
In July 2015, I was invited to speak to SQL Saturday Manchester (UK) on the topic “DML deep dive”. In this session, I showed how heaps work in SQL Server, how Forwarded Records are created and what impact they may have to underlying queries. Heap management is a very complex topic and the time was definitely too short to get into the deep internal details of Forwarded Records. For this reason, I have written this article to highlight the internal behavior of the SQL Server Engine whenever a Forwarded Record is created and read.
Structure of a HEAP
Forwarded Records can only occur in heaps. A table without a clustered index is called a heap because it stores data without any logical order. When a new record is inserted into a heap, Microsoft SQL Server scans the Page Free Space (PFS) Page and searches through the existing data pages which have been allocated for the heap. If it finds a data page that has enough free space to store the record being inserted, than it will be stored there. If, on the other hand, there is no existing data page that has sufficient space, then a maximum of eight new data pages (making an extent) will be created by the SQL Server database engine.
PFS-Page
The PFS Page(s) tracks the allocation status and the used space of data pages. The PFS Page monitors every single data page in a database by using a byte mask for every data page; so one PFS Page can handle 8,088 data pages. If the allocated data page is a heap then Microsoft SQL Server stores, within the first 2 bits, the information about the extent to which the data page has been filled:
| Bit | Value |
| 0x00 | The data page is empty |
| 0x01 | The data page is filled up to 50% |
| 0x02 | The data page is filled up from 51% to 80% |
| 0x03 | The data page is filled up from 81% to 95% |
| 0x04 | The data page is filled up from 96% to 100% |
We will now illustrate, with a code example, the way that Microsoft SQL Server handles pages of a heap. The first code creates a simple table with two columns. Each record will have a fixed data size of 2,504 Bytes.
|
1 2 3 4 5 6 |
CREATE TABLE dbo.demo_table ( Id INT NOT NULL IDENTITY (1, 1), C1 CHAR(2500) NOT NULL ); GO |
In the next code fragment, a new record will be inserted and the location of this new record will be determined by using the internal function sys.fn_physloccracker (sys.fn_physloccracker is a non-documented command of Microsoft SQL Server. It is recommended not to use those commands in a production system).
|
1 2 3 4 5 6 7 |
INSERT INTO dbo.demo_table (C1) VALUES ('Uwe Ricken'); GO -- Check the allocated page(s) SELECT P.*, D.* FROM dbo.demo_table AS D CROSS APPLY sys.fn_PhysLocCracker(%%physloc%%) AS P; |

The above picture shows the LOGICAL position of the newly inserted record. With the next code the PFS will be checked for the degree of filling for the page 126. Due to the fact that this table is part of a very small database, the allocated page is in the first 64 MB, so the first (and only) PFS page will be explored.
|
1 2 3 4 |
-- Check the degree of filling for the allocated page DBCC TRACEON (3604); DBCC PAGE (demo_db, 1, 1, 3); GO |
Please note that the first statement is the activation of a trace flag (TF). The TF 3604 will be used to redirect the output of a DBCC PAGE (DBCC PAGE is a non-documented command of Microsoft SQL Server. It is recommended not to use those commands in a production system) command from the error log to the client application itself. The command “DBCC PAGE”returns the content of the PFS to the SQL Server Management Studio.

The picture shows the result of DBCC PAGE in Microsoft SQL Server Management Studio. Although only 2,504 bytes have been allocated by the inserted record, Microsoft SQL Server recorded a degree of filling of 50%. The result for the next inserted record will be recorded as followed:
|
1 2 |
INSERT INTO dbo.demo_table (C1) VALUES ('Phil Factor'); GO |

The picture shows a degree of filling of 80% which means a total of 6,448 Bytes. A look on the page header of the allocated data page (1:126) shows 3,070 bytes free. Comparing to the length of a data record the next record must fit onto the page.
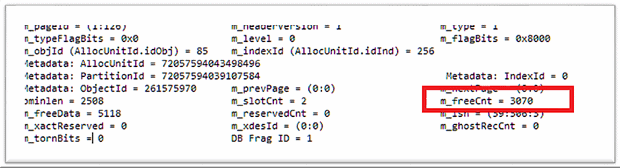
After inserting the third record in the table the result is the allocation of a new data page!
|
1 2 3 4 5 6 7 |
INSERT INTO dbo.demo_table (C1) VALUES ('Andrew Clarke'); GO SELECT P.*, D.* FROM dbo.demo_table AS D CROSS APPLY sys.fn_PhysLocCracker(%%physloc%%) AS P; |
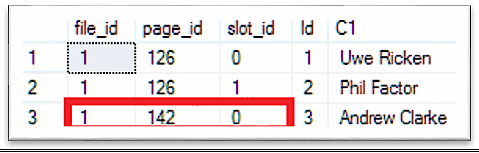
Although there is enough space on the data page 1:126, the new record has been stored on the data page 1:142. The reason is a very simple math. Microsoft SQL Server has checked the PFS page and found a degree of filling of 80%. This 80% represents 6,448 Bytes (8,060 * 0.8). 20% free space on the data page 126 means an amount of 1,612 Bytes. Based on that calculation Microsoft SQL Server will not store a record on the data page because it does not fit into it. Would Microsoft SQL Server check the data page itself than it would see that there are more than 3,000 Bytes free amount of space. Microsoft SQL Server uses the PFS data page for the allocation of data pages for heaps!
IAM-Page
An Index Allocation Map page (IAM) page manages the extents in a 4-gigabyte (GB) part of a database file used by any type of allocation unit. An IAM page manages only data of one table or index.
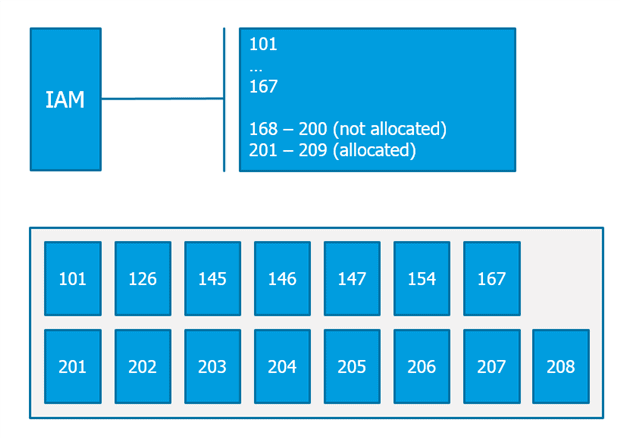
The IAM page will be used by Microsoft SQL Server for the “move” through a heap. Because of the internal structure of a heap that provides no link between the single data pages, the only way that Microsoft SQL Server can navigate between the data pages of the heap is to use the IAM.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
SELECT P.index_id, P.rows, SIAU.type_desc, SIAU.total_pages, SIAU.used_pages, SIAU.data_pages, SIAU.first_page, SIAU.first_iam_page FROM sys.partitions AS P INNER JOIN sys.system_internals_allocation_units AS SIAU ON (P.hobt_id = SIAU.container_id) WHERE P.object_id = OBJECT_ID('dbo.demo_table', 'U'); |

The above T-SQL script lists the [first_iam_page] of the table [dbo].[demo_table]. Microsoft SQL Server only needs the first IAM page to navigate through the table. Each IAM page stores an item of information that gives the location of the next IAM page that manages data from the affected table. This behavior is essential for the handling of Forwarded Records.
What is a Forwarded Record?
A Forwarded Record is a data record of a heap which, because of an update of the data, has increased his volume so much that it will no longer fit completely on the data page. Microsoft SQL Server allocates a new data page and moves the larger record on to that newly created data page. Microsoft SQL Server notes the new place of the record on the original data page; this works rather like the redirection of a letter to the intended recipient’s new address. The reason for such a “redirection” is quite simple; the record is listed still under the same address. If Microsoft SQL Server were to store the new address, it would then need to update all the non-clustered indexes on the data. This would be a much higher workload for the storage engine than the slightly increased IO for a SELECT statement that redirection demands.
Test environment
For the demonstration of a Forwarded Record, I will need to create a table with 20 records. This table has a non-clustered index on the column [C2]. One of these twenty records will then be updated and this record will have a larger size. The new size is so large that the record will not fit on the original data page. The record will have to be moved to a new data page: That is the basic functionality of a Forwarded Record.
/* Create the demo table for 20 records */
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
/* Create the demo table for 20 records */ CREATE TABLE dbo.demo_table ( Id INT NOT NULL IDENTITY (1, 1), C1 VARCHAR(8000) NOT NULL, C2 DATE NOT NULL, ); GO CREATE NONCLUSTERED INDEX ix_demo_table_C2 ON dbo.demo_table (C2); GO /* Now insert 20 records into the table */ INSERT INTO dbo.demo_table (C1, C2) VALUES (REPLICATE('A', 1995), getdate()), (REPLICATE('B', 1995), getdate()), (REPLICATE('C', 1995), getdate()), (REPLICATE('D', 1995), getdate()); GO 5 /* On what pages are the records stored? */ SELECT FPLC.*, DT.* FROM dbo.demo_table AS DT CROSS APPLY sys.fn_PhysLocCracker(%%physloc%%) AS FPLC; GO |
This code creates the table and fills it with 20 records. Each record has a record size of 2,015 Bytes. So every single data page is filled up to 100%.
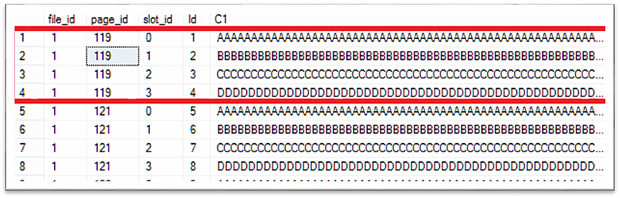
20 data records result in 5 data pages (4 records per each data page) plus one data page for the IAM page.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
SELECT DDDPA.allocation_unit_type_desc, DDDPA.is_allocated, DDDPA.is_iam_page, DDDPA.allocated_page_page_id, DDDPA.page_free_space_percent FROM sys.dm_db_database_page_allocations ( DB_ID(), OBJECT_ID('dbo.demo_table', 'U'), 0, NULL, 'DETAILED' ) AS DDDPA WHERE DDDPA.is_allocated = 1 ORDER BY DDDPA.page_type DESC, DDDPA.allocated_page_page_id; GO |
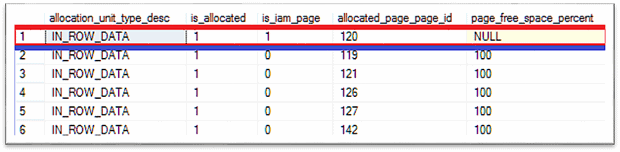
An index scan generates an IO of 5 logical reads of data pages!
|
1 2 3 4 5 |
-- INDEX SCAN over 5 data pages SET STATISTICS IO ON; SELECT * FROM dbo.demo_table AS DT; SET STATISTICS IO OFF; GO |

When Microsoft SQL Server scans a heap, it first accesses the IAM-Pages and determines the pages that are allocated by the dedicated table. When the information about the affected pages has been read, then the actual IO operation (read data for output) can start.
Generate a Forwarded Record
When a record on a data page is updated and the new size of the record increases to a length that cannot be covered by the original data page, Microsoft SQL Server creates another data page and moves the changed data onto the new data page. The following code will update the record with the [ID] = 1 and the process will increase the length of the value in column [C1].
|
1 2 3 4 |
UPDATE dbo.demo_table SET C1 = REPLICATE('Z', 2500) WHERE Id = 1; GO |
By increasing the value of [C1] for the record 1, an internal process has started to find a larger space to store the modified data. A look into the transaction log should make this effort more visible.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
SELECT FD.[Current LSN], FD.Operation, FD.Context, FD.AllocUnitName, FD.[Page ID], FD.[Slot ID], FD.[RowLog Contents 0], FD.[RowLog Contents 1] FROM sys.fn_dblog(NULL, NULL) AS FD WHERE FD.Context <> N'LCX_NULL' ORDER BY FD.[Current LSN]; |
(Please keep in mind that fn_dblog() should not be used in a production system because log clearing is disabled while fn_dblog() is running!)
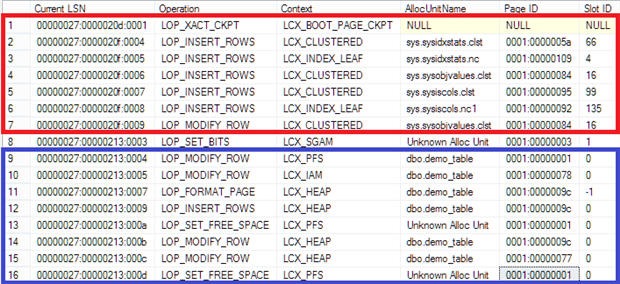
A look into the transaction log shows what has happened. In the first step (red frame), a statistics object has been created. This portion of the transaction log does not help much to understand the internals of a Forwarded Record. However, the second portion of the transaction log (blue frame) shows the individual steps of the database engine when a Forwarded Record is created:
- The PFS records a new data page. By default it is empty, and this information needs to be recorded on the PFS data page.
- The next record (line 10) shows the update of the IAM data page. The new data page is part of the table [dbo].{demo_table]. The managing IAM data page has to record the new structure changes.
- After the system has recorded a new data page in the database, it will be formatted (line 11).
- When the new data page is ready, the ORIGINAL data record will be written to the new data page.
- Due to a new filling degree of the data page, an update of the PFS data page has to occur (line 13).
- When the original data is saved on the new data page (copied) and the PFS data page is updated, the copied record will be updated to the new value (line 14).
- After the new data values have been stored, the record on the source page need to be updated. The data record is replaced by a “Forwarded Stub”. This is a pointer to the new location of the data record (line 15).
- A “Forwarded Stub” has a size of 9 Bytes and this may force an update of the PFS data page again!
Detect a Forwarded Record
A Forwarded Record can be viewed by using the dmv [sys].[dm_db_index_physical_stats]. The following statement shows the allocated data pages of the table.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
SELECT DDIPS.index_type_desc, DDIPS.page_count, DDIPS.avg_page_space_used_in_percent, DDIPS.record_count, DDIPS.forwarded_record_count FROM sys.dm_db_index_physical_stats ( DB_ID(), OBJECT_ID('dbo.demo_table', 'U'), 0, NULL, 'DETAILED' ) AS DDIPS; |

An interesting change is the number of records which are recorded in the result! Although there are still only twenty records, twenty-one are counted, because a Forwarded Record will be counted as a general data record. The information about the Forwarded Records will be stored in the [forwarded_record_count] field.
Read a Forwarded Record
What problems can be occur when a heap is storing a Forwarded Record? As mentioned previously, Microsoft SQL Server reads the IAM-Page to find out which data pages have to be read. When the IAM pages have been read, Microsoft SQL Server then starts the scanning of the data pages. The following code shows the IO when a Forwarded Record has to be read.
|
1 2 3 4 5 6 7 8 |
SET STATISTICS IO ON; GO SELECT * FROM dbo.demo_table; GO SET STATISTICS IO OFF; GO |

The same number of records produce 2 more logical reads (IO). This behavior seems quite strange but it describes exactly the way Microsoft SQL Server is handling Forwarded Records.
First IO
In the first step (not marked as IO) Microsoft SQL Server scans the IAM page and found the pages 119, 121, 126, 127, 142 and the data page where the Forwarded Record is stored as data pages which contain the data of the heap.
Now Microsoft SQL Server starts scanning the first data page (119) – this is the first IO to be counted.
When Microsoft SQL Server wants to read the first data page, it does not find the record itself but instead comes to a link to a new data page where the record can be found. A look on the data page 119 shows the problem:
|
1 2 3 |
DBCC TRACEON (3604); DBCC PAGE (demo_db, 1, 119, 3); GO |
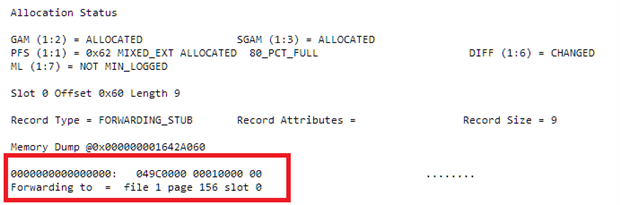
When Microsoft SQL Server hits the page 119 it founds a Forwarding Stub which points to the new location of the record.
Second IO
When Microsoft SQL Server knows the address of the Forwarded Record, it then jumps to this address (page 156) to read this record. Please notice that only this record will be read rather than the entire page! Now Microsoft SQL Server has had to do 2 logical reads (IO) and then jumps back to page 119 to read the other records.
3rd to 7th IO
Once the Forwarded Record has been read, Microsoft SQL Server then jumps back and reads the following data pages (121, 126, 127 and 142) which consumes an additional four logical reads (IO). But that’s not all! Microsoft SQL Server finally has to read the page 156 again because the IAM contains the information about this page which is allocated by the heap.
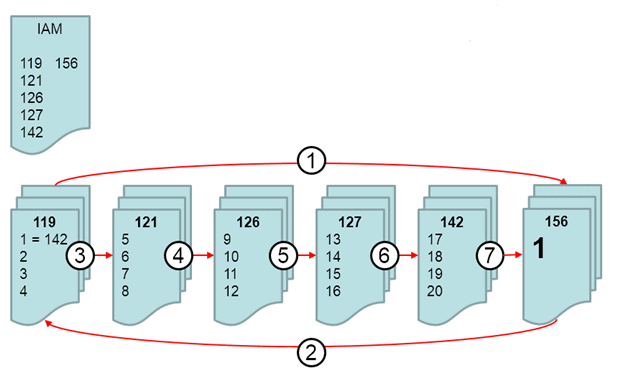
Although this page only contains the Forwarded Record, Microsoft SQL Server has to scan this page again because it is part of the whole structure of the table.
Will the REBUILD of a non-clustered index in a heap point to the new location of the Forwarded Record?
The answer is quite simple: NO! A non-clustered index in a heap stores the Row Locator Id (RID) of the record. The next depiction shows the non-clustered index [ix_demo_table_c2] after the creation of the Forwarded Record.
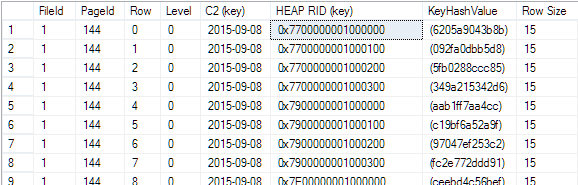
The [HEAP RID] points to the exact position of the record in the heap. The RID is an 8 bytes long value which contains information about the exact location of the record in the heap. The first 4 bytes point to the data page, the next two bytes define the file number and the last 2 bytes point to the Slot Array of the record. The first record with the [ID] = 1 was located on the data page 119 in Slot ID 0. The RID of the first entry points to that record in the heap:
The position does not change when the index will be rebuild!
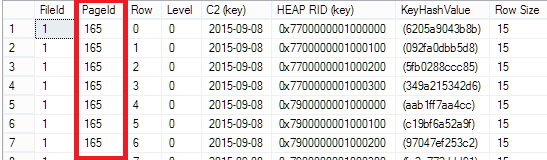
Although the index has been rebuild (see PageId) the position of the record in the Heap has not changed. The result is the same as before and the result makes sense. A Forwarded Record has its original position saved. Due to the fact that the record is too large for the data page it moves to a new data page but left an information of its new position on the original data page. If the record size will decrease it will move back to the original page if it will fit on the page. There is no reason for Microsoft SQL Server to update the index with the position of the Forwarded Record because unless the Heap has not been rebuild the position of the record (forwarded or not) will not change!
Conclusion
Heaps provide great opportunities for fast loads, but they have a few drawbacks which need to be considered. They waste space on a page because of the rough calculation of available space that is made in the PFS, and the system of Forwarded Records will increase the logical reads that are required to access the data in the heap if data is increased significantly on update. Although each Forwarded Record will cause only a small extra overhead of one logical read (IO) it is important to control the number of Forwarded Records in a Heap. As more Forwarded Records occur as more IO will be required. To avoid Forwarded Records it is recommended to guarantee the max amount of space that an attribute may allocate; use fixed length data types instead of variable length data types.
To get rid of existing Forwarded Records you have to rebuild your table but keep in mind that a Rebuild will force updates on all non-clustered indexes, too! If you are rebuilding non-clustered indexes, nothing will happen with the pointer to the heap.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments