

DevOps, Continuous Delivery & Database Lifecycle Management
Continuous Integration
As a senior DBA in a busy development environment, I’ve been interested in database CI for a while. I spent a lot of time researching, talking to people, and learning about new tools that could help me.
My goal was to set up our build environment in a way that enables it to watch the database source control repositories, and automatically create builds when changes are committed to those repositories.
This article is a summary of that effort and a guide to how you can implement CI for your database too.
Our setup
Our original setup was typical of many companies. We used VisualSVN Server for application version control and JetBrain’s TeamCity as our build/CI server.
To enable CI for the database, we added SQL Source Control and DLM Automation, both of which are from Redgate. We decided on these tools because each are plug-ins for the tools we already had, so while we were changing the way we worked, we were actually aligning CI for our database with the existing CI for our application.
If you don’t use SVN as your application version control system, don’t worry – you can configure a similar setup with GIT, Team Foundation Server, Vault, Mercurial, or Perforce. It’s the same story for your build/CI server: if it’s not TeamCity, Redgate’s tools let you set up database CI with Jenkins, Go, or Bamboo.
So even if your setup is different, the broad principals and the tools you need are exactly the same.
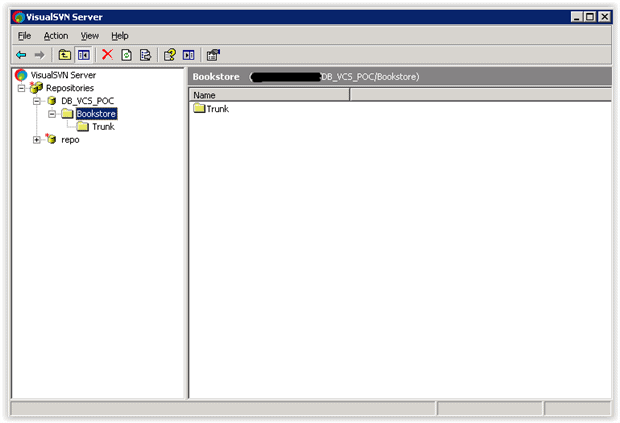
Step one – configure your SVN Repository
Configuring a repository in SVN is easy. In the VisualSVN Server Manager, simply create a repository (the example below is called DB_VCS_POC), and create a folder inside it (in this case, ‘Bookstore’).
Step two – version control your database
I mentioned SQL Source Control from Redgate earlier. I like it because it’s a plug-in for SQL Server Management Studio (SSMS) that’s intuitive and easy to use. Install it, start up SSMS, and SQL Source Control is immediately visible within SSMS, so you already feel at home with it.
Select your database in the Object Explorer and, in the setup tab for SQL Source Control, click Link to source control.
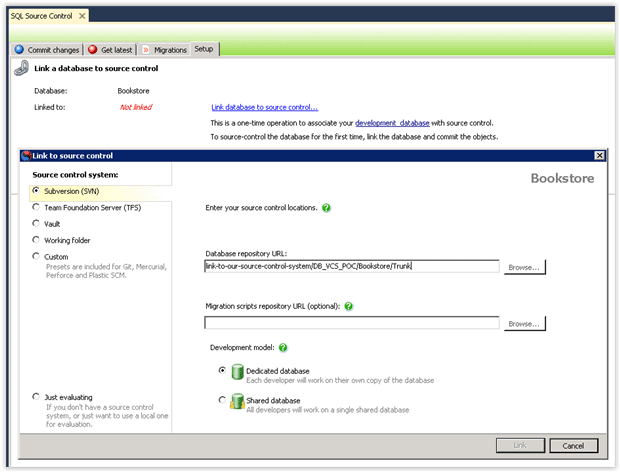
On the left of the window, you can then choose your source control system, add the location of your database depository, and specify a Dedicated or Shared database.
To do the initial commit, go to the Commit changes tab, type a meaningful commit comment (something like “Initial source control commit”) and click OK. And that’s it. You’ve source controlled your first database.
Step three – configure your build server
A build server is key for CI: it continuously builds packages triggered by the source code being checked into the source control repository. The work of multiple developers working on the same code base integrates into one mainline, which prevents integration problems.
In order to configure your build server, you’ll need to install Redgate’s DLM Automation. I found this really easy: I just downloaded the trial version from the Redgate website and installed it on our build server following their instructions.
