
Recently, I came across a description of a transformation operation using SQL Server CLR – the goal is to convert, or transpose, columns into rows and rows into columns. Microsoft ACCESS has a SQL TRANSFORM /PIVOT extension to SQL that automatically produces a crosstab query, and SQL Server 2005 introduced the pivot command, but neither simply swaps columns and rows. The problem was to replicate this sort of functionality in SQL Server. It’s possible to write a CLR function to transform the data, however, I believe that a set-based T-SQL query is the preferred solution to this type of problem.
In the example of the CLR transform function, the source data included columns for PaymentDate, and three types of payments:
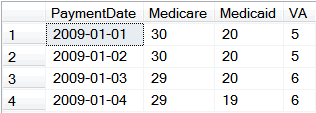
Once transformed the result would swap the columns and rows to this configuration:

The following script creates the test table and populates it with the sample test data:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
Use tempdb; CREATE TABLE Payment ( PaymentID INT NOT NULL IDENTITY CONSTRAINT pkPayment PRIMARY KEY, PaymentDate Date Not Null, Medicare INT NOT NULL, Medicaid INT NOT NULL, VA INT ); INSERT Payment (PaymentDate, Medicare, Medicaid, VA) VALUES ('1/1/2009', 30, 20, 5), ('1/2/2009',30 ,20 ,5), ('1/3/2009',29, 20 ,6), ('1/4/2009',29, 19, 6) |
The root cause behind this transformation is that the three payment columns violate first normal form. Column names that include data (Medicare, Medicaid, VA) is clear indication that first normal form is being ignored with repeating columns. Had the source data been properly normalized there would been no need to transform the columns and rows. If you find yourself needing to perform this type of transformation regularly, then you have a problem with your schema design. A normalized version of the source table should have columns for PaymentDate, PaymentType, and Amount.
But assuming the denormalized data is all that’s available, Microsoft provides a straight-forward solution using the Pivot and UnPivot commands available since SQL Server 2005. The key is recognizing that the source data violated first normal form, and that the unpivot command is designed specifically to normalize this type of unnormalized data. In the query below, the sq subquery first uses an unpivot command to normalize the data which is then passed to the pivot command in the outer query. Pairing the unpivot and pivot command makes quick work of the transformation task. The only trick in the query is appending a “d” before each date so the pivot command will accept it as a column name:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
SELECT Type, d20090101 as '01-01-2009', d20090102 as '01-02-2009', d20090103 as '01-03-2009', d20090104 as '01-04-2009' FROM (SELECT PaymentDate, Amount, Type FROM (SELECT 'd'+ Convert (Char(10), PaymentDate, 112) as PaymentDate, Medicare, Medicaid, VA FROM Payment) as sq_source UNPIVOT (Amount FOR Type IN (Medicare, Medicaid, VA)) as sq_up ) as sq PIVOT ( MIN(Amount) FOR PaymentDate IN (d20090101, d20090102, d20090103, d20090104) ) as p; |
We make some assumptions about the nature of the data when we use the MIN aggregate function. The routine expects to ignore duplicate entries for a particular PaymentDate if there are any.
Before SQL Server 2005, you would have had to use the slightly more convoluted code …
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
-- SQL 7/2000 method -- Transform using Select/Union - Sum(Case) Crosstab (SQL Server 7/2K Method) SELECT TYPE, SUM(CASE WHEN PaymentDate = '2009-01-01' THEN Amount ELSE 0 END ) AS '2009-01-01', SUM(CASE WHEN PaymentDate = '2009-01-02' THEN Amount ELSE 0 END ) AS '2009-01-02', SUM(CASE WHEN PaymentDate = '2009-01-03' THEN Amount ELSE 0 END ) AS '2009-01-03', SUM(CASE WHEN PaymentDate = '2009-01-04' THEN Amount ELSE 0 END ) AS '2009-01-04' FROM (SELECT PaymentDate, Medicare AS Amount, 'Medicare' as Type FROM Payment UNION SELECT PaymentDate, Medicaid AS Amount, 'Medicaid' as Type FROM Payment UNION SELECT PaymentDate, VA AS Amount, 'VA' as Type FROM Payment) AS NormalizedData GROUP BY Type |
You’ll see that this would give different results from the first solution if there is duplicate data in the original aggregate table
There have been several attempts to create a generic solution that emulates the TRANSFORM/PIVOT functionality ,(Rob Volk’s being probably the best known, Dynamic Cross-Tabs/Pivot Tables, but see also Creating cross tab queries and pivot tables in SQL) but the PIVOT/UNPIVOT functionality of SQL Server 2005 onwards makes such devices unnecessary.
The example provides two lessons for SQL server designers and developers. First – don’t underestimate the power of the set-based query. Turning to the CLR for a solution when T-SQL can solve the problem is nearly always an error. Perhaps a more significant lesion is that there’s a performance cost to denormalization when additional code is required to re-normalize the data. The programmer’s cliché, “Normalize till is hurts, then denormalize till it works,” simply isn’t true.
Load comments