
Columnstore index architecture in SQL Server is built on three core structures: rowgroups (batches of ~1 million rows), segments (compressed column data within each rowgroup), and the deltastore (a B-tree staging area for incoming rows that haven’t yet been compressed into the columnstore). Understanding how data flows through these structures – from delta rowgroups through the tuple mover into compressed segments – is essential for designing efficient columnstore indexes.
This article uses a 23-million-row test table to demonstrate how compression works, how segment metadata enables query optimization, and how the deltastore handles insert operations before data is moved into the main columnstore structure.
The series so far:
- Hands-On with Columnstore Indexes: Part 1 Architecture
- Hands-On with Columnstore Indexes: Part 2 Best Practices and Guidelines
- Hands-On with Columnstore Indexes: Part 3 Maintenance and Additional Options
- Hands-On with Columnstore Indexes: Part 4 Query Patterns
Indexes are the key to efficient performance in any relational database. Few index enhancements have been introduced that can improve query speed and efficiency as dramatically as columnstore indexes.
Improvements to this feature have been introduced in each subsequent version of SQL Server and have transformed columnstore indexes into the go-to method of indexing OLAP workloads.
In this article, we will review the basics of columnstore indexes. In later articles, we will dive into best practices, and explore more advanced indexing considerations. I have personally had the pleasure of using columnstore indexes in a variety of applications, from small analytics tables to massive repositories and look forward to sharing my experiences (the good, the bad, and the silly).
As this article progresses through a discussion of columnstore indexes, the information presented will become more specific. Initially, an overview and generalized benefits will be discussed, followed by basic architecture and then increasingly more detail that builds upon previous ideas.
Test Data
Before diving into columnstore indexes, it is helpful to create a large table, index it, and use it throughout this article. Having a demo available in each section will aid in explaining how these indexes work and why they are so blazingly fast. It’ll also allow us to illustrate best practices and how not to use them. The WorldWideImportersDW sample database will be used for generating schema and data sets for us to work with.
The following T-SQL will create and populate a table with enough rows to illustrate columnstore index function effectively:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 |
CREATE TABLE dbo.fact_order_BIG_CCI ( [Order Key] [bigint] NOT NULL, [City Key] [int] NOT NULL, [Customer Key] [int] NOT NULL, [Stock Item Key] [int] NOT NULL, [Order Date Key] [date] NOT NULL, [Picked Date Key] [date] NULL, [Salesperson Key] [int] NOT NULL, [Picker Key] [int] NULL, [WWI Order ID] [int] NOT NULL, [WWI Backorder ID] [int] NULL, [Description] [nvarchar](100) NOT NULL, [Package] [nvarchar](50) NOT NULL, [Quantity] [int] NOT NULL, [Unit Price] [decimal](18, 2) NOT NULL, [Tax Rate] [decimal](18, 3) NOT NULL, [Total Excluding Tax] [decimal](18, 2) NOT NULL, [Tax Amount] [decimal](18, 2) NOT NULL, [Total Including Tax] [decimal](18, 2) NOT NULL, [Lineage Key] [int] NOT NULL); INSERT INTO dbo.fact_order_BIG_CCI SELECT [Order Key] + (250000 * ([Day Number] + ([Calendar Month Number] * 31))) AS [Order Key] ,[City Key] ,[Customer Key] ,[Stock Item Key] ,[Order Date Key] ,[Picked Date Key] ,[Salesperson Key] ,[Picker Key] ,[WWI Order ID] ,[WWI Backorder ID] ,[Description] ,[Package] ,[Quantity] ,[Unit Price] ,[Tax Rate] ,[Total Excluding Tax] ,[Tax Amount] ,[Total Including Tax] ,[Lineage Key] FROM Fact.[Order] CROSS JOIN Dimension.Date WHERE Date.Date <= '2013-04-10' CREATE CLUSTERED COLUMNSTORE INDEX CCI_fact_order_BIG_CCI ON dbo.fact_order_BIG_CCI WITH (MAXDOP = 1); |
The resulting table, dbo.fact_order_BIG_CCI, contains 23,141,200 rows, which provides enough data to experiment on and demo the performance of columnstore indexes. For most analytic workloads, the clustered columnstore index is all that is needed, but there can be value in adding non-clustered rowstore indexes to satisfy specific OLTP querying needs. These are typically added on a case-by-case basis as they will add additional storage, memory, and processing footprints to the table.
Read also: Temporary tables for staging columnstore test data
To provide some side-by-side comparisons, the following T-SQL will create an additional test table that utilizes a classic BIGINT identity-based clustered index. An additional non-clustered index is created on [Order Date Key] to facilitate searches by date.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 |
CREATE TABLE dbo.fact_order_BIG ( [Order Key] [bigint] NOT NULL CONSTRAINT PK_fact_order_BIG PRIMARY KEY CLUSTERED, [City Key] [int] NOT NULL, [Customer Key] [int] NOT NULL, [Stock Item Key] [int] NOT NULL, [Order Date Key] [date] NOT NULL, [Picked Date Key] [date] NULL, [Salesperson Key] [int] NOT NULL, [Picker Key] [int] NULL, [WWI Order ID] [int] NOT NULL, [WWI Backorder ID] [int] NULL, [Description] [nvarchar](100) NOT NULL, [Package] [nvarchar](50) NOT NULL, [Quantity] [int] NOT NULL, [Unit Price] [decimal](18, 2) NOT NULL, [Tax Rate] [decimal](18, 3) NOT NULL, [Total Excluding Tax] [decimal](18, 2) NOT NULL, [Tax Amount] [decimal](18, 2) NOT NULL, [Total Including Tax] [decimal](18, 2) NOT NULL, [Lineage Key] [int] NOT NULL); INSERT INTO dbo.fact_order_BIG SELECT [Order Key] + (250000 * ([Day Number] + ([Calendar Month Number] * 31))) AS [Order Key] ,[City Key] ,[Customer Key] ,[Stock Item Key] ,[Order Date Key] ,[Picked Date Key] ,[Salesperson Key] ,[Picker Key] ,[WWI Order ID] ,[WWI Backorder ID] ,[Description] ,[Package] ,[Quantity] ,[Unit Price] ,[Tax Rate] ,[Total Excluding Tax] ,[Tax Amount] ,[Total Including Tax] ,[Lineage Key] FROM Fact.[Order] CROSS JOIN Dimension.Date WHERE Date.Date <= '2013-04-10'; CREATE NONCLUSTERED INDEX IX_fact_order_BIG ON dbo.fact_order_BIG ([order date key]); |
Columnstore Indexes: An Overview
Columnstore indexes take much of what we know about data storage and querying in SQL Server and turn it on its head. Many of the conventions we are used to following with regards to developing T-SQL, contention, and optimization do not apply here.
It is important to note that columnstore indexes are built for tables that are very large. If a table will not contain millions or billions of rows, then it will not fully benefit from it. In general, the larger a table, the more the columnstore index will speed it up.
Columnstore indexes are designed to support analytics in SQL Server. Prior to this feature, tables with billions of rows were cumbersome and challenging to query with adequate speed and efficiency. We were often forced to pre-crunch many fact tables up-front to answer the questions we might ask later. This process drove business intelligence in SQL Server for years. It also drove many analysts out of SQL Server and into SQL Server Analysis Services or a variety of 3rd party tools.
Read also:
What Are Columnstore Indexes? (introduction)
As data grew exponentially, there was a strong desire to be able to maintain detailed fact data that can be targeted directly with reports and analytics. Columnstore indexes can provide speed boosts of 10x-100x or more for typical OLAP queries. This analysis will start with clustered columnstore indexes, as they offer the most significant boost to performance for OLAP workloads. Here are the reasons why such impressive speeds can be attained:
Compression
By storing data grouped by columns, like values can be grouped together and therefore compress very effectively. This compression will often reduce the size of a table by 10x and offers significant improvements over standard SQL Server compression.
For example, if a table with a billion rows has an ID lookup column that has 100 distinct values, then on average each value will be repeated 10 million times. Compressing sequences of the same value is easy and results in a tiny storage footprint.
Just like standard compression, when columnstore data is read into memory, it remains compressed. It is not decompressed until runtime when needed. As a result, less memory is used when processing analytic queries. This allows more data to fit in memory at one time, and the more operations that can be performed in memory, the faster queries can execute.
Compression is the #1 reason why columnstore indexes are fast. The tiny storage and memory footprint allow massive amounts of data to be read and retained in memory for analytics. Consider the size of the table that we created above:
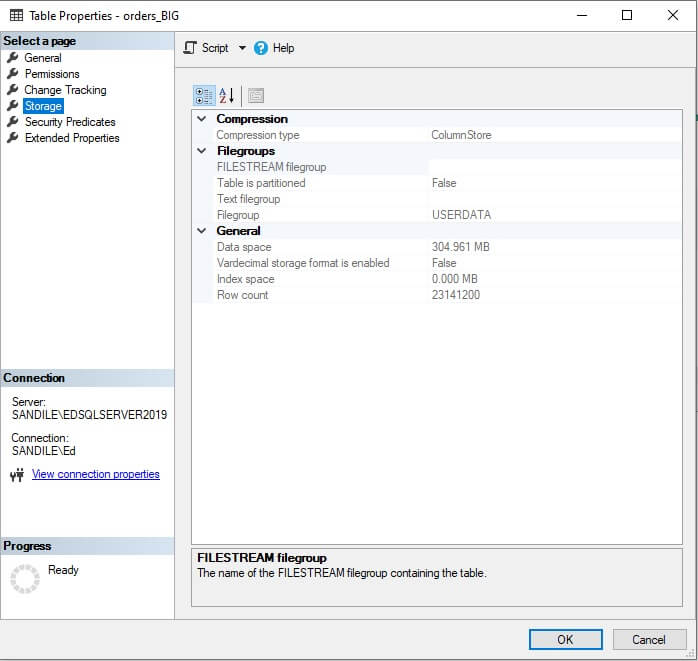
305MB for 23 million rows is quite impressive! Fact.Order contains 1/100 of the data, but consumes 55MB:
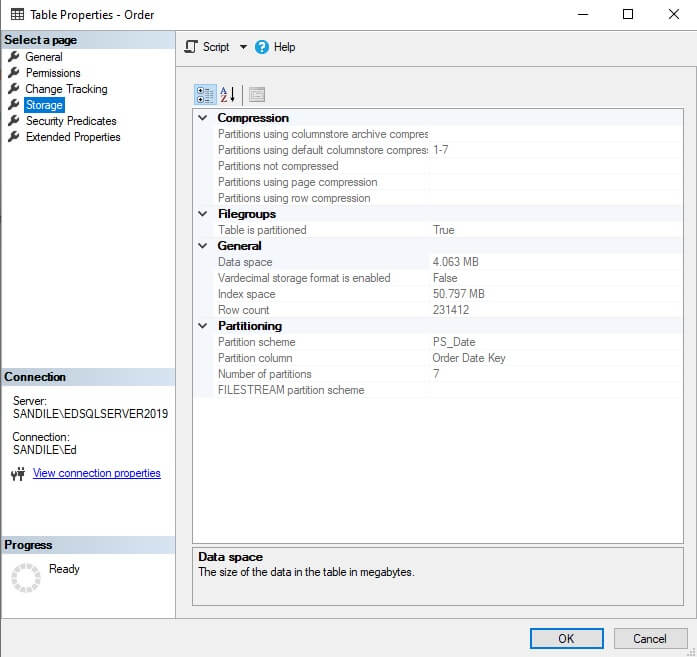
Multiplying by 100 and dividing by the columnstore index size, we can approximate a compression ratio of 18-to-1. This is partly due to the effective compression achieved by columnstore indexes, but also because there is little to no need for additional covering non-clustered indexes.
Inline Metadata
As part of compression, metadata is collected about the underlying data. This allows metrics such as row counts, minimum values, maximum values, and data size to be stored inline with the compressed data. The result is the ability to generate aggregate metrics very quickly as there is no need to scan the detail data to generate these calculations.
For example, the simplest calculation of COUNT(*) in an OLTP table requires a clustered index scan, even though no column data is being returned. The following query returns a count from our new table:
|
1 2 3 |
SELECT COUNT(*) FROM dbo.fact_order_BIG_CCI; |
It runs exceptionally fast, requiring only 116 logical reads. Note the details of the execution plan:
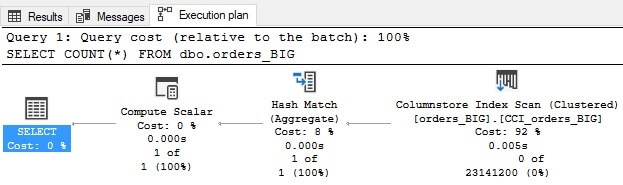
Traditionally, we have been trained to recoil at the thought of clustered index scans, but with columnstore indexes, this will typically be the operator that is used. For compressed OLAP data, scanning a large range of data is expected and normal. The index is optimized for this behavior and is no more afraid of large numbers than we should be 😊
Taking a look at STATISTICS IO, we can verify that the new index uses very little IO:
Table ‘fact_order_BIG_CCI’. Scan count 1, logical reads 0, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 116, lob physical reads 1, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
Table ‘fact_order_BIG_CCI’. Segment reads 23, segment skipped 0.
SQL Server can satisfy the count using metadata from the index, rather than needing to count each and every row in the index. The following is IO on the OLTP variant of the table:
Table ‘fact_order_BIG’. Scan count 5, logical reads 49229, physical reads 1, page server reads 0, read-ahead reads 48746, page server read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
49229 reads vs. 116 is a massive difference. More advanced queries and concepts will be introduced later. In general, expect aggregate queries that operate over a large set of rows to perform far more efficiently with a columnstore index.
Batch Execution
When columnstore indexes were introduced, Microsoft also debuted batch mode processing. This is a method of executing a query where rows are processed in groups, rather than row-by-row in a single thread. Prior to SQL Server 2016, this required the server’s maximum degree of parallelism to be set to a value other than 1 and for the query to use parallel processing and therefore take advantage of batch mode. Starting in SQL Server 2016, SQL Server added the ability for batch mode to operate as a serial process, processing batches of rows utilizing a single CPU rather than many. Parallelism can still be applied to a query, but it is no longer a requirement for batch mode to be used.
The resulting performance will be greatly improved as SQL Server can read batches of data into memory without the need to pass control back and forth between operators in the execution plan. Whether batch mode is used or not can be verified by checking the properties for any execution plan operator:
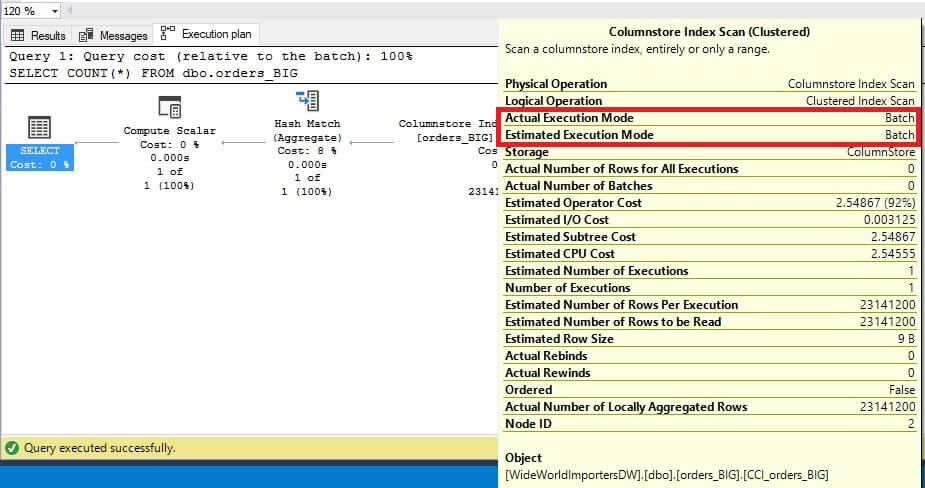
For any analytics query across a large volume of data, expect batch mode to be used. The query optimizer will typically choose batch or row mode correctly given the:
- Table schema
- Query structure
- Server settings
If a query against a columnstore index is preforming poorly and row mode is being used, then investigation is warranted to determine the cause. Perhaps not enough CPUs were available or the maximum degree of parallelism was set to 1 (prior to SQL Server 2016). Otherwise, check the database’s compatibility level to ensure it is set high enough to take advantage of the batch mode features available in the server’s SQL Server version.
Bulk Loading
To facilitate speedy loading of large volumes of data into a columnstore index, SQL Server will use a bulk load process to populate rowgroups whenever possible. This allows data to be moved directly into the columnstore index via a minimally logged process.
For a reporting database, this is ideal as logging every row inserted is time-consuming and likely unnecessary in an OLAP environment. There is no need to specify a bulk load process when loading data into a columnstore index.
Columnstore Index Architecture
Physically, data is stored in rowgroups, which consist of up to 1,048,576 (220) rows. Each rowgroup is subdivided into column segments, one per column in the table. The column segments are then compressed and stored on pages. The resulting structure can be visualized like this:
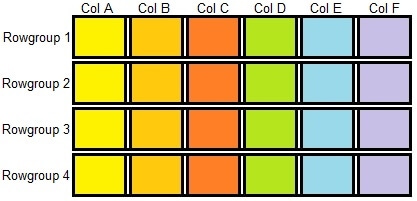
Each segment contains metadata about the data contained within, allowing many aggregate operations to be performed without reading a million distinct values. If a segment or set of segments contain no values that satisfy a query, then it can be skipped. The process of skipping unneeded rowgroups is called rowgroup elimination, and is one of two important ways that columnstore indexes are architected to reduce the amount of data that needs to be scanned to satisfy a query.
Because columnstore indexes separate each column into its own compressed structure, any columns not needed for a query can be ignored. The process of skipping unneeded columns is called segment elimination and allows large portions of a table to be ignored when only a few columns are needed.
Rowgroup structures can be viewed using the dynamic management view sys.column_store_row_groups:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
SELECT tables.name AS table_name, indexes.name AS index_name, partitions.partition_number, column_store_row_groups.row_group_id, column_store_row_groups.state_description, column_store_row_groups.total_rows, column_store_row_groups.size_in_bytes FROM sys.column_store_row_groups INNER JOIN sys.indexes ON indexes.index_id = column_store_row_groups.index_id AND indexes.object_id = column_store_row_groups.object_id INNER JOIN sys.tables ON tables.object_id = indexes.object_id INNER JOIN sys.partitions ON partitions.partition_number = column_store_row_groups.partition_number AND partitions.index_id = indexes.index_id AND partitions.object_id = tables.object_id WHERE tables.name = 'fact_order_BIG_CCI' ORDER BY tables.object_id, indexes.index_id, column_store_row_groups.row_group_id; |
Joining this new view to some additional system views provides a simple result set that tells us about columnstore index rowgroups:
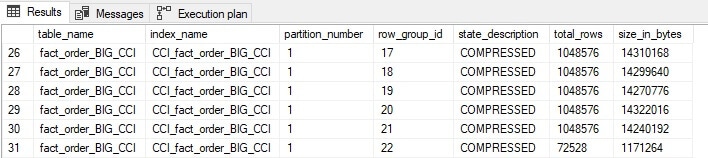
There are a total of 23 row groups within this columnstore index, of which the above image shows the last six. Note that all but the final rowgroup contain the maximum allowed number of rows that can be inserted into a rowgroup. This is optimal and exactly what we want when building a columnstore index. This optimization will be discussed in further detail when index write operations are delved into later in this article.
Similarly, we can view metadata about segments within each rowgroup using another dynamic management view: sys.column_store_segments.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
SELECT tables.name AS table_name, indexes.name AS index_name, columns.name AS column_name, partitions.partition_number, column_store_segments.segment_id, column_store_segments.row_count, column_store_segments.has_nulls, column_store_segments.on_disk_size FROM sys.column_store_segments INNER JOIN sys.partitions ON column_store_segments.hobt_id = partitions.hobt_id INNER JOIN sys.indexes ON indexes.index_id = partitions.index_id AND indexes.object_id = partitions.object_id INNER JOIN sys.tables ON tables.object_id = indexes.object_id INNER JOIN sys.columns ON tables.object_id = columns.object_id AND column_store_segments.column_id = columns.column_id WHERE tables.name = 'fact_order_BIG_CCI' |
This query returns a row per segment, allowing you to analyze the contents of a columnstore index for each column. This can help determine which columns compress most (or least) effectively, as well as keep track of the size and structure of a columnstore index on a more granular scale:
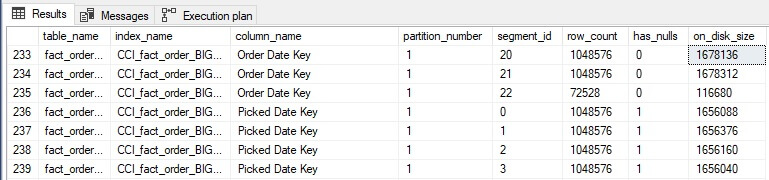
The Deltastore
Writing to a highly compressed object is an expensive operation. Because of this, SQL Server contains a separate structure for managing some of the changes to the columnstore index: The deltastore. This adds another component to the previously presented image of a columnstore index:
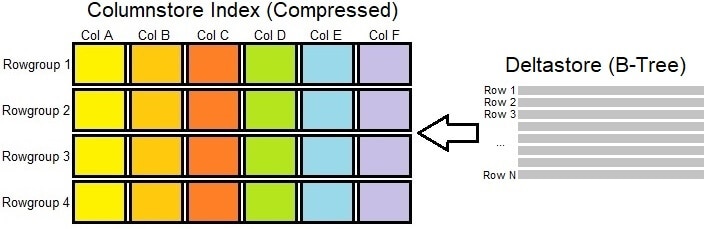
In contrast to the columnstore index, the deltastore is a classic B-tree clustered index. The minimum number of rows that can be bulk loaded into a rowstore is 102,400. When less rows are inserted, they are placed first into the deltastore, which will continue to accumulate rows until there are enough to merge into the columnstore index and the deltastore is closed.
The process that merges data from a deltastore into the columnstore index is called the tuple-mover and is an automated background process that will perform its work without operator intervention. It is possible to influence this process and move closed deltastores into the columnstore index via index rebuild/reorg operations. This will be discussed in greater detail below.
When a query is executed against the columnstore index, it will interrogate both the compressed rowgroups as well as the deltastore. The result set will be a combination of data from each. A query that needs to retrieve data from the deltastore will inherently be a bit slower as it needs to traverse a B-Tree structure in addition to the more efficient columnstore index.
With a classic heap or clustered index, large inserts could cause contention on the base table. As a result, database administrators would often perform inserts in smaller batches to reduce the size and duration of individual operations to ensure that the underlying table remains available for other operations. This reduced transaction log size, as well as the length of locks against the underlying data as it was being written to.
One of the most important takeaways of this process is that the optimal way to load data into a columnstore index is in large batches. Inserting data in small batches provides no value and will slow down data loads, as the deltastore will get used as an intermediary between your source data and the columnstore index.
An optimal data load size is 1,048,576 rows as that would completely fill up a rowstore within the clustered index. Some administrators will intentionally save data to intentionally load only the maximum rowstore size each time. This is optimal, but also a hassle. Realistically, the most convenient way to manage data loads is through a combination of large data loads and periodic index maintenance.
Delete Operations
Unlike inserts, which can benefit from bulk loading large row counts, deletes are solely managed through the deltastore. When a row is deleted, it is marked in the deltastore for deletion. The row remains in the columnstore index and the tuple-mover processes and flags them as deleted.
This can be demonstrated by performing a delete of 100 rows from the clustered columnstore index created above:
|
1 2 3 4 |
DELETE FROM dbo.fact_order_BIG_CCI WHERE fact_order_BIG_CCI.[Order Key] >= 8000001 AND fact_order_BIG_CCI.[Order Key] < 8000101; |
We can review the results by checking a new column from sys.column_store_row_groups:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
SELECT tables.name AS table_name, indexes.name AS index_name, partitions.partition_number, column_store_row_groups.row_group_id, column_store_row_groups.state_description, column_store_row_groups.total_rows, column_store_row_groups.size_in_bytes, column_store_row_groups.deleted_rows FROM sys.column_store_row_groups INNER JOIN sys.indexes ON indexes.index_id = column_store_row_groups.index_id AND indexes.object_id = column_store_row_groups.object_id INNER JOIN sys.tables ON tables.object_id = indexes.object_id INNER JOIN sys.partitions ON partitions.partition_number = column_store_row_groups.partition_number AND partitions.index_id = indexes.index_id AND partitions.object_id = tables.object_id WHERE tables.name = 'fact_order_BIG_CCI' ORDER BY indexes.index_id, column_store_row_groups.row_group_id; |
The results tell us exactly where in the columnstore index rows have been flagged for deletion:
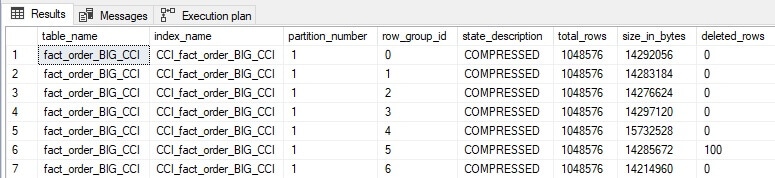
The deleted_rows column indicates how many rows have been soft-deleted. This query can be expanded slightly to expose the columnstore index delete bitmap object used for flagging these 100 rows as deleted:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
SELECT tables.name AS table_name, indexes.name AS index_name, partitions.partition_number, column_store_row_groups.row_group_id, column_store_row_groups.state_description, column_store_row_groups.total_rows, column_store_row_groups.size_in_bytes, column_store_row_groups.deleted_rows, internal_partitions.partition_id, internal_partitions.internal_object_type_desc, internal_partitions.rows FROM sys.column_store_row_groups INNER JOIN sys.indexes ON indexes.index_id = column_store_row_groups.index_id AND indexes.object_id = column_store_row_groups.object_id INNER JOIN sys.tables ON tables.object_id = indexes.object_id INNER JOIN sys.partitions ON partitions.partition_number = column_store_row_groups.partition_number AND partitions.index_id = indexes.index_id AND partitions.object_id = tables.object_id LEFT JOIN sys.internal_partitions ON internal_partitions.object_id = tables.object_id AND column_store_row_groups.deleted_rows > 0 WHERE tables.name = 'fact_order_BIG_CCI' |
ORDER BY indexes.index_id, column_store_row_groups.row_group_id;
The results add a bit more information:

Sys.internal_partitions exposes the structure used for managing the soft deletes. While this will be academic in nature for most operators, it is important to stress the nature of delete and update operations against columnstore indexes. That is: They are more complex than insert and select operations.
Note that rows are NEVER deleted from a columnstore index. They are flagged as deleted, but not removed. The cost to decompress a rowgroup and recompress it again is high and the only way to eliminate this technical debt is to rebuild the index (or the partition containing the deleted data).
Caution should be used when performing delete or update operations as they incur additional overhead in later updating the compressed columnstore index structure. In addition, delete and update operations can cause fragmentation if they change data in a way that results in the natural ordering of data within the index being disrupted. Similarly, a columnstore index can become less efficient over time if rowstores are deleted from repeatedly, as the result will be more and more rowstores with less rows in each to manage. The concept of order in a columnstore index will be discussed shortly and is critically important for making the most efficient use of it.
Update Operations
In a classic heap or clustered B-tree, an update is modelled as a delete followed immediately by an insert. The operations are carried out immediately in order, committed, and logged. Typically, these updates will not be slower than running an insert or delete operation independently of each other.
The deltastore adds an extra later of complexity that results in an update operation being modelled as two independent write operations that depend upon each other, both of which are committed to the deltastore. This is a very expensive operation, and will usually be significantly slower and less efficient than issuing separate delete and insert operations instead. For a large columnstore index, the cost of an update can be crippling to a database server – even one with significant resources allocated to it.
The following is an example of an update operation against a columnstore index:
|
1 2 3 4 5 |
UPDATE fact_order_BIG_CCI SET Quantity = 1 FROM dbo.fact_order_BIG_CCI WHERE fact_order_BIG_CCI.[Order Key] >= 8000101 AND fact_order_BIG_CCI.[Order Key] < 8000106; |
This query will update 5 rows, changing the quantity to 1 for each. By modifying the columnstore DMV query used previously, the results can be filtered to only show data that has yet to be fully committed to the columnstore index:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
SELECT tables.name AS table_name, indexes.name AS index_name, partitions.partition_number, column_store_row_groups.row_group_id, column_store_row_groups.state_description, column_store_row_groups.total_rows, column_store_row_groups.size_in_bytes, column_store_row_groups.deleted_rows, internal_partitions.partition_id, internal_partitions.internal_object_type_desc, internal_partitions.rows FROM sys.column_store_row_groups INNER JOIN sys.indexes ON indexes.index_id = column_store_row_groups.index_id AND indexes.object_id = column_store_row_groups.object_id INNER JOIN sys.tables ON tables.object_id = indexes.object_id INNER JOIN sys.partitions ON partitions.partition_number = column_store_row_groups.partition_number AND partitions.index_id = indexes.index_id AND partitions.object_id = tables.object_id LEFT JOIN sys.internal_partitions ON internal_partitions.object_id = tables.object_id AND column_store_row_groups.deleted_rows > 0 WHERE tables.name = 'fact_order_BIG_CCI' AND column_store_row_groups.state_description = 'OPEN' OR (column_store_row_groups.deleted_rows IS NOT NULL AND column_store_row_groups.deleted_rows > 0) ORDER BY indexes.index_id, column_store_row_groups.row_group_id; |
The results show 2 additional changes:

The total deleted rows count is now 105 (up from 100) and two additional entries appear in the deltastore that account for both deletes and inserts against the columnstore index.
Deltastore Summary
The primary takeaway of how the deltastore works is that larger data loads are better and delete/update operations should be minimized and isolated as much as possible. We will dig further into specific operations and performance in later articles in this series, which will allow us to further understand the most optimal ways to create columnstore indexes, load data into them, and maintain them.
When designing a large table to use a columnstore index, take extra time to design out updates and minimize delete operations. Doing so will make data loads faster, reduce the need for index maintenance, and improve the performance of select queries against the table.
Conclusion
Columnstore indexes are an impressive feature that has grown and improved with each release of SQL Server since its inception. To take full advantage of columnstore indexes, though, requires understanding how data is stored in them to determine best practices for efficiently loading and reading data.
Additional concepts such as data order, partitioning, segment elimination, and rowgroup elimination can allow OLAP data access to be significantly more efficient and scalable as data continues to grow. In the next article, I’ll cover some of these best practices and guidelines.
Read also:
Part 2: Best Practices and Guidelines
Fast, reliable and consistent SQL Server development…
Frequently Asked Questions (FAQs)
1. What is a rowgroup in a columnstore index?
A rowgroup is a batch of rows (up to approximately 1,048,576 rows) that are compressed together in a columnstore index. Within each rowgroup, data for each column is stored in a separate compressed segment. SQL Server processes columnstore data one rowgroup at a time, which enables rowgroup elimination – skipping entire rowgroups that don’t contain relevant data based on segment metadata (min/max values).
2. What is the deltastore in a columnstore index?
The deltastore is a B-tree structure that temporarily holds newly inserted rows before they’re compressed into the columnstore. When rows are inserted, they first land in a delta rowgroup. Once a delta rowgroup accumulates enough rows (typically around 1 million), the tuple mover background process compresses it into a proper columnstore rowgroup. Multiple delta rowgroups can exist simultaneously.
3. How does columnstore compression work in SQL Server?
Columnstore compression works by storing values from the same column together, allowing SQL Server to apply efficient encoding techniques: dictionary encoding for repeated string values, value encoding for integers, and run-length encoding for consecutive repeated values. Because values in the same column tend to be similar (e.g., all dates, all status codes), compression ratios of 10:1 are common. The compressed data stays compressed in the buffer cache and is only decompressed when needed by the execution engine.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved





Load comments