
In some cases we don’t update our data – we add a new version of it, and we have to keep the previous one as well. This is a well-known practice, particularly in financial systems. Although this helps maintain a good audit trail, it complicates the SQL Code for the selection of a version of the data at a particular point in time, and even just for fetching the latest version of the data. Recently, Grant Fritchey described and benchmarked several typical queries used to do this, in the article SQL Strategies for Versioned data.
I would like to describe one more approach that really shines when we are most concerned with getting the best-possible performance when selecting the latest version, even at the cost of the performance of modifications to the data and other selects.
If you haven’t read Grant’s article yet, I encourage you to read it now, before proceeding to read the rest of this article.
Adding a Column to Explicitly Indicate the Latest Versions Allows for Much Better Performance
Suppose that we store data about employees. Also, let’s assume that the date they were hired is not supposed to change, unless it was entered incorrectly. However, their name and location can change, and we need to keep the old versions. The following tables store all the required data, as well as a column named IsLastVersion, which will be explained later:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
CREATE TABLE Employees( EmployeeID INT NOT NULL PRIMARY KEY, HiredAt DATE NOT NULL, OtherData CHAR(50) ); GO CREATE TABLE EmployeeCurrentData( EmployeeID INT NOT NULL, VersionNumber INT NOT NULL, LocationId INT NOT NULL, Name VARCHAR(50) NOT NULL, IsLastVersion CHAR(1) NOT NULL, CONSTRAINT PK_EmployeeCurrentData PRIMARY KEY (EmployeeID, VersionNumber) ); GO |
Note: I have also provided a script that populates these tables with test data. To download the script, click on the bubble above the article.
We’ve already mentioned that we’ve determined that our highest priority will be in selecting the latest versions. To speed up the selection process as much as possible, we have added a column named IsLastVersion. We shall use this new column to create two database objects that store only the latest versions: an indexed view and/or a filtered index, depending on the queries we are going to optimize. If we only retrieve LocationId and Name from EmployeeCurrentData table, and we do not need any columns from Employees table, then we shall be using the following filtered index:
|
1 2 3 4 |
CREATE UNIQUE NONCLUSTERED INDEX EmployeeCurrentData_LastVersions ON dbo.EmployeeCurrentData(EmployeeID) INCLUDE(LocationId, Name) WHERE IsLastVersion = 'Y'; |
If we do need columns from Employees table, such as HiredAt, than we need to create an indexed view:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
CREATE VIEW dbo.EmployeesWithCurrentDetails WITH SCHEMABINDING AS SELECT e.EmployeeID , e.HiredAt , c.LocationId , c.Name FROM dbo.Employees AS e JOIN dbo.EmployeeCurrentData AS c ON e.EmployeeID = c.EmployeeID WHERE c.IsLastVersion = 'Y'; GO CREATE UNIQUE CLUSTERED INDEX EmployeesWithCurrentDetails_CI ON EmployeesWithCurrentDetails(EmployeeID); |
These two new objects, the indexed view and the filtered index, allow for much faster queries, as compared to the ones described in Grant’s article – but only if we explicitly use the condition IsLastVersion=’Y‘ in our queries. We shall benchmark and see that for ourselves.
Verifying the Performance Advantages
Before we begin our benchmarking, let us clearly state an assumption: we expect a lot of versions for every employee. Should we have, for example, just one or two versions for most employees, we might (or might not) get different results. Let us suppose, however, that in our system we are expecting many versions per employee. Our test data has been created using this assumption.
Suppose that we only need the latest versions of Name and LocationId. If we use IsLastVersion column in our query, it uses our filtered index and is very fast. Let us run it, as well as the equivalent query not using IsLastVersion:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
SELECT EmployeeID , LocationId , Name FROM dbo.EmployeeDetials WHERE IsLastVersion = 'Y'; GO SELECT d.EmployeeID , d.LocationId , d.Name FROM dbo.Employees AS e CROSS APPLY ( SELECT TOP ( 1 ) c.EmployeeID , c.LocationId , c.Name FROM dbo.EmployeeDetails AS c WHERE c.EmployeeID = e.EmployeeID ORDER BY c.EmployeeID DESC, c.VersionNumber DESC ) AS d; |
The first thing that we can notice immediately is that the first query has a much simpler plan - all the data it needs is stored in our filtered index. The execution plan is so simple that there is no need to show it here.
