





A Basic Technique for Masking Address Data using Data Masker
In my previous article, I showed how to use Data Masker to obfuscate credit card data, while ensuring that the masked data retained the characteristics and distribution of real credit card information. This 2-part article series is going to do the same for address data (country, province, city, zip, address lines and so on). Our aim is to protect data that is classified as personal identifiable data, personal sensitive data or commercially sensitive data. At the same time, for our non-production environments, we need to make data look real and appear consistent.
This article shows a simple way to do masking on a single table, Person.Address, while ignoring the wider database context for the time being. Were we masking a database, we would have a lot more to fix besides this table. I'll show how to use Data Masker to substitute fake but realistic address values into the address line, zip code and city columns of Person.Address, and then randomly shuffle the order of the StateProvinceID column values, so that each AddressID is associated with a different state, and therefore country, in the related lookup tables.
The result is fake address information that looks real and couldn't, by itself, be used to identify any individuals, assuming the rest of the database is also suitably masked. However, in other respects, it won't accurately reflect the real address data. Our basic masking rules don't maintain any correlation between postal codes, states and cities, so you might rise your eyebrows on seeing the city of London, in the German province of Saarland, with a US zip code. Also, we're using random data distributions in the data replacement rules, so cities with thousands of AdventureWorks-related addresses in the real data, may only have a small handful in the fake data.
In Part 2, I'll fix these issues, offering a couple of mechanisms to mask address information that will ensure that is not personally identifying, but also has improved verisimilitude and a more accurate distribution.
In a later article, we'll go on to check the database and determine if there are any ways that an inference attack can unmask these addresses or give any clue as to the identity of an AdventureWorks customer.
Why mask address data?
Some developers like to use real data, from the live database, when developing and testing the applications that rely on that data. It gives them confidence that the behavior and performance seen during testing will match what's seen in production. At the same time, we must ensure that no sensitive, or Personally Identifying Information (PII), leaks into insecure, non-production environments, where unauthorized people could view it. Therefore, we need to obfuscate that data, before it reaches these environments, and make sure that we leave no information that can be used to reverse enough of our work to constitute a data breach.
I won't delve further here into the all the regulatory and other reasons why we need to mask this data; I touched on them in my credit card article, and they are covered in detail elsewhere.
What address data do we need to mask?
This article is about masking address data, in the assumption that you'll also apply similar masking strategies to all the other types of identifying and sensitive data in the database. It's also only about masking address data in Person.Address table. While this is the primary source of address data, and masking it is a logical first step, it isn't the end of the job.
As a simple example, if you're armed with a phone number geolocator and the first six digits of a landline phone number (the area code plus 3), you can get a close approximation of that number's address. This means that a 'hacker' will be able to undo almost all your good work by accessing Person.PersonPhone.PhoneNumber and HumanResources.vEmployee.PhoneNumber. If a BusinessEntityID is correctly associated with the phone number, then your efforts to mask the Person.Address table are in vain.
There may be other lurking denormalization or perhaps some address data in an XML field that could defeat our efforts. We will need to go on to check that later.
Address lines
In the Person.Address table, it will seem obvious that address line data ('1016 Park Avenue') might allow you to identify the individual, even if you'd masked the person's name.
Some address lines won't be unique though, even when coupled with the City. Try, for example, searching for 'Main Street' in 'Springfield' in the USA. Others, on the other hand, will be enough to narrow down the list of possible identities. Very few people live in a house with that same address, and you could easily pull that person's name from public data. You only need to be able to identify a few people for a data breach and subsequent legal action. (See the 2010 Netflix breach).
Postal Codes
We'll also want to mask postal codes because if the postal code contains only a few addresses of bicycle customers, or vendors, then this could be a way to identify individuals. How many keen bikers have addresses in a unique postal code?
|
1
2
3
4
5
6
7
8
|
SELECT Sum(CASE WHEN f.residents = 1 THEN 1 ELSE 0 END) AS not_shared,
Sum(CASE WHEN f.residents = 1 THEN 0 ELSE 1 END) AS shared,
Count(*) AS total
FROM (
SELECT a.PostalCode, Count(*)
FROM Person.Address AS a
GROUP BY a.PostalCode
) AS f(postcode, residents);
|
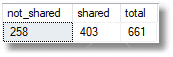
258 AdventureWorks affiliates have a unique postal code. If these postal codes aren't masked, and someone is able to use them to join the table to an external source of information, such as membership of biking clubs, they might gain enough information to identify some individuals.
City, region and country
If we mask the address lines and postal codes, are we now done? Not really. We've made progress, but the city, region and country are all highly correlated with the postal code. To be realistic, they must relate to the new masked postal code (we'll take care of that in Part 2).
There is a more important reason that we still have work to do. Even just knowing the city, region and country of a customer could lead you to being able to identify them in the database, if this knowledge can be combined with other information. If, for example, you are trying to discover personal information about a cyclist who you know has bought from Adventureworks, who you know lives in Baltimore, you would be in luck, because there is only one in the Adventureworks database. You would then have his or her primary key. If we can join this to data from other sources, such as records from the carrier, we can unmask the name of a few individuals in the database.
|
1
2
3
4
5
|
SELECT a.City,
COUNT(*) AS ResidentsCount
FROM Person.Address AS a
GROUP BY a.City
ORDER BY ResidentsCount ASC;
|
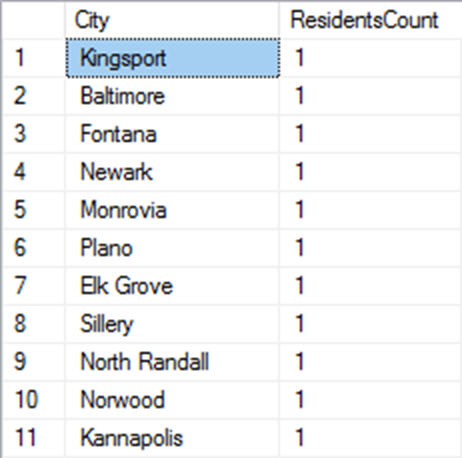
Similar arguments can apply at the State/Province or even country level. Just knowing someone lives in California and Washington won't help you much because AdventureWorks has thousands of addresses in each of these states, but other states have only one, or a small handful:
|
1
2
3
4
5
6
7
8
9
|
SELECT sp.Name,
SpCount.ResidentsCount
FROM Person.StateProvince AS sp
JOIN ( SELECT a.StateProvinceID,
COUNT(*) AS ResidentsCount
FROM Person.Address AS a
GROUP BY a.StateProvinceID) AS SpCount
ON SpCount.StateProvinceID = sp.StateProvinceID
ORDER BY SpCount.ResidentsCount ASC;
|
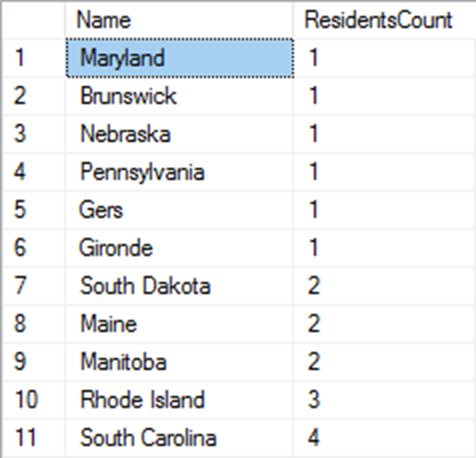
Anyone from 'Gers' or 'Nebraska' is likely to stand out, if someone is attempting an inference attack, since it narrows down the candidates. Even just accidentally revealing the country of an address could be dangerous, if the attacker also has access to other information such as shipping data. If the data reveals details about one AdventureWorks customer in the Czech Republic, and you happen to know that a shop on Prague sells specialist AdventureWorks cycles then you've made an identification.
