally violate 1NF for practical reasons, such as storing JSON or XML data, fixed repeating attributes, or performance optimization. The key is knowing when the benefits outweigh the drawbacks.
4. What is a repeating group in a database?
A repeating group is a set of multiple values stored across columns in the same table (e.g., Color1, Color2, Color3). 1NF requires moving such groups into child tables or storing them as atomic values.
5. How is 1NF different from 2NF and 3NF?
While 1NF focuses on atomic column values and no repeating groups, 2NF removes partial dependencies on composite keys, and 3NF removes transitive dependencies. Each level reduces data redundancy and improves consistency.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved



Load comments