
ETL redefined
ETL is a well-known acronym, standing for Extract, Transform and Load. It is identified particularly with data warehouse workloads and business intelligence applications. Nowadays, however, any regular process of data movement in a data-driven organization could be considered to be a type of ETL, and there are many alternative ways of managing such a process. There are, for example, several data integration tools, ranging from open source all the way to enterprise-level commercial solutions. Many of them, if not all, are GUI-based tools. The main advantage of the graphical approach is that you can rapidly provision your ETL packages, simply by using drag and drop capabilities; and have a nice visual overview. There are a whole range of scripting approaches as well, even using workflow techniques to ensure that ETL processes can be persistent and resilient. The advent of Big Data has given us another alternative approach using Scala powered by the built-in parallel processing capabilities of Apache Spark. In this article, we will look closer at this alternative, and try assess whether it is worth the hype.
GUI based ETL
Before we jump into the details of coding in Scala, let’s check out those advantages that GUI-based ETL tools give us out of the box. For this purpose, we’ll build a simple integration package that will simply count the words from a text file. The Microsoft SQL Server Integration Services (MS SSIS) example could look like this.
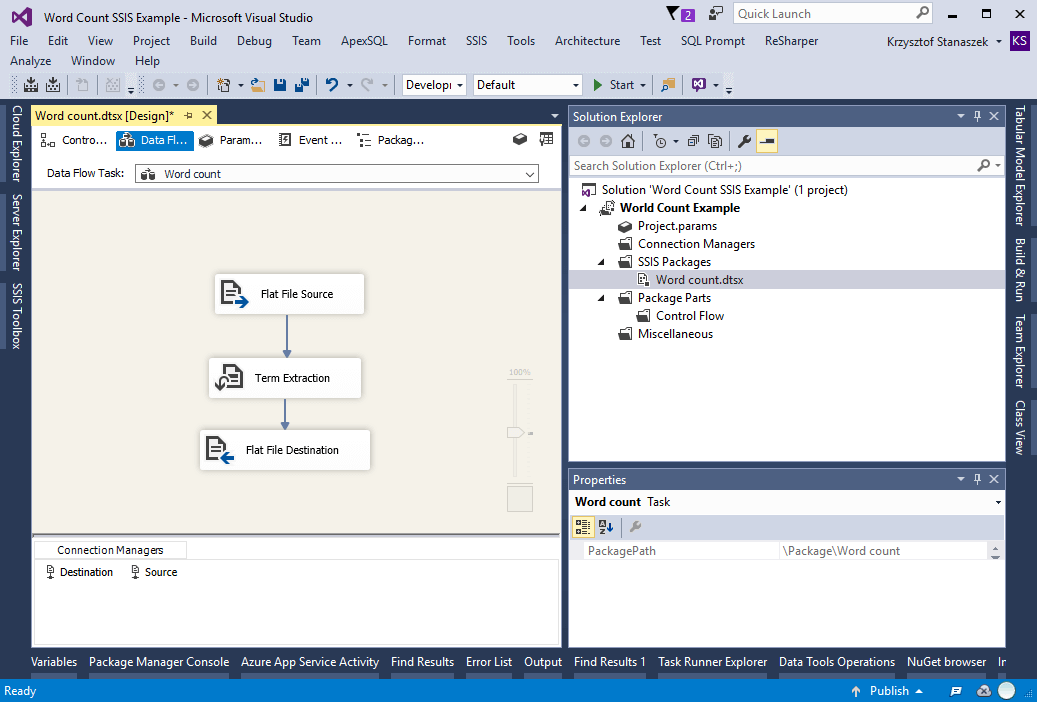
Figure 1. MS SSIS as an example of GUI based ETL tool
First, we have a good visual overview, going from the high-level perspective to the details. Because it is just an example, our ETL is very simple. We have two flat file connectors, one for a source and the other for a destination with term extraction transformation between them. This is what we can get from SSIS without effort.
It looks very simple and these first impressions will beguile you into going further and building more complex solutions. These will work, I can assure you. GUI tools allow you to rapidly build your data pipeline from scratch, and SSIS is a mature product. It looks impressive at first glance and I am pretty sure that some IT executives will be tempted to buy it. They don’t have to understand the details but when you show them the flow of data they will be delighted. They will be impressed how easy it was to provision this example, and to build the entire end-to-end solution. If you have a long experience with complex ETL, you already know at this point how misleading their impression is. Beware however; both you, and your IT managers that hold the budget, can only see the tip of an iceberg. The simplicity of the solution is an illusion produced by the simplicity of the graphical representation of it. When you look into the source code you will have a better understanding what really happens behind the scenes.
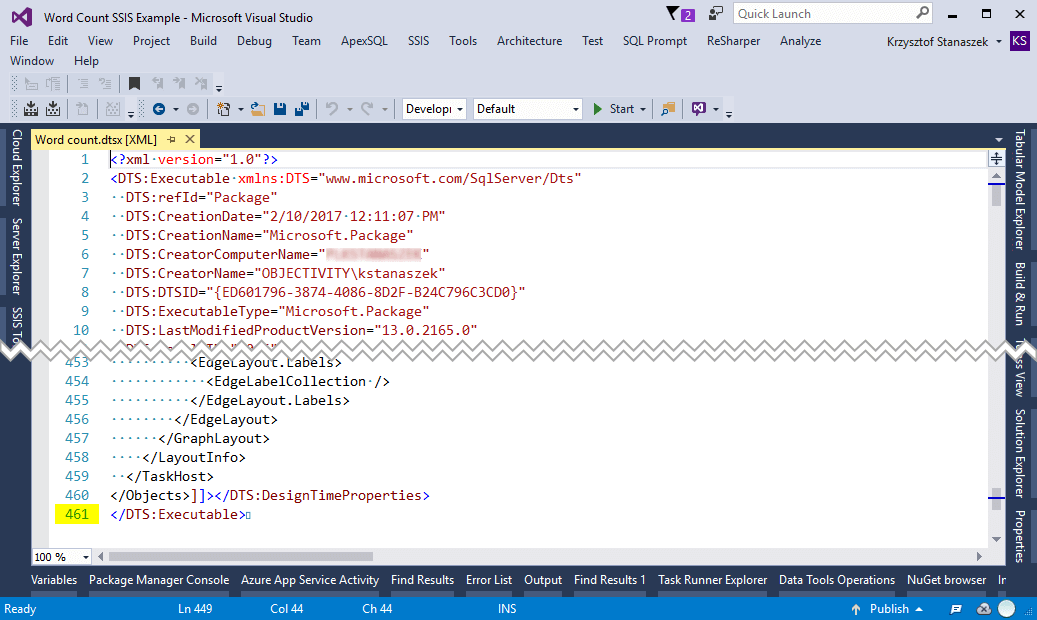
Figure 2. DSL-like code of MS SSIS package
As you can see, our SSIS package contains around 400 lines of DSL-like code. That’s a lot, bearing in mind that this is simple ETL. At this point, we wouldn’t be bothered by this. However, try to imagine that you have production ETL pipeline with hundreds of packages. How would you maintain them in a production environment or refactor some special-purpose functionality to provide for new business needs? How would you introduce changes without breaking existing code? As the process grows or changes, it could become a tough, hefty task even for an experienced data professional.
Those and other similar questions are not new in software engineering. In fact, there are a lot of tools and techniques around that are crafted especially for modern programming projects, but have achieved a high level of maturity and stability over the years. Nevertheless, almost all of them are very hard to execute within an ETL project. In our example, SSIS is excellent for simple requirements and for cases where something temporary needs to be put in place quickly. It is fine for a Proof of Concept (PoC) project: However, like many other GUI tools in general, SSIS doesn’t scale to meet the needs of corporate team-based development. There are no mature dedicated tools for unit testing, team-based development, source code merging, or even for automated deployment. SSIS is a great tool for a particular use, but it isn’t a general panacea. Don’t get me wrong at this point. I am not saying that all GUI based tools such as SSIS are bad by definition. In fact, there are many use cases where GUI based tools like SSIS fit the best as they are still the mainstream technology. What I would like to say is that using one tool for all may be not the best idea. To paraphrase the words of A. Maslow, don’t put yourself in a position when “if all you have is a hammer, everything looks like a nail”.
Code driven ETL
Let’s re-do our Word Count example, but use instead Scala and Spark. It takes 20 lines of code to implement the same transformation. It is fairly concise application. It wouldn’t be fair to compare this with the 400 lines of the SSIS package but it gives you a general impression which version would be easier to read and maintain.
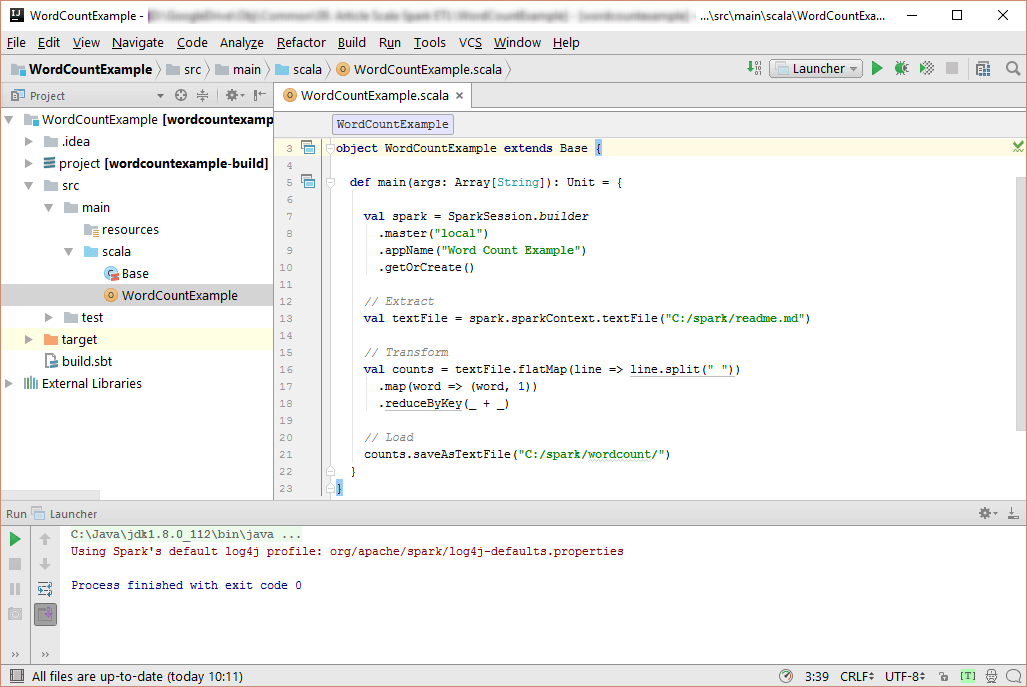
Figure 3. Scala and Spark as an example of code driven ETL
Actually, you don’t even need Spark to achieve the same goal. You can do the same in every modern programing language like C#, Java, F# or Scala. What makes Scala and Apache Spark combination special? Scala gives you the best of functional programming features with immutable data structures whereas Spark offers parallel processing out of the box. This combination can be the foundation of highly reliable and scalable ETL pipelines.
The code looks very simple and developer-friendly, but beware: Scala is a very broad-based language with lots of useful but sometimes complex features. There is a struggle, even for intermediate-level programmers to master the code and, in particular, with some of its more esoteric language features. The design of the language was heavily focused on the functional aspect and on reducing the need for boilerplate code often found in other languages. So, you will need to be prepared for some deep learning that can be frustrating at first!
Scala advantages
By choosing Spark as a processing framework that is internally written in Scala, you will be limited in programming languages to Scala, Python, Java, C# and R. However, you become enabled to write unit and integration tests in a framework of your choice, set up a team-based development project with less painful code merges, leverage source control, build, deployment and continuous integration features. The framework and language will protect you from many errors and bugs that are bread and butter of every IT project. Besides all of the advantages of modern programming language, Scala gives you extra benefits such as:
- conciseness and less code than in a language such as Java or C#,
- immutable data structures allowing for parallel, lock-free data processing,
- full-featured object-oriented paradigms, so you are not limited to functional programming,
- performance that is better than interpreted languages such as Python,
- good compatibility with the MapReduce processing model,
- a plethora of well-designed libraries for scientific computing.
In order to demonstrate one of Scala’s advantages, we’ll create a sample unit test for your ETL application. There’s many ways to unit-test your Scala and Spark code. The most popular way is to use the ScalaTest framework, where SparkContext can be easily initialized for testing purposes. We only need to set master URL to local, run the operations and then stop the context gracefully. It could look as follows.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
import org.apache.spark.sql.SparkSession import org.scalatest.{BeforeAndAfterAll, Suite} trait SparkSpec extends SparkDatasetSpec with BeforeAndAfterAll { this: Suite => @transient var _ss: SparkSession = _ override def beforeAll() = { _ss = SparkSession.builder .master("local") .appName(this.getClass.getSimpleName) .getOrCreate() super.beforeAll() } override def afterAll() = { if (_ss != null) { _ss.stop() _ss = null } super.afterAll() } def ss = _ss def sparkContext = _ss.sparkContext } |
Figure 4. Spark hand-rolled code for unit testing
Although the boiler plate for testing a regular Spark program is pretty short, another alternative choice is to use Spark-Testing-Base solution written by Holden Karau or use sscheck, which integrates ScalaCheck with Apache Spark. You can also do full integration tests by running Spark either locally or in a small test cluster. Finally, unlike in GUI based ETL tools, you have the option of choosing the test framework that best fits your needs. For the time being, and for a better understanding of what’s behind the scenes, we will use our own hand-rolled version. We will test transformation logic, which is the core of a word-count routine.
The reason that I’m emphasizing unit test is that the act of writing your first ETL unit test forces you think in different way about your code. You are compelled to ask yourself whether your code is testable. When you start writing unit tests, you are quickly drawn to the conclusion that the part of your code that needs to be tested must be encapsulated in a separate construct that is inherently testable. Thanks to this approach, we should achieve one code used by both the application and the test.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
case class WordCount(word: String, count: Int) object WordCountExample extends Base { def main(args: Array[String]) = { val spark = SparkSession.builder .master("local") .appName("Word Count Example") .getOrCreate() // Extract val textFile = spark.sparkContext.textFile("C:/spark/README.md") // Transform val stopWords = List("the", "and", "to", "for") val wordCounts = count(spark, textFile, stopWords) // Load wordCounts.map { case WordCount(word, count) => (word: String, count: Int) }.rdd.saveAsTextFile("C:/wordcount/") } def count(ss: SparkSession, lines: RDD[String]): Dataset[WordCount] = { count(ss, lines, List.empty) } def count(ss: SparkSession, lines: RDD[String], stopWords: List[String]): Dataset[WordCount] = { val words = lines.flatMap(_.split("\\s")) .map(_.stripSuffix(".").stripSuffix(",").toLowerCase) .filter(!stopWords.contains(_)) .filter(!_.isEmpty) val wordCounts: RDD[WordCount] = words.map(word => (word, 1)).reduceByKey(_ + _).map { case (word: String, count: Int) => WordCount(word, count) } import ss.implicits._ wordCounts.toDS } } |
Figure 5. ETL code refactored
As you can see, after a small amount of refactoring, we have extracted the transformation logic into a separate method. We have also added some extra features such as a stop list. Finally, this has enabled us to write the tests.
We have created two tests. The first simple one to check the border case where our data source is empty and second, more complex, to test the core of our transformation. Few things require attention. First of all, we use FlatSpec testing style, which is behavior-driven style of development (BDD), in which tests are combined with text that specifies the behavior the tests verify. We have also used Spark-Testing-Base solution written by Holden Karau to be able to compare two datasets smoothly.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
import org.scalatest.{FlatSpec, GivenWhenThen, Matchers} class WordCountTest extends FlatSpec with SparkSpec with GivenWhenThen with Matchers { "Empty set" should "be counted" in { Given("empty set") val lines = List("") When("count words") val wordCounts = WordCountExample.count(ss, sparkContext.parallelize(lines)) Then("empty count") wordCounts shouldBe empty } "Abraham Maslow quote" should "be counted" in { Given("quote") val lines = List("I suppose it is tempting.", "If the only tool you have is a hammer, to treat everything as if it were a nail.") Given("stop words") val stopWords = List("as", "have", "i", "the", "a", "to", "you") When("count words") val wordCounts = WordCountExample.count(ss, sparkContext.parallelize(lines), stopWords) Then("words counted") val sparkSession = ss import sparkSession.implicits._ val expectedWordsCounts = List( ("everything", 1), ("hammer", 1), ("if",2), ("is",2), ("it",2), ("nail",1), ("only",1), ("suppose",1), ("tempting",1), ("tool",1), ("treat",1), ("were",1)).toDF("word", "count").as[WordCount] assertDatasetEquals(wordCounts.orderBy($"word"), expectedWordsCounts.orderBy($"word")) } } |
Figure 6. ETL unit-test examples
Another thing is an inheritance in our test class. You can see that the test class inherits from four class-like constructs. This is unusual even for modern object-oriented languages, when you can inherit only from one class. Without straying from the topic of this article, I must just say that Scala achieves this behind the curtain by linearization and these class-like constructs are called traits, that can be mixed with your base class. At this point you might think that traits are like C#/Java interfaces with concrete methods, but they can actually do much more. This benefits our ETL to achieve great flexibility in how you design an entire solution.
Apache Spark advantages
One of many advantages of Spark is the rich abstraction of the API. You can build complex data workflows and perform data analysis with minimal development effort. This is one of the goals of Spark development team where simple things should be simple, and complex things should be possible. There are many Spark features not covered by this article. If you would like to know more about Spark, take a look at spark.apache.org examples or at my last article How to Start Big Data with Apache Spark. However, this article focuses on ETL capabilities that Spark gives out of the box.
One of the most interesting features is concept of a dataset, which is a strongly typed collection of domain-specific objects. These can be transformed in parallel by using functional or relational operations. The core of the dataset is a new concept called an encoder, which is responsible for converting between JVM objects and their tabular representation. The tabular representation is stored using Spark internal binary format, allowing for operations on serialized data and improved memory utilization. Thanks to this, dataset implementation runs much faster with less memory pressure than the naive RDD implementation.
If you look closer at a unit test example introduced in previous code snippets, you can see that we are already used a Spark dataset. In the example below, the dataset operates on type-safe domain objects with a compile-time error on not existing domain member.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
val df: DataFrame = spark.read.json("people.json") // Convert data to domain objects case class Person(name: String, age: Long) val ds: Dataset[Person] = df.as[Person] // Show the results ds.filter(_.age > 30).show() ds.filter(_.name startsWith "J").show() // Compile time error: value lastname is not a member of Person ds.filter(_.lastname startsWith "A").show() |
Figure 7. Type-safe datasets
The noteworthy thing here is the way that data is converted to domain objects. We use the case class construct, very popular in Scala due to its many advantages. We use it because it eliminates a lot of unnecessary boiler plate code – at a small price. You have to write the case modifier, and your classes become a bit larger. Case classes fit ideally for data structures and Spark leverages this Scala feature with type-safe datasets objects.
It gives you as a developer a convenience that at least during development you don’t need to worry about schema validation of your text data sources. From now on, most schema related issues can be captured during compilation instead of runtime. That is a huge relief.
Summary
In this article, I was trying to show you that there are different approaches to doing ETL. However, it isn’t easy to choose an architecture that is right for you. It is not just about the volume of data but also the development approach of the organization and the available skills of the development team. The issues are not just about the technology but also about the culture of work and mindset in your organization.
It is important to note that Spark is a Big Data framework, so you must build a full Hadoop cluster for your ETL. This could be expensive, even for open-source products and cloud solutions. On the other hand, if you are not a Big Data fan, you still need to make an investment in an expensive enterprise-ready ETL tool. Probably you will also have to provision a dedicated server environment for your ETL if your dataset is quite big. So, there is still a trade-off. What I can say that right now, with Scala and Spark you have an alternative that does not force you to use a hammer to drive in a screw.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments