




Database Build Blockers: Mutually Dependent Databases
It is both common and legitimate for database projects to include several databases that have dependencies on each other. However, these interdependencies can introduce complications into the database build process. Typically, the databases will, for example, contain objects such as views that make cross-database references to each other. SQL Server checks these references when it executes the CREATE or ALTER statement, and this will cause an error if the referenced object doesn't exist. When there are mutual, or circular, dependencies between databases, there is no natural order of creating them that doesn't break the build. Whichever you build first, there is an error.
For simple database projects, I'll show how you can get around this by identifying the dependencies that exist, and then modifying the source build scripts so that they create some 'stub' code objects, initially, and then fill in their logic once the objects to which they refer exist. However, you won't want to cut build scripts by hand when you have hundreds of tables and views, so I'll then show how, using a simple pre-deployment script in SQL Change Automation, which creates some stubs to satisfy dependencies, before SCA then does a full build of all databases (no stubs are left in place, and therefore all dependencies are fully tested). You can incorporate this technique into a standard build process, without the need to make any changes to the original source scripts. It works well in cases where all databases live on a single SQL Server instance. For cross-server dependencies, you'll need a different approach, using synonyms, which I explain in a separate article.
The database dependency build breaker
Cross-database references are sometimes an 'evolutionary accident' but often the result of a design choice, where instead of using schemas to partition a database into logical security spaces, components or namespaces, you use separate databases.
To illustrate the problems that cross-database dependencies can cause for a standard build process, let's create a simple two-database project with mutual dependencies.
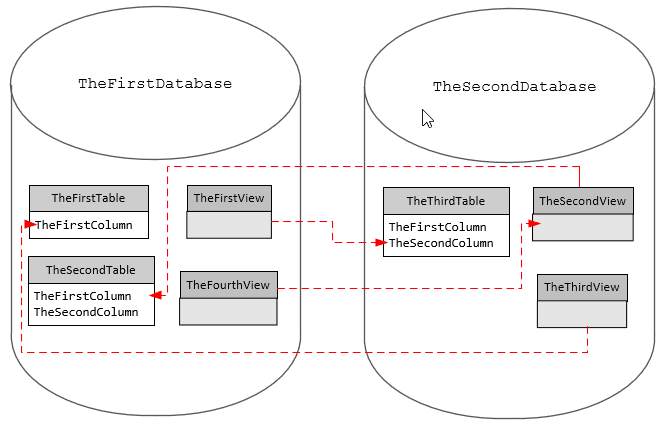
Before we run the script, we create TheFirstDatabase and TheSecondDatabase. After a 'teardown' section, to ensure that whatever we've created in a previous run is no longer there, we start the test by building TheFirstDatabase followed by TheSecondDatabase.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
|
/*-- start of Cleanup script to ensure that we start
with an empty database --*/
USE TheFirstDatabase;
IF Object_Id('dbo.TheFirstTable') IS NOT NULL
DROP TABLE dbo.TheFirstTable;
IF Object_Id('dbo.TheSecondTable') IS NOT NULL
DROP TABLE dbo.TheSecondTable;
IF Object_Id('dbo.TheFirstView') IS NOT NULL
DROP VIEW dbo.TheFirstView;
IF Object_Id('dbo.TheFourthView') IS NOT NULL
DROP VIEW dbo.TheFourthView;
USE TheSecondDatabase;
IF Object_Id('dbo.TheThirdTable') IS NOT NULL
DROP TABLE dbo.TheThirdTable;
IF Object_Id('dbo.TheSecondView') IS NOT NULL
DROP VIEW dbo.TheSecondView;
IF Object_Id('dbo.TheThirdView') IS NOT NULL
DROP VIEW dbo.TheThirdView;
/*-- end of Cleanup script --*/
/*-- start of build script for TheFirstDatabase --*/
USE TheFirstDatabase; --we switch to the 'TheFirstDatabase' database
GO--create the very simplest of tables
CREATE TABLE dbo.TheFirstTable (TheFirstColumn INT);
GO--and a second one with an index
CREATE TABLE dbo.TheSecondTable
(
TheFirstColumn INT IDENTITY NOT NULL,
CONSTRAINT pk_TheFirstTable_TheFirstColumn PRIMARY KEY CLUSTERED
(TheFirstColumn),
TheSecondColumn int NOT null
);
GO--and a view that references a second database
Create VIEW dbo.TheFirstView
AS
SELECT TheSecondColumn FROM TheSecondDatabase.dbo.TheThirdTable;