Finally, we also need to worry about the most precise piece of data when talking about an Address, namely the latitude and longitude, which represented in SQL Server by geographical data. There are multiple services that can reverse a latitude and longitude coordinates into an actual address, including Bing Maps and Google Maps. Currently, SQL Data Masker doesn't support the spatial data type, so although I don't show it here, we'd need to add another step to our process to clean that data, through a simple T-SQL command.
Defining your strategy for masking addresses
Addresses are complex entities, and when masking this data, we need to consider not simply the need to protect the PII, but also how best to do that within the context of the schema of our organization's databases. We can't wish for a simpler data structure, or one that is easier to use. I like to work with the AdventureWorks database, but not because it's a great database design; the opposite in fact. It's an awkward database design with some odd normalization choices. However, in my view, this makes it a perfect platform for exploring real world solutions because we are constantly dealing with legacy or third-party databases that are poorly structured.
Within these data structures, we don't necessarily need to replace every address-related data value with a fake one, but we need to do enough that it won't be possible to identify individuals. Figure 1 shows a small extract of the AdventureWorks schema, showing only the Person.Address, Person.StateProvince and Person.CountryRegion tables.
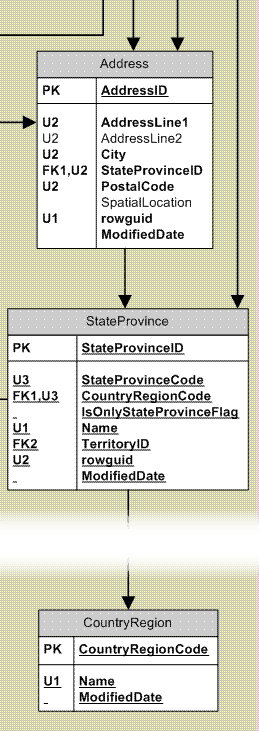
Figure 1
As discussed in the previous section, in the Address table, the address lines, the city and the postal code are all potentially PII, so we'll need to replace those values with fake ones.
In the address table, there are several columns that are foreign keys to the State/Province and location data. Do we merely shuffle the foreign keys to the StateProvince table, for example, or is it better to substitute all the Name values in StateProvince for fake ones?
In this case, the former, because StateProvince is just a lookup table for Address, based on StateProvinceID. The data values in this table doesn't represent PII except as they relate to an address, and an address relates to a person. Similarly, CountryRegion is just lookup table for StateProvince, based on CountryRegionCode.
So, all we need do is ensure that AddressID values are associated with different StateProvinceID values, so that there is no longer a link between people and addresses. You'll have to go through similar thought processes when deciding how to mask your own address data.
Implementing basic address masking in Data Masker
The first task is to substitute the PII data in the Address table. A simple, brute force way to do that is simply to substitute, for example, every address line value for a single fake address:
|
1
2
|
UPDATE Person.Address
SET AddressLine1 = '1313 Mockingbird Lane';
|
Done. Of course, we've just destroyed the data distribution. We want our faked address lines to bear some closer resemblance to reality, so we need to have a distribution of information.
Fortunately, Data Masker can do a lot better. It provides built-in data sets for each of our address columns, which will allow us to substitute the data values in these columns with fake, but realistically distributed, data.
The basic address masking rule set
At the bottom of the article, there is a link to download the full data masking set (Address.DMSMaskSet) that I used. Figure 2 shows the first step, which is to define the substitution rule for the Address table.
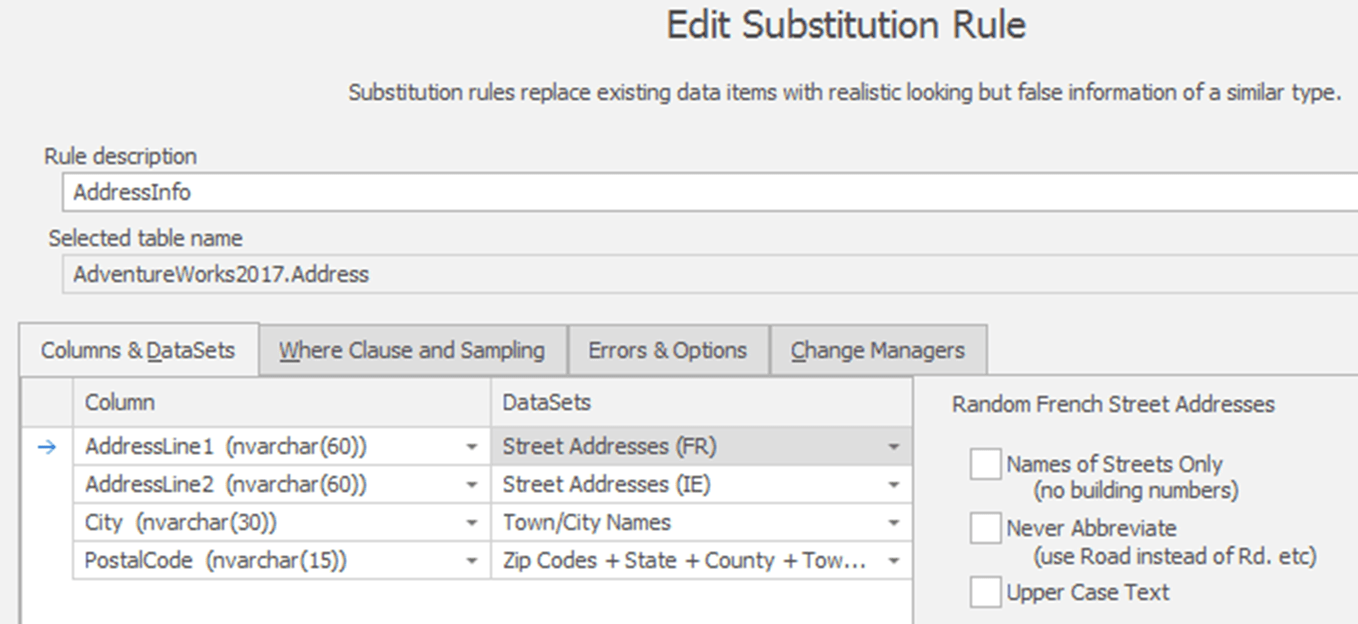
Figure 2
I'm using a data set from France for all the AddressLine1 values, and a data set from Ireland for all the AddressLine2 values. I'm using a US distribution of Town/City names, for the City column, and US zip codes for the PostalCode column.
That ensures both realistic Franco-Irish-American address data and a complete replacement of all the columns. Leaving out the AddressLine2 column could again lead to exposing potential PII information by association. Figure 3 shows a sample of data, for South Carolina, 'before' and 'after' data applying this substitution rule.
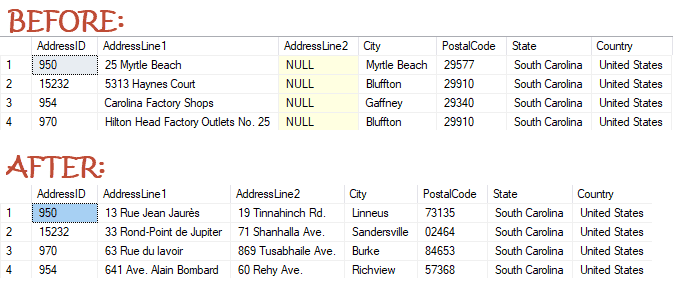
Figure 3
As you can see, although we've faked the address line, city and postal code data, the problem we still have is that the same AddressID values are associated with the same States.
Depending on the data distribution, this means that someone could tie an AddressID column value to an individual, through other tables in the database. So, as a second step, I've done an in-place shuffle the data values in the StateProvinceID column
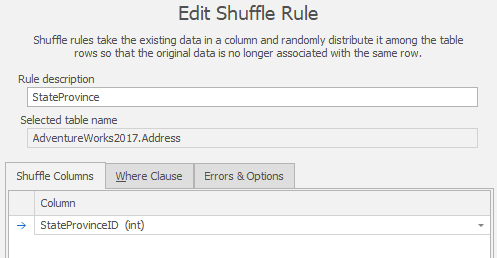
Figure 4
This will result in each AddressID being associated with different State/Province data, and by extension in this case, all the Country data as well, without us needing to modify these lookup tables. Figure 5 shows a sample result, with South Carolina associated with a complete different set of AddressID values.

Figure 5
These two processes result in a complete masking of all the information necessary to both protect PII and create realistic looking address data. That said, there are some problems with this approach.
Problems with the Basic address masking
This methodology arrives at protected and realistic data, but not data that reflects the data distribution in our production environment. The address information looks like addresses, postal codes, and so on, but it isn't accurate. We simply supplied fake cities and fake postal codes, neither of which correlate to the state and province from which they originated. We're not correlating the data to ensure that US cities and zip codes match US addresses and UK cities and postal codes match UK addresses.
In the original data, for example, a query for all addresses in London will return over 400 rows, all in the UK capital, and with accurate postal codes. In the faked data, you'll see a very different number, in my case one (and it was for London, Germany).
This may be sufficient for some purposes such as user-acceptance testing but is likely to affect database development because queries will behave differently. Let's say we often query the data looking for addresses of customers in a given postal code. In the real data, the number of addresses by postal code (see Listing 1) ranges from 1 up to 215 for Burien, Washington. This is a small database, but in a bigger one we can imagine them ranging from 1 up to tens of thousands. In my faked data, it ranges from 1 to 5, so we'll never be able to test queries by postal code properly.
So, what do you do if you want fake address but that mirrors the real data distribution more closely? Depending on how realistic a match we're trying to achieve and how important that is for our processes, we may need some additional steps to deal with these correlations.
We'll deal with that in the next article.
Data Masker can be found as part of SQL Provision. Find out more and grab your 14-day fully functional free trial.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Tools in this post
Data Masker
Shield sensitive information in development and test environments, without compromising data quality
SQL Provision
Provision virtualized clones of databases in seconds, with sensitive data shielded
You may also like

Article
Using striped backups with SQL Clone
Can we use a striped backup as the source for a SQL Clone image? Yes we can!

Article
Meeting your CCPA needs with Data Classification and Masking
This article will explain how to import the data classification metadata for a SQL Server database into Data Masker, providing a masking plan that you can use to ensure the protection of all this data. By applying the data masking operation as part of an automated database provisioning process, you make it fast, repeatable and auditable.
Article
How to create and refresh development and test databases automatically using SQL Clone and SQL Toolbelt
A PowerShell automation script to build a SQL Server database from source control, seed it with dummy data, document it, and then deploy copies to any number of test and development servers.

Webinar
Tipps und Tricks zur Datenbanküberwachung
Join Solutions Engineer, Marko Coha, for this online workshop, and find out how to deliver secure and fast database copies using Redgate solutions.

Article
Database Continuous Integration with SQL Clone and SQL Change Automation
Phil Factor provides the basis for a Database Continuous Integration process, using SQL Change Automation to build the latest database, and then SQL Clone to distribute it to the various team-based servers that need it. Having honed the process, you can run it every time someone commits a database change.
Article
How to automatically provision sanitized data using SQL Clone, Data Masker and PowerShell
Chris Unwin describes a strategy, using data masking, cloned databases and PowerShell, which will allow you to sanitize data before provisioning test or development environments.
Loading comments...