
The series so far:
- DevOps and application delivery
- DevOps application delivery pipeline
- Database DevOps
- DevOps security privacy and compliance
- DevOps Database Delivery
- 10 Guidelines for Implementing DevOps
DevOps has been gaining steady ground in the world of application development, with ongoing improvements in delivery processes and the tools needed to support them. For the most part, however, DevOps has focused primarily on the application itself, with databases left to their own devices, despite the integral role they play in supporting many of today’s data-driven workloads.
According to the 2018 Accelerate: State of DevOps report, “database changes are often a major source of risk and delay when performing deployments.” But the report then states that integrating databases into the application delivery process could have a positive impact on continuous delivery. The key, according to the report, is good communication and comprehensive configuration management that incorporates databases. In other words, database changes should be managed in the same way as application changes.
Redgate’s 2019 State of Database DevOps report adds to these findings with their own survey results. According to the report, 77% of the respondents claim that their developers work across both databases and applications, and 75% say that developers build the database deployment scripts. However, 63% acknowledge that DBAs are responsible for deploying database changes to production.
The report also states that the two most significant challenges to integrating database deployments into the DevOps process are “synchronizing application and database changes” and “overcoming different approaches to application and database development.” In contrast, the two biggest reasons for integrating databases into DevOps are “to increase speed of delivery of database changes” and “to free up developers’ time for more added value work.” More importantly, 61% believe that such a move would have a positive impact on regulatory and compliance requirements.
Clearly, integrating database deployments into the DevOps process remains a challenge for many organisations, yet there’s a growing recognition that databases need to be brought into the DevOps fold. And in fact, this is beginning to happen, as more organisations incorporate database deployments into their integration and delivery processes. Not only does this promise to help improve application delivery, but it can also benefit database development itself.
The DevOps Promise
When application and database development efforts are more tightly integrated—with teams working in parallel and sharing a common process—they can release builds that are more consistent and stable, while reducing unnecessary risks and delays. The teams use the same infrastructure to develop and deploy application and database code, making it easier to standardise processes and coordinate efforts.
In a more traditional development environment, database changes can hold up application delivery, impacting productivity and costs. By incorporating databases into DevOps, database deployments can benefit from the established processes, while more tightly integrating database and application development.
A DevOps approach to database development also makes the process more agile and adaptable. Teams implement smaller, more frequent changes as part of a coordinated effort while receiving continuous feedback on the delivery processes and application components. In this way, database development and deployment are no longer disconnected from the larger delivery workflow but become integrated into the process throughout the application lifecycle.
The DevOps Challenge
As good as database DevOps might sound, there’s a good reason that organisations have been slow to jump on board. Transitioning from a siloed-database model to a DevOps-database approach is no small effort.
To begin with, databases were never part of the original DevOps vision. Processes and tools were developed for application code and application deployments, not for the peculiarities of database management. It’s only been recently that databases have been incorporated into DevOps processes in a meaningful way.
Database tools and operations are very specific to database development and management and the environment in which those databases reside. In the early days of DevOps, many viewed the database as existing in a separate world, and both sides of the aisle preferred to keep it that way.
One of the significant differences between application and database deployments comes down to data persistence. With applications, it’s much easier to update or replace code because there’s no data to manage along the way. With databases, however, you can’t simply overwrite schemas or copy changes from one environment to another without pulling the data along with you. Careful consideration must be given to how changes impact existing data and how to preserve that data when changes are made. Otherwise, you risk data loss, integrity issues, or privacy and compliance concerns.
Databases also bring with them size and scalability issues that differ from application code. Implementing schema changes on a massive database in a production environment can be a significant undertaking and lead to performance issues and degraded services. Database changes become even more complicated if the database is being accessed by multiple applications, especially if no single application has exclusive ownership.
Perhaps the biggest hurdle to implementing database DevOps has been a siloed mindset that makes it difficult for various players to come together in a way that makes integration possible. According to the Redgate report, only 22% of the respondents said that their developers and DBAs were “great” at working together effectively as a team, and without a team-focused attitude, an effective DevOps strategy is nearly impossible to implement.
Despite these challenges, however, database DevOps has made important inroads in recent years. DevOps tools now better accommodate databases, and database tools better integrate with DevOps systems. Attitudes, too, are beginning to change as more participants come to understand the value that incorporating databases can offer. Although database DevOps is still a challenge, many teams have now demonstrated that application and database delivery can indeed be a unified effort.
Moving Ahead with Database DevOps
To make DevOps work, the database team must adopt the same principles and technologies as those used by the application team when delivering software. Figure 1 provides an overview of what the database DevOps process might look like when integrated into the application delivery pipeline.
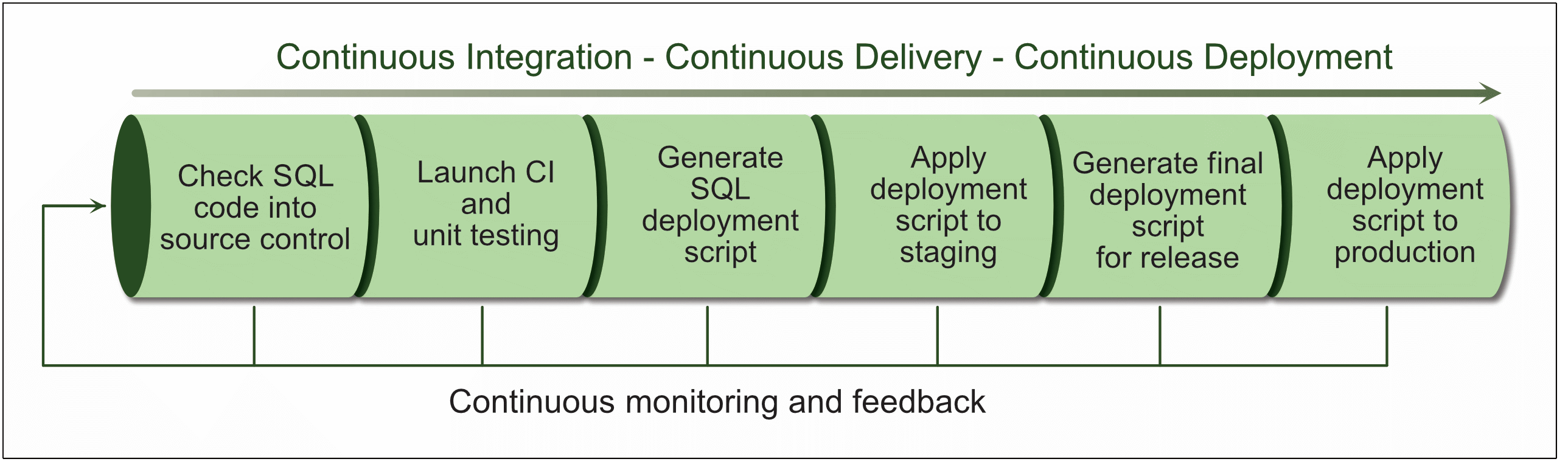
Figure 1. Integrating database deployment into the DevOps process
The first step is to store all database code in source control (also referred to as version control). A source control solution provides the foundation on which all other DevOps operations are based.
With source control, every developer works from the one source of truth, resulting in fewer errors and code conflicts. Source control also tracks who made what changes and when those changes were made. In addition, source control maintains a version history of the files, making it possible to roll back changes to previous versions. Source control also makes it easier to repeatedly build and update a database in different environments, including QA and development.
Database teams should store all their database code in source control. This includes the scripts used to build the databases as well as the migration (change) scripts that modify the database or data. For example, source control should be used for scripts that create, alter, or drop database objects—such as tables, views, roles indexes, functions, or stored procedures—as well as any scripts that select, insert, update, or delete data. The teams should also store static data, such as data used to populate lookup tables, as well as configuration data, when appropriate.
Once all the code and data are in source control, the database deployment operations can be incorporated into the same DevOps continuous integration (CI) and continuous delivery processes used for application deployments. When a developer checks in database code, it triggers an automated build operation that runs alongside the application release process, making it easier to coordinate database and application deployments.
When code is checked into the source control repository, the CI service kicks in and runs a series of commands that carry out such tasks as compiling source code and running unit tests. If a database is part of the deployment, the CI service tests and updates the database—or alerts developers to errors. If problems are discovered, developers can fix them and resubmit the code, which relaunches the CI process.
To incorporate databases into CI, a team might turn to a tool such as Redgate’s SQL Change Automation, which can integrate with any CI server that supports PowerShell. Redgate also provides extensions for CI products such as Jenkins, TeamCity, or Azure DevOps for enabling database integration.
When the CI service processes the SQL code, it produces an artifact that includes the deployment script necessary to update the applicable database objects and static data. The artifact also contains details about the deployment process, including a diff report that shows what has changed in the database. The artifact represents a specific, validated version that can be used as a starting point for the database release process.
At this point, the artifact is deployed against a staging database that is ideally an exact copy of the production database. Here DBAs can verify and confirm the changes to ensure the staging database is production-ready. If necessary, they can also make additional changes. Out of this process, a final deployment script is generated, which can then be passed down the pipeline for deployment against the production database.
Not surprisingly, the exact approach to database delivery is much more involved than what I’ve described here, especially when it comes to migration script versioning, and that process can vary significantly depending on the tools being used and how those tools are configured.
What this does demonstrate is that database DevOps is indeed doable, providing database teams with a process that automates repetitive deployment and testing operations. With DevOps, teams can deliver smaller releases that are easier and faster to deploy, while having in place a consistent, steady mechanism for ongoing database deployments that work in conjunction with application delivery.
Testing and Monitoring
One of the most important aspects of the application delivery pipeline is ongoing testing. Changes to the database should undergo rigorous testing before the release reaches the staging environment. In this way, developers learn of problems quickly and early in the development process. When issues are discovered, they’re immediately alerted so they can check fixes into source control and keep the development effort moving forward.
Developers and DBAs should invest the time necessary to write comprehensive tests that provide for as many scenarios as possible. Many of these tests will be based on frameworks specific to database testing. For example, tSQLt is a popular open-source framework for SQL Server that lets you write unit tests in T-SQL. Regardless of the framework, the goal is the same: to identify as many issues as possible before database changes make it to production.
Unit tests offer your first line of defence against problem SQL code. Because they run when the code changes are checked into source control, they provide the fastest response to possible issues. A unit test is a quick verification of specific functionality or data, such as ensuring that a user-defined function returns the expected result. A unit test should be concise and run quickly, producing a single binary value—either pass or fail.
Also important to the application delivery pipeline is ongoing monitoring, which needs to be as comprehensive as the testing processes themselves. Monitoring can be divided into two broad categories: the feedback loop and system monitoring.
A DevOps application delivery pipeline includes a continuous feedback loop that provides participants with ongoing details about the delivery process. For example, when the CI service notifies developers about problems in their code, those alerts can be considered as part of the feedback loop. Development teams (application and database) should have complete visibility across the entire pipeline. Not only does this help identify issues with the application and database earlier in the delivery cycle, but it also helps to monitor the delivery process itself to find ways to improve and streamline operations.
System monitoring is more typical of what you’d expect of database operations. Once the changes have been deployed to production, you must closely monitor all related systems to check for unexpected issues and ensure that systems are running as they should, before users or data are seriously impacted. To this end, DBAs should monitor database systems for performance and compliance, taking into account regional differences and regulatory requirements. Developers and DBAs alike should have a real-time understanding of issues that might need immediate attention or those that should be addressed in the foreseeable future.
Testing and monitoring also play a critical role in ensuring a database’s overall security. Developers, IT administrators and DBAs must take into account security considerations throughout the entire application lifecycle, addressing issues that range from SQL coding to server security in order to ensure that data is protected at every stage of the application delivery process.
Proper testing and ongoing monitoring can go a long way in helping to enforce these protections. By using source control and automating the delivery process, organisations have a process that is more predictable and easier to manage, while providing an audit trail for tracking potential issues. Database teams still need to ensure proper configurations and secure environments, but an effective DevOps pipeline can also play an important role in your security strategy.
The New Era of Database DevOps
Database DevOps offers the promise of quicker, easier and more secure deployments while bringing application and database development efforts in line with one another. But DevOps is not a one-size-fits-all solution to application delivery, nor is it meant to be a developer-first strategy that leaves DBAs and IT administrators behind.
Developers, DBAs, and operation professionals must work together to implement an application delivery strategy that takes into account the needs of all participants, with the goal of delivering the best applications possible as efficiently as possible in the shortest amount of time. Anything less and your database DevOps efforts are destined to fail.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved



Load comments