
Network infrastructure is not inherently obvious. The logical flow and layout of data traffic isn’t apparent in the same way that it is in other complex systems, like highway infrastructures. This makes computer networking more difficult to envision at a glance.
Adding to the difficulty is, unlike highways, computer networks’ complexity is not necessarily a function of their size. With large interstates, elaborate interchanges are required, whereas small side streets may only require stop signs. It’s frequently the case with computer networks that instead of stop signs, small infrastructure administrators are required to engineer the equivalent of a scaled down interchange with a similar level of complexity.
Computer networks may need to be complex, but they don’t need to be a mystery. With the right viewpoint and frame of reference, the relationships between the logical systems become clear, and we’re much more easily able to grasp the root of problems, rather than flail blindly at symptoms.
Designing Networks
Designing a network from scratch isn’t something that most of us need to do very often, but when we do, it’s vital that we get it right. In larger organizations, engineers, manager and the implementation team would be involved at every step to develop, present, and approve designs. In smaller infrastructures, we, as sysadmins, are very often on our own. With no-one around to check our work, extra diligence is required. We have to ensure that the plans we lay down are sound and logical, that they meet the organization’s requirements, and that we have the budget necessary to implement our designs.
We have to ensure that the plans we develop are sound and logical, that they meet our requirements, and that we have the budget necessary to implement our designs. In a small organization, there is little or no room for design mistakes. An unnecessary purchase of a few thousand dollars makes a lot more difference to our small organization than it would to a Fortune 500 company.
All of these necessities when designing new networks also apply to wide-scale upgrades of existing networks. Any significant change to the networking layout needs to be approached from the perspective that we are building a new network entirely. Failure to see things from this viewpoint may lead us to include aspects of the previous infrastructure that would be better dispensed with.
In my experience, subnets in small infrastructures generally consist of three kinds of networks. The logical network divisions created by these subnets mimic the logical security divisions necessary between servers and the clients that access them. For the following taxonomy, consider each subnet in your infrastructure as its own network.
End-User Networks
These networks are the typical “small office / home office” networks. Doctors’ offices, some retail stores, and maybe your home network are examples. Any time you’ve got users accessing a network, and there are no servers on that particular network, then you can look at it like an end-user network.
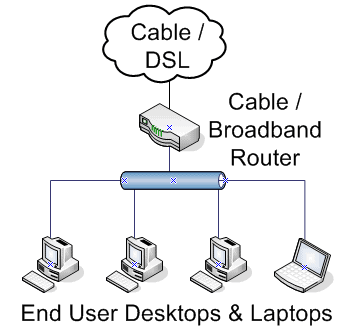
Figure 1.1: A simple end-user network
These networks are the simplest to administer, because typically we’re only concerned with ensuring that each of the nodes has network connectivity and that the gateway device (such as the router or WAN link) is functioning properly.
On small end-user networks, network security is typically accomplished by a low-end firewall at the gateway and antivirus software running on the PCs. More elaborate security configurations aren’t usually necessary, but would become so if the small end-user network were a branch of a larger organization that had more stringent regulations.
These networks typically involve a centralized physical point where all of the client nodes connect, or several of these that are geographically close to their end points. In a small network, such as a dentist’s office, in-wall wiring is probably run into a closet which houses a switch and a router/firewall combo. In a larger network, such as a warehouse, several switches are used to ensure that wiring lengths are kept to IEEE specifications.
Server Networks
Servers are highly specialized computers, and the design requirements for the networks they utilize are specialized as well. Servers provide access to multiple clients, whether they’re internal to the organization or internal; therefore a network outage on a server is more serious than a network outage on any one client. The network that provides access to these machines needs to be more reliable and fault tolerant than would be the case for desktop computers.
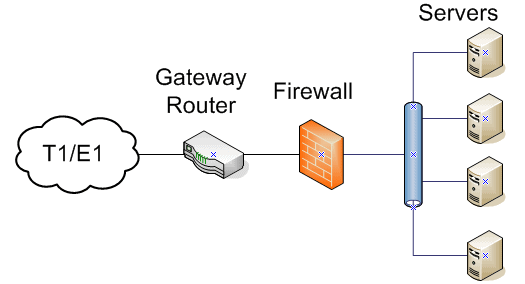
Figure 1.2: A simplified server network
Each server machine is accessed by multiple clients, therefore the network performance needs are higher than on end-user networks. The uptime requirement for the server infrastructure is therefore considerably higher.
In addition to a more robust network, security needs are also increased. A firewall on a server network is sometimes an additional piece of hardware, rather than being integrated onto the router, but the router itself can also be configured with Access Control Lists (ACLs) as a first line of defense. Alternatively, a unified security device that performs routing and firewall functions may be utilized, which provides the added benefit of simplifying security management.
Server networks are typically limited in geographic area. Server rooms or closets are usually as large as these grow, although sizable organizations can have several server rooms or datacenters.
Hybrid Networks
In situations where we have a single network with both end-user workstations and servers on the same subnet, we can consider this a hybrid network. These are certainly the simplest networks in terms of infrastructure, but they’re a bad idea except in the smallest installations. Sometimes we can’t justify building an entire separate network for a couple of servers or a couple of desktop machines, but for anything mission critical, segregating the servers and workstations into separate networks is definitely preferred.
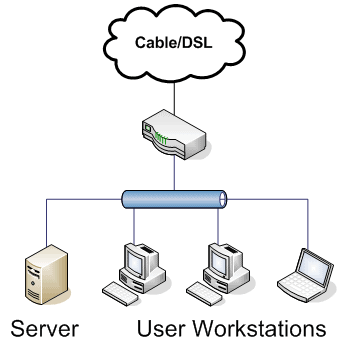
Figure 1.3: A typical simplified hybrid network
These networks are simple to envision but complex to securely administer. In an ideal situation, we would always have a traffic control device between our users and our servers to act as a security checkpoint. We only want specific traffic hitting our servers, and without intervening access control between the desktops and servers, we’re at the mercy of the users (or the mercy of whoever ends up controlling their machines, if malware gets installed). Because of that, we’ve got to take extra care when configuring the software firewalls on each server.
Due to the small nature of the organizations that use hybrid networks, there is usually only a short distance between nodes. A small bookstore that has point of sale (POS) terminals that connect to a back office database server for inventory information would be a typical example.
As soon as a network in this category requires more than just a couple of servers, the network needs segregated into different subnets. Access control is much simpler with a router/firewall between our users and our servers.
Also, when we are configuring access control, the chances of us screwing up as we configure a single router is much lower than if we try to individually configure half a dozen machine firewalls.
One of the more compelling reasons to avoid this network layout is that one rogue desktop can take out an entire server. It’s not unheard of to have users play with settings and “accidentally” assign themselves an IP address. If that IP address happens to be the one that belongs to the server, everyone loses access. This is not a fun thing to diagnose, either. Do yourself a favor and segregate your networks when possible.
Once we segment our network, we can treat each segment according to the category that it fits best into.
Business Dependent Design
In a sense, small infrastructure administrators are like model railroad hobbyists. We design, implement, and maintain an entire infrastructure by ourselves, or with a small group of people. One of the dangers of this is that we can be drawn toward complexity in our infrastructures the same way that model railroaders are drawn to create intricate and complex structures in their miniaturized worlds. We need to steer clear of this inclination.
The design of our networks should only be as complex as the business needs it to be. You may desperately want multiple T1s because you’ve been dying to try a multilink PPP connection. You might really want to secure the network by using 802.1X authentication (and purchasing switches which cost several hundred dollars more than they would otherwise), but if there is no legitimate business need, don’t.
As your organization gets larger, it may start to be appealing to have each department use its own network. There’s nothing particularly wrong with this idea, and large companies all over the world use this model. If this is something that you’re contemplating, consider the business justification behind it. The biggest difficulty that it introduces is the extensive (and expensive) amount of underlying infrastructure that needs to be in place to make it happen. Switches and routers need to be aware of VLANs from top to bottom, and you’ll need to make decisions as to whether or not to support dynamic VLANs, which are convenient but generate yet another system to engineer. If the cost and time aren’t justified, it doesn’t make sense to execute the plans.
