

DevOps, Continuous Delivery & Database Lifecycle Management
Automated Deployment
Whatever method you use to develop a database, it is important to build it regularly from the DDL scripts and other materials in version-control. It checks that any version can actually be built successfully, highlights potential difficulties before they become problems, and prevents work being lost.
The need to perform regular builds means that it needs to be made as easy to as possible to do, so that it becomes a routine part of the workflow. For a simple database, this build process is trivial; but it gets trickier to get right as the database gets more complex.
In this article, we’ll explain what we mean by a database ‘build’, and then suggest how to apply DLM techniques to make it automated, predictable and measurable. In other DLM articles, we will delve into the details of continuous integration and testing, and also explain how to release and deploy the artefact that is the end-product of the build process.
What is a database build?
In application development, we build a working application from its constituent parts, compiling it in the correct order then linking and packaging it. The ‘build process’ will do everything required to create or update the workspace for the application to run in, and manage all baselining and reporting about the build.
Similarly, the purpose of a database build is to prove that what we have in the version control system – the canonical source – can successfully build a database from scratch. The build process aims to create from its constituent DDL creation scripts and other components, in the version control repository, a working database to a particular version. It will create a new database, create its objects, and load any static, reference or lookup data.
Since we’re creating an entirely new database, a database build will not attempt to retain the existing database or its data. In fact, many build processes will fail, by design, if a database of the same name already exists in the target environment, rather than risk an IF EXISTS...DROP DATABASE command running on the wrong server!
Builds versus migrations
In environments such as Production, Staging or User Acceptance Testing (UAT), teams sometimes use the term ‘the build’ more generically, to mean ” the artefact that will establish the required version of the database in that environment“. Unless the database doesn’t already exist, ‘the build’ in these environments is in fact a migration, and will modify the existing database to the required version, while preserve existing data, rather than “tear down and start again”. We focus only on building a database in this article. We cover modification of existing databases in the article, DLM for Database Migrations.
A database is likely to be built many times during the development and testing process. Once it’s been tested fully, in development, we should be able to use the same build process on all environments, assuming we’ve separated environmental dependencies from the build script itself (more on this shortly).
A significant build is the one that produces the release candidate, and a subsequent deployment involves the same build process, but with extra stages, for example to account for the production server settings, and to integrate the production security, and incorporate production architecture that isn’t present in development, such as SQL Server replication. In fact, Microsoft refers to a build as ‘ the mechanism that creates the necessary objects for a database deployment‘. A build, per their definition, is just the act of creating a script or a DACPAC file. They then refer to the act of applying that script to the database as publishing the build.
The rapid and efficient build process is essential for some databases that are released in several variants for individual ‘customers’ or installations for any particular version. It is in these development environments that a build process that takes its source from the VCS and maintains strict ‘versioning’ comes into its own.
The purpose of the build
From the database developer’s perspective, a build provides a regular health-check for the database. During development, the build process should be automated and performed regularly, because it tells the team whether it is possible to do this with the latest version of the committed code, and keeps all the team up-to-date with the latest development version. The canonical database that results from a successful build can also be checked against other development versions to make sure that they are up-to-date, and it can be used for a variety of routine integration and performance tests.
If the build is also sufficiently instrumented (see later) then if a build breaks, or runs abnormally long, then the team need access to detailed diagnostic information and error descriptions that will allow them to identify the exact breaking change and fix it, quickly.
In a shared development environment, it is possible to avoid building the database. However, a build process that is manual and poorly tested will inevitably lead to delayed and unreliable database deployments. The database build process becomes a bottleneck for all downline deployment processes, and deploying the application must wait while the manual steps required for the database build are navigated. In addition, because these processes are likely to be manual, they are much more error-prone. This means that the application deployment is waiting on a database deployment that may not even be correct when it eventually gets finished.
A database build process that breaks frequently, and causes subsequent downstream problems with a database deployment, will knock the confidence of the other IT teams, perhaps to the point that they request that the development team perform less frequent releases, until all the database build issues are resolved. Unreliable database build processes (as well as unreliable migration processes) can prevent the applications that use the database from delivering new functionality quickly enough.
Database Lifecycle Management cannot be done effectively unless you get your database builds under control within the development environment. Conversely, if automated builds run regularly and smoothly then, assuming all necessary database and server-level objects have been accounted for in the build, the team will be confident that little can go awry when it is shepherded through the release process to deployment.
The mechanics of a database build
The database build mechanism will need to pull from the version control system the correct version of all necessary components. This will most often include the scripts to build all schema-scoped objects such as tables, stored procedures, functions, views, aggregates, synonyms, queues. It will also need to load any necessary ‘static’ data.
A common way to represent the database in version control is as a set of individual object scripts. It is usually a convenient way of versioning a database system because you get a useful and easily-accessed history of changes to each object, and is the most reliable way of ensuring that two people do not unintentionally work on the same set of objects. It is, however, not the only legitimate way of storing the source of a database in a version-control system.
In fact, when building many databases, you are unlikely to want to create every table separately, via CREATE statements. A small-scale database can be built from a single script file. If you prefer, you can script out each schema separately. For larger, more complex databases, where it becomes more important for the team to be able to see the current state of any given object, at any time, you’ll probably be versioning object-level DDL scripts.
Scripting the database objects
Many databases can be built solely from scripts that create the schemas, database roles, tables, views, procedures, functions and triggers. However, there are over fifty potential types of database objects in SQL Server that can form part of a build. The vast majority are scriptable.
Tables are by far the most complex of scriptable components of a database and they provide the most grief for the developer. In SQL Server, tables are represented as objects but the schema that it resides in isn’t. A table’s constituent parts are child objects or properties in a slightly confusing hierarchy.
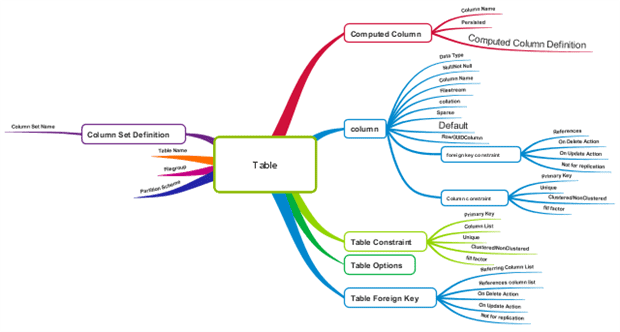
Figure 1: Properties of a database table
Tables can be built in one step with a CREATE TABLE statement or can be assembled from the initial CREATE TABLE statement and decorated subsequently with columns, constraints, FOREIGN KEY constraints, by using ALTER TABLE statements. Without a doubt, table scripts are best written in the former table-level way rather than the latter method of treating the child objects and properties in their own right. It is clearer to read, and shows in one view what has changed between versions of the table. It gives a much more concise history of the changes.
Scripting server-based objects
It is a mistake to think that by storing the database objects in source control and building those that you have the entire database. Some components aren’t actually stored in the database. If they are used, they may be at server level, and or in SQL Agent. If these server objects, such as database mail profiles, logins, SQL Agent jobs and alerts, schedules, server triggers, proxy accounts, linked servers, are required for the functioning of the database, then they must be held as SQL Scripts in the development VCS and built with the database.
Some server-based objects are associated with the database application but need entirely different scripts for each server environment. Operators, the contact details of the person who is alerted when a database goes wrong, are a simple example of this type of script. As we prepare to deploy the database to production, the same build process must be able to define the appropriate operator in each environment, whether it be development, test, integration, staging or production.
SQL Server Management Objects (SMO) exposes server-level objects through the Server and JobServer classes, and we can create a PowerShell script, for example, to iterate over all of the various collections of this class, containing the jobs and alerts and other server objects, along with associated operators, schedules and so on. The example shown in this article scripts out these objects into a directory named according to the server name.
In many organizations, scripts for these server objects are likely to be stored in a separate version control system under the control of the operational or production DBA staff, on the central management server. In many cases, they are not typically put into any development scripts for production. As such, the specifics of dealing with these server objects during a subsequent deployment will be saved for the Database Release and Deployment article.
However, a DLM approach to database builds requires that the development environment mimic production as closely as possible (more on this shortly), and of early and frequent collaboration between development, governance and operations teams, in order to avoid as far as possible build difficulties arising from differences between server environments.
The build scripts
A database build process should be about as complex as the database system it needs to create. For a small database, a single build script can encompass the entire database. As a database increases in size, the scope can be decreased first to the schema level, and finally to the object level.
To be productive, you will probably use a variety of tools and techniques. If you use an Entity-Relationship diagramming tool, such as the table-design tool in SSMS, or one of a plethora of other table designing tools on the market, to design the database then you can make the ‘first-cut’ by generating the table-creation scripts directly from the tool.
However, remember that is then the developer’s responsibility to subsequently edit that ‘generated’ script to ensure that the script conforms to the house style and standards, and is commented adequately to ensure the whole team understand the purpose of each object. It is a bad idea to make a habit of reverse-engineering the source-code of an object from your development server to store in the VCS. For example, a table may be altered slightly by a diagramming tool as part of a wider re-engineering task. Would you over-write the easily-understood, carefully-documented and hand-crafted table script with a generated script to update it, and lose all that extra information? The answer is probably ‘never’.
In addition to using diagramming tools and other visual tools, you will probably ‘hand-cut’ tables from raw CREATE statements, and will probably over time develop and reuse ‘boiler-plate’ designs for handling common functionality such as “Names and Addresses”. You have plenty of freedom and more options than you’d wish for.
Single script builds
If your database comprises just a handful of tables and a few views and stored procedures, there is no need for a complicated build process using object-level DDL scripts. You can just save in the VSC a single build script that creates the database, and then all tables and code objects, and loads any necessary data. This script will incorporate referential integrity constraints so there are no concerns over dependency order.
To create the ‘first cut’ of a database, in version control, you may consider generating the build script from a live development database, using a database diagramming tool, or SSMS, or via a Server Management Objects (SMO) script. You can then use a tool such as SQLCMD or PowerShell to run the script on all required environments, assuming you’ve separate out environmental dependencies, such as database configuration properties, security settings, such as database roles, and so on. Using a tool like SQLCMD, we can use variables for properties like database file locations, and the correct value for a given environment will be read in from a separate file.
Schema-level builds
SQL Server works naturally at the level of the schema. Developers that use a login that is restricted to the schema that they are working on will see only those schema objects and their scripts will contain only those objects. To make this work properly, they will only access scripts on other schemas via an interface, consisting of a view, procedure or function. These scripts can be hand-cut, and this is customary at the later stages in development. In the earlier stages, where developers are using GUI tools such as ER Diagramming utilities, the build script can usually be created via an SMO script or via the SSMS GUI.
Object-level builds
Eventually, a database will grow to the size that only object-level scripting is feasible. Normally, this is only required for the schema-bound objects such as tables, functions, views and procedures. Other database objects such as XML Schema collections, schemas and service broker objects can be placed together in one script per object type. There are many PowerShell-based scripts that can be used to create object-level scripts for the first time if the database was formerly saved to the VCS at database or schema level, or if the database was initially ‘cut’ from an ER Diagramming tool. You can also script it each object using any good database comparison tool that compares the live development database as source against the model database on the same server.
The build process
Whatever level of build script is most suitable for the stage of database development, it is always best to store the source in a VCS archive. The first advantage is that it makes it easy to audit the change history through standard VCS mechanisms, and identify quickly who added or removed code.
The second advantage is intelligibility, because the VCS will always hold the latest build script for each object, ideally well-formatted and liberally-commented. The CREATE script for a table, for example, can be complex. There are many subordinate ‘objects’ that have no existence without the table, such as constraints, indexes, triggers and keys. A good table script is liberally sprinkled with comments, and the script defines all the subordinate objects at the same time. The table is formatted to make it more intelligible. Column constraints are created with the columns rather than trailed afterwards as ALTER TABLE afterthoughts. Table constraints are placed likewise at the table level.
Having in the VCS a well-documented build script for each object makes it very easy for the team to see the exact state of an object at any given time, and to understand how changes to that object are likely to affect other objects.
Manual builds from database object scripts
If we store individual object scripts in version control to then build a functioning database from scratch, we need to execute these scripts on the target server, in the right order.
Firstly, we run a script to create the empty database itself, and then we use that database as the context for creating the individual schemas and the objects that will reside in them, by object type and in the correct dependency order. Finally, we load any lookup (or static) data used by the application. We may even load some operational data, if required. There are other scripts to consider too, such as those to create database roles, which will be mapped against users separately for each environment, as well as those to set-up server-level objects and properties, as discussed earlier.
To build all the required database objects in the right order, you can specify these individual files in a ‘manifest’ file, for example as a SQLCMD ‘manifest’ file, using the ‘ :r‘ command, and this can then be run to perform the build. A SQLCMD file can also specify the pre-build and post-build script (see later) and is kept in the VCS, and can be updated whenever a new database object is created.
The manifest is necessary because the objects must be built in the correct dependency order. SQL Server, for example, checks that any table referenced by a FOREIGN KEY actually exists. If it isn’t there at the point that you execute the CREATE statement, then the build breaks. The safe order of building tables isn’t easy to determine and it is even possible to create circular dependencies that will defeat any object-level build. There are ways around this difficulty such as:
- Put the
FOREIGNKEYconstraints in the VCS separately and then execute these after the tables are created. - Put
FOREIGNKEYconstraints in the build script but disable them, and add a post-build script to enable them.
However, the build process can get complicated, and error prone, very quickly if you’re putting the build script together by hand. The ‘manifest’ file has to be altered whenever necessary and can become a cause of errors when the database grows in size and complexity. At that point, you will need to automate the build more comprehensively to dispense with the need for the manifest.
Automated builds from object scripts
There are tools that can automate the generation of the build script, from object-level scripts. Essentially, these tools consist of a comparison engine to determine the difference between the target database and the source files and packages in the VCS, or a source database. SQL Compare (Oracle, SQL Server and MySQL) can read a number of scripts and combine them together in the right order to create a ‘synchronization’ script that can be executed to publish a new database. In effect, a synchronization script that publishes against an entirely blank database, such as MODEL, is a build script.
The tool compares a live target database at version x with source scripts that describe the database at version y, and generates a change script to turn database version x into database version y. If your comparison tool can’t compare to the source scripts then you would still require a build of the database from the VCS at version y.
The DACPAC (SQL Server) works rather differently and requires the developers to create a logical ‘model’ of the database from scripts. It does not fix the problem of getting object-level scripts in the right order since the object model has to be built in the correct order!
Modifying existing databases
We can use essentially the same technique to create a synchronization script that that ALTERs a target database at version x and changes it to version y, while preserving existing data i.e. to perform a migration. We’ll discuss this in the article, Database Migrations: Modifying Existing Databases.
The comparison tools generally have various options for excluding or including different kinds of database objects (procedures, functions, tables, views, and so on) and some have support for data comparisons, allowing new reference data (such as store locations or product codes) to be updated in the target database.
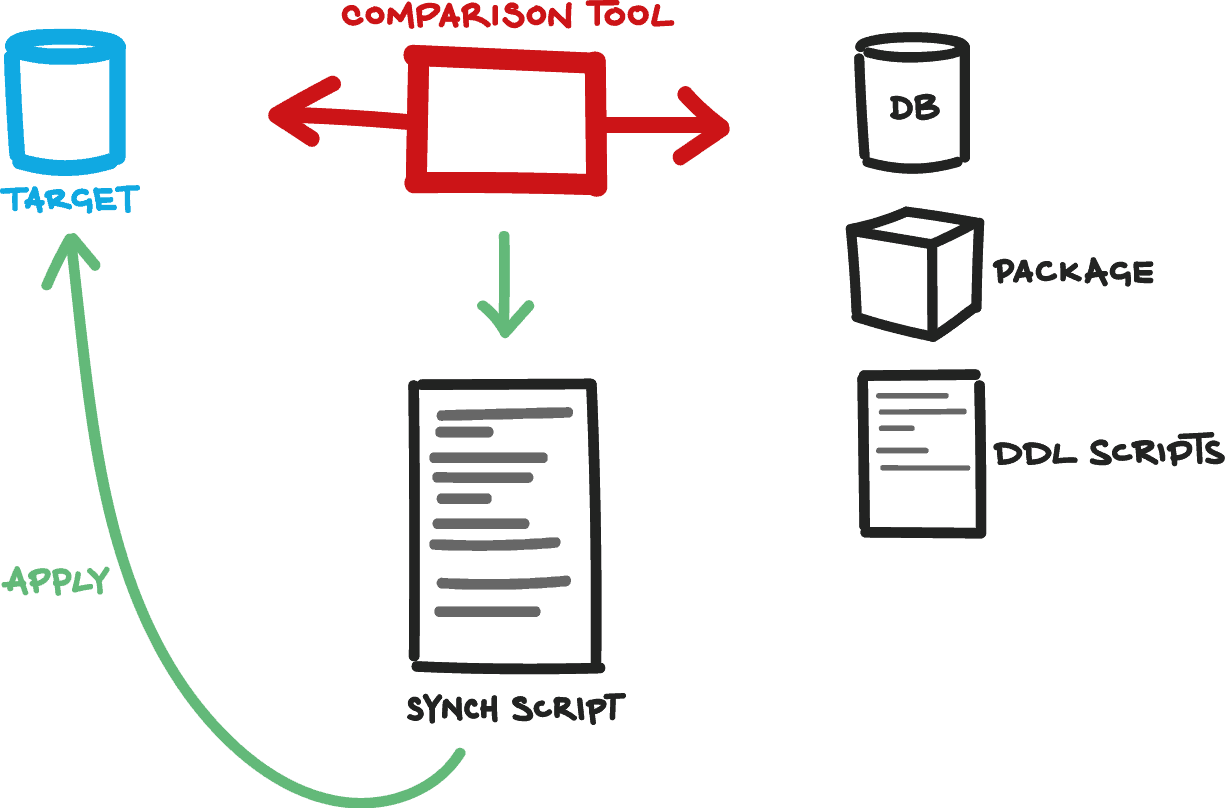
Figure 2: Auto-generating a database build script from object scripts
While this build process relies on the object-level DDL scripts in the VCS as the “source of truth”, the team needs to test and archive every synchronization script that has been used to build a database in this way, because the synchronization script is one step away from that ‘truth’.
Achieving repeatable builds
Each build script should contain any necessary logic to ensure that it is idempotent, meaning that you can run it over and over again and it will achieve the same result. You are likely to hear of different types of build script that differ mainly by the use of ‘guard clauses’ that prevent mistakes from harming data. The main types are the ‘brute force’, ‘kill and fill’ and ”idempotent’ scripts. Some build systems offer ‘transactional’ build scripts as an optional ‘extra’, so we’ll cover this type of script too.
The brute force script
The simplest build script to create the database objects will assume an empty database. It creates each object in a ‘dependency’ order that prevents references to objects that haven’t yet been built. If you accidentally run it twice, then you will get a ghastly list of errors, but no harm is done.
The kill and fill script
A slightly more complicated one is the ‘kill and fill’. Before executing the DDL script to create an object such as a table, function, procedure, view or whatever, it will check whether it already exists, and if it does it removes it. This allows you to rebuild a database regularly on the same server without the need to re-create the empty database. It has two snags. Firstly, a careless or distracted DBA can accidentally run it on a live production version of the database and thereby destroy several tables of data. Secondly, it allows you to miss out an important part of the build, which is to create the empty database with the correct configuration options.
The idempotent script
With an idempotent script, you will be unable to do any harm from running it more than once. If it finds a version of the database already there, it will check the version of the database, and refuse to run if it isn’t the same version that the script builds. If it is the same version, it will merely build any missing objects. It does not attempt anything resembling a change to an object.
The transactional script
The transactional script will attempt the process of building part or all of a database, and if it hits an error, it rolls all the successful operations back to leave the database in the state it was in before the script was executed. The build script is different from a migration in that, if any part of a build fails, the whole operation has to be completely ‘torn down’. The rollback of one component script isn’t necessary because the whole database will be dropped anyway.
However, this does not apply to server-based components or scheduled tasks which are always better done by a transactional script. Migrations (covered in a separate article) should always be transactional, otherwise the database is left in an indeterminate, and possibly non-working, state.
Handling data
Often, the build process will need to load any necessary data required for dependent applications to function, and possibly to support database testing. There are various types of, mainly immutable, data that we may need to load because it is required for the database to function, including:
- reference data – data that refers to relatively unchanging data such as information about countries, currencies or measurements
- static data – usually a synonym for reference data
- enumerations – short narrow tables that represents sets of unchanging entities
- seed data – data that is required to initialize a hierarchical table with the root of the hierarchy
- domain data – data that defines the business domain and which will not change in the lifetime of this version of the database
- error explanations for ‘ business ‘ or ‘ domain ‘ errors – such as for bad data in ETL jobs or failed business processes.
Such data is the only data that should be held in version control. All other data is loaded in a post-build script as dictated by the manifest, unless the build takes place against a version that already has the required data.
Test data should be generated to the same distribution, characteristics and datatype as the potential or actual production data, and each type of test is likely to require different test data sets. Performance and scalability testing will require a range of large data sets whereas integration test is likely to require standard ‘before’ and ‘after’ sets of data that includes all the likely outliers. Test data is best loaded from ‘native’ BCP format using bulk load.
Pre- and post-build processes
A build process will generally include pre-build and post-build processes. Various automated or semi-automated processes are often included in the build but are not logically part of the build, and so are slotted into one or other of two phases of the build called the ‘pre-build process’ and the ‘post-build process’. A build system will have slots before and after the build to accommodate these. These are most likely to be either SQL or PowerShell scripts.
An important pre-build process, for example, is ‘preparing the workspace’, which means ensuring that all the necessary requirements for the build are in place. What this entails is very dependent on the nature of the database being built, but might include preparing a Virtual Machine with SQL Server installed on it at the right version, or checking to ensure that the platform is configured properly, and that there is sufficient disk space.
Typical post-build processes will include those designed to manage team-based workflow or reporting. For example, we need to log the time of the build, the version being built and the success of the build, along with warning messages. It might involve email alerts and could even list what has changed in the build since the last successful build.
Also, of course, there will need to be a post-build step to validate the build. Specially-devised tests will not only check that the build was successful but that no major part of the system is entirely broken.
Promoting builds through the environments
Ideally, you should not have a different build process for development, test, integration, release and deployment. Our goal is that the build is fully automated, and that the build package that we produce, and subsequently test, will be used to the build the database, at that version, for all environments, from development through QA and Staging up to production.
In order to achieve automated, consistent builds across all environments, ‘it is best if the development environment mimics the production environment as closely as possible in terms of the architecture of the database and objects, and in the surrounding database technologies.
This isn’t always possible. Enterprise databases will likely use features such as partitioned tables, ColumnStore indexes and many other Enterprise features, which cannot easily be imitated in the development environment. In addition, there may be disaster recovery, high availability or auditing features, such as replication or change data capture, that aren’t appropriate in the development environment.
DLM encourages teams to collaborate closely, making it easier to provide ‘hooks’ in the build to allow aspects of the build to be different in each server environment, for example to associate the appropriate logins with each server and database role, in each environment, or to provide the correct auditing regime.
Builds in the development environment
In order to achieve build consistency across environments, all DLM solutions to the database build process need to offer a high degree of freedom to what is included, or not, in the build process.
A build process within development will generally use only local resources. A DLM build is designed to be flexible-enough that external dependencies such as ETL processes and downstream BI can be ‘mocked’, by creating interface-compatible stubs, to enhance the range of testing that can be done and allow development to run independently. This means that up-stream ETL processes will be ‘mocked’ sufficiently for them to be tested. Allied databases, middleware services and message queues will either be skeletal or mocked. Likewise ‘downstream’ processes that are ‘customers’ of the data from the database are generally also ‘mocked’.
A development build process will also have a security and access-control system (e.g. GRANTs and user accounts) that allows the developers complete access. If it is role-based, then the production access-control can easily be used for a production build during the deployment process. Typically, operations will want to assign users via active directory, so the production build will have a different set of windows groups created as database users, and assigned database roles as befits the security model for the database.
One step toward the goal consistent builds is to ensure that any necessary modifications to the build process, for the different environments, should be in the manifest rather than in the scripted process itself. All these manifests can be saved either in development source control or in the central management server (see the Database Release and Deployment article).
Essentially, we need a clear separation between the data and the database configuration properties. We can use templates to cope with such challenges as references to external systems, linked databases, file paths, log file paths, placement on a partition scheme, and the path to full-text index files, filegroup placements or file sizes, which would produce different value for each environment. We can supply separate configuration files, tested by your CI processes (see the Database Continuous Integration article), as part of the database release package. For example, we can:
- Specify environment-specific parameters in environmental configuration files – such as the location of the database files, their size, growth rates and so on
- Remove all environme nt-specific statements from the build and migration scripts – no change of the configuration should involve any code or script change
- Make the security configuration easily maintainable -security (logins, roles, database object permissions) settings belong in configuration files, not in T-SQL scripts
Builds in QA, Staging and Production
For a database to work properly, when it comes time to deploy to production, or to production-like environments, the canonical source, in the VCS, will also need to include components that are executed on the server, rather than within the database. These Server objects include scheduled jobs, alerts and server settings. You’ll also need scripts to define the interface linking the access-control system of the database (database users and roles) to the server-defined logins, groups and users, so that the appropriate users can access the roles defined within the database.
Therefore, if a build succeeds and is validated, it means that all the DDL source code, assemblies, linked servers, interfaces, ETL tasks, scheduled jobs and other components that are involved in a database have been identified and used in the right order. This makes it more difficult for a subsequent deployment to fail due to a missing component, and all of the people involved in the database lifecycle can see, at any stage, what components are being used.
The characteristics of a DLM database build
If the database development team does not rigorously enforce the discipline of always starting from a known version in source control, and regularly testing to prove that they can build the required version of the database, then you are likely to suffer with an unreliable and time-sapping database build process.
A fairly typical non-DLM approach goes something like as follows. The development team make changes to a shared database, either directly or with the help of a database administrator (DBA) or a database developer. When it comes time to release a new version of the application, the development team works with the DBA to come up with a list of just the database changes that are needed to support the new version. They generate a set of scripts, run them against the database in the test environment (although, in the worst cases, this is done directly against a production environment), and then build the application.
Testing reveals that some of the necessary database changes aren’t there, so additional scripts are generated and run. Next, they discover that some scripts were run that implement database changes that the application is not yet ready to support. They generate another set of scripts to roll back the unwanted changes.
This chaotic process continues until, more by perseverance than planning, the application works. The team now have a whole new set of scripts that have been created, manually, and that will have to be run in the correct order in order to deploy to the next environment.
This causes all sorts of problems. Development and testing are slowed down because of all the additional time needed to identify the changes needed. The manual process of generating scripts is time-consuming and very error prone. It leads to delayed functionality, and often to bugs and performance issues. In the worst cases, it can lead to errors being introduced into the data, or even loss of data.
To avoid this sort of pain, database builds (and migrations) should be automated, controlled, repeatable, measurable and visible.
DLM database builds are automated
As described previously, to allow a database to be built that has scripts with a number of different objects in them, you either need to create, and subsequently maintain, a ‘manifest’ file that lists the files in the order of execution, or you should use a tool such as SQL Compare which can read a directory of scripts as if it were a database.
- If using a manifest, keep that in source control with the scripts.
- Label and branch the manifest with the scripts
- If using a differential tool, such as SQL Compare, save the generated build script in source control with the appropriate label or branch
A big part of automation is having the ability to both replicate what you’ve done and go back and review what you’ve done. If you keep the manifest or generated scripts in source control, you’ll always be able to do this.
Although a build tool or proprietary build server is often used to automate database builds, it is not necessary. You merely need a script that executes each script serially in order, and SQLCMD.exe can be used easily to execute a SQL file against a target server.
If you are using a shared development server with the development database in it, and it is kept entirely up-to-date with version control (all current work is checked in) then you can calculate the build order with a SQL routine that does a topological sort of the dependencies between objects to list first the objects that have no dependencies and then successively, all the objects that are depending only on already listed objects until all objects are accounted for. You can, of course, create a PowerShell routine that calls SMO to do the task for you. If all else fails, you can use SSMS to generate an entire build script for you from the development database only to use the order in which the objects were created to determine the order for your manifest.
DLM Database Builds are frequent
During development, the build process should be done regularly, because it tells you whether it is possible to do this with the latest version of the committed code, and allows you to keep all the team up-to-date. The canonical database that results from a successful build can also be checked against other development versions to make sure that they are up-to-date, and it can be used for a variety of routine integration and performance tests.
Frequent or overnight builds can catch problems early on. A build can be scheduled daily, once all developers’ changes have been committed and if necessary merged, or after every significant commit, when any component parts change. Testing is performed on the most recent build to validate it. Usually, builds are done to the latest version, but with version-control, ad-hoc builds can occasionally be done when necessary on previous versions of the code to track down errors, or to revive work that was subsequently deleted.
DLM database builds are repeatable
As described earlier, we should be able to run that same script over and over on any system and it not ever break because it had been run previously. A DLM build process should never result in a “partial” build. If it fails at any point, it should roll back all the changes to the starting version. This requires wrapping the build into a transaction that rolls back on error.
If a build is successfully automated, it is much more likely to be repeatable in exactly the same way, with minimal operator-intervention. The governance process will be more confident in the time that must be allowed for a build process and validation, and will be much more confident in a successful outcome. This makes the entire end-to-end delivery process more predictable.
DLM database builds are tested
Of course, we need to validate not just that the build or migration succeeded, but that it built the database exactly as intended. Is your database and static data intact? Do all parts of your application and important code still function as expected? Are all the database object there and correct?
By incorporating automated testing into your build process you add additional protections that ensure that, ultimately, you’ll deploy higher quality code that contains far fewer errors. We address testing in detail in the Database Testing article.
DLM database builds are instrumented
Once you have the build process automated, the next step is to set up measurements. How long does a build take? How many builds fail? What is the primary cause of build failure?
You need to track all this information in order to continuously improve the process. You want to deliver more code, faster, in support of the business. To do this, you need to get it right. If you’re experiencing the same problems over and over, it’s best to be able to quantify and measure those so you know where to spend your time fixing things.
As the databases increase in number, size and functionality, within an organization, the complexity and fragility of the build process will often increase, unless serious thought has been given to structuring and modularizing the system via, for example, the use of schemas and interfaces.
A common blight of the database build is, for example, the existence of cross-database and cross-server dependencies. At some point, the build chokes on a reference from one object to a dependent object in another database, which it can’t resolve for one reason or another. This might typically be because the database containing the object is not available in the context in which the current database is being built. It’s often good practice in terms of data architecture to remove the dependency to a higher layer (integrating in a service for example), but if that’s not possible, you might want to examine ‘chaining’ database builds to best satisfy dependencies.
At this point, it’s very important that the build process is well instrumented, providing all the details the developer needs, including the full stack trace if necessary, to pinpoint with surgical precision the exact cause of the problem. In poorly instrumented builds, it’s more likely the developer will see a vague ” can ‘ t find this column” error, and will be left to sift through the remaining few thousand objects that didn’t load to find the one that caused the problem. No wonder, in such circumstances, database builds and releases are infrequent and often delayed, and therefore potential problems spotted much later in the cycle.
DLM database builds are measureable and visible
An automated build can be more wide-ranging, building not only the database, but also any automatically-generated build notes and other documentation such as help pages.
It is easier to report on an automated build, and as well as simple facts such as the time it took and whether it succeeded, the number of warnings, and even an overall code-quality metric, or code policy check, if necessary. This allows the governance process to do its audit and accountability tasks, and firm-up on planning estimates.
Any build and version-control system must allow developers, as well as people outside the development team, to be able to see what is changing and why, without needing time-wasting meetings and formal processes.
Advanced Database build considerations
There seem to be an infinite variety in databases and this is reflected in the number of options that have to be considered in the build, and subsequent deployment process. There are many choices to be made as to how the build processed in case of various eventualities. Here are just some of them (we cover others in the Database Migrations article).
Is the server version (platform) compatible with the database code ?
Different versions and editions of the RDBMS will have different capabilities. It is easy to produce working code for one version of SQL Server that will fail entirely, work in a subtlety different way, or with degraded performance, on a different version. A database is always coded for a particular version of the RDBMS. If the database specification includes the compatibility-level of the database, or the range of versions it must run on, then the build script should contain a guard clause to check the compatibility and version of the host SQL Server that the database is being installed on, and fail the build if it is incorrect.
Is the default collation of the database the correct one ?
A collation will affect the way that a database behaves. Sometimes, the effect is remarkable, as when you change from a case-sensitive to a case-insensitive collation or the reverse. It will also affect the way that data is sorted or the way that wildcard expressions are evaluated. This will produce subtle bugs that could take a long time to notice and correct. The build script should, to be safe, check the database collation and cause an error if it is incorrect.
Can database-level properties be changed in the build?
Code that works under one database configuration can easily be stopped by changing a database-level configuration item. When a server creates a database, it uses the database-level configuration that is set in the model database. This may be quite different from the database configuration on the developers’ servers, and if these differences are allowed the result will be havoc. The build script should check to ensure that the database has the correct configuration for such things as the default isolation level, date format, language, ANSI nulls.
Should the database being built then be registered as a particular version on the server?
SQL Server allows databases to be registered when they are built or modified, meaning that an XML snapshot of a database’s metadata is stored on the server and can be used to check that no unauthorized changes have been made subsequently. It is generally a good precaution to register a database if you are using DacFx, but very large databases could possibly require noticeable space.
Should all constraints be checked after all the data is inserted into the build?
This only applies if some sort of static data is imported into the database as part of the build. In order to guarantee a fast data import, constraints are disabled for the course of the import and then re-enabled after the task is finished. By re-enabling the constraints, all the data is retrospectively checked at once. It is the best time to do it but it could be that more data has to be inserted later into a related table, and so this should, perhaps, be delayed.
Should the build allow for differences in file paths, column collation, and other settings?
Many paths and database or server settings may vary between server environments. For example, there will likely be different file paths for data and log files, perhaps different filegroup placements, a different path to full-text index files or for a cryptographic provider.
Some settings, such as file paths, log file paths, placement on a partition scheme, the path to full-text index files, filegroup placements or file sizes have nothing to do with development and a lot to do with operations and server-administration. They depend on the way that the server is configured. It can be argued that the same is true of FillFactor. There are dangers in over-writing such things as the seed or increment to identity columns, or collation.
These settings should be in a separate build script for each server environment or dealt with by SQLCMD variables that are set at execution time.
How should the build handle different security options between server environments?
How should the build handle differences in the security settings, security identifiers, permissions, user settings or the role memberships of logins of the build, for the different server environments? This very much depends on the context of the build, and the way that the database handles access control. If the database is designed to hold live personal, financial or healthcare data, it is likely to be illegal to allow the same team of people to both develop the database and to determine, the access rights or security settings for database objects. Best practice is for these to be held separately in a central CMS archive by operations, and determined according to whether the database holds real data or spoofed test data.
In practical terms, it makes sense to base the development access-control system on database roles and assign these to users or windows groups by a build script that is based on the one provided in the release, but with the appropriate assignments made for the server environment, whether QA, staging or production, and held in a CMS archive.
Within development, the problem is greatly simplified as long as live data is never allowed. The development and test builds can run unhindered. As soon as live data is used, as in staging, forensic analysis, or production, then all security and access control settings need to comply with whatever legislative framework is in force.
Conclusion
When developing a database application, it is a mistake to believe that database build is a simple task. It isn’t. It has to be planned, scripted and automated. The build must always start from a known state, in the version control system. You can then use various means to generate the scripts necessary for a build or migration. You need testing in order to validate the build, and ensure that you’re building the correct items in a safe fashion. You need instrumentation and measurements that will log the time of the build, the version being built and the success of the build, along with warning messages. Warnings and errors need to provide detailed diagnostics, if necessary, to pinpoint the exact cause of the failure quickly.
As a result, your database builds and releases will be frequent, punctual, and you’ll spot and fix potential problems early in the cycle, and you’ll have the measurements that will prove just how much your processes are improving and how much higher the quality and speed of your development processes has become.

DevOps, Continuous Delivery & Database Lifecycle Management
Go to the Simple Talk library to find more articles, or visit www.red-gate.com/solutions for more information on the benefits of extending DevOps practices to SQL Server databases.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved




Load comments