
The ability to use .NET languages for stored procedures and user-defined functions has been around since SQL Server 2005 was introduced. Even though it has been six years since it became available, there is still much hesitation about using CLR-the .NET Common-Language Runtime-code in SQL Server and if so what the appropriate usages would be. Microsoft sells this feature on the idea that not only will it provide functionality not available in T-SQL but it will also provide a more efficient environment for programmatic logic. There has been some testing which shows that CLR can perform better than T-SQL, but there is still too much room for speculation and conjecture. My goal with this article is to perform more thorough testing via a wide variety of scenarios. This will give a more complete picture of exactly what performance gains CLR code (or SQL CLR, as it is commonly known as) can provide and when T-SQL stored procedures are clearly the better choice.
Before we begin I should mention two things. First, I did not compare stored procedures between T-SQL and CLR. I find few reasons for creating CLR stored procedures over Functions, given how easy it is to interface with both Scalar and Table-Valued Functions (TVFs). The only reasons I can think of to create a CLR stored procedure would be to either modify the state of the database or server, or to return a dynamic result set. Both of these operations are not allowed in functions so stored procedures are necessary if you need to do those things. But for data retrieval and/or manipulation, most of the time T-SQLstored procedures will not only be easier to create and maintain, but it should perform better.
Second, all of the test code is attached to this article in a zip file which you can find at the bottom of the article. There are scripts to: create the CLR Assembly and the T-SQL wrapper functions for the CLR methods; create the test-harness stored procedure; create the example T-SQL Functions and Numbers table; and create two sample data tables used in the set-based tests. If you want to recreate the tests, just run all of the numbered scripts in order. Finally, there are three scripts of tests: one for the single-execution tests, one for the set-based tests, and one for the TVF tests. At the top of each test script there is a comment-block that includes all of the “unit” tests. I have also included the Visual Studio 2008 solution folder with the source code for the CLR functions, but you don’t need to compile or deploy this as everything is contained in the setup SQL scripts.
Methodology
I created a stored procedure to be a test apparatus to facilitate repeatable testing. There are several concerns regarding the testing environment that the “RunTest” stored procedure takes care of:
- Dynamic test code can be passed in.
- There is a SQL_VARIANT variable called @Dummy that all tests store their value into. This allows for both single and set-based operations to execute a function while not returning that data to SQL Server Management Studio (SSMS) because returning the data could cause variances in overall execution times.
- Test code can be executed in a loop for operations that return in less than 1 millisecond.
- Start and end times are taken right before and after the loop so as to reduce any outside factors. Within the loop a counter variable is incremented, but this factor is consistent across all tests and hence its effect is cancelled out if using the resulting times as relative instead of absolute indicators.
- Test code can be run across several sets of loops to gather enough data to produce a meaningful average.
- Cached data pages and execution plans are cleared at the beginning of the stored procedure to eliminate caching between test scenarios.
- Cached data pages and execution plans are not cleared between loops or sets of loops because any real-world environment will have caching for the same piece of code / scenario.
- Several variables can be passed in as parameters so that the tests can easily be run against various values.
- The passed-in variables are then used to set internally declared variables. This allows some variance in how the same function called with different values performs since it bypasses parameter-sniffing and constant-folding (depending on which test is running).
I chose three different types of tests to show the various ways in which functions can be used:
- Scalar functions used in a single-execution manner, such as to set a variable
- Scalar functions used in a set-based approach (i.e. as part of a query)
- Table-valued functions (TVFs)
For the scalar functions, both in single-execution and set-based usages, I only tested for total elapsed time. This was because each test runs in many loops and would have produced too much output for STATISTICS IO or STATISTICS TIME to reasonably deal with. As a control (or maybe just thoroughness) in the experiment I included the inline T-SQL formula for both methods of executing the Scalar Functions. I also included versions of a few of the scalar functions marked as Deterministic for two of the T-SQL functions because that should theoretically improve performance.
For the TVFs I was able to gather several metrics from the sys.dm_db_session_space_usage and sys.dm_exec_sessions Dynamic Management Views (DMVs). Since these DMVs report session level information I had to open up a separate session for each test. Also, the metrics of the DMVs are cumulative so a new session for each function ensured that each metric started at 0.
Lastly, for each set of functions across all three types, I ran the functions in a group, as a unit-test, to ensure that they returned the same output given the same input. This ensures that I was truly testing equivalent code between T-SQL and CLR to make sure that the metrics would be meaningful.
The Tests
The tests were run on a 32-bit instance of SQL Server 2008 (not R2). The machine had 8 processors and 16 GB of RAM.
For each group of tests I will describe the basic algorithm being used and show a chart of the metrics. All times are reported in milliseconds. Notice that in all cases, the maximum (or slowest) time for the CLR version is less than the minimum (or fastest) time for the T-SQL UDF version. In the single-execution and set-based tests, while the inline T-SQL numbers are mostly so much better than both T-SQL or even CLR functions, the main point of the article is to compare T-SQL to CLR functions and the inline T-SQL results are mainly just there for reference and thoroughness. However, there are a few notable exceptions. Finally, in scenarios that include either deterministic or inline T-SQL tests, I only compare the standard T-SQL UDF with the CLR UDF for the “How many times better?” values (except in a few instances where the CLR values are actually better than the inline T-SQL values).
In the results tables for all but the TVF stress tests, I have used the following color-coding:
- The slowest time for the CLR version and the fastest time for the T-SQL version are shown in blue for easy comparison.
- The average times for the CLR tests are in bold, red.
- The inline T-SQL results that beat the CLR results (what is expected) are shaded peach.
- The inline T-SQL results that are slower than the CLR results are shaded blue.
Single-execution test
These are scalar user-defined functions (UDFs) that are used with constants and/or variable values passed in. They are typically used in this case to set a variable.
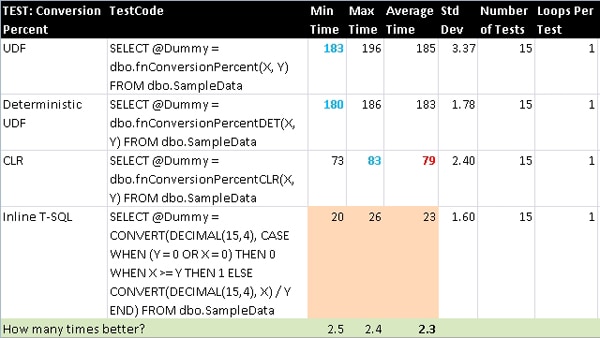
ConversionPercent
This is a simple percent that corrects for divide-by-zero errors and has a ceiling of 1. The T-SQL function was eligible to be marked as deterministic but that did not provide any benefit.
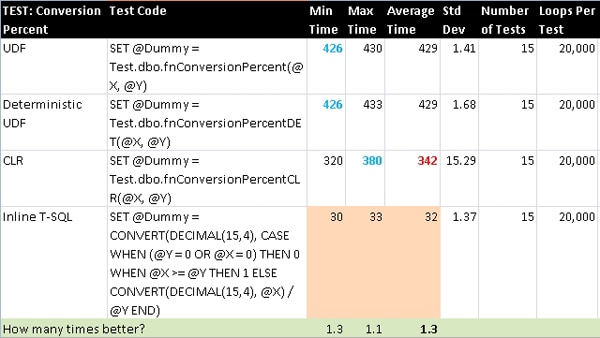
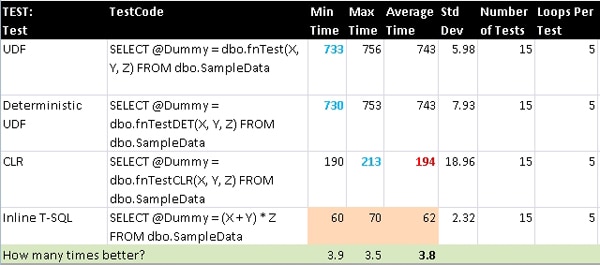
Test
This is a very simplistic formula: one that shows nothing more than a mathematical operation being performed and no other logic or internal function calls. The T-SQL function was eligible to be marked as deterministic and again doing so provided no performance gain.
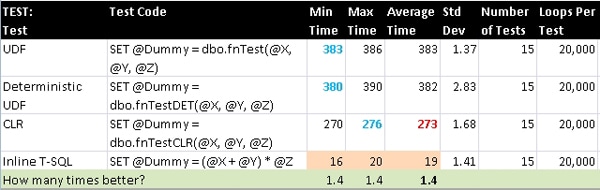
FromJDate
SQL Server has a built-in conversion from INT to DATETIME and vice-versa that equates a Date (no Time component, or just midnight) to the number of days since January 1st, 1900 (which is basically a quasi-Julian date). The T-SQL function is eligible for being marked as deterministic, but seeing as there was no gain in doing that from the previous tests I did not do so for this or the following tests.
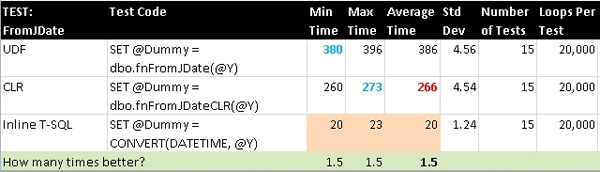
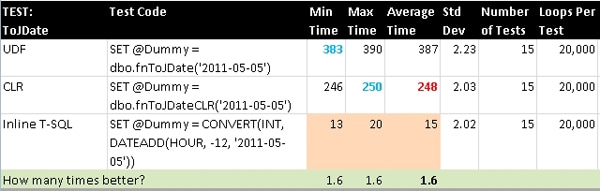
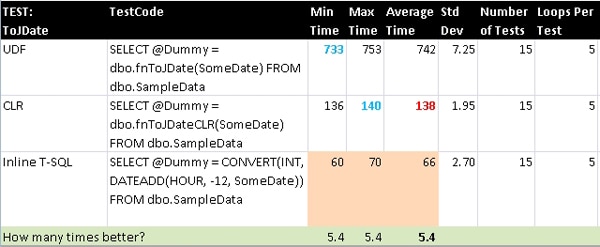
ToJDate
This is the companion computation to the previous conversion, but in the direction of DATETIME to INT. In this case, we need to do a secondary adjustment of setting the time component back 12 hours due to what is most likely a rounding issue with the conversion: all times on a given date starting at noon (1200 hours) will convert to the next higher INT value corresponding to the next calendar day.
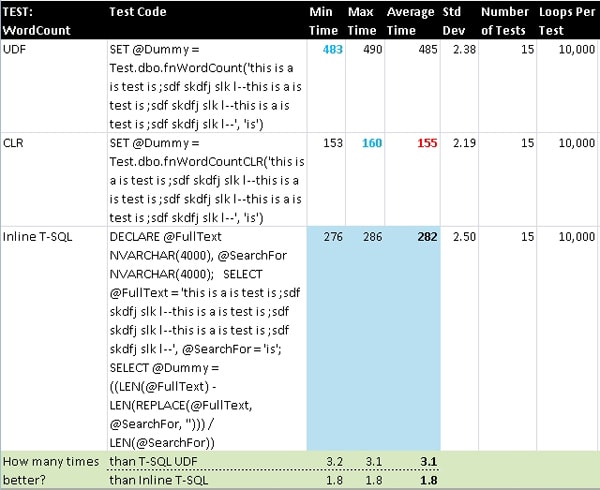
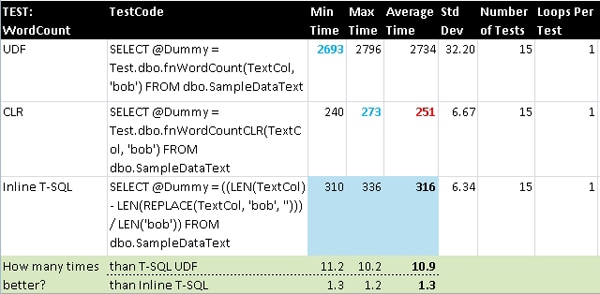
WordCount
This is a basic, non-overlapping word counting function that uses the same algorithm in both T-SQL and C#. It simply replaces all occurrences of the search string in the main string with nothing (i.e. empty string) and then compares the length of the new string with the original and divides by the length of the string to search for. So if 3 sets of a two-character expression are found, the new string will be 6 characters shorter representing those 3 sets. What is most interesting about this test is that the CLR version is actually faster than the inline T-SQL. Because this result is not expected, I ran the test a few times and each time came up with the same performance ratios.
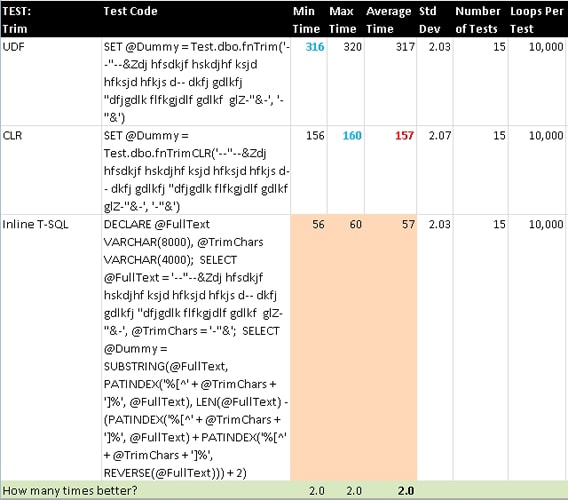
Trim
The most common usage of Trim is to remove whitespace from the beginning and/or end of a string. In .NET languages it handles both sides of a string whereas the TrimEnd and TrimStart methods work on one side only. T-SQL only has LTRIM and RTRIM so it is necessary to use them together in order to trim both sides of a string.
There is an override available in .NET languages that lets you pass in a character array and it will remove all of those characters from both sides of a string until it reaches the first character that is not in the array. This makes it very easy to remove quotes or text-qualifiers from strings when those characters could be anything: a single-quote, double-quote, square-bracket, or something else. While this is built into .NET, I had to do a little more work to emulate it in T-SQL using PATINDEX, SUBSTRING, and REVERSE. In the test code below, I am removing all occurrences of the three characters (-, &, and “) from both sides of the string and they appear differently on each side just to show that it is not matching the exact sequence of those characters.
Set-based tests
These tests are the same scalar UDFs as before, but this time they are used in SELECT statements so they are executed many times with values coming from a table. Since the idea of databases is to work in sets as much as possible, it only makes sense to test functions against sets. The SampleData table has 20,000 rows and the SampleDataText table has 50,000 rows. Since the functions are the same as in the single-execution group, there is no reason to explain the algorithms again in this section.
However, please note the much greater performance difference between the T-SQL and CLR UDFs as compared to the single-execution differences. The advantage of using CLR functions is much clearer in these scenarios, especially with regards to the WordCount and Trim functions.
ConversionPercent
Test
FromJDate
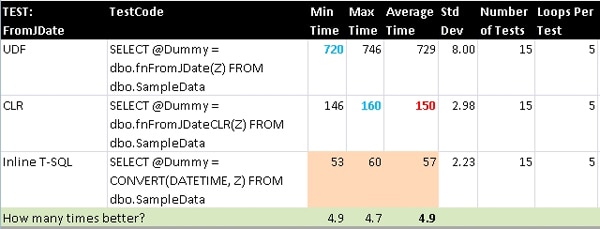
ToJDate
WordCount
Please note that, just as in the single-execution test, the CLR function out-performs even the inline T-SQL.
Trim
Similarly to the previous test for WordCount, but unlike the analogous test for Trim in the single-execution set, the CLR function out-performs the inline T-SQL code. In all cases for the set-based group the performance gain of the CLR is greater than with the single-execution group, but this is the only case where a set-based approach is faster for CLR whereas the same algorithm is faster with inline T-SQL when executed once to set a variable.
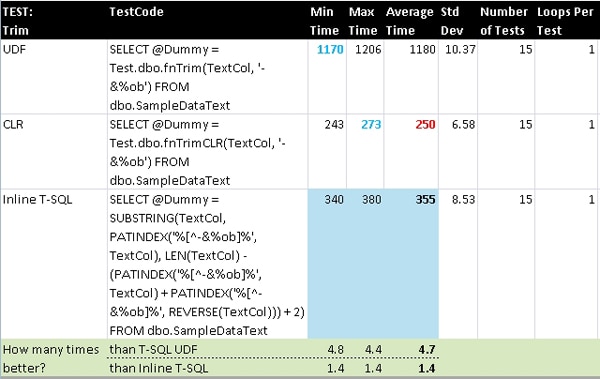
Table-Valued Functions (TVFs)
TVFs are a separate category since, while they are set-based like the previous group, they return a set of data rather than execute many times over a set.. Because of this they have different performance considerations.
For each of the tests some of the values are enclosed in double-quotes so that we can test the Trim function in conjunction with a Split function. I created a Numbers table containing 1 million values and found a simple yet very fast T-SQL-based split function (written by Nathan Oglesby, used with permission). I created both multistatement and inline versions of the T-SQL function to see the difference between those two on their own and because it seems that most functions are multi-statement anyway. I then created a very simple CLR-based split function that took all of a few minutes and a few lines of code.
Some people will claim that it is possible to find a better/faster T-SQL split function. That might be the case but other people have tested the comparison between T-SQL and CLR splitting and came to the same conclusion. Jeff Moden recently published an article on this topic trying to find the fastest possible T-SQL Split function, comparing faster T-SQL and possibly faster CLR functions than used here, and even after he and many others spent many hours on many variations of the code it still did not beat the CLR version and is constrained to a VARCHAR(8000) input string whereas the CLR versions take an NVARCHAR(MAX). Meaning, the purpose here is not to get caught up on the specific example of a Split function but the more general concept of doing TVFs in T-SQL vs CLR.
Normal Use
In this section I started with a CSV – comma-separated value – string that is 10,498 characters long and contains 2017 elements. The idea here is to test a more typical scenario (as compared to the more interesting large-scale tests in the next section). I used the same stored procedure to run the tests as I used in the scalar tests. However, I had to pass in a slightly more complex string as it had to build the CSV string. The images here have a redacted set of the test code as it was too long to manage pasting into a narrow cell. The full test code is available in the zip file attached to this article.
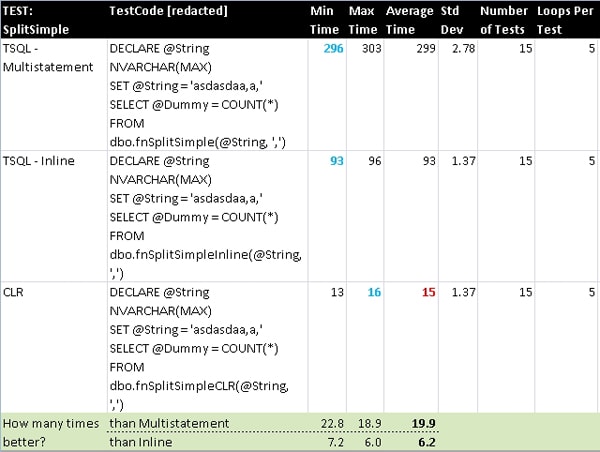
SplitSimple
The simple split function was chosen as it is so commonly used that it would be easy to relate to. Also, it is something that can be done in both T-SQL and .NET which makes for an easy comparison.
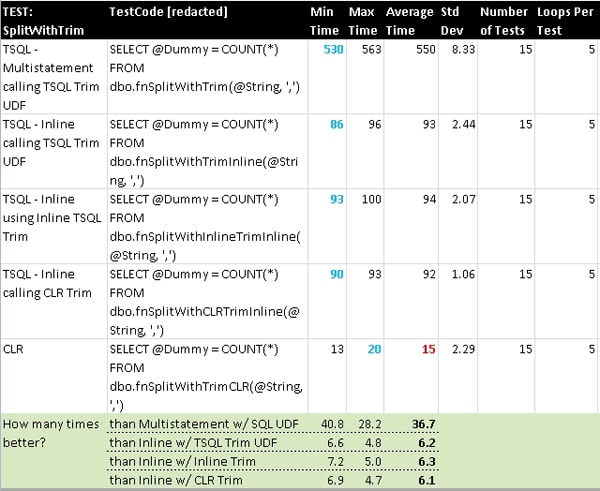
SplitWithTrim
The simple split function is interesting and definitely very common, but its simplicity masks (to a degree) the real magnitude of performance gain of using CLR code. The more complex the algorithm, the larger the performance gain is when using the CLR. To show this I merely combined the previous Trim function with the Split to accomplish a basic de-quoting ability. I chose this because it does have real-world application in that some values within the CSV string might be text-qualified and we might want those text-qualifiers (usually quotes) removed. This represents what is likely the most common scenario for doing a TVF. I created several variations as we have already used three different Trim methods: T-SQL UDF, CLR UDF, and inline T-SQL.
Stress Testing
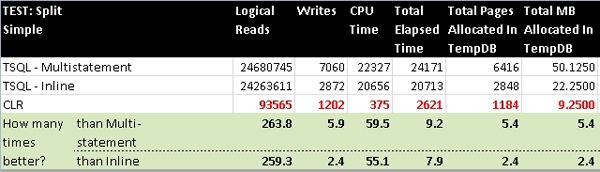
In this section I started with a CSV string that is 955,008 characters long with 183,709 elements. Inline TVFs are not only better performing than multi-statement TVFs, but they also release their data to the calling process as it becomes available. On the other hand, multi-statement TVFs need to store the entire record-set in the table variable created at the top of the function in the RETURNS clause before any of it gets released to the calling process as the function ends (something that is not visually apparent when running smaller-scale tests). This means that the multi-statement version of the Split took 24 seconds to complete and for most of that time no results were returned whereas, with the Inline version, results were returned to SSMS a second or two after starting the process. The true advantage of CLR in this case is that not only does it start returning results immediately (if done properly) but it also completes in a fraction of the time of either T-SQL version and consumes very little tempdb usage (as evidenced by the Total Past MB Allocated in TempDB which shows a lot of I/O for both T-SQL versions).
For this set of tests I did not run them repeatedly as I did before with the test stored procedure. I instead ran them once but in separate sessions so I could get more detailed I/O data. I captured the performance metrics with the following query:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
SELECT tsu.session_id, tsu.internal_objects_alloc_page_count AS [PagesAllocatedInTempDB], tsu.internal_objects_alloc_page_count / 128.0 AS [MBAllocatedInTempDB], (tsu.internal_objects_alloc_page_count - tsu.internal_objects_dealloc_page_count) AS [CurrentPagesInTempDB], (tsu.internal_objects_alloc_page_count - tsu.internal_objects_dealloc_page_count) / 128.0 AS [CurrentMBInTempDB], ssu.internal_objects_alloc_page_count AS [TotalPastPagesAllocatedInTempDB], ssu.internal_objects_alloc_page_count / 128.0 AS [TotalPastMBAllocatedInTempDB], es.[status], es.cpu_time, es.total_scheduled_time, es.total_elapsed_time, es.reads, es.writes, es.logical_reads, es.row_count FROM sys.dm_db_task_space_usage tsu INNER JOIN sys.dm_db_session_space_usage ssu ON ssu.session_id = tsu.session_id INNER JOIN sys.dm_exec_sessions es ON es.session_id = tsu.session_id WHERE tsu.session_id IN (x, y, z) -- fill out with SPIDs |
With the smaller dataset in the normal usage tests, the performance gain of the CLR code was the same between the simple Split and Split with the Trim function added when compared to the inline versions. But with the much larger input string in the next two tests the CLR performance gains are even more pronounced.
In the results tables for the following two tests, I have used the following color-coding:
- All CLR metrics are in bold, red.
- The unexpected / anomalous ratios for the inline split using inline trim are shaded blue.
SplitSimple
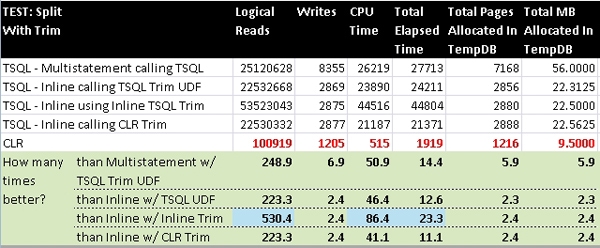
SplitWithTrim
In this test, you’ll notice that the inline Split TVF which uses the inline Trim algorithm actually performs much worse than either of the other two inline TVF Split functions which call either the T-SQL Trim UDF or the CLR Trim UDF. I ran this test several times to make sure it was not an anomaly and the result was always the same. At first glance this is both curious and interesting. Not only would we expect inline T-SQL to be faster, but in the normal usage test with a much smaller string this method was just barely worse than the other two methods calling the Trim UDFs. If we look back at the set-based tests, the inline version was slower than the CLR version but it was still faster than the T-SQL UDF, which is not the case here.
Conclusion
As you can see, in all cases the CLR approach is faster than T-SQL UDFs and TVFs (to varying degrees). Set-based uses of scalar UDFs offer even more pronounced improvements over single-execution uses. And TVFs are even more efficient still. The more complicated the operation the larger the performance gain of using CLR.
Of course, given that it took 20,000 executions of several of the functions to register even 300 milliseconds of total time it should be safe to say that the benefits of using CLR (at least in terms of duplicating functionality that can be done in T-SQL) are mainly realized as data volume and/or execution frequency increase to a sufficiently large scale. This means that for the minute performance gains you get when working on 100 rows or with a system that has a few transactions per-second, it might not be worth encapsulating the logic within a .NET assembly. However, when dealing with millions of rows and/or thousands of transactions per second, the performance gains most definitely would make it worth moving that logic over to a SQLCLR assembly. And while I did not track this particular metric in my research shown above (outside of the TVF section), when running the functions individually with SET STATISTICS TIME ON it was also clear that the CPU usage of CLR functions was lower than the T-SQL functions which is yet another gain for the system as it frees up more CPU to be used by other processes.
Finally, keep in mind that CLR is not always the best choice. When a computation can be done with inline T-SQL then it typically seems to perform better than even the fastest CLR code, especially for single executions. But sometimes you have a particular computation or expression in many different places (stored procedures, functions, triggers, views, etc.) and you have to weigh the cost of long-term maintenance with the performance hit of moving that code to a single function. In these cases you can most likely minimize that performance hit by using CLR instead of a straight T-SQL UDF. And you always have the option of using CLR code for an algorithm that appears in 100 or more other pieces of code but yet use inline T-SQL in the few places where performance is of critical concern.
Given the few instances where the CLR code ran faster than the inline T-SQL code it should be clear that there is no hard and fast rule about what is the best or fastest way to accomplish something. What is clear is the need for proper testing as each situation has its own characteristics that might alter the outcome so that it does not fit with the conventional wisdom. However, it should now be clear that CLR code is a powerful tool not just to provide functionality not possible with the built-in T-SQL functions, but also to assist greatly in scalability.
Load comments