If you’ve inherited a large, complex network that has since shrunk, you may rightfully want to simplify the infrastructure, but again, this has associated costs and drawbacks. Assuming the best of all possible worlds, where documentation is current and up to the minute, you would need to re-engineer enough of the infrastructure that will remain in order to provide services lingering on the soon-to-be-disposed of networks. Only once the service has been prepared and put into place can the removal of the legacy infrastructure begin. Completing the removal of infrastructure takes care and patience, because as you disconnect, your previous work will need checked to ensure no loss of services.
Evaluate the situation, and justify the cost and time that you would invest. Make no large decisions that affect the infrastructure without weighing the pros and cons first.
Form Follows Function
The two hardest parts of any engineering endeavor are knowing where to begin and knowing where to end. We know that we need a network, but if we don’t explore the needs driving the request, we’re bound to end up with lousy results.
When we begin planning a network, the very first question that we need to ask ourselves is “why”. What need would this network fill? Is it a server network or an end-user network…or is this a small enough network that it has workstations but still needs a server or two, and so needs to be a hybrid?
By answering this question first, we set the tone for the rest of the network configuration. It also gives us a much better idea of the quality of hardware that we’re going to need to buy when the time comes.
Size of the network should be our next concern. An end-user network in a small office is one thing; a multi-building dormitory network is something entirely different. Each goal is achievable, but there are orders of magnitude more resources required for the dorm network.
1.4: Campus scale network vs. office network
The next things I look at are the specialized requirements for this particular configuration. Unusual geography may cause part of the network to be attached using wireless radios or repeaters, or particularly long network runs may require the use of fiber optic cable and transceivers. If the fiber needs laid outside, then contractors need to come in and provide quotes, etc. Identifying unusual (and typically expensive) aspects of the network at this stage will leave fewer surprises when the time comes for in-depth planning, budgeting, and implementation.
Performing these early evaluations allow us to examine the form that our network will take. Watching it develop as we work through the various phases of completion gives us the chance to ensure that “feature creep” doesn’t set in and stop (or reverse!) our progress.
In the end, every piece of the network infrastructure should directly support the business or support another aspect of the network. The unnecessary, ornamental, and extraneous should be left out.
As Simple As Possible, No Simpler
In our efforts to simplify the network, it is possible to go overboard and start removing things that should remain in, even though they might be thought of as optional.
Be careful about trying to make the network too simple. By removing logical divisions, such as subnets, we may run the risk of overloading the remaining networks, leaving them deprived of vital resources such as IP addresses and bandwidth. Desegregating network traffic can lead to data being compromised by interception in a misconfigured network. Trying to patch these sorts of changes after the fact leads to additional expense and downtime, not to mention a headache for the administrator who has to deal with and document the changes.
Oversimplification in the beginning may also lead to inflexibility later in life for the network. For instance, cutting costs out of the gate by making decisions that you don’t need switches that recognize Virtual Local Area Networks (VLANs) will cause issues later if you need to segment your network to deal with growth.
Don’t be afraid of complexity, but don’t revel in it, either. The appropriate amount is whatever it takes to accomplish the goals of the organization.
Documenting Existing Networks
Far more often than being asked to create new networks outright, we inherit existing infrastructures with questionable amounts of documentation. The previous administrator is typically gone, and it’s hard to tell what happened to the network between then and now. We’re handed the reins and told, “make it go.” What do we do now?
Information is power, and without it, we’re powerless. In order to do our jobs, we’ve got to document the network as it exists before we can go about improving it. This important step will be our first clue as to the health of the network.
First, we need to look for any existing documentation. Check in places that old documentation lingers, like the bottoms of drawers, the bottoms of the piles on our predecessor’s desk, and the permanent-looking scrawling on whiteboards. If you’re lucky, you’ll find documentation that has been dated, in which case you’ll have an idea of the last time someone cared about documenting the infrastructure.
