
Find out more

DevOps, Continuous Delivery & Database Lifecycle Management
Version Control
Until a database is first released into production, there is no necessity for change scripts. It is generally simpler and more convenient to build a database from the DDL source code components, and bulk load whatever data is required. From the source DDL scripts, plus the basic versioning functionality of the version control system, you can see at a glance the history of each table’s evolution and who did what, why and when. You can build the database from any release that is in version control and can then use that same build for whatever purposes you require, such as developing, testing, staging and deployment.
Database migrations, rather than simple builds, suddenly become necessary when a production database system must be upgraded in-situ. You can’t just build a new version of the database: you have to preserve the data that is there, and you need to do the upgrade in a way that doesn’t disrupt the service. Migrations are useful in other cases too, for example if you need to repeatedly update development databases where the volume of test data is large enough to preclude the possibility of running frequent builds. In the deployment pipeline particularly, the released version will need to be tested with large datasets, and at this stage migrations often make more sense.
Where databases are reasonably simple, this process of modifying existing databases is very simple too: in fact the process can be automated. Where databases get more complex, and become the hub of corporate information systems, then there is more detail to check and precautions to take. Teams that delay tackling these issues until late in the development cycle find that changes build up to the point that deployments become daunting, and releases become infrequent.
This article gives an overview of some of the ways of making the migration process as painless and stress-free as possible. It discusses the mechanics of a database change process and describes the two basic approaches to managing changes (state-based versus migration-based). It offers some steps, starting with relatively straightforward improvements, which will lead towards a reliable, automated and tested database migration process, and minimize the chance of any data integrity issues in the production database.
What is a database migration?
A database migration involves changing it from one defined version to another. A migration script alters the metadata of a database, as defined by its constituent DDL creation scripts, from one database version to another, whilst preserving the data held within it. Migration scripts can be forward, or “up”, to upgrade a database to a newer version, or backward, or “down”, to downgrade to a previous version of a database. In order to promote an existing database from its current version to any other version in the VCS, we simply run, in the correct order, every “up” migration script in the set.
The migration process will use, as a starting point, the build scripts for the individual database objects held in version control. In fact, as described in the Database Builds article, a ‘build script’ is then really just a special case of a migration script that migrates the database from an empty database (as defined by model) to the required version.
The primary challenge when migrating an existing database is how to handle changes to the databases tables. The migration script must alter any table in the database that has changed while preserving data. The required change may be as simple as adding or removing a table column, or a complex refactoring task such as splitting tables or changing a column in a way that affects the data it stores. Most changes are managed by SQL Server in such a way as to preserve the data: most but not all. For example, let’s say we need to “split” the zip code portion of an address column into its own column, to facilitate searches. This would require a “3-stage” migration script, first creating the new column, then moving new data into column, then cleaning the data in the original column.
Two approaches to database migrations
There are two basic approaches to migrating databases, one based on versioning object CREATE scripts, commonly referred to as the state-based approach, and one based on storing in the VCS only the initial CREATE scripts for each object followed by a string of object change (ALTER) scripts, often referred to as the migration-based approach.
There is no fundamental difference between the two approaches. Both use migration scripts to do the work. In essence, they are distinguished by whether we consider the source of any version of a database object to be that version’s creation script, or the original creation script combined with whatever alterations to it took place to produce the current version.
The two approaches are not mutually exclusive. Tools used to migrate a database using the state-based approach occasionally need ‘help’ defining the correct route for migrations that affect existing data; i.e. it may involve hand-crafting the change scripts required for a tricky migration. Tools that use the migrations approach often need a way to “back fill” the state of each object, at each version, so that we can see easily how the object has changed over time.
State-based database migrations
When using the state-based technique, we store in the VCS the source DDL scripts to CREATE each database object. Each time we modify a database object, we commit to the VCS the latest creation script for that object. In other words, we are versioning the current state of each object in the database.
We then derive a migration script based on a comparison between the static definition of the database in version control (the object DDL scripts) and the target database. We will need to automate the generation of this migration script, often referred to as an automated synchronization script. Generally, we will generate this script dynamically using a schema comparison engine (discussed in more detail later) and then a developer or DBA will need to check it, and perhaps edit it to deal with any tricky data migrations.
Sometimes it is impossible for a tool to create a synchronization script that will preserve the data correctly. Although it knows what the initial and final versions of the database look like, there is sometimes ambiguity regarding the correct transition path. For example, if we rename a table, the tool is likely to miss the fact and simply drop the existing table and create the one with the new name, thereby failing to preserve the data under the newly-named table. Of course, there are other changes, such as splitting or merging columns or changing the data type or size of a column where the tool may not have enough information to be certain of where the data should go.
These situations require human intervention. We may need to manually alter the synchronization script to cope with difficult migration problems, and define manually additional change scripts that describe how existing data should be migrated between versions of the database: However, some automation tools now make handling this much easier than in the past.
With each code-based object in the database, we can simply store in the VCS a script that deletes the current object, if it exists, and re-creates the changed object. However, with this approach we need to reset permissions on the object each time. A better approach is to store in the VCS a script that create the object only if it doesn’t exist, and alter it otherwise, so that existing permissions on that object are retained (although under the covers, the objects is still dropped and recreated).
Change script-based migrations
This technique migrates a database by means of one or more change scripts. Any DDL script that alters one or more existing database objects is a change script. For each migration between consecutive database versions, we need to store in version control the initial build scripts, plus change scripts that describe precisely the steps required to perform the necessary changes to migrate to the required database version. For table changes that involve data migrations, the object change scripts include extra logic that defines how existing data is migrated between changes in the organization of tables. We adopt the same change script-based strategy for tables and code objects, which is useful, but arguably this approach is redundant for code objects that don’t hold data and are entirely overwritten on every change.
SQL-based versus code-based migrations
This discussion assumes we store SQL change scripts in the VCS. However, some tools use code-based migrations, which define the required database changes in the application code language, such as Java, C#, or Ruby. We’ll cover a few of these tools, briefly, a little later.
Whether you need to move a database from one version to another or build a database, you can use a tool that builds the migration script from a series of change scripts. It does this merely by applying this set of immutable change scripts to the target database in a pre-defined order.
Often the order of execution of the SQL scripts will be determined by the file naming, for example using sequential numbers at the start of the name (00000_2015-11-14_CreateDatabase.sql, 00001_2015-11-14_CreateTableOrders.sql and so on) so that it is simple to determine the order in which they need to be run. An alternative scheme uses the date and time at which the script was generated to create a script sequence that still has ordering but does not need sequential integers, for example 20151114100523_CreateDatabase.sql, where the ordering is defined by a concatenation of year, month, day, hour, minute, and second in 24-hour format. The latter scheme works better with source code branching because the ID number is not needed prior to the script being created. However, the ordering is more difficult for humans to read, and there is a chance that migrations may merge fine technically but not achieve the desired intent (just as with any code merge).
A change script-based approach generally rely on a metadata table held in the database itself that captures the database version and keeps tracks of which scripts have been run for that version. At the least, it stores the date of the migration, and the script version/name, but some frameworks or tools store additional information too, such as a description of the migration, the author of the script, the length of time taken to run the script, or a hash of the script file contents so that any accidental changes to a script can be detected.
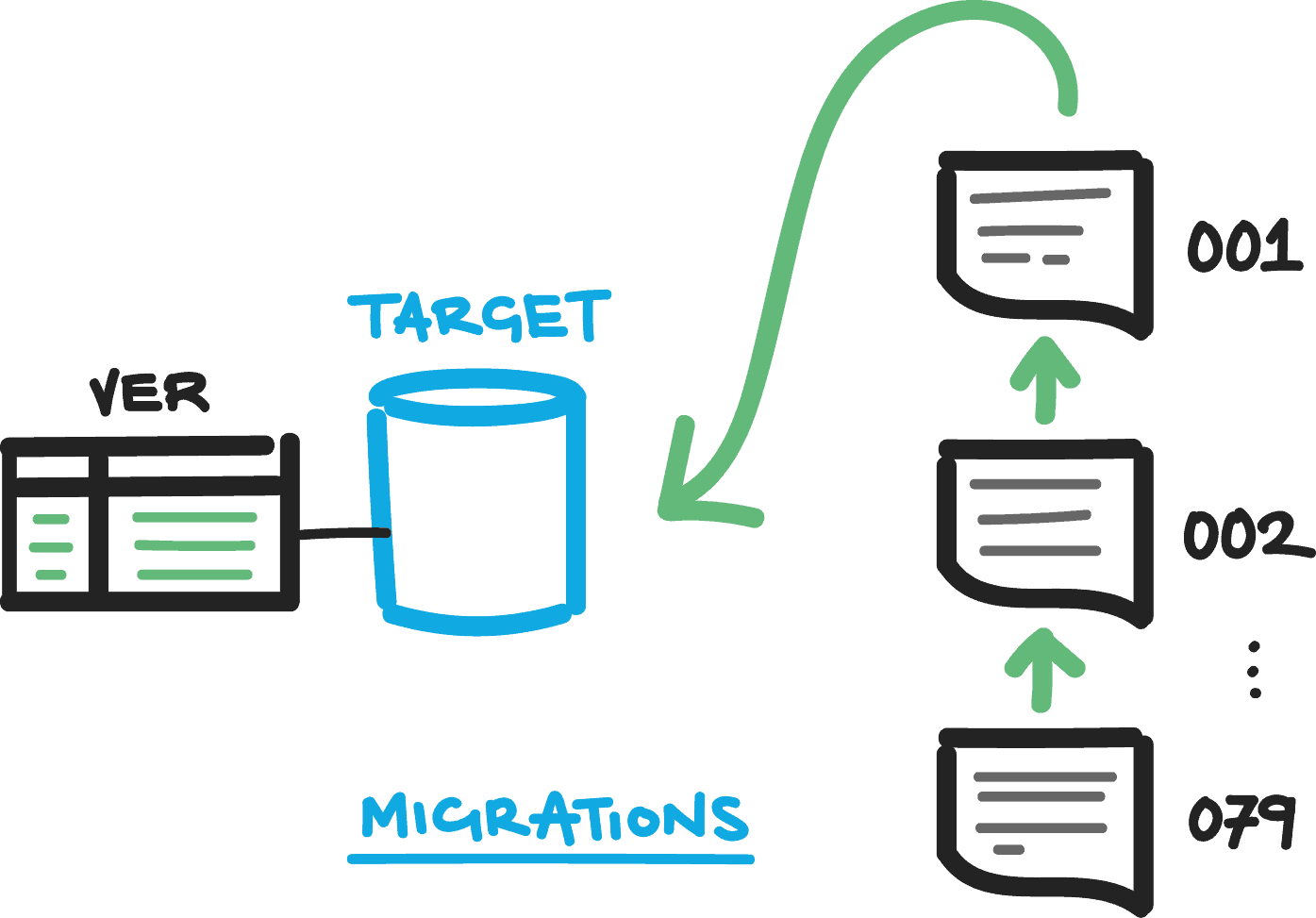
Figure 1
When running a migration, the framework or tool checks to see which script was last run by accessing the metadata version table, and then runs only those scripts that are numbered sequentially after that version. The versioning metadata also provides traceability for database changes, which can be essential for regulated industries such as banking, finance, or healthcare.
Choosing a DLM change automation approach
Which approach you choose will depend on a number of factors, such as how well either approach integrates with your existing approach to deploying application changes, and how frequently the team make significant changes to the initial design of the base tables, as well as others relating to the team’s capabilities, and overall approach to database development.
As discussed earlier, the approaches are neither fundamentally different nor mutually exclusive. While a single, unified approach is usually preferable, a team or organization may need more than one approach for different parts of the system or at different times in development. With the right tools, either is viable.
We’ll discuss just a few of the technical factors that may influence your choice of approach, but there are other factors to consider too, such as team discipline and collaboration. For example, a change script-based approach that works well with a single team or two closely-related, highly-collaborative teams might prove unworkable with three geographically dispersed teams that belong to different organizations that cannot collaborate as effectively.
Frequency of significant database changes
The state-based approach works very well if the team starts development with a robust entity-relationship design, with relatively minor tweaks during development. In projects with frequent release cycles, but where the team’s understanding of the data domain continues to evolve even after the first deployment to production, it’s likely that significant database changes will frequently form part of database migrations. In such cases, the state-based approach can begin to feel like a disjointed approach in development projects where many of the required database changes require custom change scripts.
If the team makes frequent, significant changes to tables as they gain an understanding of the data, then the change script-based approach is likely to be a better fit, since it allows the team to exert granular control over all database modifications, providing we have tools to support and automate the process of constructing, tracking, and executing correctly the individual object change scripts.
If the migration scripts are tested frequently, the development team gets closer to the goal of have “push button” database deployments to production, or at least directly to staging prior to final checks, from “a bunch of change scripts”.
Bear in mind though that if every change must be reflected in a new script, since existing scripts are immutable, then if you make a mistake, you must write a script to undo it, then write a script to do it again, the right way. As a result, your database change process is doomed to repeat every “wrong turn”.
For a large, frequently changed databases you may end up with a vast number of individual object change scripts that may need to be run. Some change script-based tools, such as ReadyRoll (covered later), recognize that some teams, at certain points, would like to “rebase” and simply have the tool auto-generate a change script that effectively makes redundant all the separate object change scripts.
Visibility into database state
Having a well-documented build script in the VCS for every object makes it very easy for the team to see the exact state of an object at any given time, and to understand how changes to that object are likely to affect other objects. This is arguably one of the biggest advantage of a state-based approach to database migrations. Having the latest state of the database schema in version control, in the form of the latest set of object-level scripts, is also a natural fit for the standard version control processes that provide the audited history of changes
By contrast, the change script approach is not such a natural fit for standard source control processes. If every table change is a new immutable script then there is effectively nothing to “version”. However, it does allow very granular control over every change.
Some teams attempt a “best of both” approach, maintaining both the current state of each object, and the required sets of change scripts to move between database versions. The obvious danger with this approach is that we now have two points of truth, and the very real possibility that they will become out-of-sync. What if creating an object according to the latest CREATE script doesn’t give the same result as running the specified set of ALTER scripts on the existing build? The obvious way of getting around this is to do the initial build by the sequence of change scripts and then scripting out the objects individually into source control. SMO provides an easy way to do this via scripts but it is tricky to get this completely accurate. Some migration tools will do this automatically for you.
We can check accuracy of this ‘back-fill’ process by upgrading a target database by the migrations approach, using a set of change scripts, and then using a schema-comparison engine, such as Redgate SQL Compare, to compare the resulting database to the set of object-level scripts in version control. If they are the same, then the build or migration is valid and there is no drift.
Support for branching and merging
As discussed in the Database Version Control article, the DLM approach advocates that the development team avoid using branches in version control wherever possible, and try to keep those branches that are required short lived.
Nevertheless, many teams rely on branching strategies to streamline their development and release activities and, generally, the state-based approach tends to be a better fit. When we are versioning the object DDL scripts, and developers make conflicting changes to the same object, in different branches, then the subsequent merge attempt will raise the conflict and the team can deal with it.
With the change script approach, and every change is a new script, there is a very real chance that one developer will simply overwrite another’s changes. If you are maintaining multiple are using branches, the team faces the prospect of dealing painstakingly going through every script, line by line, to work out the order that they need to run in or if there are conflicts. With a migrations-based strategy, team discipline is exceptionally important and managing the order of upgrade scripts is a very important task.
From ‘chaotic’ to ‘optimized’ database migrations
In organizations where the approach to database change is essentially ‘chaotic’, the database release process swill often consist of the development team depositing a ‘bunch of scripts’ in a folder shortly before they wish to deploy. This is the ‘throw it over the wall’ approach to database releases.
The scripts will likely be ‘metadata’ scripts, describing only the required changes to the database tables and programmable objects. As discussed previously, the migration script may take the form of a list on individual object change scripts, or an auto-created transactional synchronization script to update the existing database, from the source object scripts.
In either case, there are likely to be places where radical table modifications require hand-crafted migrations scripts. It can take the operations team many days to craft migration scripts that they are confident will preserve existing production data exactly as intended, won’t cause instability in their production systems, and fail gracefully and roll back if a problem occurs. It all has to be written and tested, it all takes time, and it can delay delivery of functionality to the business.
If the development team has a justifiable need to put changes into production (or at least staging) frequently and rapidly, then this system is no longer appropriate.
The answer is either to deploy less frequently, or push responsibility for data preservation in the migration scripts down into the development team. It might be a daunting prospect for a DBA to cede control of database modifications, as part of a new deployment, to the development team. After all, the DBA is responsible for the preservation of the existing production data, and for and data integrity issues or service disruption caused if things go wrong. Indeed, it is only likely to be successful an automated DLM approach to database change, undertaken with close collaboration between development and operations team, according to the ‘DevOps’ model.
This has several implications. It means that the development must grasp the nettle of Database Continuous Integration in order to test these migrations sufficiently before they get anywhere near release. It means that the development team would have to perform tests that prove that the migration scripts work, while the system was working with a realistic data and load. It means that many governance checks will need to be done in parallel with development, rather than by sticking with the familiar chaotic procession down the deployment pipeline. The whole process will need to be instrumented, as discussed for the build process, so that the team tracks all the information required in order to spot problems quickly and continuously improve the process.
The following sections suggest some “staged” improvements you can make to your database change management processes.
Ensure scripts are idempotent
Every migration or change script should be idempotent; it should have no additional effect if run more than once on the same database. A migration script takes you from one version of a database to another, however many times it is run.
A standard database scripting practice is to include ‘guard clauses‘ that prevent a change script making changes if it doesn’t need to be or can’t be run, or to abort a script if it determines that it has already been run, or to perform different logic depending on the database context. Alternatively, some automation tools will ensure that a migration script is not run more than once on a given database version.
Ensure scripts are immutable
A migration, or change, script is immutable. Once it has been written, tested, and any bugs fixed we should very rarely change it. Instead, we add extra scripts to perform schema changes or data updates.
Often a migration script needs to resolve tricky data migration issues. If a script is never changed once it has been run successfully and has been proven to work then we only need to solve each data migration problem once, and we can then run exactly the same set of migration scripts should be run on every server environment that requires the same changes.
This helps to ensure that we can upgrade any database ‘in the wild’ without needing to inspect it first. As long as the database objects have been changed only via the migration tools, it is safe to run the migration scripts against it.
Guard against database drift
A migration script is valid only for the database versions for which it was intended. Before we run any database migration, we need to be sure both that the source represents the correct database version, and that the database after the migration is at the expected version. In other words, the database migration process must check, before it does any modification, that the database is really at the correct version and that no ‘uncontrolled’ changes have caused the version to ‘drift’.
If the target is at a known version, but not the version we anticipated, then we need to use a different change script, or set of change scripts. If the target is in an unknown state, then it has been altered outside of the final change process; this is known as database drift. If we run the migration regardless, it may delete the “out-of-process” change so that the work may be irretrievably be lost. If this is a risk, then this is time for the anomaly to be investigated: otherwise the migration should go ahead and obliterate the drift.
Many teams, regardless of whether they adopt a state- or change script-based approach to database changes, will often use a state-based comparison tool for database drift detection, giving the team early warning of unrecognized changes to databases in different environments. The comparison tool keeps track of a set of known database states (or versions, assuming every known state is given a version), and periodically checks that the target databases match one of the known states.
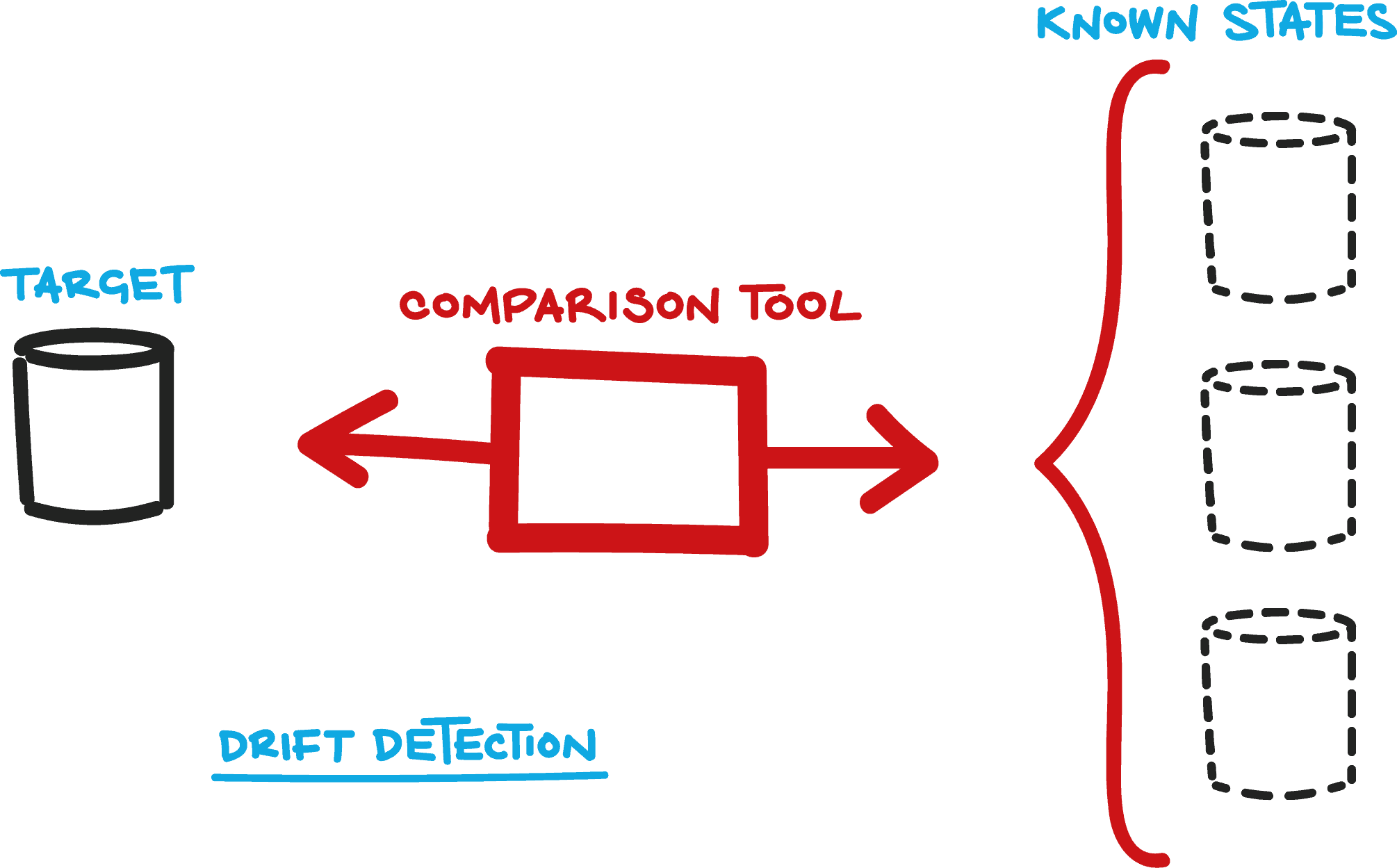
Figure 2
State-based tools typically check the database state in every environment before applying changes. For situations where database changes are applied in several different or even haphazard ways, state-based tools provide a high degree of confidence that database changes will be executed correctly, even when the nature and source of the changes are unknown or unpredictable.
Perform early and frequent testing
We need to write integration tests during development in order to check that the migration scripts worked exactly as intended, and the final database state, including the data, is exactly as we expected. The development team, ideally, need access to a ‘production parallel’ environment, often cloud-based, where they can perform these tests with realistic, ‘production like’ data, and under realistic data access loads. See the Database Continuous Integration and Database Testing articles for further discussion.
Fail Gracefully
A DLM change process must never result in a “partial” build or migration if something goes wrong. We need to be able to revert to the starting version if an error occurs during the migration process, or to revert to a previous version if the error becomes apparent after the migration. Any DDL change can be run in a transaction. This means that, with correct handling of errors within the transaction, the script can be rolled back, leaving no trace. Some tools are able to generate a migration script that handles this properly.
There is really no satisfactory alternative to this technique. It is possible to create a script that checks for the existence of any of the alterations and ‘undoes’ them, but this is difficult to do and generally only appropriate in an emergency once the transaction within which the migration script has run has been committed. Generally, DBAs prefer to ‘roll-forward’ a failed migration by a hand-cut script.
Introduce governance checks early in the cycle
Databases are ‘migrated’ from one version to another for a wide variety of reasons, and so governance will have a wide range of interest in the process for many different reasons.
A change script-based approach is generally a concern for governance unless the state of each database object can be recorded for each release. There needs to be a record of when each change was made and why. In a change script-based approach, each change usually has its own script but the context of the object is difficult to work out from this. A change of a datatype will only record the new type in the migration, not the old one. An auditor needs to be able to see quickly the extent of the changes between two consecutive changes in order to check that the changes have no implications for audit. A data expert may need to check the context of a database under development to determine how it fits into the company’s master data ‘file’ or model. A project manager will need to determine from a release whether the progress of a development is going according to plan.
Assuming we’ve enforced immutability of a migration script, it will be used for all migrations between the two versions for which it was designed. This means that whatever method of reporting it uses to record the date of migration, the name of the server, and whether it was successful, should be applicable to all contexts in which the script is used.
A brief review of automation tools for database migrations
Regardless of whether you prefer change-script based or state-based database migrations, making database changes can at times be risky and error prone, unless the processes are well-controlled and automated. Thankfully, there is growing range of software tools we can use to help automate the deployment and testing of database changes, regardless of whether we opt for a state-based or change script-based approach.
Automating state-based database migrations
It is a hard task to construct a migration script manually, based on a comparison between the object DDL scripts in source control and the target database. We would need to tackle all the issues of building new objects in the correct dependency order, as described in the Better Ways to Build a Database article, plus the need to preserve data. Your only real option if using a manual approach based on object-level scripts, may be to take the database offline, read out all the data, via for example Bulk Copy Program (BCP), build the new database version, and read all the data back in. However, this is only viable for small databases, and manual migration techniques quickly become laborious as the size and complexity of the database increases, and as more people become involved in the task.
A DLM approach requires automation of this process and most teams use a schema comparison tool to do this job for them. The comparison engine will inspect the target database and the source DDL scripts and packages in the VCS, compare the two, and auto-generate a synchronization script that will ALTER a target database at version x and changes it to version y, whilst updating the living database definition and preserving existing data. The comparison tool can run this change script against the target database to make the required changes. The comparison tools generally have various options for excluding or including different kinds of database objects (procedures, functions, tables, views, and so on) and some have support for data comparisons, allowing new reference data (such as store locations or product codes) to be updated in the target database.
While this migration process still relies on the object-level DDL scripts in the VCS as the “source of truth”, the team needs to test and archive every auto-generated migration script that has been used to build a database in this way.
There are now a range of tools and frameworks that use the state-based approach to DLM changes. We’re only going to cover a few of these automation tools in any detail, but also provide a section that lists out other candidates.
Redgate
Redgate provides a variety of tools for SQL Server, Oracle and MySQL, aimed at database change and deployment automation, including SQL Source Control, SQL CI (for automated testing), SQL Release (for release control via OctopusDeploy), and DLM Dashboard (for tracking database changes through environments).
SQL Compare, the comparison engine behind these tools sniffs out your directory of object scripts, including all subdirectories, parses what it finds and creates an internal model (network graph). It takes the scripts in any order. It compares this internal representation with the database, backup or script directory. What emerges from all this work is a change script that is not only in the correct dependency order, but is also transactional, so it doesn’t leave bits of a failed migration in place, and builds the objects. To avoid the possibility of creating circular dependencies, it delays enabling constraints when necessary.
The SQL Source Control tool is able to handle the use of migration scripts where the correct transition can’t be determined. It allows custom change scripts to be substituted for the auto-generated migration script, at the object level. The system checks whether there is a custom change script for relevant database object(s) to convert from one version to another, within the range of the migration being undertaken, and if so, this over-rides the automatic script at that point. This facility has been in the product for some time but has recently been thoroughly re-engineered to make it robust enough to handle all known requirements.
Microsoft SQL Server Data Tools (SSDT)
SSDT is Microsoft’s declarative approach to database change automation. SSDT is aimed at Developers using Visual Studio, and has tight integration with other Microsoft tooling, particularly tools for Business Intelligence (BI). Some teams successfully use SSDT in combination other tools (Redgate, tSQLt, etc.) where SSDT lacks features (such as reference data management).
SSDT uses Microsoft’s DacFx technology, and DacPacs, to auto-generate database change scripts. Unfortunately DacFx and DacPacs can’t help much with the problem of migrating a database automatically from object level scripts, because you have to append change scripts to the DacPacs in the correct dependency order.
DacPacs produce a SQLCMD change script, which accepts parameter to provide values for such properties as the location of the database files on the target server. DacPacs can’t compare a database to the scripts in the VCS.
Altova Database Spy
Altova Database Spy provides a database schema comparison tool that can produce SQL ALTER scripts to synchronize one database from another and save database comparisons for later use. There is also a tool for data comparison and merging.
The tools support a wide range of databases, including SQL Server 2000 to 2014, PostgreSQL 8 to 9.4, Oracle 9i to 12c, DB2, and Sybase.
DBMaestro
DBMaestro provides tools for SQL Server and Oracle, with a strong focus on policy enforcement.
Devart dbForge
dbForge from Devart supports SQL Server, MySQL, Oracle, and PostgreSQL databases. It provides the ability to compare both schema differences and data differences and has command-line interface for automation.
Others
- ApexSQL: http://www.apexsql.com/sql_tools_diff.aspx
- Datanamic: http://www.datanamic.com/datadiff-crossdb/index.html
- DBArtisan: http://www.embarcadero.com/products/dbartisan
- DBComparer: http://dbcomparer.com/
- OpenDBDiff: https://opendbiff.codeplex.com/
- SQLDelta: https://www.sqldelta.com/
Automating change script-based database migrations
For small or simple databases, a ‘hand-rolled’ solution can work well enough: the very first script sets up the metadata versioning table in the blank database, and early subsequent scripts build out the schema and add static/reference data. With a hand-rolled approach you have the complete confidence that you are in full control of the SQL scripts and therefore the database.
However, as the database grows in complexity or other colleagues or teams need to change the database, it can be useful to adopt a tool to help with some of the heavy lifting. In particular, tools will tend to have solved most of the tricky migration activities and in particular the logic associated with the migrations mechanism itself (that is, the checking of the metadata version table and working out which migration scripts to run).
The following sections describe briefly some common database migration tools and frameworks, all of which use SQL change scripts.
DbDeploy
DbDeploy is a veteran, well-tested database migration tool used in much commercial and open source software. DbDeploy has versions for Java, PHP, and .NET.
Flyway
Flyway is an open-source database migration tool that strongly favors simplicity and convention over configuration. Flyway has APIs for both Java and Android and several command-line clients (for Windows, Mac OSX, and Linux). Flyway uses ‘plain’ SQL files for migrations, and also has an API for hooking in Java-based and custom migrations. Notably, Flyway has support for a wide range of databases, including SQL Server, SQL Azure, MySQL, MariaDB, PostgreSQL, Oracle, DB2 and others.
Liquibase
Liquibase is a database migrations tool that has strong support for multi-author changes and branching, and targets a wide range of databases including MySQL, Oracle, SQL Server, DB2 and H2. Liquibase migrations can be defined in SQL, XML, YAML, or JSON, and has tools that generate SQL scripts in order to address some of the ‘people and process’ complexities of DLM. Liquibase also has explicit support for SOX-compliant database changes via automatically- or manually-generated rollback statements.
MyBatis
The MyBatis migrations framework draws on the techniques of both Rails Migrations and dbdeploy.
ReadyRoll
ReadyRoll offers a pragmatic workflow for making database changes that combines ‘online’ database changes (making changes directly to a database) with sequential SQL scripts. This makes it particularly suitable for working with existing databases that may not have been created programmatically and also for working in mixed teams of DBAs and developers, where some people may make changes directly in databases and others may write SQL scripts.
ReadyRoll inspects online databases and generates sequential scripts via a sync tool, using version control diff and merge, and the experience of DBAs and developers, to determine which changes to merge and how.
It also supports a feature called Offline Schema Model will “back fill” the object scripts for a database version, to enable you to audit of changes to your database objects
Automating code-based migrations
Whereas SQL-based migrations use native SQL code to define and control database changes, code-based migrations define the required database migrations in the application code language, such as Java, C#, or Ruby. Tools that automate code-based migrations will often generate the SQL code automatically from the annotated Java/C#/Ruby code. This makes code-based migrations more natural for many software developers although less accessible to DBAs who are less familiar with these languages.
Example automation tools:
- ActiveRecord Migrations – a Ruby migrations framework works with the Ruby implementation of Martin Fowler Active Record data access pattern. Note that ‘the Active Record way claims that intelligence belongs in your models, not in the database so migration frameworks based on Active Record are likely to be unsuitable for situations where referential integrity needs to be maintained by the database.
- Entity Framework – Migrations are written in C# and can be exported as SQL for review by a DBA. Starting with EF6, the EF Code-first Migrations generate idempotent scripts, making them safer to run in different environments
- FluentMigrator – an open-source .NET database migrations framework with support for many different databases. Installation is via a NuGet package, and migrations are written in C#. Each migration is explicitly annotated with an integer indicating the order in which the migrations are to be run. There are several ways to run the migration scripts, including command-line, NAnt, Rake, and MSBuild, which makes for useful flexibility in testing and deploying using FluentMigrator.
- Phinx -a database migrations framework for PHP with support for MySQL, PostgreSQL, SQL Server and SQLite.
Advanced Database migration considerations
As for database builds, there are many choices to be made as to how database migrations proceed in case of various eventualities. Here are just some of them.
Should the database be backed-up before the update is made?
If a migration is done as part of a deployment process, then a number of precautions need to be taken. A database backup is an obvious backstop-precaution, though if a deployment goes wrong, the restore-time can be significant. However, many people have been grateful that the precaution was taken when a deployment has gone badly wrong.
Can we stop users accessing the database during the upgrade?
We may require non-breaking online deployments, but these will risk locking and blocking on large tables (for example, a table column ALTER is likely to lock the entire table). Some migrations need the application(s) that uses the database to be quiesced, or need the database to be in single-user mode, and so the script will need to check whether this has happened before they proceed.
Do we alter Change Data Capture objects when we update the database?
Change Data Capture involves capturing any changes to the data in a table by using an asynchronous process that reads the transaction log and has a low impact on the system. Any object that has change data capture requires sysadmin role to alter it via a DDL operation.
Do we drop existing constraints, DDL Triggers, indexes, permissions, roles or extended properties in the target database if they aren’t defined in the build?
Where operations teams are maintaining a production system, they may make changes that are not put into development source control. This can happen legitimately. Normally, changes to indexes or extended properties should filter back to development version control, but in a financial, government or healthcare system, or a trading system with personal information, there must be separation of duties, meaning that database permissions, for example have to be administered by a separate IT role, and the source stored separately in a Configuration management system. To apply a migration to a target database that has separation of duties, permissions and role membership has to be ignored. DDL Triggers that are used for audit purposes are sometimes used to monitor unauthorized alterations of DDL, and so obviously cannot be part of development source control. In this case, the migration scripts need to ignore certain types of objects if they are outside the scope of development
How do we deal with NOT NULL columns for which no default value is supplied?
If the migration involves updating a table that contains data with a column that does not allow NULL values, and you specify no column default, should the build provide a default to make existing null data valid?
Developers sometimes forget that, if they are changing a NULL-able column to a NOT NULL-able constraint, all existing rows with a NULL in that column will be invalid and cause the build to fail. Sometimes a build that succeeds with development data then fails when the build is used to deploy the version to production. Of course, the code needs to be altered to add a DEFAULT to a non-null value to accommodate any rogue rows. However, some developers want the build to do this for them!
Summary
Databases come in all shapes, sizes and requirements, and so too should the way we deploy these changes. Database builds and migrations aren’t necessarily complicated, but merely reflect the complexity of the database.
Whether you choose a state-based or change script-based approach to managing database upgrades, you will end up using a migration script. A development team using a change script-based approach, sees the change scripts that make up the migration as the canonical source of the database, whereas the team using the state-based approach sees the CREATE scripts in version control as the canonical source, and uses them to derive the migration script.

DevOps, Continuous Delivery & Database Lifecycle Management
Go to the Simple Talk library to find more articles, or visit www.red-gate.com/solutions for more information on the benefits of extending DevOps practices to SQL Server databases.
Load comments