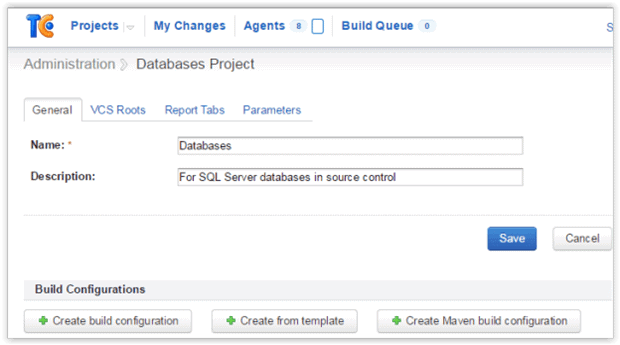
Next, create a project in TeamCity and give it a name. In the example below, I chose the name ‘Databases’ and added a description, which is useful for future reference.
Now the exciting stuff starts because, with a project created, you can make your first TeamCity build configuration for your database. This is a group of settings that include where to checkout sources for the build, what build procedures to run, and the triggers that start a new build.
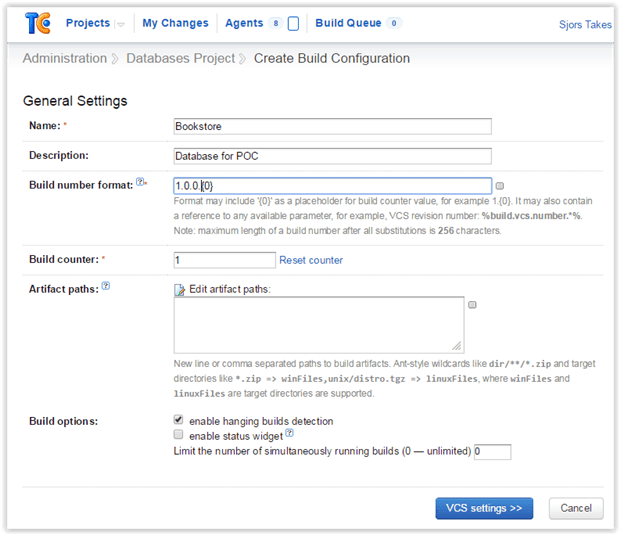
In this example, the build configuration is named ‘Bookstore’.
The blue button labelled ‘VCS settings’ is next, and this is about configuring the VCS settings (VCS stands for Version Control System and is the same as Source Control). This is where you configure the build configuration to watch the Database Source Control Repository.
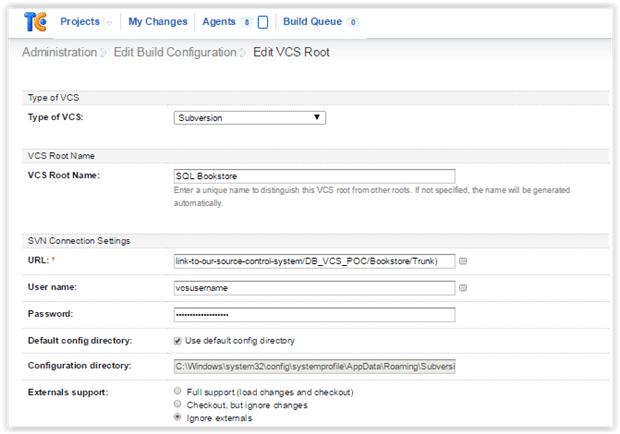
Here, you enter the URL of your database source control repository. As you can see, we’re using Subversion (SVN) as our VCS/Source Control System, but you could just as easily choose GIT, TFS, Vault, etc.
Step four – configure your first build step
Since you’ve already installed Redgate’s DLM Automation, you can now select the Redgate SQL CI Build Runner type for the first step you configure. Give the step a meaningful name and a meaningful Package ID, as show below.
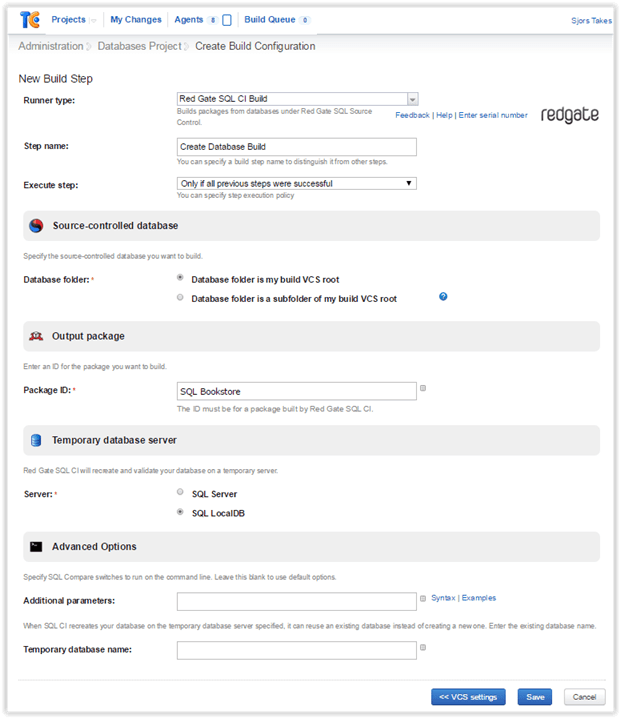
It’s advisable to select SQL LocalDB as your Temporary database server if you’ve just started. It means that when this build step is executed, a temporary scratch database for some automated tests will be created on this instance. This instance lives on every build server where you installed Redgate’s DLM Automation.
If your database is referencing one or more other databases, it’s not possible for the Build Runner to create a scratch databases if the temporary database server is LocalDB (those other databases don’t exist on your LocalDB instances). In that case you have to select a SQL Server instance, preferably one dedicated for this purpose.
Step five – configure your publishing package
At this point, the SQL CI tool is integrated with Team City and the build configuration is complete.
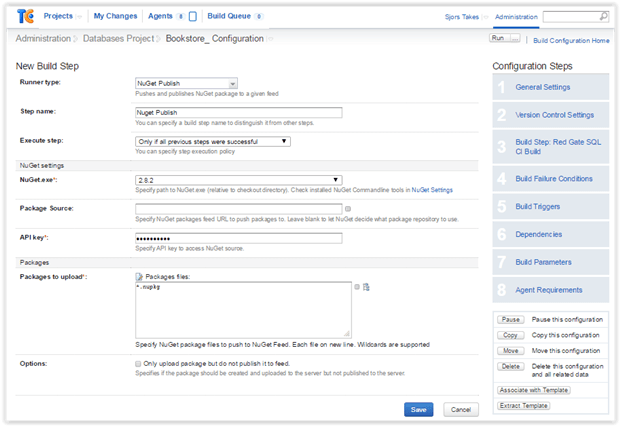
One extra step you need is to choose your preferred publishing package – the kind of package you’d like the system to produce when you’re certain everything is ready.
In the following example, I’ve chosen the NuGet Publish runner type, given the step a name, selected the NuGet.exe version, and entered the API key.
Step six – configure the build trigger
Finally you want this configuration to be triggered to automatically create a new build every time a change in the database repository occurs. This can be done by configuring a build trigger, as shown below.

That’s it. As you can see, it only takes a few minutes to create a TeamCity Build Configuration for your databases. You’re probably eager to see the magic of automated database builds happen, so go ahead and make a change to your database repository (preferably by committing a change to it from your development environment).
Conclusion
As a DBA, the systems I talk about in this article were completely new to me. I can imagine there are DBAs in the same position as I was – wanting to set up a database deployment pipeline, but not sure how to start. If that sounds like you or someone you know, my advice is to get out of the cubicles and talk to the developers. Ask them what source control system they use for their software, if they use a build server (and which brand), and how they deploy their software (do they use a deployment tool?). Ask for a demo.
Let them show you how they commit their software to the source control system, and how they create builds and deploy them to the various environments. Most importantly, ask how they would like to be able to deploy database changes in a smooth, pain-free way. I’ll bet they’ll really appreciate your interest and your intentions to make things better for them – and they’ll be willing to work with you to make everyone’s life better.
Also talk to the administrators of the servers which run the source control system, the build server(s) and the deployment server(s) – they are probably members of your operations team. Let them know you’re thinking about a continuous integration process for your database, and explain the advantages for them.
Depending on how your company’s database delivery processes are set up right now, they can become more efficient with continuous integration. Developers can make changes to databases in their local work environments (sandboxes), commit those changes to source control and in the background your build environment is triggered to automatically create a new build of the database including the change just made. Then it’s only a matter of deploying the build with a push of a button from within your Deployment Environment.
Think of the problems it can solve in your situation, like conflicts developers might have with each other because of the way they are working now. Think of how collaboration between your colleagues will improve, because you are all working on the same software/database delivery pipeline which, in turn, leads to a more DevOps culture.
Don’t forget too that CI is a key part of continuous delivery: if your company wants to implement continuous delivery, you have to implement CI first. And as I’ve demonstrated, it’s a lot easier than you think.

DevOps, Continuous Delivery & Database Lifecycle Management
Go to the Simple Talk library to find more articles, or visit www.red-gate.com/solutions for more information on the benefits of extending DevOps practices to SQL Server databases.
Load comments