The information that we find will probably not be dated, will probably not be done clearly, and will almost certainly be out of date. If we found any at all, that is. If the documentation is clearly poor, it may be better to chuck it and start from scratch.
To get a grasp of the current infrastructure, we need to know what networks exist, and what the devices on them are. Once we have the list of networks and the nodes attached to them, we can start crafting documentation in a form that’s useful to us, and as we repair and improve the network, our documentation needs to grow with us, so it needs to be in a form that’s simple to modify but powerful and flexible enough to cover our needs. To do this, we need to invoke the three D’s: Discovery, Documentation, and (ongoing) Documentation.
Discovery
Assuming that we have no documentation whatsoever, we’re going to have our hands full. Fortunately, several software vendors have produced free and commercial tools to help us learn the layout of the infrastructure.
Finding devices on the network
For the UNIX and Linux world, the most pervasive network mapping tool around is nmap, literally short for “network mapper”. Although primarily command line based, it includes a somewhat limited graphical user interface (GUI) called nmapFE.
In the Windows world, there is a plethora of available software. The most comprehensive that I’ve seen are Spiceworks and LANsurveyor from SolarWinds. Spiceworks is available for free and is ad supported, while the software from SolarWinds is commercial. Both options generate large amounts of information about your existing network and the nodes attached to it.
Additional Information
It is possible to document everything by hand, but it isn’t much fun. In some cases, even with the above software, it’s going to be necessary to do some mapping and analysis by hand, because we’re going to have unknown devices, misconfigured equipment, and other odds and ends that the scanners won’t find correctly.
One of the strengths of the above mentioned software is that they analyze the various packet responses and make informed guesses as to the operating system (and sometimes even patch level) of the remote device. This is handy when our network scan finds a device that we’re completely unfamiliar with.
In addition to the OS guessing by the scanner, it’s possible to do some manual detective work and narrow it down even further. Performing a full port scan on the device can yield many clues. Web ports (80, 443, 8080, and 9090) frequently give us interfaces that tell us what machine we’re looking at, and if the interface itself doesn’t, the HTTP headers may.
Get HTTPS headers
It’s simple enough to get HTTP headers by telnetting to port 80 of a web server, but HTTPS is more difficult due to the encrypted connection. To get around this, utilize the openssl command: ‘openssl s_client -connect <hostname>:443’
Other useful ports are the Windows file sharing and management ports (139, 443), various database ports (3306 for MySQL, 5432 for PostgreSQL, 1433 for SQL server), and mail ports (25 for SMTP, 110 for POP3, and 143 for IMAP). If there are unfamiliar open ports on the scanned machine, we can look up the open port numbers in the /etc/services file on a UNIX machine or at the IANA port assignment page, http://www.iana.org/assignments/port-numbers
Finding physical devices
There are times when we’ve been given a network and we’ll be perfectly able to administer the machine on the network, but still have no idea where it physically lives. This never seems like an important issue until the machine stops responding. There’s no more frightening of a feeling than knowing you have a down machine and have no idea where to start looking for it. This is why it’s important to document these sorts of things when the network and machines are functioning reasonably well.
In recent years, many hardware manufacturers have gone out of their way to make it easier for us to locate a particular physical machine. Most major server hardware manufacturers include software for their servers to flash a system identification light to let the admin know which machine they should be connecting to. Lots of us don’t have the server hardware with this feature, though, and need to use other methods.
Fortunately, almost every computer in the world comes with a conspicuous method of identifying itself: the CD-ROM tray. By issuing an eject command on the machine scheduled for service, you can be sure that when you get to the server room, if the machine’s drive isn’t open, you need to double-check the identity before you start to work. It’s better and cleaner to use the system ID light, but if our machine doesn’t have one, it’s better to use the CD than to take down the wrong machine.
