
Over the past few years, I’ve worked to maintain and optimize a database environment, and I’ve faced all sorts of problems, but one pain point common in almost all SQL Server environments is tempdb.
The usage of tempdb in SQL Server is well known, and I don’t want to explain the same list of issues and recommendations already covered very well in many articles all over the internet. Here are some of the known issues you could easily google to get more information about:
- Object allocation contention on metadata pages used to manage space on tempdb data file
- Metadata contention for pages that belong to system objects used to track the temporary object’s metadata (btw, this is improved on SQL Server 2019)
- Issues with codes that are not optimized to the benefit of tempdb cache of system metadata
- Spills of hash and sorts
In this article, I would not like to focus on those common things, but in other interesting problems I found while I was supporting my customers.
Some tempdb Problems You are Very Likely to Have
The following is a list of a few tempdb problems you are very likely to have in your SQL Server environment, that you may not know about.
- In versions prior to SQL Server 2014, eager writer is slowing down your inserts and wasting I/O when a flush operation is not needed.
- On SQL Server 2014 (backported to SQL Server 2012 SP1+CU10 or SP2+CU1), the eager writer was relaxed to not flush for tempdb; this fixed one problem and caused another one.
- Indirect checkpoint (target recovery time) enabled by default on tempdb for SQL Server 2016. The idea was to clean up dirty pages created by the change in SQL2014, but it doesn’t really do a good job fixing it as it doesn’t clean up dirty pages allocated on minimally logged operations.
Eager Writer and tempdb
One of many performance improvements that came with SQL Server 2014 is that it doesn’t flush dirty pages created in a minimally logged operation on tempdb. This gives you the benefit of having faster (compared to prior versions) inserts, but it caused another problem as those allocated pages may take a lot of time to be removed from the buffer pool data cache. Before discussing the problem, quickly look at the benefit and then understand some important concepts of flush dirty pages on tempdb.
Use the following query which inserts around 520MB of data into a temp table:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
USE tempdb GO IF OBJECT_ID('#TabTest1') IS NOT NULL DROP TABLE #TabTest1; CREATE TABLE #TabTest1(Col1 CHAR(500)); INSERT INTO #TabTest1 SELECT TOP 1000000 CONVERT(CHAR(500), A.name) AS Col1 FROM master.dbo.sysobjects A, master.dbo.sysobjects B, master.dbo.sysobjects C, master.dbo.sysobjects D OPTION (MAXDOP 1); GO |
When I ran it on in my local instances with both tempdb configured with same details (same disk, initial sizes, Trace Flags, etc.), I see the following results:
- On SQL Server 2008 R2 (10.50.6220.0) it took 32 seconds to run.
- On SQL Server 2017 (14.0.3238.1) it took 1 second to run.
As you can see, the difference is huge; this is pretty much because of the following:
|
1 2 3 4 5 6 7 8 9 10 |
SELECT Page_Status = CASE WHEN is_modified = 1 THEN 'Dirty' ELSE 'Clean' END, DBName = DB_NAME(database_id), Pages = COUNT(1) FROM sys.dm_os_buffer_descriptors WHERE database_id = DB_ID('tempdb') GROUP BY database_id, is_modified |
|
SQL Server 2008R2 |
SQL Server 2017 |
|
|
|
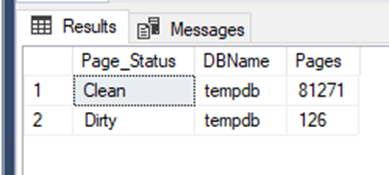
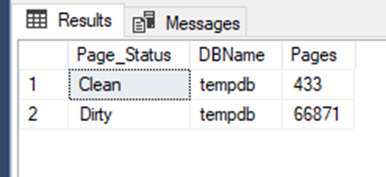
As you can see, checking the DMV sys.dm_os_buffer_descriptors shows that most of the allocated pages on SQL Server 2017 are dirty, and on SQL Server 2008R2 the eager writer process took time to clean and write the pages on the tempdb data file. This is where the time difference comes from. On SQL 2008R2, the command has to wait for the flush, and on SQL2017 it doesn’t.
What does Checkpoint do on tempdb?
Before moving forward, here’s a quick recap of some important concepts you need to know to understand the problems I’ll mention in this article.
When you insert a row in a table, SQL Server does not immediately write it in the data (mdf) file. It has a control to write it on the log (ldf) and keep the row in a page in memory. The pages that are in memory and were not physically written to the data file are called dirty pages. A dirty page is written to the data file by one of the three processes: checkpoint, lazy writer or eager writer. These are the very basics of I/O writing on SQL Server, and you need to understand it to be able to troubleshoot and explain complex problems related to tempdb and the whole SQL engine.
Rows may exist only on the log file and dirty pages in memory. If an unexpected crash happens and your SQL Server stops, once it is back, SQL engine must redo any transaction that was written to the transaction log file and apply those changes to the data (mdf) files. This whole thing doesn’t make sense for tempdb, right? Since tempdb is recreated on SQL Server start, there is no need for tempdb to recover transactions from the log file into the data file, therefore, there is no need to flush dirty tempdb pages to disk. Actually, this is why SQL Server doesn’t (there are exceptions, when the log reaches 70% of space, manual checkpoint…) do automatic checkpoints for tempdb.
Understanding Why the Change on SQL2014 Caused Another Issue
You may be wondering, considering the case we’re looking at, why this whole checkpoint thing is important? Well, let me answer this with another question.
Using the query inserting data on #TabTest1 as a sample, consider that on SQL Server 2014+, dirty pages won’t be flushed by the eager writer; would this behavior cause another problem? In other words, what would be the impact of having many dirty pages on tempdb?
Well, the problem is that you could have a scenario where tempdb dirty pages are using a lot of memory of your precious buffer pool. If you consider there are scenarios with heavy usage of temporary tables, this can quickly turn into memory pressure. The main problem of this memory pressure is that there will be no automatic checkpoint to flush those dirty pages, that means that lazy writer will be the one flushing those pages. After it flushes the pages, then it will free other buffers available by removing infrequently used pages from the buffer cache.
As Bob Dorr mentioned in his blog post on the improvement, “the pages used in these operations are marked so lazy writer will favor writing them to tempdb”. What he is saying here is that those pages will be written to tempdb data file by lazy writer. So far, so good. However, if there is any memory pressure, lazy writer will flush those pages and put them in the free list and will do it for all dirty pages. That includes pages that were allocated in a session that are not active anymore. Say you have a session that created a 10GB temporary table. Once you’re done, you can drop the table and close the session, but the allocated pages will still be there in memory. Right? All those nasty 10GB of dirty pages of a table that does not exist anymore. As soon as you have memory pressure and need to find space on buffer cache to put some data in memory, lazy writer will waste time to flush those useless dirty pages that will never be used. In my opinion, the correct concept should be that once the table is dropped or session is done, lazy writer should be able to put these pages on the free list to avoid using up precious buffer pool cache and triggering unnecessary write I/O operations on tempdb data file.
Ok, Fabiano, I don’t get it, can you show me a sample on where this could be a problem? Yep, sure. Stay with me.
Now to prepare the scenario to simulate the issue. First, set the instance (you could use any version equal to or greater than SQL Server 2014, I’m using a SQL Server 2017) to use only 8GB of memory:
|
1 2 3 4 5 6 7 |
USE master GO -- Set MaxServerMemory to 8GB EXEC sys.sp_configure N'max server memory (MB)', N'8192' GO RECONFIGURE WITH OVERRIDE GO |
Then, create a 5GB table to run the tests. For this demo, I’m using the AdventureWorks2017 database:
|
1 2 3 4 5 6 7 8 9 10 |
USE AdventureWorks2017 GO DROP TABLE IF EXISTS AdventureWorks2017.Sales.SalesOrderDetailBig GO SELECT TOP 50000000 a.* INTO AdventureWorks2017.Sales.SalesOrderDetailBig FROM AdventureWorks2017.Sales.SalesOrderDetail a, AdventureWorks2017.Sales.SalesOrderDetail b OPTION (MAXDOP 1) GO |
Now, create a procedure that will insert 5GB of data into a temporary table using an INSERT + SELECT command.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
USE AdventureWorks2017 GO IF OBJECT_ID('st_1') IS NOT NULL DROP PROC st_1; GO CREATE PROC st_1 AS IF OBJECT_ID('tempdb.dbo.#TabTest1') IS NOT NULL DROP TABLE #TabTest1; CREATE TABLE #TabTest1 ( Col1 CHAR(500) ); INSERT INTO #TabTest1 SELECT TOP 10000000 CONVERT(CHAR(500), A.name) AS Col1 FROM master.dbo.sysobjects A, master.dbo.sysobjects B, master.dbo.sysobjects C, master.dbo.sysobjects D OPTION (MAXDOP 1); GO |
Now, before running st_1 to populate the temporary table, make sure to run it using a cold cache:
|
1 2 3 4 5 |
-- Manual checkpoint on tempdb to flush pages and start with a cold env. USE tempdb GO CHECKPOINT;DBCC DROPCLEANBUFFERS(); DBCC FREEPROCCACHE() GO |
Now, open a new session and run the procedure st_1 to allocate some pages on tempdb. Once you’re done you can close the session; I know that the temporary table is destroyed after sp execution, but just in case you think it is not, go ahead and close the session.
|
1 2 3 4 |
-- Should take about 15 seconds as long it has memory to keep -- all 5GB of inserted data EXEC AdventureWorks2017.dbo.st_1 GO |
At this time, if you look at the sys.dm_os_buffer_descriptors, you’ll see that about 666k (scary number) of newly allocated pages are dirty:
|
1 2 3 4 5 6 7 8 9 10 11 |
SELECT Page_Status = CASE WHEN is_modified = 1 THEN 'Dirty' ELSE 'Clean' END, DBName = DB_NAME(database_id), Pages = COUNT(1) FROM sys.dm_os_buffer_descriptors WHERE database_id = DB_ID('tempdb') GROUP BY database_id, is_modified GO |
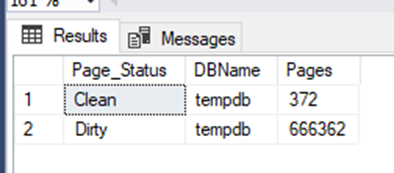
Now, here is the fun part. If you try to read the 5GB table (Sales.SalesOrderDetailBig) created on AdventureWorks2017 DB, what happens? Remember, it’s a 5GB temporary table. Pretty much all those pages are in memory and dirty. If you try to read another 5GB, there will not be enough memory available (max server memory is set to 8GB), and lazy writer will have to run and put some pages on the free list. Before it does that, it will flush all those dirty pages. While it is doing it, your query will be put to sleep and may take a long time to run.
|
1 2 3 |
SELECT COUNT(*) FROM AdventureWorks2017.Sales.SalesOrderDetailBig OPTION (MAXDOP 1) GO |
While the query is running, this is what you can see:
As expected, lazy writes/sec performance counter is showing lots of activity:
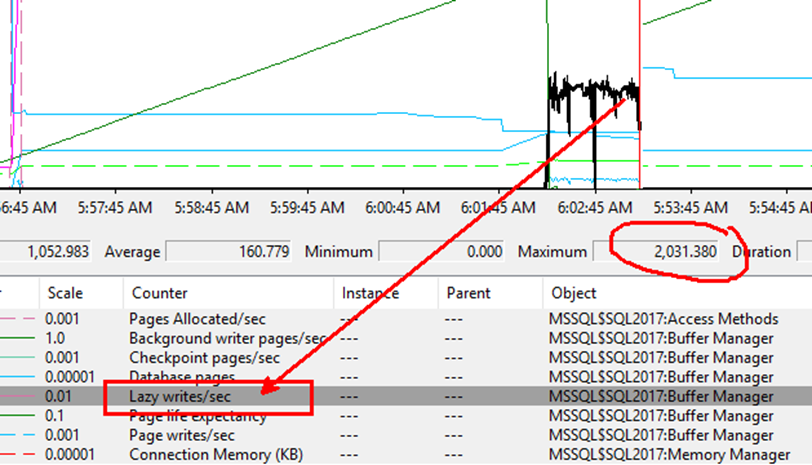
The query is waiting on SLEEP_TASK, and there are several pending I/O requests.
|
1 2 3 4 5 |
SELECT * FROM sys.dm_os_waiting_tasks WHERE session_id = 51 GO SELECT * FROM sys.dm_io_pending_io_requests GO |
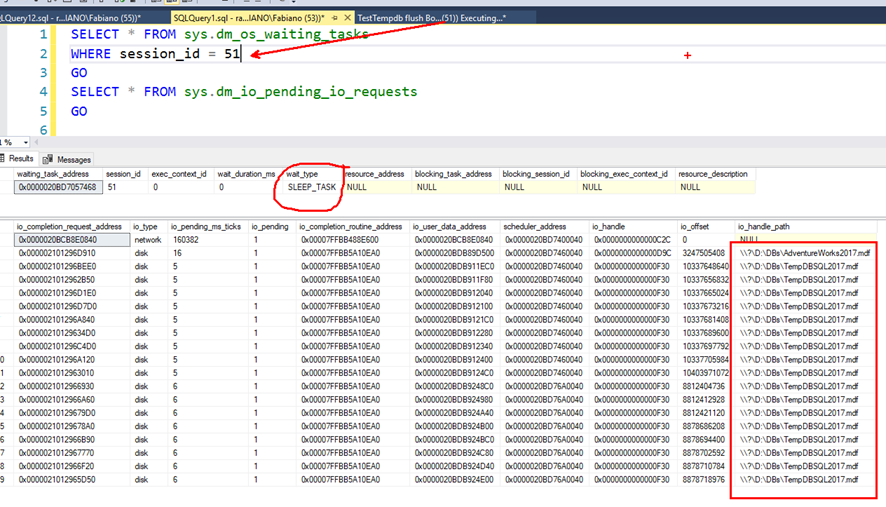
My point is that the query on Sales.SalesOrderDetailBig is taking 3 minutes to run, and most of the time it is waiting for lazy writer to flush some of the dirty tempdb pages and put pages on the free list. If lazy writer didn’t have to flush those pages, the query should be able to run in just a few seconds.
But wait, SQL 2016+ indirect checkpoint on tempdb fixed this problem
On SQL Server 2016 indirect checkpoint, an outstanding feature initially introduced on SQL Server 2012, is enabled by default on model system database and set to 60 seconds. Since the tempdb database is derived from model during startup, it inherits this property and has indirect checkpoint enabled by default. (Note: TF3468 can be used to disable this)
If you haven’t heard about indirect checkpoint, the following is a quick explanation of it from this MS document:
“The conventional or automatic checkpoint algorithm assumes fixed time interval to recover each log record without accounting for the number of pages dirtied by a database transaction. In simpler terms, when (number of log records * fixed time interval to recover a log record) exceeds recovery interval set at the instance level, automatic checkpoint is triggered on the database. As automatic checkpoint doesn’t account for the dirty pages from each transaction (an important influencer of recovery time), it makes the recovery time less predictable. With indirect checkpoint, the engine maintains partitioned dirty page lists per database to track the number of dirty pages in the buffer pool for that database from each transaction. When the background recovery writer polling the dirty page manager detects the condition, where the number of dirty pages exceeds the dirty page threshold (calculated by heuristics), the recovery writer would trigger the flush of dirty pages to ensure database recovery would complete within the target_recovery_time set”
As I mentioned before, there is no recovery need for tempdb as it is recreated on SQL service start, so indirect checkpoints on tempdb may not make much sense from a recovery perspective. However, the indirect checkpoint feature is still important to ensure the dirty pages in tempdb do not continue to take away buffer pool pages from user database workload as there is no automatic checkpoint to flush pages for tempdb.
One of the reasons to enable indirect checkpoints on tempdb is to help scenarios with dirty tempdb pages take away the buffer pool data cache and cause pressure on lazy writer while it flushes dirty pages, the exact scenario we are analyzing.
If indirect checkpoint had previously flushed dirty pages on tempdb, a query wouldn’t need to wait (SLEEP_TASK) for lazy writer to flush it.
But, wait, don’t be happy yet; there is a small problem with indirect checkpoints on tempdb. Any non-logged “bulk” operation that qualifies for an “eager write” in tempdb is not a candidate to be flushed by the recovery writer (the internal thread that runs the indirect checkpoint).
This raises an important question: which data load operation is minimally logged on tempdb? This is important to know because minimally logged operations on tempdb will not be flushed by the indirect checkpoint. The following list can be used to assist you in understanding which load operations on tempdb will be minimally logged and which will not.
|
Command |
Is minimally logged? |
|
INSERT INTO #TMP + SELECT |
Yes, since local temporary tables are private to the creating session, there is no need to use TABLOCK to get an ML operation. |
|
INSERT INTO #TMP WITH(TABLOCK) + SELECT |
Yes. Note that TABLOCK is required to get + SELECT an insert operator running in parallel on SQL2016+. |
|
SELECT INTO #TMP |
Yes. Since tempdb DB recovery model is always set to simple, a SELECT + INTO will be ML. |
|
SELECT INTO tempdb.dbo.TMP |
Yes. |
|
INSERT INTO tempdb.dbo.TMP WITH(TABLOCK) + SELECT |
Yes. Since this is a regular user table that can be accessed by any session, it requires a TABLOCK to be ML. Same applies for a global (##) temporary table. |
|
INSERT INTO tempdb.dbo.TMP + SELECT |
No. So, the only way to don’t qualify for a ML operation on tempdb is to use a regular or a global (##) temporary table and don’t specify the TABLOCK. |
As you can see, pretty much all of the insert commands you can use on tempdb will be minimally logged, and pages won’t be flushed by the indirect checkpoint.
Summary
Tempdb troubleshooting can be very complex. It requires you to understand many components of the SQL Server engine. If you need an answer to the “why” question, make sure you took some time to study SQL Server internals.
The current behavior of SQL Server is just “the way it works today.” I honestly expect it to improve on this area, as it is not rare for me to see an environment where tempdb is the TOP 1 database on data cache usage. I don’t want my environments to have my precious productions tables doing physical reads because someone ran a report that created a 20GB temporary table, or, in a worst-case scenario to wait for lazy writer to flush some “never will be used again” dirty pages. It would be good to have something like a “max buffer pool usage” setting on tempdb. What do you think?
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved





Load comments