The second query acceses two tables, joined with nested loops, which should use up somewhat more CPU, and should need substantially more reads:
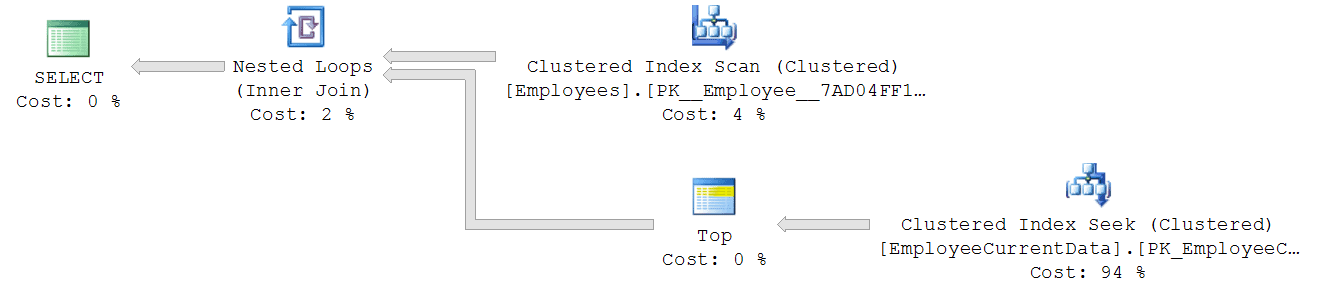
When we actually run both queries, we see that the first one is requiring fewer reads and using less CPU. However, both queries run for almost the same time on my laptop, as shown in the following table (naturally your mileage may vary):
Query that uses IsLastVersion
Query that does not use IsLastVersion
Duration
Appr. 1400 ms
Appr. 1400 ms
Reads
349
319209
CPU
78 ms
531 ms
These results may look a little bit confusing: how is it possible that the first query uses 6.8 times less CPU, does 914 times less reads, yet it runs for almost the same time as the second one?
The reason is simple: in both cases most of the time is spent transferring 100K rows and rendering the result set in SSMS. This is easy to demonsrate. Let us materialize the results in a table, and just select all the data from that table, as follows:
|
1 2 3 4 5 6 7 8 9 10 11 |
SELECT EmployeeID , LocationId , Name INTO dbo.TempResults FROM dbo.EmployeeDetails WHERE IsLastVersion = 'Y' ; SELECT EmployeeID , LocationId , Name FROM dbo.TempResults ; |
As expected, we are getting the same duration: this last query is as simple as it goes, and it runs for approximately 1400 ms, just like the previous two ones.
Let us change our benchmarking just a little bit: instead of comparing the performance of a executing a query, transferring 100K rows, and rendering them on the client, let us filter out most of the rows, so that only a small result set is sent over and displayed. Clearly we want this filtering to be non-intrusive: it should not change the execution plans, and it should not use too much CPU. For these purposes I have added the following condition to both queries:
|
1 |
LocationId*0.99 BETWEEN 108.89 AND 108.91 |
This numeric comparison is a very cheap; it does not use much CPU. Also it is not index-friendly, so we are still getting the same execution plans for both queries. The modified queries are as follows:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
SELECT EmployeeID , LocationId , Name FROM dbo.EmployeeDetails WHERE IsLastVersion = 'Y' AND LocationId*0.99 BETWEEN 108.89 AND 108.91 ; SELECT d.EmployeeID , d.LocationId , d.Name FROM dbo.Employees AS e CROSS APPLY ( SELECT TOP ( 1 ) d.EmployeeID , d.LocationId , d.Name FROM dbo.EmployeeDetails AS d WHERE d.EmployeeID = e.EmployeeID ORDER BY VersionNumber DESC ) AS d WHERE LocationId*0.99 BETWEEN 108.89 AND 108.91 ; |
Both queries with this additional condition return only one row, the cost of transferring and displaying one row is small as compared to the cost of running queries, and the duration now reflects the difference in queries' performance just as well as CPU and reads do:
Query that uses IsLastVersion
Query that does not use IsLastVersion
Duration
40 ms
372 ms
Reads
349
319209
CPU
47 ms
656 ms
Note: although the second query used 656 ms, it used a parallel plan and as such completed in only 372 ms - these 656 ms were spread over two processors.
Now we'll benchmark the query that involves having to retrieve columns from both the Employee and EmployeeDetails tables. For this case we have already created an indexed view which uses IsLastVersion. As before, we shall add the same filtering to exclude from our comparison the costs of sending and rendering a large result set.
The following two queries retrieve the same results, the same one row. The first one uses IsLastVersion, the second one does not:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
SELECT c.EmployeeID , c.LocationId , c.Name , e.HiredAt FROM dbo.Employees AS e JOIN dbo.EmployeeDetails AS c ON e.EmployeeID = c.EmployeeID WHERE c.IsLastVersion = 'Y' AND c.LocationId*0.99 BETWEEN 108.89 AND 108.91 ; GO SELECT d.EmployeeID , d.LocationId , d.Name , e.HiredAt FROM dbo.Employees AS e CROSS APPLY ( SELECT TOP ( 1 ) c.EmployeeID , c.LocationId , c.Name FROM dbo.EmployeeDetails AS c WHERE c.EmployeeID = e.EmployeeID ORDER BY c.EmployeeID DESC, c.VersionNumber DESC ) AS d WHERE d.LocationId*0.99 BETWEEN 108.89 AND 108.91 ; |
To satisfy the first query, the database engine simply scans our indexed view. The second query gets a nested-loopish execution plan, just as in the previous case.
The performance advantages of using IsLastVersion, both in reads and in CPU, are just as impressive as in the previous case:
Query that uses IsLastVersion
Query that does not use IsLastVersion
Reads
411
320033
CPU/Duration
15 ms/77ms
484 ms/261 ms
As in the previous case, the duration of the second query is less than the amount CPU it used because the second query runs in parallel.
As we have seen, using IsLastVersion column allows for much better performance. However, can we guarantee that it always stores correct values? In most cases we choose slower queries which always return correct values over faster queries that can sometimes return wrong results. So, we have to ensure the complete correctness of all the values in IsLastVersion column.
Enforcing the Integrity of the IsLastVersion Column
In this section we shall enforce the following data integrity rules:
For every row in Employee table that has any corresponding rows in EmployeeDetails table, there is exactly one row in EmployeeDetails table with IsLastVersion='Y' Every row in EmployeeDetails table with IsLastVersion='Y' has the biggest VersionNumber for that employee
Our filtered index, EmployeeDetails_CurrentVersions, already guarantees that there is at most one last version per employee. The following script completes the implementation of these two data integrity rules:
|
1 2 3 4 5 6 7 8 |
ALTER TABLE dbo.EmployeeCurrentData ADD NextVersionNumber AS CASE WHEN IsLastVersion = 'Y' THEN NULL ELSE VersionNumber + 1 END PERSISTED; GO ALTER TABLE dbo.EmployeeCurrentData ADD CONSTRAINT FK_EmployeeCurrentData_NextVersionNumber FOREIGN KEY(EmployeeID, NextVersionNumber) REFERENCES dbo.EmployeeCurrentData(EmployeeID, VersionNumber); |
Essentially this constraint means that if a version is not marked as the last, then it must refer to a next version, with the next value of VersionNumber. This means that we can only insert a row with the largest version number if and only if it is marked as IsLastVersion='Y'.
As long as these constraints are trusted, we can safely use IsLastVersion='Y' in our queries, and benefit from much faster queries.
Note: as a side effect of this foreign key constraint, we cannot have gaps in version numbers. For example, if we have versions 2 and 4, than we must have version 3 as well. Typically this is a very good thing - it enforces data integrity. The existing solution does not guarantee that we have version number 1, but this is only because the emphasis of this article is on performance, and for best performance we only require that the last version is marked as such. For better data integrity, the existing solution can be easily tweaked to also enforce the rule that version number 1 always exists. I'll leave this as an advanced exercise.
Naturally, when we insert a new latest version, we have to unmark the current latest version, settting it to IsLastVersion='N', because we cannot have more than one latest version per employee. We have to both modify the previous latest version, and insert the new row in the same statement, otherwise we shall have a constraint violation. The following MERGE command shows how to do it:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
MERGE INTO dbo.EmployeeCurrentData AS TargetTable USING ( SELECT TOP ( 2 ) EmployeeID , VersionNumber + [Offsets].offset AS VersionNumber , 'New Name' AS NAME , 110 AS locationID FROM dbo.EmployeeCurrentData CROSS JOIN ( SELECT 0 AS offset UNION ALL SELECT 1 ) AS [Offsets] WHERE EmployeeID = 1 ORDER BY VersionNumber DESC ) AS NewValues ON ( TargetTable.EmployeeID = NewValues.EmployeeID AND TargetTable.VersionNumber = NewValues.VersionNumber ) WHEN MATCHED THEN UPDATE SET IsLastVersion = 'N' WHEN NOT MATCHED THEN INSERT ( EmployeeID , VersionNumber , LocationId , Name , IsLastVersion ) VALUES ( NewValues.EmployeeID , NewValues.VersionNumber , NewValues.LocationId , NewValues.Name , 'Y' ); |
This MERGE command in its current form will only work if we already have at least one version added before. However, it is very easy to change it, so that it can add the very first version as well. I'll leave you to figure out how to do this!
Conclusion
If we add a pre-calculated column IsLastVersion, we can benefit from much faster selecting of the latest version, but we have to pay a price for it: slower and more complex modifications. In some cases this price is too high.
Let me reuse the argument from my previous article, "Tuning SQL queries with the help of constraints" (http://www.simple-talk.com/sql/t-sql-programming/tuning-sql-queries-with-the-help-of-constraints/).
If we need high quality video and fast playback, we invest in burning a DVD. If we need acceptable quality video, and we need a cheap solution, then a webcam is a better choice.
The approach described in this article is not the right one for all circumstances: It only recommended for those cases where our highest priority is both the performance of selecting the latest version and the quality of results.
I would like to thank Plamen Ratchev, Phil Factor and Grant Fritchey for reviewing this article.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments