





Managing Data Masking Rules in Larger Teams using Source Control
There are many valid reasons why an organization will want to use its existing 'production' data for development, testing, training, analytical and reporting purposes. This is fine, if that organization also has a standard database provisioning process that guarantees that this data remains protected, once it is distributed. This means ensuring that no sensitive, or Personally Identifying Information (PII), leaks into insecure, non-production environments, where unauthorized people could view it.
In my previous article, I showed how to use SQL Provision to automatically provision a group of interdependent databases to each machine in set of test servers. There was a sales database, a couple of inventory databases, a shipping database, and a sales database, and to each one we had to apply the right set of data masking rules, as part of our strategy to protect its sensitive or personal data. My focus was on the PowerShell-automation task, so I didn't offer any details on the masking rules, or how they were maintained by the team, but this requires some thought, especially in larger organizations.
Just as we should place our database build scripts, and PowerShell automation scripts in source control, so we should our data masking rules, which after all are just another set of text (XML) files. With the files in source control, we can track versions and changes enabling several people to work safely work on the same set of masking definitions at the same time. We can also create branches as required to support multiple development streams, and deal with any merge conflicts that might arise.
Creating and maintaining the masking rules for each database
In a production environment with five different databases, such as described above, we'd need to have multiple masking sets, at least one for each database. However, for illustration purposes here, we'll start with a straightforward and simple set of masks. Early in the project it was determined that we need to do some masking for addresses, and our current masking set for the Address table looks like this:
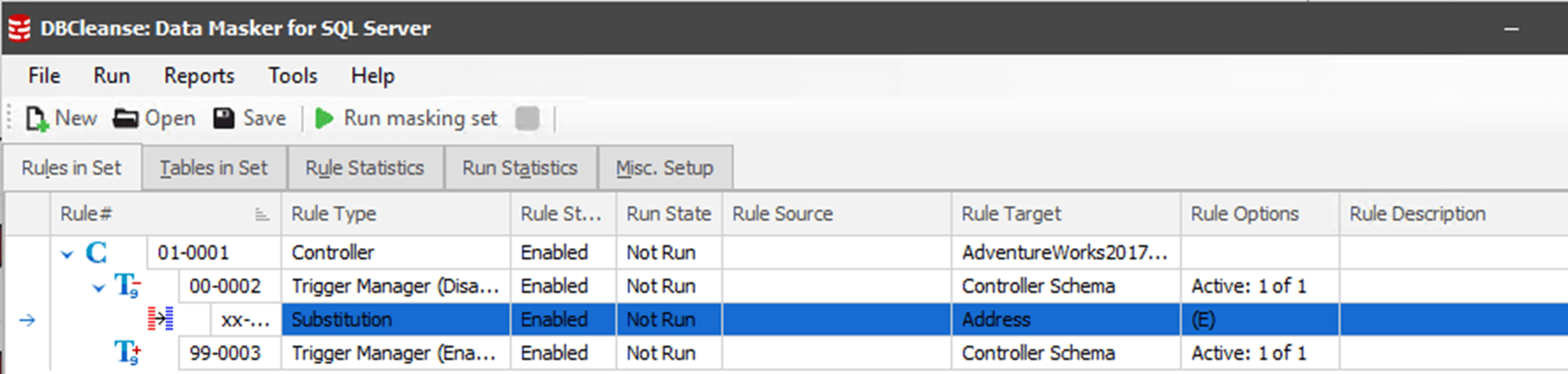
The substitution rule for the Address table modifies a few key fields:
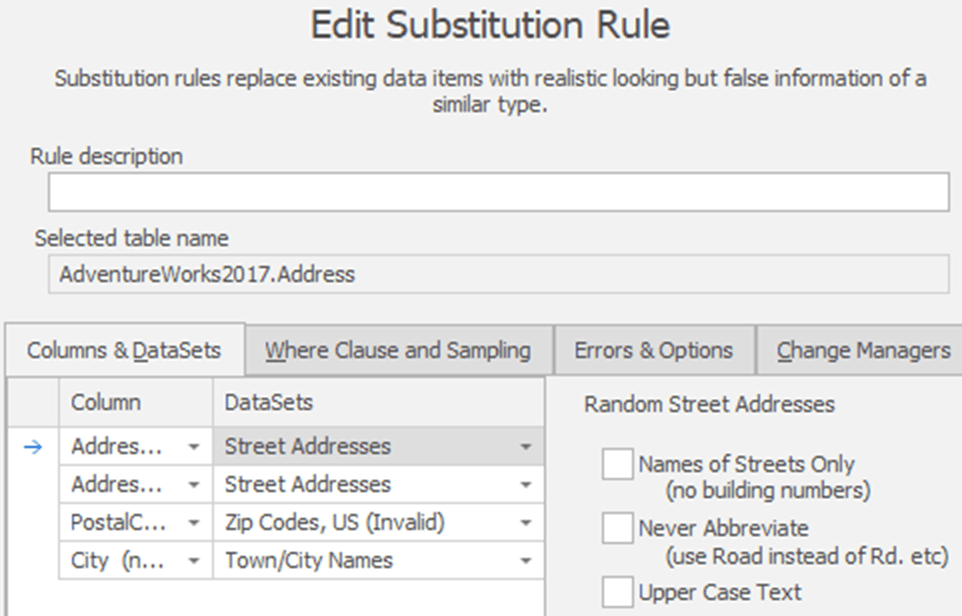
Application of this masking set and any others, during database provisioning, would be automated as outlined in the previous article. Our team of developers and data specialists tasked with maintaining the masking rules would edit them using the Data Masker UI as shown.
Under the covers, the set of data masks is stored as a .DMSMaskSet file, which is just an XML file. You'll find the schema definitions of each table, column, index and key as well as various elements that define how each of the masking rules works. For our substitution rule, for example, you'll find in the XML a <RuleSubstitution> element and then, within that, elements that define the rule (<DMSRule>), and then how it applies to each of the tables and columns. For example, here we can see how the rule works on the AddressLine1 column and that we're using a random_street_addr_fr.dmds data set to replace existing values in that column with French street addresses:
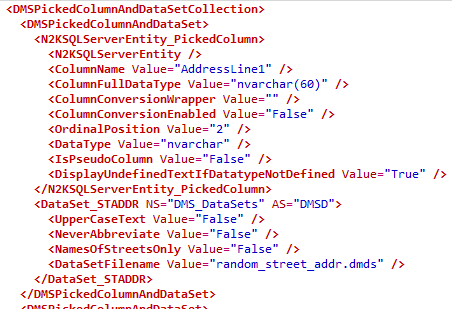
This is just a tiny part of all the XML that defines the substitution rules, processing, columns, data types and so on. However, it's all normally controlled through the Data Masker user interface, even in a multi-user environment.
Putting masking files into source control
Since the masking definition is just an XML file, we simply place the file into a folder that is managed by your source control system and manage the files through the source control interface, just like any other file. In my example, I have a shared GitHub repository in which we manage our code. I've cloned that repository locally and I'm adding my Data Masker file (DBCleanse.DMSMaskSet) for the first time, to my local GitHub repo.
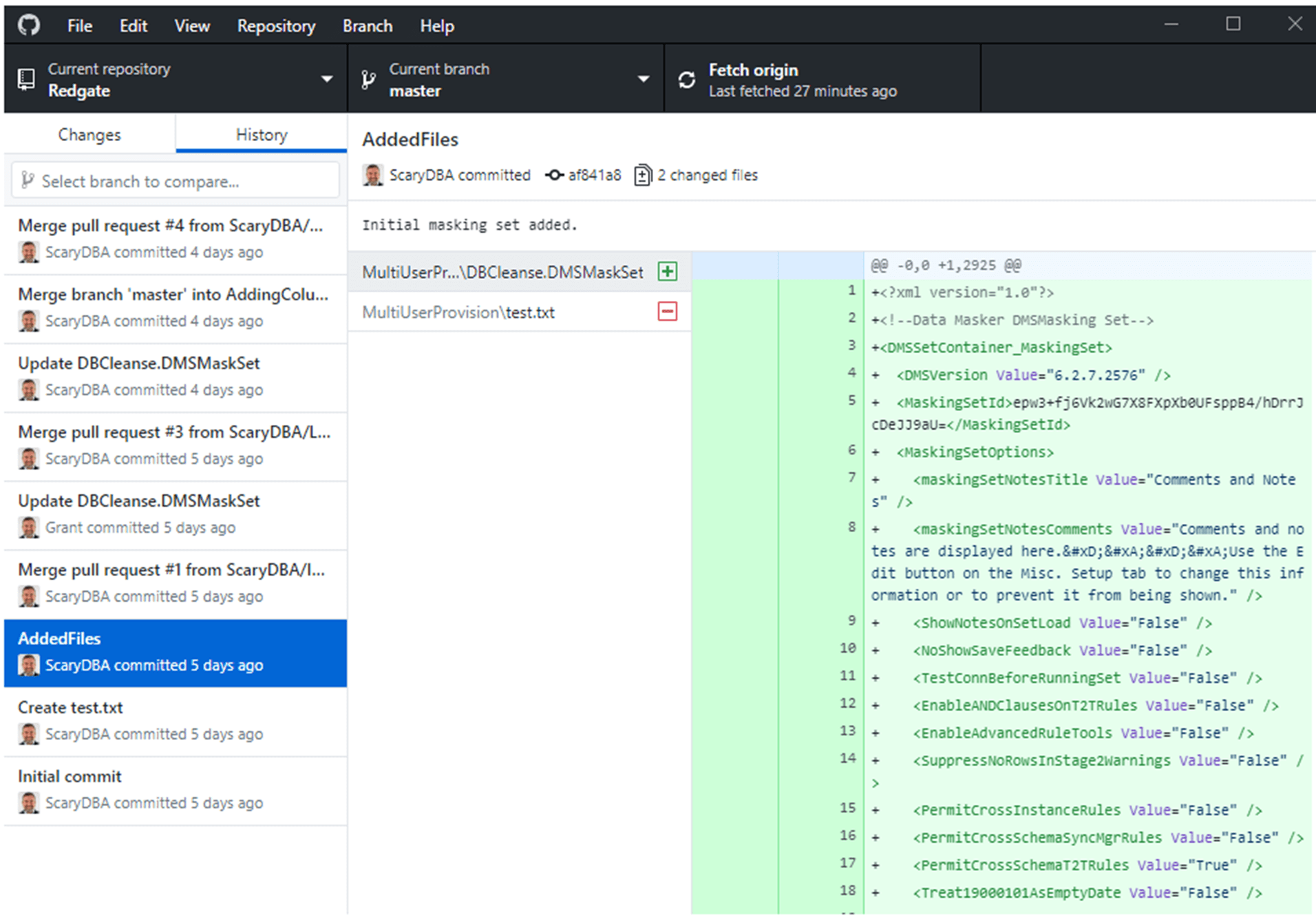
Once I've finished working on the file locally, I can issue a pull request and merge the file into the shred project. This allows the team to control and document how changes are made, coordinate those changes with deployments and releases, testing, everything in short that source control offers us through DevOps and automation.
Working with branches
Let's say I need to do some work on the data masking set to protect email addresses. First, I'll synchronize with the main branch to ensure I have all the latest changes from source control. From there, I'll create a local branch to begin my work.
I can then do the work within that new branch, adding and then refining my new substitution rule for the EmailAddress table, within my Data Masker file. The result looks like this:

Working on my own branch means that I can add my changes to source control without those changes affecting users working on trunk, or on other branches. I'll run some local tests to verify that my modified rules mask the data in exactly the way I expect, and then I can commit the changes to my local branch.
When I'm ready, I'll use GitHub to create a pull request to get those changes up to main branch for further testing and a possible deployment.
With a fair wind, there will be no conflicts and the merge can proceed automatically, and the rest of team can now use the new masking set.
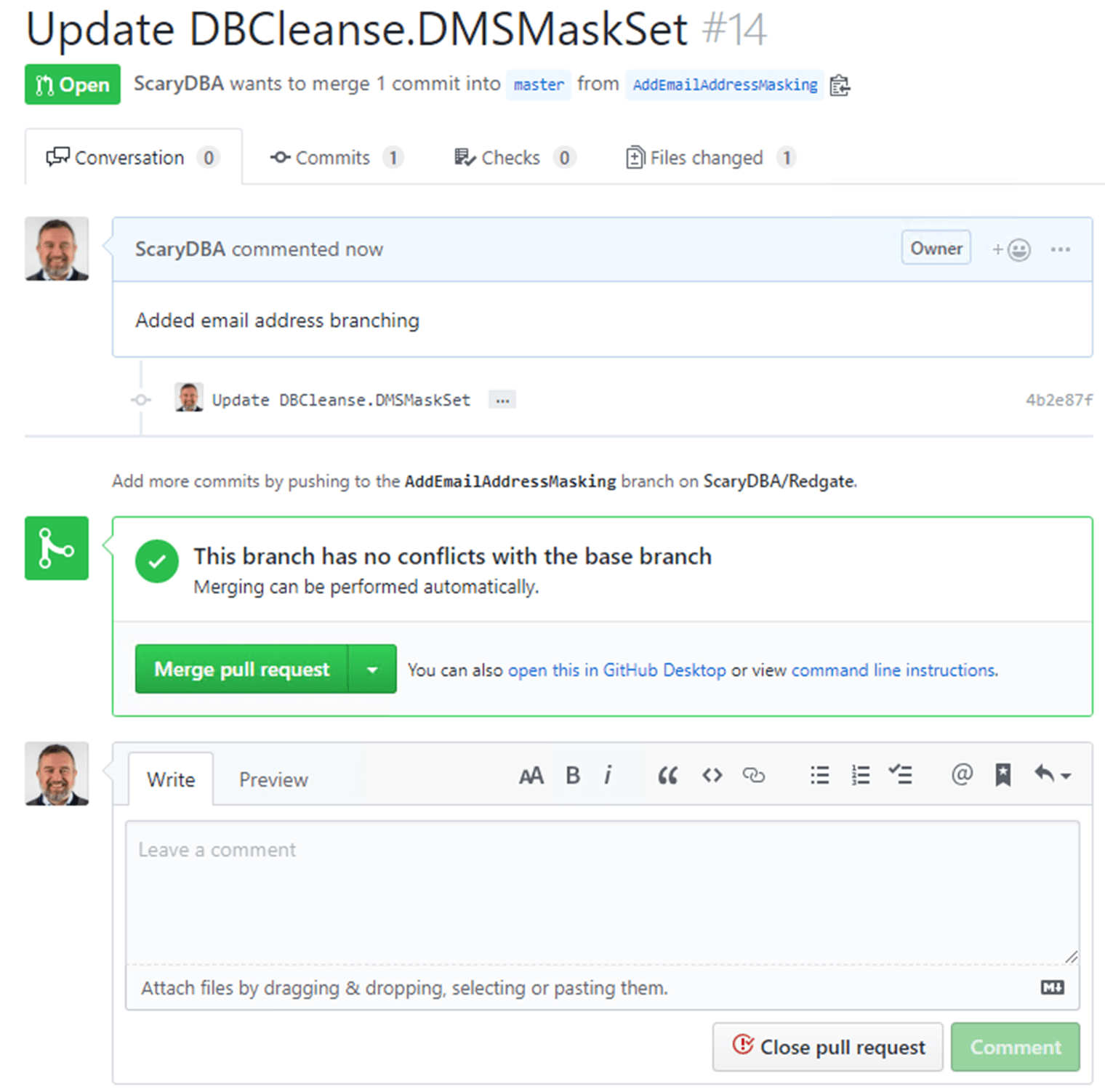
From there it's just standard work to reconcile the changes and move forward with our processes.
Collaborative maintenance and dealing with merge conflicts
When a team is collaboratively developing and maintaining the same set of masking files, then there will inevitably be occasions, hopefully rare, when they make conflicting changes to the same files, which then need to be resolved as part of the merge process.
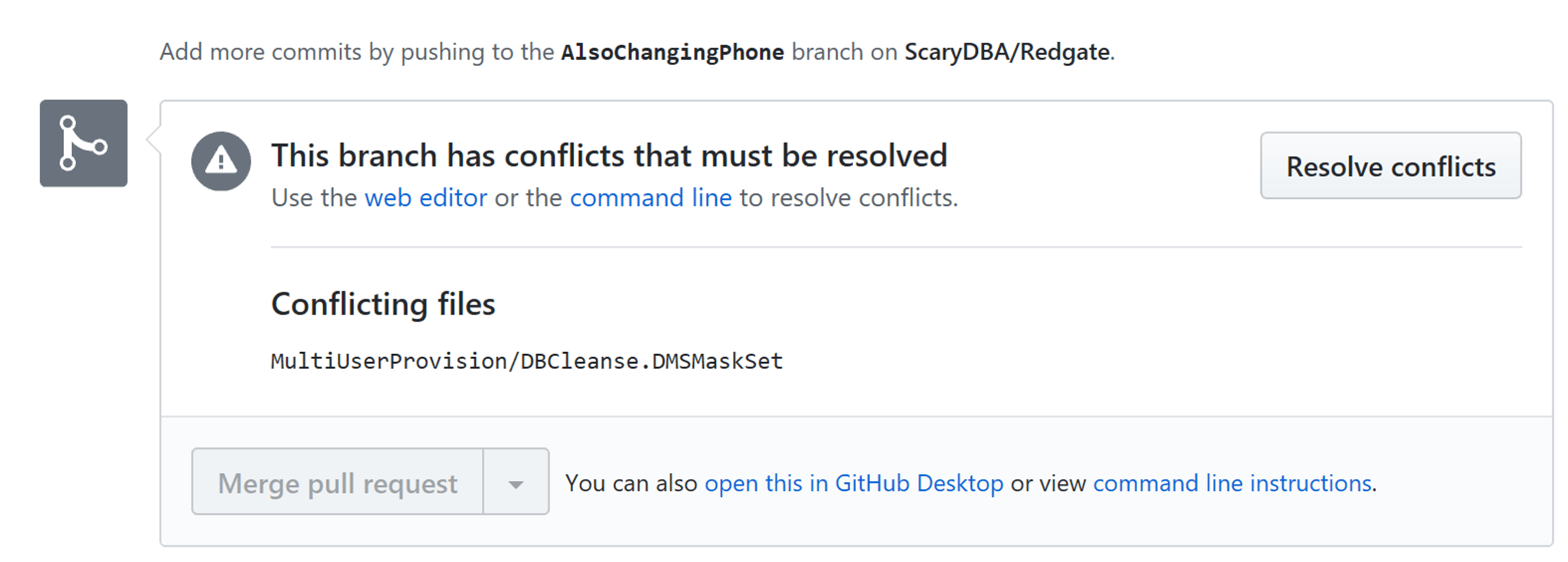
Here is a situation where, due to a communication breakdown, two developer worked on the same masking file, each with the intention of implementing data masking for telephone numbers.
Each developer synchronizes their local repo with the main branch in order to get all existing code changes, and then each one creates a local branch so that they have the ability track the work they do and undo changes, if things go wrong, without affecting others
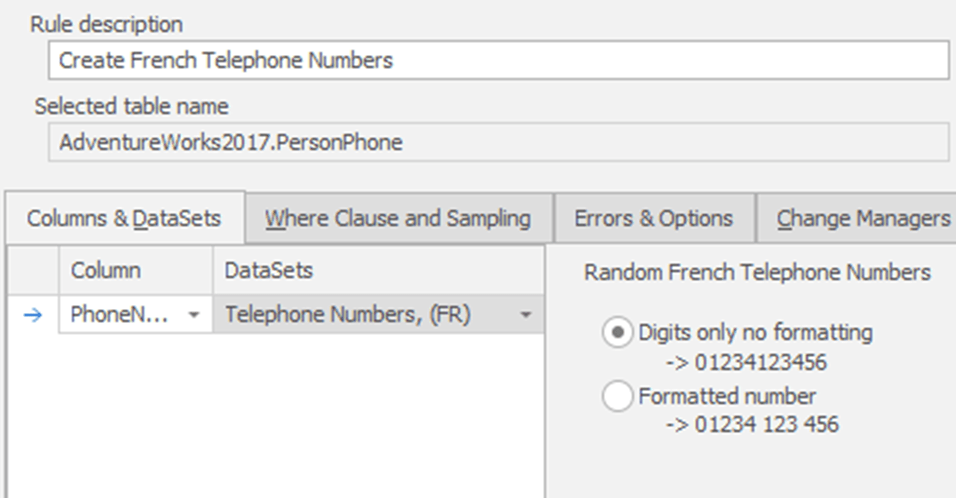
The first developer opens Data Masker and adds a new substitution rule for telephone numbers that replaces the real numbers with random French phone numbers, like this:
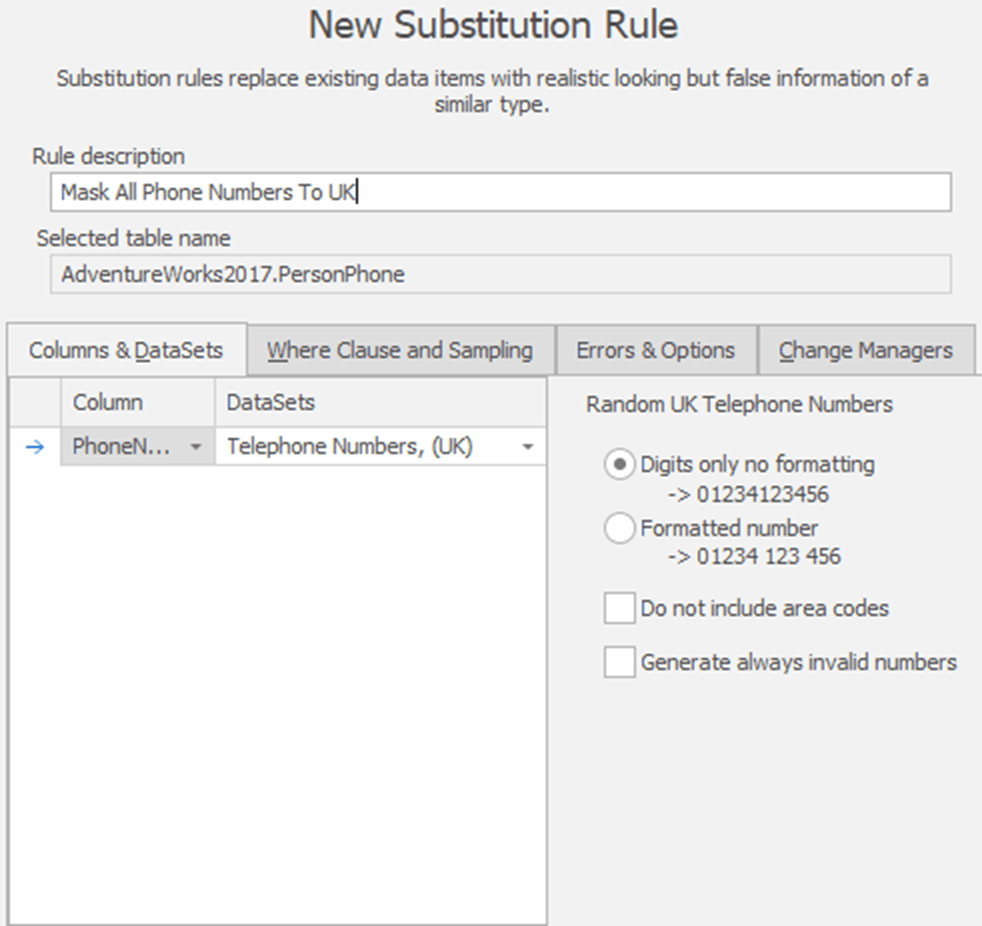
At roughly the same time, a second developer modifies the same masking set file, in their own local branch, to mask real phone number with UK telephone numbers as follows:
When the first developer issues a pull request, it succeeds with an automatic merge, as we saw earlier. However, when the second developer issues a Pull request, it results in a conflict, which must be resolved before the merge can take place.

If you move forward with the pull request, you'll be faced with the following and will have to do a manual fix in order to resolve the conflict:
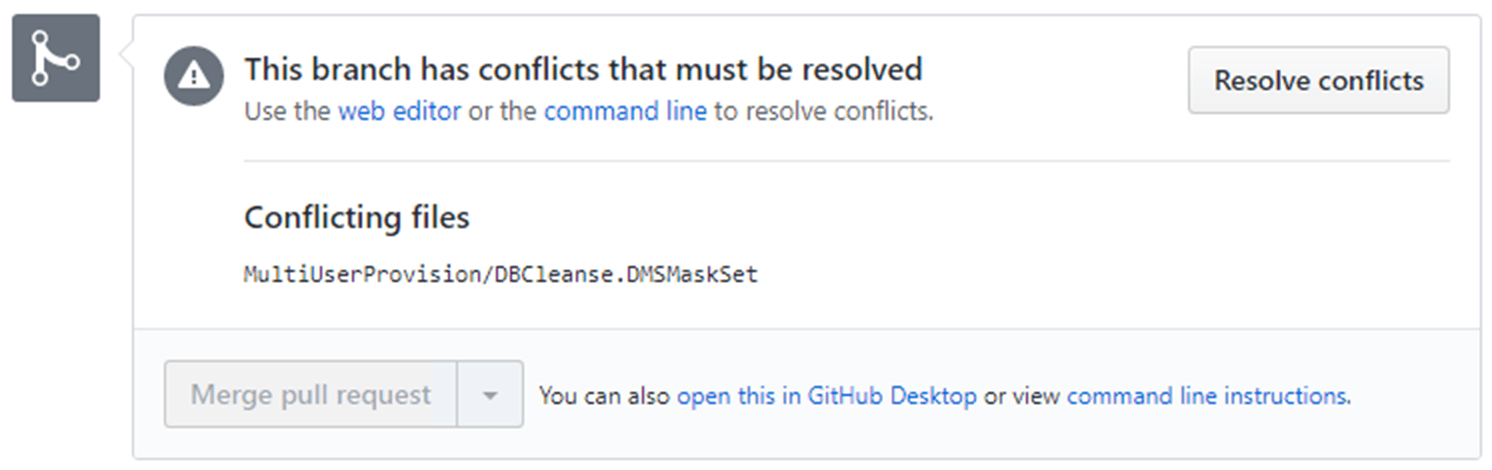
There are several ways dealing with the conflict. If it turns out that the first, successful merge was the one the team wants, then simply remove the second branch and reject it's pull request. If there are elements of the second developers work that you need to retain, then you would need to copy in the XML information, or, re-open Data Masker and add the rule again.
I'll only demonstrate the most common approach, which is to try to resolve the conflict by directly editing the conflicting files. Here, I'm going to use conflict resolution tool within GitHub but I'd only recommend doing that for simple conflicts. Generally, I felt a lot more confident editing the XML in a purpose-built XML editor such as VS Code, where I could see the precise open and close commands for each element.
Let's imagine that, in this case, the team want to retain both the new substitution rules, replacing 90% of the real data with UK phones numbers, and 10% with French phone numbers, reflecting the real distribution of the customer base.
Here is the full window for resolving conflicts:
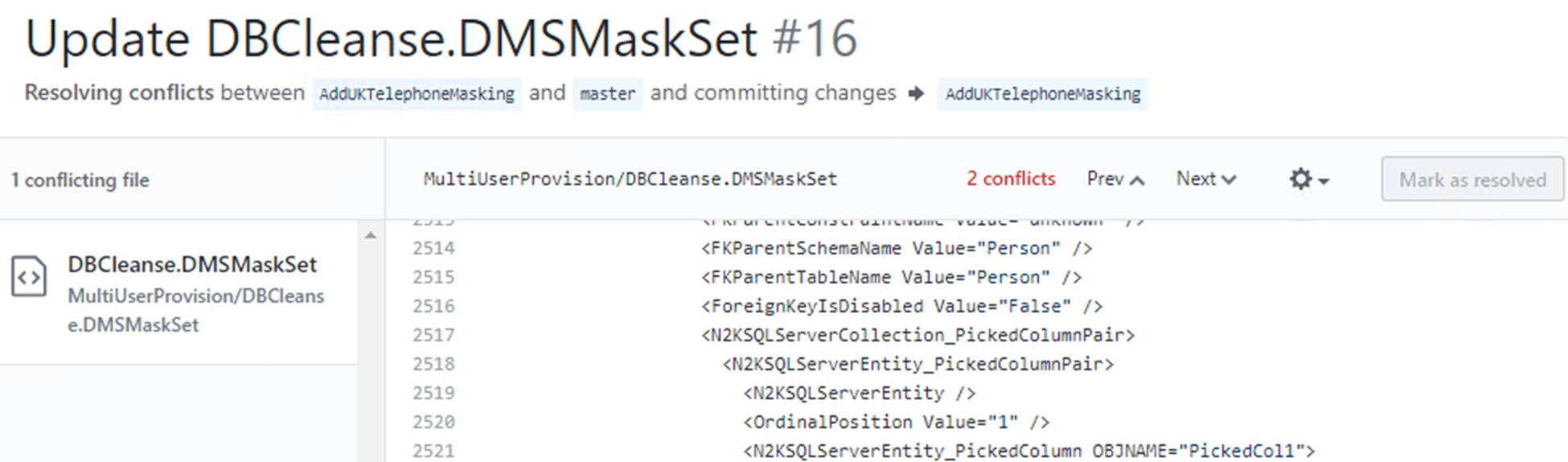
On the left are all the files with conflicts, in our case only one file. You can see that we have two conflicts. Below that is the XML that defines the file. Within that XML, you can navigate to the conflict errors using the Prev or Next buttons in the upper right of the window. Here's the first conflict, and it's essentially a description of the problem; the second developers proposed changes conflict with the current definition of the same rule, in master. You can that difference highlighted by GitHub. The first pull request successfully merged the new rule with the description, "Create French Telephone Numbers" The second developer is trying to merge in a conflicting version of the same rule, to "Mask All Phone Numbers To UK"
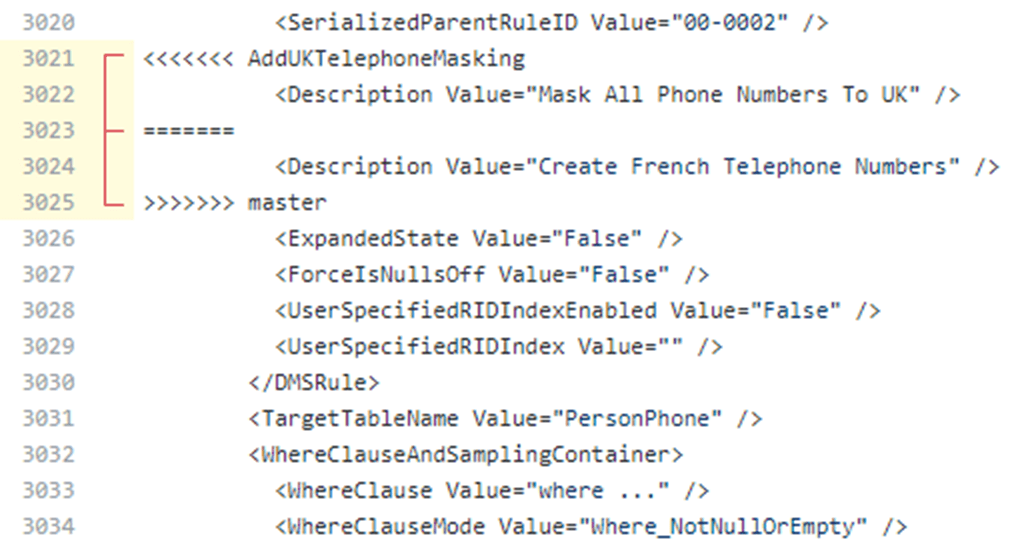
The interesting thing is that most of the XML that defines the two rules is the same. We're only seeing where there are slight differences. Click on the "Next" conflict button to see the other differences:
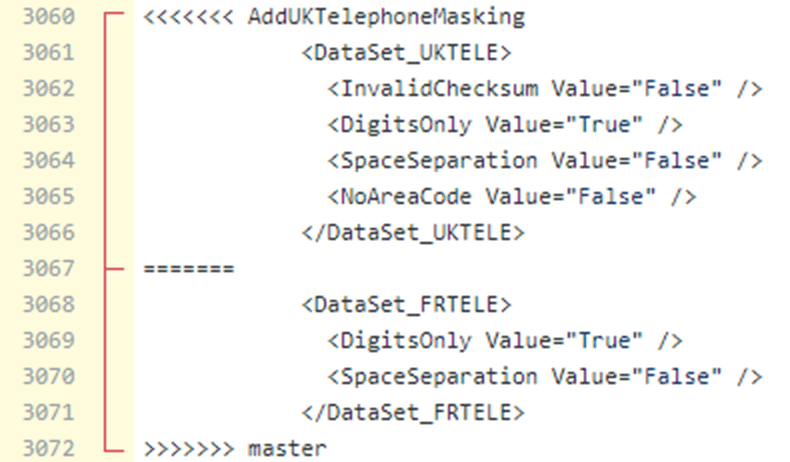
The version of the rule that is currently in the master branch uses the DataSet_FRTELE data set for the substitution, and the version of the file we're attempting to merge uses DataSet_UKTELE.
In order to fix this by editing the XML, there are several stages. First, I'll need to create a copy of the whole rule definition, so that I'm defining two different rules. By looking through the XML, we can identify that the rule is defined by the element <RuleSubstitution>. With that knowledge, I'll copy everything from the <RuleSubstition> starting tag to the </RuleSubstituion> ending tag and paste that back into the XML. This creates a second rule so that we're no longer attempting to modify the existing rule. To denote this as two separate substitution rules for the same table, in the second copy of the rule, I simply need to change the property "Value" in the <RuleNumber> element to "0007", from "0006".
The first rule to run will replace all existing phone numbers with UK phone numbers. I need to edit out the information from this rule that is marked as already being in the master branch. This is the information between "=======" and ">>>>>>> master", at both points of conflict. I'll remove that data and the tags. I'll also remove the "<<<<<<< AddUKTelephoneMasking" tag, added by GitHub to help us navigate to the conflicts. These edits will result in a rule that updates all the telephone numbers to be UK.
Next, I move to the second rule definition and make similar edits but reversing what gets removed. I'll take out the data between "<<<<<<< AddUKTelephoneMasking" and "=======", inclusive. Then I'll remove ">>>>>>> master". This will leave the second rule in a state where it will replace all the UK telephone numbers with a French telephone number.
Of course, this is not what we want. We want to replace only a sample (10%) of those numbers with French numbers. To achieve that, I'll go to the <SamplePercentage> element in this rule and change the property to "10.00". That will make it only update 10% of the numbers to a French telephone, more accurately reflecting our real data. Then, for this to take effect, I modify <WantSamplePercent> to be "True" instead of "False".
If you're wondering why I didn't use a sampling for both rules, 90% in the first and 10% in the second, it's because we wouldn't see a neat break between 90% updated one way and 10% updated the other. Data Masker is very sophisticated and will distribute a sampled update. This could lead to data not being properly masked. To prevent this, we mask 100% of the data one way, then modify subsets of the data.
When I've got all the edits complete, including removing the tags that were added by Github, scrolling back to the top, you can now see that the "Mark as Resolved" button is enabled. Clicking on that changes the screen:
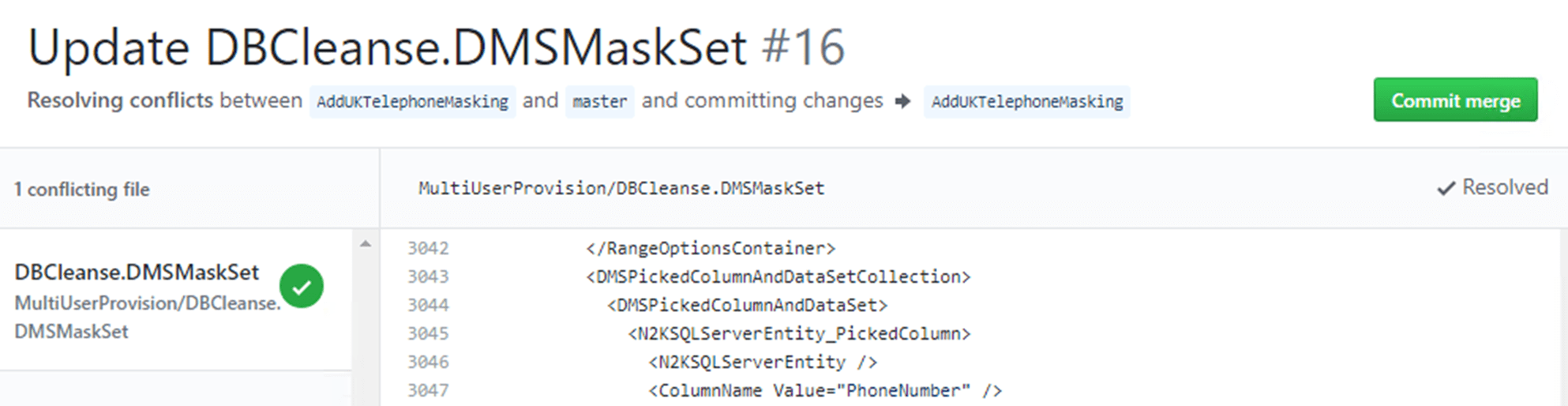
I can now click on the "Commit Merge" button and my merge will be done. From there I can complete the pull request as we've already seen before.
With all this completed, the next time a user synchronizes with the master branch and opens the Data Masker file, the complete rule set will look like this, showing two substitution rules for the PersonPhone table, one for the UK and one for French. You can also see that the French rule is using 10% sampling, all exactly as we defined it within the XML:

Conclusion
If more than one person in your organization is responsible for developing and maintaining data masking rules, then you need to coordinate this through source control. Just as with any well-run DevOps process, avoiding conflicts requires good communication, and a focus on frequent, smaller changes so that any that do arise are relatively simple to resolve.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Tools in this post
Data Masker
Shield sensitive information in development and test environments, without compromising data quality
SQL Provision
Provision virtualized clones of databases in seconds, with sensitive data shielded
You may also like

Article
How to do Accurate Address Masking using Data Masker
Grant Fritchey shows how to adapt a data masking process, for address data, so that it incorporates knowledge of the data distribution in the real data. The result is fake address data, with an accurate distribution, for use in development and testing work.

Article
Safely Deleting Clones and Images during Database Development and Testing
Whenever you’re ready to refresh a test cell with the latest database version, you need a safe way to drop the current set of clones, and the parent image, without losing any unsaved work. Phil Factor provides a PowerShell script that automates this process so it runs in the time it takes to grab a coffee, after which can quickly deploy the new clones.
Article
Why is my clone so small?
How is it possible that the cloned databases could be so small and lightweight, and yet behave exactly like any normal database, complete with all the data? It sounds like magic, but it's not. It simply makes clever use of native Windows virtualization technology.
Article
Team-based database development with SQL Clone
For most development teams, the database provisioning process involves some element of compromise. Either the process is slow, but the database is realistic or the process is fast but the database unrealistic. Chris Hurley explains why SQL Clone can allow the team to develop and test with a real database, without the compromises.
Article
SQL Provision offers users an easier way to manage, organize and make available masked copies of databases
Rebecca Edwards premieres the new SQL Clone 3.0 dashboard, and explains new features to make it easier to manage clones, view recent activity on them, and reset clones with the push of a button.

Article
Getting Started with Database Development Using SQL Provision
Steve Jones shares how he migrates his existing development databases to clones, using SQL Provision and a simple PowerShell function.
Loading comments...