GO--and a second view, this one referencing a view
CREATE VIEW ThefourthView AS
SELECT ThefirstColumn FROM TheSecondDatabase.dbo.TheSecondView;
GO
--build script for TheSecondDatabase
USE TheSecondDatabase;--we switch to the 'TheSecondDatabase' database
GO
CREATE TABLE dbo.TheThirdTable
(
TheFirstColumn INT IDENTITY NOT NULL,
CONSTRAINT pk_TheThirdTable_TheSecondColumn PRIMARY KEY CLUSTERED
(TheFirstColumn),
TheSecondColumn int NOT null
)
GO--a view that references a table in the first database
CREATE VIEW dbo.TheSecondView
AS
SELECT TheFirstColumn FROM TheFirstDatabase.dbo.TheSecondTable;
GO--references the first database
CREATE VIEW dbo.TheThirdView
AS
SELECT TheFirstColumn FROM TheFirstDatabase.dbo.ThefirstTable
GO
|
Ouch! That won't work!
Msg 208, Level 16, State 1, Procedure TheFirstView, Line 3 [Batch Start Line 35] Invalid object name 'TheSecondDatabase.dbo.TheThirdTable'. Msg 208, Level 16, State 1, Procedure ThefourthView, Line 2 [Batch Start Line 39] Invalid object name 'TheSecondDatabase.dbo.TheSecondView'.
Try it the other way around, building the second database before the first. It won't work either. Something must 'give'.
In a very simplified script like this, which merely demonstrates the problem, we can simply move the two offending views, TheFirstView and TheFourthView to the end of the script and precede them with a use TheFirstDatabase. However, real build systems will only work on a single database at a time, so we don’t have that option.
The 'stub' solution in a hand-cut build script
Probably the easiest way of resolving this problem is to replace the two offending views with 'stub' or 'mock' objects. A 'stub' is an object that has the same name as the original, and gives the same result, even if no rows are produced. SQL Server only checks the name and datatype of the result, not whether it generates the result. It doesn't even have to be the same type of object generating the result, as long as that result contains the referenced column.
Once the two databases are created without problems, we just alter the view to replace it with the version that has the reference.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
|
/*-- start of Cleanup script to ensure that we start
with an empty database --*/
USE TheFirstDatabase;
IF Object_Id('dbo.TheFirstTable') IS NOT NULL
DROP TABLE dbo.TheFirstTable;
IF Object_Id('dbo.TheSecondTable') IS NOT NULL
DROP TABLE dbo.TheSecondTable;
IF Object_Id('dbo.TheFirstView') IS NOT NULL
DROP VIEW dbo.TheFirstView;
IF Object_Id('dbo.TheFourthView') IS NOT NULL
DROP VIEW dbo.TheFourthView;
USE TheSecondDatabase;
IF Object_Id('dbo.TheThirdTable') IS NOT NULL
DROP TABLE dbo.TheThirdTable;
IF Object_Id('dbo.TheSecondView') IS NOT NULL
DROP VIEW dbo.TheSecondView;
IF Object_Id('dbo.TheThirdView') IS NOT NULL
DROP VIEW dbo.TheThirdView;
/*-- end of Cleanup script --*/
/*-- start of build script for TheFirstDatabase --*/
USE TheFirstDatabase; --we switch to the 'TheFirstDatabase' database
GO
CREATE TABLE dbo.TheFirstTable (TheFirstColumn INT);
GO
CREATE TABLE dbo.TheSecondTable
(
TheFirstColumn INT IDENTITY NOT NULL,
CONSTRAINT pk_TheFirstTable_TheFirstColumn PRIMARY KEY CLUSTERED
(TheFirstColumn),
TheSecondColumn int NOT null
);
GO
--create a stub/mock
CREATE VIEW dbo.TheFirstView
AS
SELECT Convert(INT, 2) AS TheSecondColumn;
GO
CREATE VIEW ThefourthView AS
SELECT Convert(INT, 2) AS TheFirstColumn
GO
--build script for TheSecondDatabase
USE TheSecondDatabase;--we switch to the 'TheSecondDatabase' database
GO
CREATE TABLE dbo.TheThirdTable
(
TheFirstColumn INT IDENTITY NOT NULL,
CONSTRAINT pk_TheThirdTable_TheSecondColumn PRIMARY KEY CLUSTERED
(TheFirstColumn),
TheSecondColumn int NOT null
)
go
CREATE VIEW dbo.TheSecondView
AS
SELECT TheFirstColumn FROM TheFirstDatabase.dbo.TheSecondTable;
GO
CREATE VIEW dbo.TheThirdView
AS
SELECT TheFirstColumn FROM TheFirstDatabase.dbo.ThefirstTable
GO
USE TheFirstDatabase;--we switch to the 'TheFirstDatabase' database
GO
-- turn the stubs/mocks into a real view
--by adding the actual body of the views
ALTER VIEW dbo.TheFirstView
AS
SELECT TheSecondColumn FROM TheSecondDatabase.dbo.TheThirdTable;
GO
ALTER VIEW dbo.TheFourthView AS
SELECT ThefirstColumn FROM TheSecondDatabase.dbo.TheSecondView;
GO
|
That went well! We can now inspect our two databases to see the cross references that are in place.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
USE TheFirstDatabase;
SELECT --
referenced_database_name + '.' + referenced_schema_name + '.'
+ referenced_entity_name AS reference,
Db_Name() + '.' + Coalesce(Object_Schema_Name(referencing_id) + '.', '')
+ Object_Name(referencing_id)
+ Coalesce('.' + Col_Name(referencing_id, referencing_minor_id), '') AS referencing
FROM sys.sql_expression_dependencies
WHERE referenced_database_name IS NOT NULL;
USE TheSecondDatabase;
SELECT --
referenced_database_name + '.' + referenced_schema_name + '.'
+ referenced_entity_name AS reference,
Db_Name() + '.' + Coalesce(Object_Schema_Name(referencing_id) + '.', '')
+ Object_Name(referencing_id)
+ Coalesce('.' + Col_Name(referencing_id, referencing_minor_id), '') AS referencing
FROM sys.sql_expression_dependencies
WHERE referenced_database_name IS NOT NULL;
|
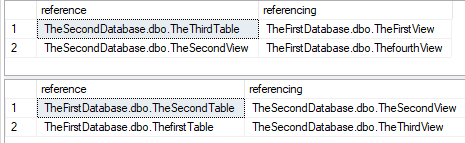
Automating builds for interdependent databases using SCA
This technique means that, even if you don't have the full source of each database, you can build the database you are working on, and use a set of stubs to represent each of the other databases, and you can develop using 'mocks' instead of 'stubs'. By 'mock', I mean a 'stub' that returns results, as a table source, or values, or both, as required to represent the actual database object.
However, let's take a deep breath. Are we really going to cut our build scripts by hand, even when we have hundreds of tables and views? Nope. Changing the source code just to try to defer name resolution add complications and can cause errors.
What we really want is a way to develop, build and release the databases from the code in source control, but without needing to change the source code to accommodate potential cross-database references. Fortunately, we can use the same 'stub' or 'mock' object principle using pre-deployment scripts that create the stubs for the referenced objects, only if the they don't already exist. I'll show how this is done using SQL Change Automation to automate the build process, but the same principle works for other database build systems.
One alternative way around the problem, explained by Kathi Kellenberger, is to ensure that each of the development servers has full copies of all the databases, merely updating them as required. This alternative technique might be more appropriate for one-off changes where scripting a full build process would be overkill, or where the number and complexity of the cross-references makes the scripted approach difficult to devise and maintain.
Setting up a database scripts directory
We'll first get our two sample databases scripted out into two directories, each representing the object-level scripts for that database.
Each object in a file is merely a create statement as usual:
You'll have noticed the extra "Custom Scripts" directory, containing Pre- and Post-Deployment folders. These are a signal to SQL Change Automation (or SQL Compare) that any synchronisation script must have some extra scripting added. In our case, we want to add a PreScript that SQL Change Automation will then append to the start of the actual synchronization script. This is a SQL Compare option that is also used in SCA. You can adapt the principle to other build systems.
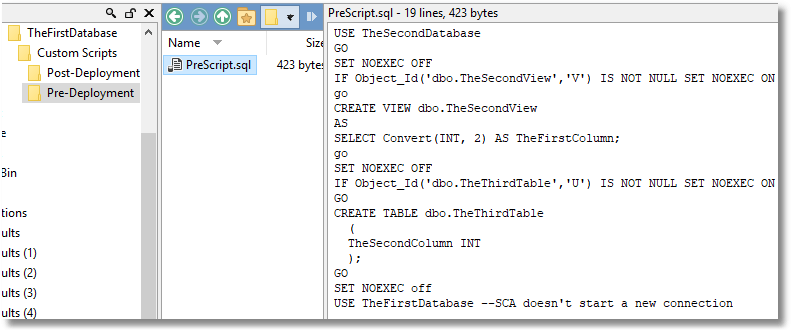
The PreScript checks each of the references to objects in the other database to see if they exist. If an object isn't there, it creates a 'stub'. Otherwise it leaves well alone. For every reference to an object in the other database, you create a matching 'stub' that you add to the database's PreScript. This unlikely to become too arduous, as calls to another database are usually well-managed and carefully defined, so as to prevent errors.
Here is PreScript.sql for TheFirstDatabase:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
USE TheSecondDatabase
GO
SET NOEXEC OFF
IF Object_Id('dbo.TheSecondView','V') IS NOT NULL SET NOEXEC ON
go
CREATE VIEW dbo.TheSecondView
AS
SELECT Convert(INT, 2) AS TheFirstColumn;
go
SET NOEXEC OFF
IF Object_Id('dbo.TheThirdTable','U') IS NOT NULL SET NOEXEC ON
GO
CREATE TABLE dbo.TheThirdTable
(
TheSecondColumn INT
);
GO
SET NOEXEC off
USE TheFirstDatabase --SCA doesn't start a new connection
|
This routine only creates stubs for its dependencies in the other database if necessary, i.e. if the object or stub doesn't exist. If it already exists, then the code issues a SET NOEXEC ON, which means SQL Server will compile the code that follows but won't execute any statements until it sees a SET NOEXEC OFF. We use this device to get around the problem of a CREATE statement having to be at the start of the batch.
Here is the PreScript for TheSecondDatabase, which checks if it needs to create stubs in TheFirstDatabase of any objects it is referencing but which don't exist.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
USE TheFirstDatabase;
GO
SET NOEXEC off
IF Object_Id('dbo.TheFirstView','V') IS NOT NULL SET NOEXEC on
go
CREATE VIEW dbo.TheFirstView
AS
SELECT Convert(INT, 2) AS TheSecondColumn;
GO
SET NOEXEC OFF
IF Object_Id('dbo.TheSecondTable','U') IS NOT NULL SET NOEXEC ON
go
CREATE TABLE dbo.TheSecondTable
(
TheFirstColumn int
);
GO
IF Object_Id('dbo.TheFirstTable','U') IS NOT NULL SET NOEXEC ON
go
CREATE TABLE dbo.TheFirstTable
(
TheFirstColumn int
);
GO
SET NOEXEC off
Use TheSecondDatabase --SCA doesn't start a new connection
|
Deploying the scripts directory to a database with SCA
Right. We are ready to start. We will build this behemoth with the full might of SCA and PowerShell. Make sure that both target databases exist on the hosting instance. They needn't be empty; by using SCA, we can update the build rather than, from necessity, creating it from scratch. Here, I'm creating an SCA release artifact directly from the source (so there is no build validation phase).
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
Import-Module SqlChangeAutomation
$targetsAndSources=(
@{'connection'= 'Server=MyServer;Database=TheFirstDatabase;User Id=PhilFactor;Password=SomethingDevilish!;Persist Security Info=False';
'source'= ' MyNetworkPathTo\TheFirstDatabase'},
@{'connection'='Server=MyServer;Database=TheSecondDatabase;User Id=PhilFactor;Password=GuessWhat?;Persist Security Info=False';
'source'='MyNetworkPathTo\TheSecondDatabase'}
)
$ReleaseArtifacts=@()
$targetsAndSources|foreach {
$iReleaseArtifact=new-DatabaseReleaseArtifact `
-Source $_.source `
-Target $_.connection -SQLCompareOptions 'NoTransactions' `
-AbortOnWarningLevel None
Use-DatabaseReleaseArtifact -InputObject $iReleaseArtifact -DeployTo $_.connection
$ReleaseArtifacts+=$iReleaseArtifact
}
|
Success. Two databases deployed. I didn't need to overwrite the initial stubs because SCA did it for me as part of the normal release process. It was able to script a change from the stub to the real object. It was able to verify that there had been no drift in the target database, because I didn't cause any in the initial 'pre' script, and it was satisfied that the result of the deployment process had the same metadata as was in the source code. The only thing I had to do was to ensure that the referenced objects existed in a form that would satisfy the SQL Server Engine.
Will this scale? Yes, to as many databases as you wish and as many database objects as you need. If you allow unfettered access into one database from another, you may need to put more work into maintaining the PreScript.sql for the databases with foreign dependencies, but it is a small price to pay to get over what could otherwise be a sticky problem.
Using SQL Compare with interdependent databases?
Will this technique work with SQL Compare? Yes, it will, if you execute the deployment script from SSMS or SQLCMD. At the time of writing there is a bug that causes an unhandled exception if you deploy SQL Compare's deployment script via SQL Compare. Just set up a project for each database, comparing the script folder to the target database, and away it goes, but make sure you just get it to generate the script.
Conclusion
It is perfectly legitimate for database projects to include several databases, either on the same server instance, or on other server instances. This should present no more difficulties for teams that use source control and build from object-level scripts as it does for teams using migration scripts.
I've demonstrated a technique that simply places stubs in otherwise-empty databases, in order to let you develop, build and release individual database from the code in source control, even when they are destined to be components in a larger system. You don't need to make any changes to the source to accommodate potential cross-database references.
I've covered the case of groups of databases on the same server instance, but if the databases are on different servers, then you're likely to require a different technique to using stubs, this time involving Synonyms. That will have to be a separate article!
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Tools in this post
You may also like

Article
Database Delivery with Docker and SQL Change Automation
Phil Factor demonstrates how to integrate SQL Change Automation into containerized workflows, such as are typical of a microservices architecture. He shows how to automate database builds into a Linux SQL Server container running on Windows, and then backup the containerized database and restore it into dedicated containerized development copies for each developer and tester.
Article
Database Build Blockers: Mutually Dependent Databases
Phil Factor demonstrates a clever way to create 'stub' objects, in SQL Change Automation pre-deployment scripts, in order to overcome the problems caused by 'missing objects' when building databases that have circular, or mutual, dependencies. In the subsequent deployment, SQL Change Automation fully builds every object in each of the databases, so all dependencies are fully tested.
Article
Database Build Blockers: Cross-Server Database Dependencies
Phil Factor demonstrates how to tackle builds when databases make cross-server references. The technique uses synonyms to represent the remote objects, and local 'stub' objects to overcome the problems caused by 'missing references' when building the individual objects.
Article
Basic data masking for development work using SQL Clone and SQL Data Generator
Richard Macaskill describes a lightweight copy-and-generate approach for making a sanitized database build available to development teams, using SQL Clone, SQL Change Automation and SQL Data Generator.
Article
Sometimes the tool just fits - using SQL Change Automation and Octopus Deploy for Data Change Control
From a business risk perspective, data change can be just as significant as code or schema change. Sometimes even more so; an incorrect static (or reference, or master) data change can drive your software’s behaviour more dangerously askew than pretty much any bug can. Imagine treating a retail customer for an investment fund as a corporate by mistake, or vice versa (a potential regulatory breach). Or booking the repatriation trades in the wrong currency (and not finding out until they settle, and hit the wrong cash balance). And what are your web customers going to do when the ‘choose credit card type’ drop-down is
Article
Recreating Databases from Scratch with SQL Change Automation
Phil Factor starts with the basics how to rebuild a set of development database from scratch, using SQL Change Automation, and then demonstrates how to check for any active sessions before rebuilding, import test data using BCP, and secure passwords if connecting to the target with SQL Server credentials.
Loading comments...