Finding the physical location of a physical machine has not been made easier by virtualization. In some cases, it’s even difficult to determine if a given machine is physical or virtual. There are indications that you can check to determine whether you’re in a physical or virtual machine, but these aren’t guaranteed to work as VM technology progresses. As of this writing, there is no documented way to determine an unmodified VM host from within the guest VM. There are ways of modifying the guest VM’s various hardware identifiers, but these need configured and recorded beforehand in order to be utilized.
As a last resort when identifying a node on the network, if you can obtain the MAC address from the OS, you can then track down the switch port that it’s connected to and then trace the cable to its destination. In the case of a VM, at least you’ll know the VM host. If the other end of the cable is attached to a wireless access point (AP), then we’ve got our hands full.
Physically locating a machine connected over wireless is imprecise at best. Even in large, complex wireless networks, triangulation is used to narrow down the possible locations. There is an entire field called “wireless forensics” devoted to this topic. Generally speaking, with a single AP, it is very difficult to determine where a single machine is. With a sufficiently configurable AP, you may be able to determine the power of the signal that the device is using, and work backwards from there. In a less feature rich device, you may be able to repeatedly lower the power until the device disappears from the node list, at which point you know the relative strength, and can use this to experiment and compute a likely area for the device to exist in.
Documentation
Discovering the devices on our networks is important, but the process doesn’t end there. Recording the information we have on each device is just as important as finding it was in the first place.
The information from this article ‘Documentation: Shoulda, Coulda, Woulda’ will be useful for giving you details on the best ways to store the information and keep it up to date, but you must first gather the information that becomes the documentation.
When dealing with new network equipment, or network equipment with which we’re unfamiliar, it’s very important to record the physical specifications of the equipment. For network devices like routers, this is the manufacturer, the model number, the firmware version, and the serial number of each particular unit. I also record any distinguishing features that aren’t given away by the model number; the number of ports or interfaces, for instance. Finally, if the device supports it, I download and save the configuration, along with the date that I retrieved it.
For computers, the first things I record are the manufacturer and model, if it’s from a vendor like Dell or HP. Many times, we’ll find cobbled together servers that are re-tasked desktops and custom build “Franken-boxes” that no vendor would touch. In this case, the important parts are going to be the motherboard and processor model. All computers should have certain hardware information recorded, such as amount of physical RAM, operating system (and version), purpose(s) on the network, and important services running.
One of the most difficult parts of dealing with a new (or inherited) infrastructure is keeping track of passwords. We don’t have them memorized yet, and its bad practice to write them down and keep them beneath our keyboards. What to do?
I use a password management program called Password Safe to help manage my passwords. With this tool, I create a “master safe” that holds my other passwords securely. Another similar program that many people use is called KeePass.
Tool Repository
You can find these, along with hundreds of other useful utilities, in the “Tools” section of the League of Professional System Administrators (LOPSA) site.
All of these bits of data added together can be used to create the actual documentation, which exists in several forms. The most basic is a simple spreadsheet that retains all of the gathered information so far. A better solution is a web-based repository that’s accessible from anywhere.
An excellent solution that I have used is GLPI, a free open-source inventory management system. When combined with OCS Inventory and its agent, it makes for a powerful interface. These are by no means the only solutions, but they have worked well for me.
Ongoing Documentation
The third ‘D’ is again “Documentation”, but this time, I’d like to consider a different aspect of it. It is not enough to discover the layout of the network and document it.
Documentation must be continued with every change that you make. The network that you inherited was in a sorry state because the previous administrator did not document the network that they created, and they did not document changes throughout the lifecycle of the network. Let us learn from their mistake and become better administrators.
After a few years, the chances of our network looking exactly like it does now are remote. So many small things change that render existing documentation obsolete that even a list of IP addresses may not matter in a short time. Playing catch-up after a couple of weeks, and trying to remember all of your changes will lead to inaccuracies down the road. These small differences will inevitably come to a head at the worst possible time, when you need to rely on the faulty documentation.
Murphy’s Law et al
Although the most famous pessimistic adage is Murphy’s Law, phrased “Anything that can go wrong, will”, there is an aphorism known as Finagles’s Corollary that may apply even more to system administrators: “Anything that can go wrong will, in the worst possible order.”
It is for this reason that we must continuously document the infrastructures that we work on, as we work on them. We are our own worst enemy if we don’t do this, because when something breaks, we’re the ones who will fix it, and without up to date documentation, remembering what small changes we made two weeks ago will be impossible at 3am.
If we were to pull up our diagrams and spreadsheets every time we needed to make a change to the documentation, we’d never have time to make changes to the network. Instead, why not take a physical notepad and dedicate one page per day to changes that we’ve made. If we date the top of each page and list each change as we’ve made it, we’ll not only be able to take a few minutes at the end of each day reviewing our changes and updating the documentation, but we’ll have a physical record of what changes were made when. This can be exceptionally useful in many situations, from answering questions such as, “when did X happen”, to “what were you doing with all of your time?”
Seeing the Relationships
Computer networks are a collection of systems, and by systems, I don’t mean just computers. I mean a collection of separate pieces that work together as part of a whole. Routers, switches, computers, and we administrators ourselves all function as parts of the physical infrastructure of a network, but there are layers above that, as well.
I consider systems to be task oriented. Email is a system, as is DNS. The email system relies on DNS to work, and DNS relies on the TCP/IP network. And of course, the TCP/IP network relies on various routing protocols, the layer 2 networking system, and even the physical infrastructure itself to be functioning correctly.
Taken together, all of these separate systems comprise our infrastructure, and in order for the infrastructure to work correctly, the underlying systems need to function. When something is broken, the entire infrastructure may not crash, but it won’t be functioning as well or as efficiently as it should.
Our job as administrators is to ensure that each individual system is functioning, and to tie the systems together in a way that makes sense and ensures the maximum amount of usability of the whole. To do this, it is vital that we be able to envision all of the logical subsystems that comprise it.
Identify systems
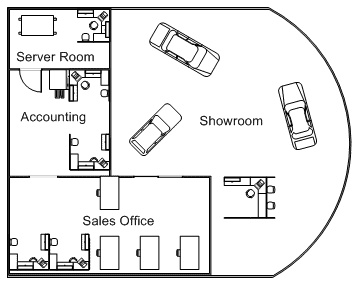
Figure 1.5: Honest Matt’s Discount Auto
Begin evaluating your organization with a broad question. “What do we do?” From this open ended question, we can start to narrow down our systems. If you work for the automotive dealership in figure 1.5, you might say “We sell cars.”
Most companies have a more complex business model. Whenever the answer to the first question is more complex, treat each part as its own question, and complete the following steps for each of those.
Our next question builds on the first answer. “How do we do that?” The response to this query should be much more involved, because we need a certain level of detail upon which to examine our business processes.
“People come to us who wish to buy cars. We evaluate their needs, suggest models that we have, and show them a selection of vehicles that fit their requirements. If they wish to purchase one, we verify any necessary paperwork, transfer the titles, and deliver their car.”
Oversimplified, yes, but essentially, that is the core business of a car dealership. Now that we’ve identified the process for accomplishing the central goal, we need to delve further. “What IT services need to be in place for this to happen?”
You may end up recursing through this question several times until you have the answers you seek. Every organization is different, and the answer to this question may range from a paragraph to a series of books, but the end result is that you identify the separate systems that need to be in place for each of those business purposes.
Abstract the details
After working through the previous questions, you probably have a good concept of what services IT needs to provide to the company, and you’re probably going to start to evaluate how best to implement them.
Wait a bit before you start ordering licenses at this point, because we’re still examining the interdependencies of the various services that we discovered in the last step. Let’s briefly surmise what we’ve learned about our automotive dealership.
Through in depth examination, we’ve learned that we need a centralized database to store various billing details, inventory, customer records, and the like. We also need a file server, because the salesmen want to be able to see the raw contracts in one space, and human resources would like to have a single location for employees to pick up time-off and 401k forms. Several of the new car models are going to be able to tie into Wi-Fi networks, so we’re going to need one of those on the showroom floor. The office staff is going to need wired access in the offices and cubicles, but the salespeople will need Wi-Fi everywhere. Also, the owner wants a website where people can click and see the cars in 3-D and sign up for test drives online.
Notice that not once did I say “We need an X brand database”. At this point, we don’t care what the actual implementation is. We can’t. Tying ourselves to one particular brand will limit our choices just when we need to have the most flexibility.
From these requirements, we know that we’re going to need at least one user network and at least one server network. It’s tempting to say “We’ve only got two servers, a database and a fileserver. We can shove those on the same machine and make it a hybrid network”.
Avoid this temptation, because it’s going to drive us crazy in 6 months when, thanks to the spectacular job we’ve been doing as the network administrator, operations have improved their efficiency 300% and the dealership buys a competitor. When that happens, all of a sudden we have who-knows how many servers to deal with, all vying for resources on our only network, all capable of having any single user deny access to everyone through a simple misconfiguration. And that’s not even considering the Wi-Fi.
“The Wi-Fi”, you ask? Yes, the Wi-Fi. In our efforts to oversimplify, we’ve undoubtedly used the same wireless network for the cars and the salespeople, and of course, the cars are difficult to configure, so the wireless network was left unencrypted, which means that the salespeople’s traffic is unencrypted and open to interception, not to mention anyone driving by can attack your servers with ease.
So instead of the oversimplified solution, we think a while and consider our options. Then we design a server network, plus two user networks. One of the user networks will be the office staff, plus the wireless network for the salespeople (encrypted with WPA-2 or whatever is currently designated as “secure”), plus another network that only exists as internet access for the Wi-Fi in the cars. Building a web server is easy. Making sure that it can be accessed reliably is not. Nor is it cheap. We’ll continue to weigh our options of hiring a hosting firm versus building our own infrastructure for that particular requirement.
Identify interdependencies
At this stage in planning, the details are still abstracted, but the goal is clearer. We know what systems we need, but we’ve only begun to consider how they really relate to each other, and how we can take advantage of that fact.
All three will need internet access, although the serve r network will really only need it for software updates, and the car network should have no access to the servers or the office computers at all. The office will need access to the servers and the internet. Theoretically, we could order three internet connections, but there’s no reason that the right router / firewall device couldn’t segregate the networks securely.
We’re also going to have two wireless networks. We absolutely could buy two access points and configure each one on their own network, but that’s doubling our efforts and our hardware cost. Instead, we can use one AP that segregates the traffic, and use VLANs to separate the traffic all the way back to the router, which will prevent the two networks from talking. Now we can start looking for specific parts to fill the needs that we’ve identified.
We set up a centralized router / security device that acts as a gate keeper between the various networks and the internet access, and we shop around for an AP that can transmit multiple ESS IDs and that can use VLANs to segregate traffic, so we only have to buy and administer one wireless device instead of two. We also buy a hosting account for the wiz-bang website that the owner wanted, because it’s far easier and cheaper to outsource a reasonably small website than it is to build a high-availability web infrastructure.
Why this is hard to do
As system administrators, our job is to get things done. Most of the administrators that I’ve met see a problem and fix it. Planning is usually done quickly, and only to the extent necessary to finish the task and move on. This technique requires thought and time to plan. Action is held off until the rest of the plan is laid out.
The most difficult part of this process is that not everyone has the same tacit knowledge of networking. If you didn’t know that APs existed that could transmit on multiple ESS IDs, you would have finished with a much different solution to the problem above.
This really is one of the most serious difficulties of being a small infrastructure administrator. We are not typically part of a diverse team of sysadmins. Frequently we’re alone in the job, and the lack of other individuals with which to interact and learn from hampers our technical skills over the long run.
In my opinion, this is why an online community of system administrators is so important. It gives us people with which to interact and people to learn from, and can, in some small way, approximate the environment experienced by admins in larger environments
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments