
I’ve long been a huge advocate for always referencing objects with a schema prefix in SQL Server.
In spite of what may be a controversial title to many of my regular blog readers, I don’t really want you to stop that practice in most of your T-SQL code, because the schema prefix is important and useful most of the time. At Stack Overflow, though, there is a very specific pattern we use where not specifying the schema is beneficial.
Background
The Stack Exchange Network is comprised of many web sites with the same question & answer model, and you’ve almost certainly heard of “the big three” – Stack Overflow, Server Fault, and Super User (all with spaces!). There are many other sites, covering everything from cooking and physics to science fiction and woodworking.
The way the public network sites work is that each web site has a domain name and a connection string to an individual database. Every database is basically identical in structure – each site has a Posts table, a Users table, and all the usual suspects.[ * ]
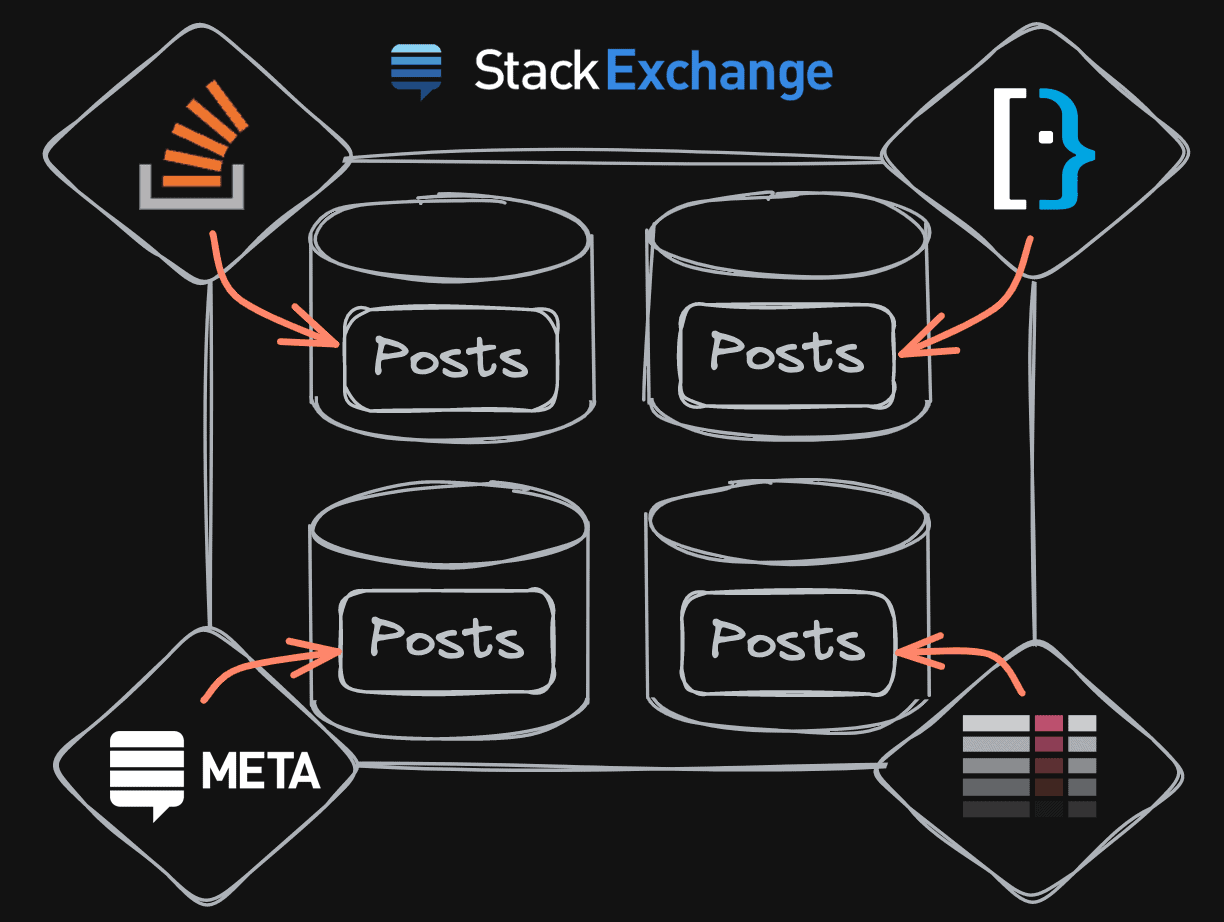
Our Stack Overflow for Teams offering is a private version of the public network – you create your own team, and you get your own private Q & A web site, where you can share information within your organization or even just among your immediate teammates.
The database structure works slightly differently here; in most tiers, each team does not have its own database, but rather the security boundary is by schema, as explained in this security overview. There are multiple reasons for that, and they pre-date my tenure here. But certainly, as a reliability engineer, I do not want to have to manage thousands and thousands of databases, especially since even at 100 databases, we bump up into both enforced limits (e.g. Managed Instance) and practical limits (see our well-documented and oft-lamented performance problem around AG failovers).
But each team still has its own connection string. And each team’s schema still has a Posts table, a Users table, and all the usual suspects.[ * ]
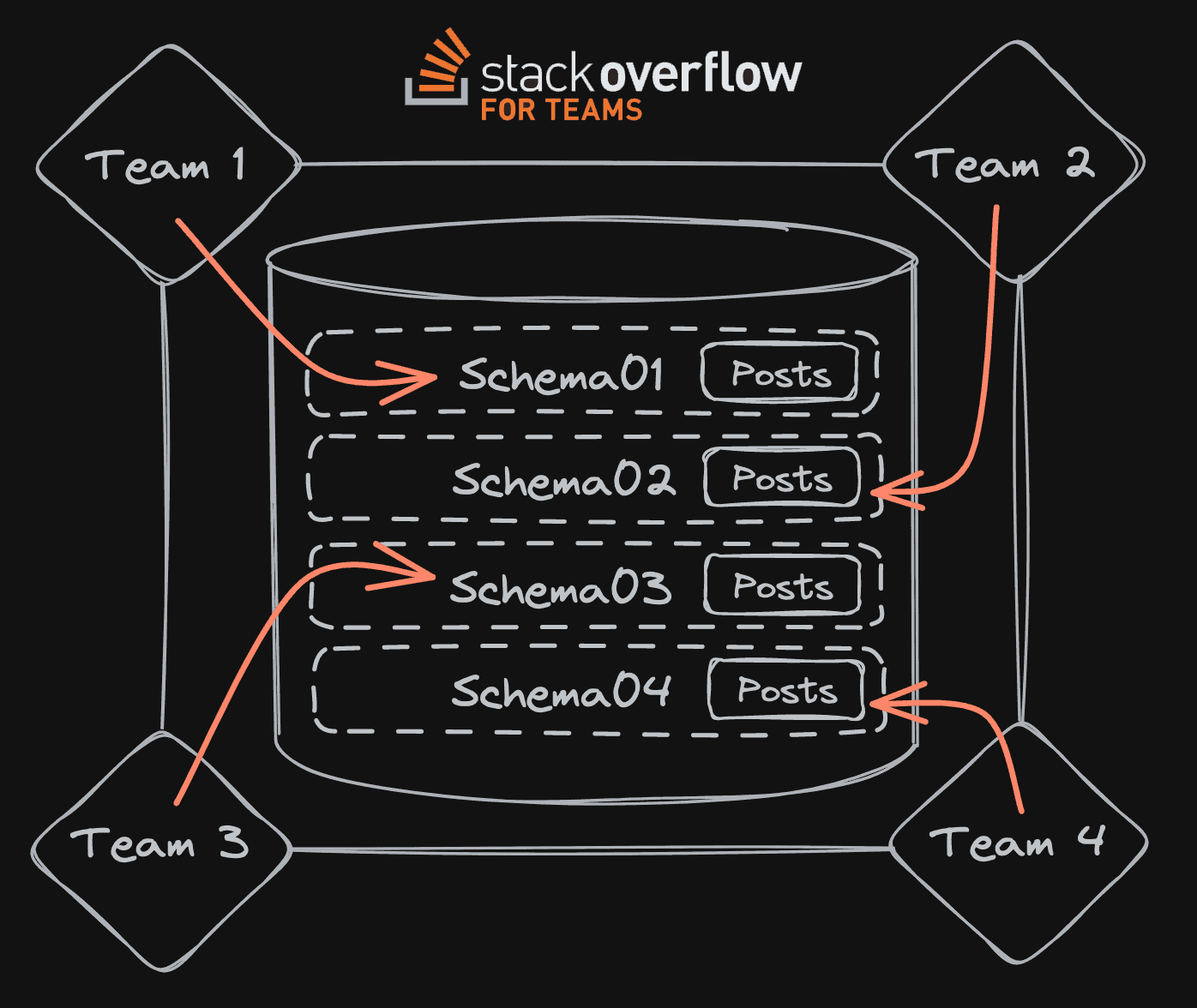
The structure is the same because large portions of the codebase are shared across all of the applications and services, and they issue all kinds of queries – often dynamically and conditionally constructed within Dapper or the bowels of C#. The problem is clear: we can’t obey the pattern of always specifying the schema without complicating every single query and injecting either dbo. in the case of public network or Schema00xxx. in the case of Teams. So the code is full of queries that simply don’t reference any schema at all, to make them the most portable and compatible with all flavors of the software:
|
1 2 3 |
SELECT {columns} FROM Posts WHERE ... |
For Teams, we take advantage of the fact that the connection string for any site specifies a user that owns that single schema, uses it as their default, and can’t access any others. The potential trade-off there is something I mentioned in my earlier rant: every time a user from a different schema executes any specific version of a query, another entry is added to the plan cache (even though the query text and all other attributes are identical).
This isn’t a problem in the public network side because there are only dbo versions of the tables, and no app users or service accounts have anything else as their default schema. And it’s actually not the huge problem you might assume in Teams, either, because teams come in all shapes and sizes. It can actually be beneficial for each team to generate their own unique plan, with estimates based on their specific table cardinalities. But it is worth mentioning because it can come as a surprise.
Other Challenges
This solution is not without its challenges aside from “plan cache stuff.”
- Balance: It takes time and experimentation to balance the right number of schemas across the right number of databases. If you have to create a million tenants, what’s best? Ten databases with 100,000 schemas each? 100,000 databases with 10 schemas each? Somewhere in the middle? Considerations include how many are supported (I mentioned the 100-database limits above) and, even where there is no explicit limit, there are other questions like, “how long am I willing to wait for Object Explorer to render 10,000 schemas?” And how many backups are you taking vs. how big are your backups vs. how long does it take you to recover a single tenant (or many tenants). We started with 10,000 schemas per database, and have since adjusted that to 1,000.
- Server-level logins: If your SQL Server is domain-joined, you will find there is a practical upper bound where creating the next login (even a SQL Authentication login!) will take longer and longer and, eventually, will effectively grind to a halt. One adjustment we made – which had zero impact on the behavior of the application, APIs, or supporting services – is to switch from matching server-level logins and database-level users to just a single set of contained database users. As the documentation suggests, this also makes it easier to move a database with a noisy neighbor to a different server, though we haven’t done that yet.
- Muscle memory: It has been very hard to get into the habit of not doing something I’ve been training myself to always do for about two decades now, and have been influencing others to always do through writing, speaking, peer review, and answers. I have submitted several PRs that were very quickly rejected because an errant
dbo.snuck in there out of habit.
Conclusion
This solution works great for our specific use case because the application codebase is very large and managing at the schema level is the lesser of several possible evils. In a multi-tenant solution, you will always have trade-offs – not just between performance and management overhead, but also between where performance is most important and where management overhead hurts the most.
For Stack Overflow, I’m convinced we’ve made the right compromise, and happy that the architecture is built in such a way that we can easily tweak configuration like “number of schemas per database.”
This is not to suggest, necessarily, that you should use this model in your environment. There are many other factors involved, including where you want more or less complexity, and how you want to scale tenancy. Those criteria are much more important than whether you are following or ignoring what some old-timer rants about in his blog posts and presentations, and I just thought it would be useful to have a counter-example where I admit that almost every rule has justifiable exceptions.
* Further Reading
To learn more about the Stack Overflow schema, and the tables I lump into “the usual suspects,” see Erik Darling’s gentle introduction. If you’re a more hands-on person, you can snoop around a rough subset of the schema in the Stack Exchange Data Explorer, or download the data dump from archive.org.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved





Load comments