
It used to be that we would say, “It’s not a matter of if, but when, we will be breached.” The reality is that when many of us said it, we still thought we’d be the ones who wouldn’t be compromised. Today’s a far different world. Now we operate with the understanding that we’re likely already breached, and it’s a matter of finding out where and shutting things down, if we can.
However, as a whole we’re not being very successful. Some organizations are doing a great job. Too many others, however, are not. Data breaches are common news. And just looking at the United States, too often the first time an organization realizes it has been breached is when the US Secret Service pays that organization a visit, revealing that they have clear evidence that data has left the organization and is now for sale.
Problem #1: Whom Do You Trust and How?
One of the issues we face is wrapped around trust. What can be trusted? Who can we trust? Can we trust the connection? Is there a period of time when they are untrustworthy? Who determines trustworthiness?
If we think about it, this is an issue in society. The difference is things tend to move a lot slower than on the wire. It’s easy for a criminal to withdraw all the funds from a bank account in a matter of minutes. An adversary can break in and steal all the intellectual property on a given project in a matter of days or weeks. To gain the level of trust to get access to that level of information often takes months or years. Therefore, it’s easier, faster, and more risky to be on-line. But being off-line isn’t an option for most folks.
Problem #2: Insecure Protocols
Most of the protocols we use to communicate were written during a time when the networks they were used on were mostly isolated and limited to primarily government and academic use. As a result, security wasn’t baked into those protocols. With the boom of the Internet on top of those protocols, it has proven extremely difficult to try and build security on top of what are inherently insecure means of communications.
Problem #3: Insecure Practices
Most organizations of any size hold security awareness training, usually annually. Some organizations go even further and organize attempted phishing attacks by an auditing firm to determine how well users are paying attention to said training. And, more often than not, the number of times the email is opened, and the link is clicked is discouraging. This is just one example of how we often commit actions which lead us to being vulnerable to attack.
Problem #4: So Much Data
This doesn’t mean the data we’re trying to protect. It means the amount of information that we can collect: packet traces, access logs, application traces, and more. There’s so much to sift through to find where a breach started and how extensive it ended up being. And while we collect a lot of information, much of the time we find ourselves missing the exact information we need.
Working Towards a Solution:
When covering the situation and some of the problems we face, it appears like anything we do is a lost cause. However, that’s not the case. Facing facts, there are some extremely capable adversaries out there who, if they target us, are going to eventually be successful. While there are those top skilled teams out there, most of the threats we deal with don’t come from them (exception noted if you’re working in government, especially military, or a related career field). There are some solid things we can do to try and detect a breach, or at least, give us some indicators that something suspicious is going on.
We’re going to make some assumptions. First, we’ll assume no one is above suspicion. After all, a trusted employee who gets hit and falls to a phishing attack is still trustworthy, but his or her user account isn’t. Even the best can fall to such an attack. Therefore, we’ll assume every account is capable of being used for a data breach.
Second, we’ll accept as a given that there are insecure protocols and insecure procedures/behavior. From a technology side we can do some things about those areas, but there are still too many situations we can’t deal with by using technology alone. For instance, I know of a case where a client had an employee find several hundred printed pages of sensitive information just left sitting in a publicly accessible smoking area. Using Extended Events in SQL Server can’t fix that type of lapse in security. However, rather than throwing our hands up because we can’t prevent this type of situation by some configuration within SQL Server, we’ll endeavor to do what we can with what SQL Server can do for us.
As a corollary, we’ll assume that discovering data breaches is hard. If all we have is what’s in SQL Server, the odds are stacked against us. Even with sophisticated tools, detecting a breach is still a difficult endeavor. However, we’ll do our best to set up methods of detection using what we can within SQL Server.
Finally, we’ll acknowledge there’s a lot of data we can collect. That data is useless if we can’t sift through it, so we’ll take an approach that will reduce the amount of data we do collect and try to examine. Let’s look at what that approach consists of.
Audit and Report Changes to Logins, Users, and Permissions
When an attacker gains access to a system, typically one of the steps is to secure future access. There are a couple of ways to do this when it comes to connecting to SQL Server. One way is to change the password and permissions of an existing, but little used login. Another way is by creating a new account, hoping that it will go undetected. At the database level, it’s giving a login, that previously didn’t have access, a user account within the database with the appropriate permissions to see everything.
Given that a lot of environments don’t audit every security change on their SQL Servers, either of these is usually successful in order to maintain access. Therefore, if we audit and verify any and all security-related change within our SQL Servers, we can spot such activity. The catalog views we’re interested in are:
-
sys.server_principals
-
sys.server_permissions
-
sys.server_role_permissions
-
sys.database_principals (per database)
-
sys.database_permissions (per database)
-
sys.database_role_members (per database)
The limitation with the catalog views is that they only provide us an instantaneous snapshot of what the state is at time of query. For instance, if a login is deleted yesterday, we won’t see anything about it in the server level catalog views. We see the logins as they are when we executed the query. If we are periodically querying these catalog views and storing the results, there is some use to that. We can, for legitimate purposes, be able to tell what the logins, users, and permissions were at a given point in time and this can be incredibly helpful from a troubleshooting perspective. We can narrow down when a change happened to determine when something stopped working, for instance. From an auditing perspective, having these types of records can help us determine a period of time to take a closer look. For instance, if a login wasn’t there Monday but was present on Tuesday, we know the time range to examine.
To that point, we do need more detailed records of activity. One built-in way is to have Audits set up to detect changes. For instance, here’s a simple audit specification to detect changes to logins:
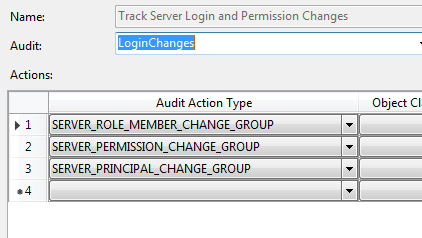
When we check the logs, we can see that a login was created, a role membership change was made, a server level permission was executed, and a login was dropped. Looking at the details for that role membership change, we see that a login was added to the securityadmin fixed server role.
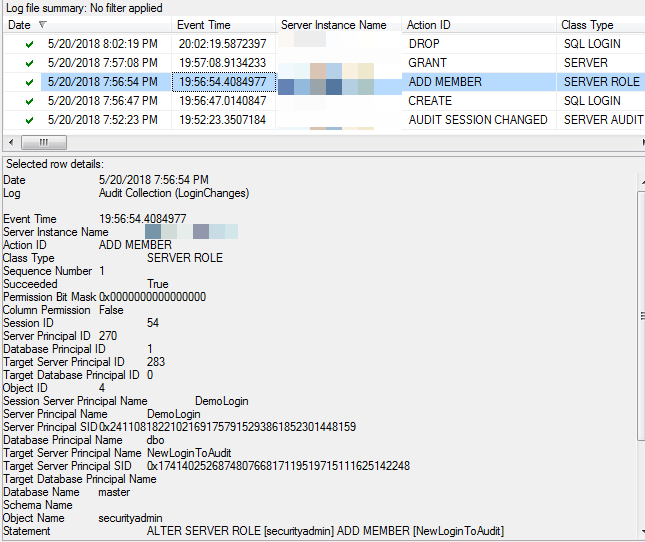
Audits can be scripted and quickly deployed across a SQL Server farm. This is an effective way of setting up the type of information gathering we need. However, the proviso still applies: this data does no good if no one is looking at it.
Taking a regular snapshot of what the catalog views contain can help us narrow down when something happened. That can tell us when to look in the Audit logs. Hopefully we’ll find the information there, and quickly. However, there does need to be a regular review of the Audit logs, regardless of what we’re doing with the catalog views. After all, if we’re querying the catalog views once a day, then we won’t detect the case where an attacker creates what he or she needs, uses it, and then deletes those objects to cover their tracks if the attacker performs all of these activities in between our querying. Therefore, with or without the catalog views, it’s important to have some way of regularly examining the Audit logs against what has been authorized and expected.
Audit and Report Changes to Objects
Just as we’re concerned about logins/users and their permissions, we are also concerned with changes to objects. This does include the object permissions as well. Object doesn’t just mean traditional tables, views, and stored procedures. Because of the hierarchical nature of SQL Server security since SQL Server 2005, we’re also concerned with permissions granted at the schema and database levels as well. However, we’re concerned with more than just security.
We’re also interested in changes to objects such as the modification of stored procedures. We typically are focused on the data, but if the purpose of an attacker is to cause issues, not just steal data, then modifying a stored procedure containing key logic becomes just such a method to do so. The same is true of functions.
We should also be interested in tables which appear in databases. It’s not an unusual occurrence in the event of a breach to find that the attackers have created tables and other structures in seemingly insignificant databases. Those databases are chosen because they aren’t seen to be of much value and, therefore, they don’t receive as great a scrutiny as other databases containing more sensitive data. However, if an attacker is looking to exfiltrate data out of an organization, they will probably need a staging location in which to contain the data they’re looking to grab. Either they’ll to bundle it altogether into a few big packages or use processes which slowly move the data out – slow enough that such activity hopefully doesn’t get caught by an Intrusion Detection System (IDS) or Data Loss Prevention (DLP) appliance.
There are various ways of detecting changes. The oldest way is using server traces and periodically reviewing activities. SQL Server has the built-in default trace which does this type of monitoring. However, the default trace is of limited size and wraps around, meaning if we don’t look quickly enough, we could lose the details we’re trying to find. We could build our own server-side traces. When working prior to SQL Server 2012, this may be the most viable option.
Another option is to use DDL triggers. We can create DDL triggers that fire on schema changes. The traditional means of using DDL triggers is to prevent any and all schema changes unless the DDL triggers are disabled. The problem is that we have to remember to disable them. When performing automated deployments, this shouldn’t be an issue. However, if we’re not, this can be a cause for great consternation when a deployment script aborts because the DDL trigger stops it. Alternately, the DDL trigger can just record the changes. This introduces its own host of problems, however, especially if the write target suddenly is unavailable.
The two preferred options built-in to SQL Server are, therefore, extended events and the Audit object once again. Let’s look at how we might set up the Audit Specification in a particular DB.
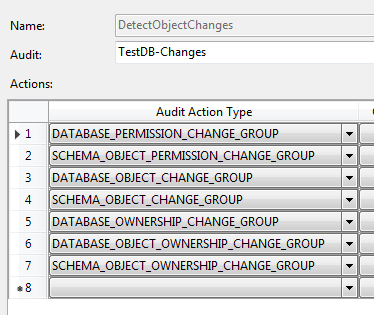
There are quite a few audit action types we’ll have to include. Note that I put both database and schema object level items. In order to see table and stored procedure type changes, we have to include schema_object events because those objects are contained within schema. To see potential changes to schema themselves, we need the database object events. Database ownership change detection are also included, though this shouldn’t ever happen. If it does, we definitely want to know about it.
Now when we check the logs, we can see activity.
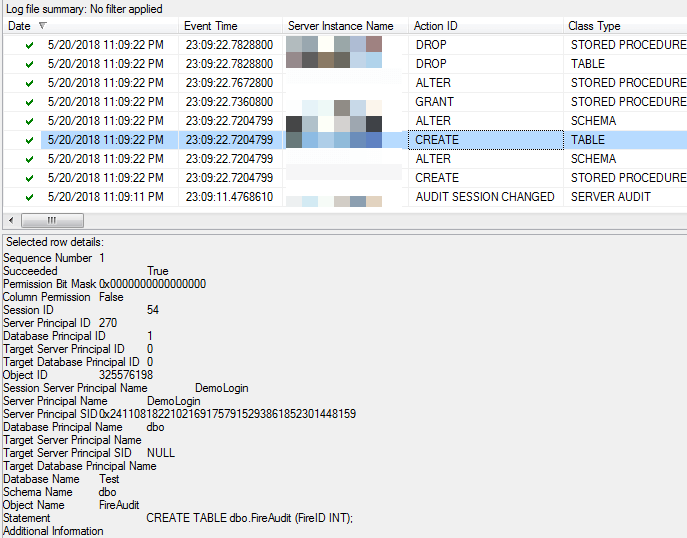
There are a number of audit events here. We definitely see the creation of a stored procedure and a table, as well as a permission change, an alter to a stored procedure, and finally two drops of objects. The detail shows the creation of the table. This is valuable information, especially if we’re trying to detect malicious activity on our databases.
Track Access to Tables Which Contain Sensitive / Private Information
Through the use of Extended Events or the Audit objects we can track when particular tables are accessed. The old means of using server traces work, but server traces are incredibly inefficient and tend to be more costly operational wise. We can see not only changes, which we traditionally audited with DML triggers, but we can also observe when folks are viewing data. DML triggers have their own issues, such as, when they fail, they cause a rollback we may not want to occur.
There are plenty of resources in the community which talk about how to use both Audit as well as extended events to see what’s going on against particular tables, so I won’t give any examples here. What is important is to properly identify what tables we care about and then determine what other objects – views, stored procedures, and functions – access those tables. Then we’ll want to audit for all of them.
A busy system will produce a lot of data. That’s a given. In fact, it’s probably too much data for folks to go through line-by-line. That brings us to our next topic, which is how to make sense of all the data we have to collect to try and detect an adversary in our systems.
Build a Baseline and Continually Compare
In a heavily used system, there will be a lot of activity and a lot of data collected from our audits. This is true of most components of information technology. A great example is at the network layer, where we collect massive amounts of data in the forms of packets traces, access logs, and the like. Sifting through all of that data looking for some indicator of an attack is typically an impossible endeavor. There are simply too many records to go looking at each one. Even if we try and filter down to potentially suspicious activity, the question that quickly comes up is whether that activity is, in fact, an attack. A lot of the time the difference between what is and isn’t an attack is intended use. For instance, creating a login when it’s approved isn’t an attack. Creating a login to compromise a system is an offensive action. To a recording system, both events are legitimate. So how do we deal with so much data and this situation where nuance determines what is and isn’t an attack?
Going back to a concept from performance monitoring and tuning, we create baselines. Most IDS systems now have a learning mode where we let legitimate activity pass through and the system learns what to expect. This is true whether we are talking the network or host level. After a sufficient amount of time, the system is “trained” and when it detects activity that doesn’t match the patterns it has previously observed and learned, it alerts. When it comes to our data collection, we need to do the same thing. Do we expect to only see administrative activity only from a certain range of IPs? Do we only expect a particular range of hours for particular privileged logins to do work? Does that 3rd party application we have to support constantly create its own database objects? Those are the kinds of things we need to look at in order to build learning into our operations.
Use Other Technologies
Building a home-grown solution is probably not going to work for managing a large environment. There’s a reason we have large security event management systems (Security Incident and Event Management – SIEM) capable of quickly processing terabytes of information. There’s simply too much. Therefore, we should look to see where we can leverage other solutions. However, everything we’ve looked at with respect to SQL Server can feed into those systems. An audit object puts its event data in XML format which can be written to either the Application or Security event logs for the OS. Those systems can be taught the format so they can process the event data. Once those systems know how to process those events, they can then be used to see the patterns and do the alerting. That’s invaluable, because that’s a lot of technology and capability we don’t have to design and build ourselves. That frees us up to do more productive work for our organizations. So definitely consider those other tools. The last thing, when it comes to security, that we want to be guilty of is the “not built here” syndrome. Therefore, we must work with the teams that manage those systems to get the information we record into what should already be used by our organizations.
Conclusion
There are numerous problems to securing data. Trust is the number one issue. However, insecure protocols and practices as well as the amount of data we have to sift through to detect a breach are also problems every organization faces. We can improve our likelihood of detecting a breach in spite of these challenges by doing a few simple things. First, we need to audit changes to logins, users, and permissions. Next, we want to look at changes to objects. A small change can have a big impact. Finally, focusing on the data itself, we do want to audit access to any structures which have sensitive information.
When we audit, though, we must be clear that simply collecting audit data isn’t enough. We also must have methods of reviewing that collected data quickly to flag and report any issues or discrepancies which are found. To that end, baselining what is normal access and use is critical. If we don’t know what is normal, we’ll never be able to define what is abnormal and worthy of further investigation. This brings us to a final consideration, and that’s the use of third party tools. At this point, they are a must in an organization of any size. Let the tools do the repetitive tasks and the initial filtering of the data. We need the time to be able to look at the anomalies and determine whether or not we’ve been breached.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments