
Executive Summary
Entity Framework performance problems typically fall into four categories: database access issues (N+1 selects, greedy row/column loading, missing indexes, mismatched data types), client-side overhead (change tracking on large result sets, non-async database calls), startup performance (slow first-context initialisation, giant contexts), and configuration choices (missing disposals, skipping bulk insert alternatives). This article covers all four, with each problem demonstrated using a sample application showing the before/after query behaviour. If you have a specific problem, jump directly to: N+1 select → H3 ‘The N+1 Select Problem’; slow SELECT * → H3 ‘Being too greedy with Columns’; change tracking → H3 ‘Change tracking’; startup → H2 ‘Startup Performance’.
Compared to writing your own SQL to access data, you can become miraculously more productive by using Entity Framework (EF). Unfortunately, several traps that are easy to fall into have given it a reputation for performing poorly; but it doesn’t have to be this way! The performance of Entity Framework may once have been inherently poor but isn’t any more if you know where the landmines are. In this article we’ll look at where these ‘traps’ are hiding, examining how they can be spotted and what you can do about them.
We’ll use examples from a simplified school management system. There’s a database with two tables for Schools and their Pupils, and a WinForms app using an EF code-first model of this database to fetch data in a variety of inefficient ways.
To play along at home, you can grab the code for most of these examples from
https://github.com/bcemmett/EntityFrameworkSchoolSystem – setup instructions are included in the readme.
Database access
By far the biggest performance issues you’re likely to encounter are of course around accessing the database. These few are the most common.
Being too greedy with Rows
Sample application: button 1
At its heart, Entity Framework is a way of exposing .NET objects without actually knowing their values, but then fetching / updating those values from the database behind the scenes when you need them. It’s important to be aware of when EF is going to hit the database – a process called materialization.
Let’s say we have a context db with an entity db.Schools. We might choose to write something like:
|
1 2 3 |
string city = "New York"; List<School> schools = db.Schools.ToList(); List<School> newYorkSchools = schools.Where(s => s.City == city).ToList(); |
On line 2 when we do .ToList(), Entity Framework will go out to the database to materialize the entities, so that the application has access to the actual values of those objects, rather than just having an understanding of how to look them up from the database. It’s going to retrieve every row in that Schools table, then filter the list in .NET. We can see this query in ANTS Performance Profiler:
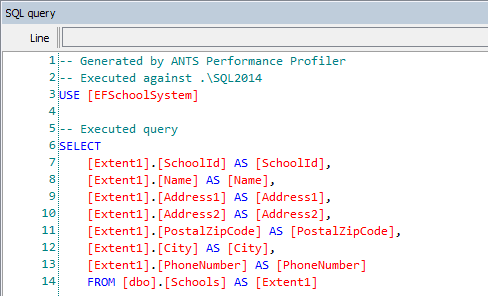
It would be far more efficient to let SQL Server (which is designed for exactly this kind of operation and may even be able to use indexes if available) do the filtering instead, and transfer a lot less data.
We can do that either with …
|
1 |
List<School> newYorkSchools = db.Schools.Where(s => s.City == city).ToList(); |
… or even …
|
1 2 |
IQueryable<School> schools = db.Schools; List<School> newYorkSchools = schools.Where(s => s.City == city).ToList(); |
The ‘N+1 Select’ problem: Minimising the trips to the database
Sample application: button 2
This is another common trap caused by misunderstanding when objects will be materialized.
In our database, every Pupil belongs to a School, referencing the Schools table using a foreign key on the SchoolId column. Equivalently, in our EF model, the Schools object has a virtual property Pupils.
We want to print a list of how many pupils attend each school:
|
1 2 3 4 5 6 7 8 9 10 |
string city = "New York"; List<School> schools = db.Schools.Where(s => s.City == city).ToList(); var sb = new StringBuilder(); foreach(var school in schools) { sb.Append(school.Name); sb.Append(": "); sb.Append(school.Pupils.Count); sb.Append(Environment.NewLine); } |
If we look in ANTS at what happens when this code runs, we see a query run once to get a list of schools in New York, but another query is also run 500 times to fetch Pupil information.
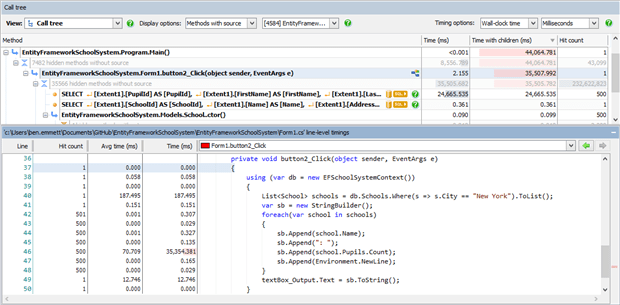
This happens because by default, EF uses a loading strategy called Lazy Loading, where it doesn’t fetch any data associated with the virtual Pupils property on the School object when the first query is run. If you subsequently try to access data from one of the related Pupil objects, only then will it be retrieved from the database. Most of the time that’s a good idea because otherwise any time you accessed a School object, EF would bring back all related Pupil data regardless of whether it were needed. But in the example above, Entity Framework makes an initial request to retrieve the list of Schools, and then has to make a separate query for each of the 500 Schools returned to fetch the pupil data.
This leads to the name “N+1 select problem”, because N plus 1 queries are executed, where N is the number of objects returned by the original query. If you know that you’re definitely going to want the Pupil data, you’d be better doing things differently – especially if you want it for a large number of School objects. This is particularly important if there is high latency between your application and the database server.
There are a couple of different approaches available. The first is to use the Eager Loading data access strategy, which fetches the related data in a single query when you use an Include() statement. Since the Pupils data would be in memory, there would be no need for Entity Framework to hit the database again. To do this your first line would read:
|
1 2 3 |
List<School> schools = db.Schools .Where(s => s.City == city) .Include(x => x.Pupils) .ToList(); |
This is an improvement because we don’t run the 500 extra queries, but the downside is we’re now bringing back all pupil data for those schools just to see how many there are. Sometimes you don’t need to bring back this additional data. For example, if we just wanted to get a list of Schools in New York with more than 100 pupils (but not caring about exactly how many pupils there are), a common mistake would see us write:
|
1 2 3 4 5 6 7 |
List<School> schools = db.Schools .Where(s => s.City == city) .ToList(); List<School> popularSchools = schools .Where(s => s.Pupils.Count > 100) .ToList(); |
We could use the same technique as above by adding an Include() statement, as follows:
|
1 2 3 4 5 6 7 8 |
List<School> schools = db.Schools .Where(s => s.City == city) .Include(x => x.Pupils) .ToList(); List<School> popularSchools = schools .Where(s => s.Pupils.Count > 100) .ToList(); |
But since we don’t actually need to know how many pupils there are, it would be far more efficient to just do:
|
1 2 3 4 |
List<School> schools = db.Schools .Where(s => s.City == city && s.Pupils.Count > 100) .ToList(); |
We can further improve performance by specifically selecting only the columns we need, which I will now describe.
Being too greedy with Columns
Sample application: button 3
Let’s say we want to print the name of every pupil at a certain SchoolId. We can do:
|
1 2 3 4 5 6 7 8 9 10 11 |
int schoolId = 1; List<Pupil> pupils = db.Pupils .Where(p => p.SchoolId == schoolId) .ToList(); foreach(var pupil in pupils) { textBox_Output.Text += pupil.FirstName + " " + pupil.LastName; textBox_Output.Text += Environment.NewLine; } |
By taking a look in ANTS at the query which has been run, we can see that a lot more data than the first and last names (FirstName and LastName) has been retrieved.
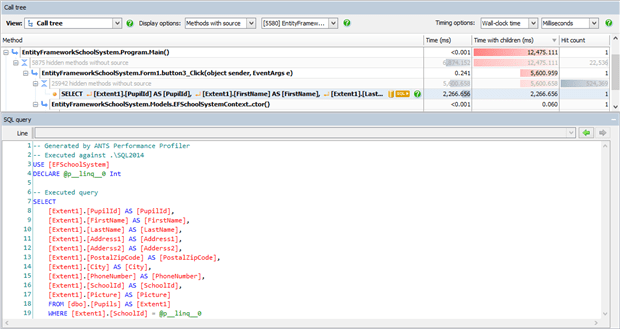
The problem here is that, at the point when the query is run, EF has no idea what properties you might want to read, so its only option is to retrieve all of an entity’s properties, i.e. every column in the table. That causes two problems:
- We’re transferring more data than necessary. This impacts everything from SQL Server I/O and network performance, through to memory usage in our client application. In the example here it’s particularly frustrating because although we just want the small FirstName and LastName strings, the Pupils table includes a large Picture column which is retrieved unnecessarily and never used.
- By selecting every column (effectively running a “Select * From…” query), we make it almost imÂpossÂible to index the database usefully. A good indexing strategy involves considering what columns you frequently match against and what columns are returned when searching against them, along with judgements about disk space requirements and the additional performance penalty indexes incur on writing. If you always select all columns, this becomes very difficult.
Fortunately we can tell Entity Framework to select only certain specific columns.
We can either select a dynamic object:
|
1 2 3 4 |
var pupils = db.Pupils .Where(p => p.SchoolId == schoolId) .Select(x => new { x.FirstName, x.LastName }) .ToList(); |
Or we could choose to define a separate class, sometimes called a DTO (Data Transfer Object), to select into:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
List<PupilName> pupils = db.Pupils .Where(p => p.SchoolId == schoolId) .Select(x => new PupilName { FirstName = x.FirstName, LastName = x.LastName }) .ToList(); ... public class PupilName { public string FirstName { get; set; } public string LastName { get; set; } } |
Another option, if you know there is data that you will never need to access from your application, is to simply remove that property from your model – EF will then happily just select the columns it knows about. You need to be careful, since if you remove a non-NULLable SQL Server column without a default value from your EF model, any attempt to modify data will result in a SqlException.
It’s also important to consider that selecting specific objects comes at the expense of code readability, so whether or not you decide to use it is a trade-off between readability and possible performance issues relating to the two problems discussed above.
If the unnecessary columns that you’re transferring are only small string columns (like perhaps a telephone number), or very low data volumes, and if returning those columns doesn’t negate use of indexes, then the performance impact will be minor, and it’s worth taking the hit in return for better readability and reduced effort. However, in this example, we’re retrieving a large number of images that we don’t need, and so the optimization is probably worthwhile.
Mismatched data types
Sample application: button 4
Data types matter, and if not enough attention is paid to them, even disarmingly simple database queries can perform surprisingly poorly. Let’s take a look at an example that will demonstrate why. We want to search for Pupils with zip code 90210. Easy:
|
1 2 3 4 5 6 |
string zipCode = "90210"; var pupils = db.Pupils .Where(p => p.PostalZipCode == zipCode) .Select(x => new {x.FirstName, x.LastName}) .ToList(); |
Unfortunately it takes a very long time for the results to come back from the database. There are several million rows in the Pupils table, but there’s an index covering the PostalZipCode column which we’re searching against, so it should be quick to find the appropriate rows. Indeed the results are returned instantly if we directly query the database from SQL Server Management Studio using
SELECT FirstName, LastName FROM Pupils p WHERE p.PostalZipCode = ‘90210’
Let’s look at what the application’s doing.
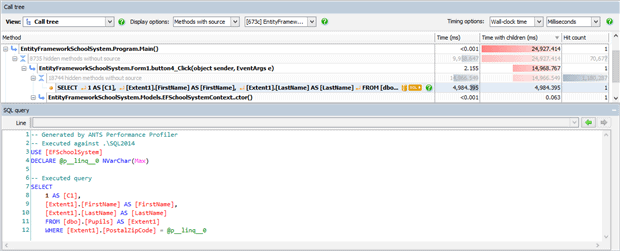
The query generated takes a long time to run, but looking at it, it seems perfectly reasonable. To understand why a query is slow, you need to look at its execution plan to see how SQL Server decided to execute the query. We can do that inside ANTS by hitting the Plan button.
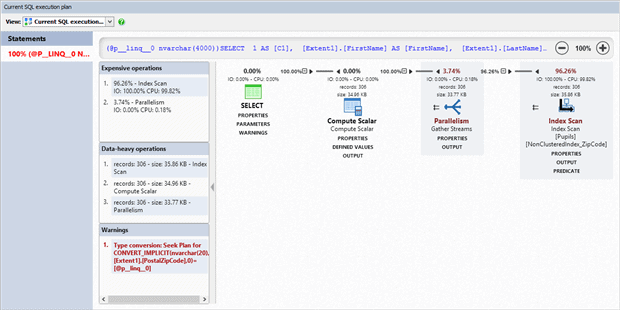
In the query plan, we start by looking for the expensive operations – in this case an Index Scan. What does that mean? A scan operation occurs when SQL Server has to read every page in the index, applying the search condition and outputting only those rows that match the search criteria (in this case, PostalZipCode = ‘90210’). In terms of performance, an Index Scan and a Table Scan are equivalent, and both cause significant IO because SQL Server reads the whole table or index. This is in contrast to an Index Seek operation, where an index is used to navigate directly to those pages that contain precisely the rows in which we are interested.
The query plan is showing us that we’re using an ‘Index Scan’ operation instead of an ‘Index Seek’, which is slow for the amount and characteristics of the data we have (there are around 30 million rows, and the PostalZipCode column is quite selective). So why is SQL Server choosing to use an Index Scan? The clue lies in the red warning in the bottom left:
|
1 |
Type conversion: Seek Plan for CONVERT_IMPLICIT(nvarchar(20), [Extent1].[PostalZipCode],0)=[@p__linq__0] |
So [Extent1].[PostalZipCode] was implicitly converted to NVARCHAR(20). If we look back at the complete query which was run we can see why. Entity Framework has declared the variable as NVARCHAR, which seems sensible as strings in .NET are Unicode, and NVARCHAR is the SQL Server type which can represent Unicode strings.
But looking at the Pupils table we can see that the PostalZipCode column is VARCHAR(20). Why is this a problem? Unfortunately, VARCHAR has a lower Data Type Precedence than NVARCHAR. That means that converting the wide NVARCHAR data type to the narrower VARCHAR can’t be done implicitly because it could result in data loss (as NVARCHAR can represent characters which VARCHAR can’t). So to compare the @p__linq_0 NVARCHAR parameter to the VARCHAR column in the table, SQL Server must convert every row in the index from VARCHAR to NVARCHAR. Thus it is having to scan the entire index.
Once you’ve tracked this down, it’s easy to fix. You just need to edit the model to explicitly tell Entity Framework to use VARCHAR, using column annotation.
|
1 2 3 |
public string Adderss2 { get; set; } [Column(TypeName = "varchar")] public string PostalZipCode { get; set; } |
After making this trivial change, the parameter will be sent to SQL Server as VARCHAR, so the data type will match the column in the Pupils table, and an Index Seek operator can be used.
Generally, these data type mismatches don’t happen if EF creates the database for you and is the only tool to modify its schema. Nevertheless, as soon as someone manually edits either the database or the EF model, the problem can arise. Also, if you build a database externally from EF (such as in SSMS), and then generate an EF model of that database using the Reverse Engineer Code First capability in EF power tools, then it doesn’t apply the column annotation.
These days almost all languages use Unicode to represent string objects. To lessen the likelihood of this kind of issue (not to mention other bugs!) I’d always advocate for just using NVARCHAR / NCHAR in the database. You pay a very small extra cost in disk space, but that will probably pay for itself in the very first avoided bug. Naturally the internet has plenty of argument healthy debate on this topic.
Missing indexes
Sample application: button 5
We might want to find all Pupils who live in New York. Easy:
|
1 2 3 4 5 6 7 |
string city = "New York"; var pupils = db.Pupils .Where(p => p.City == city) .OrderBy(p => p.LastName) .Select(x => new { x.FirstName, x.LastName }) .ToList(); |
Actually not so easy. We can see that the generated query has taken a while to run.
Luckily this is a fairly easy issue to track down. Because there’s a long-running query, we’ll want to take a look at the execution plan to understand why that query ran slowly. We can see that the most expensive operation is the Table Scan. This means that SQL Server is having to look at every row in the table, and it’s typical to see that take a long time.
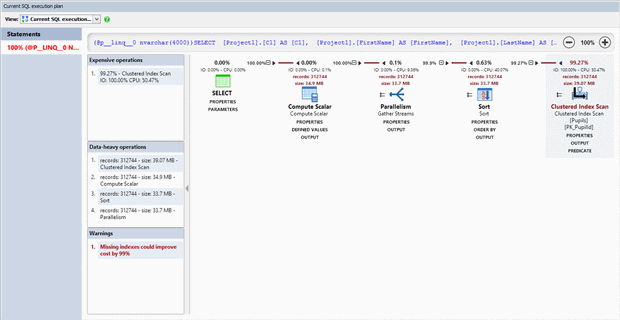
The good news is this can be easily improved. If you’re relying on EF migrations to manage your database schema, you can add a multi-column [Index] attribute which includes the City, FirstName, and LastName properties of the Pupil class. This tells EF that an extra index is needed and when you run an EF migration it will add it to your database.
Alternatively if you are handling your own database migrations, as described in this article for example, then you can add a covering index that includes the City column (ANTS will give you the script to create this index if you click on the warning). You’ll need to give it a few minutes to build, but after that if you rerun the query, it should be nice and fast.
|
1 2 |
CREATE NONCLUSTERED INDEX [NonClusteredIndex_City] ON [dbo].[Pupils] ([City]) INCLUDE ([FirstName], [LastName]) ON [PRIMARY] |
No change exists in isolation though, and maintaining that index has a cost associated with it. Every time that the Pupils table is updated, SQL Server will have to do some extra work to keep the index up to date (not to mention the additional disk space requirements). If you have a table which is primarily used for inserts (an auditing log for example) and which only has occasional ad-hoc queries run against it, it may be preferable to have no indexes in order to gain improved write performance.
This is arguably not an Entity Framework issue, but a general reminder to consider indexing as part of application design (see this article for a general introduction to SQL indexes). It’s one of those trade-offs that you have to make carefully, considering the performance implications for other code or applications sharing the database, and ideally testing to make sure there isn’t unreasonable degradation.
Overly-generic queries
Sample application: button 6
Often we want to do a search that is based on several criteria. For example, we might have a set of four search boxes for a user to complete, where empty boxes are ignored, so write something like:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
//Search data as input by user var searchModel = new Pupil { FirstName = "Ben", LastName = null, City = null, PostalZipCode = null }; List<Pupil> pupils = db.Pupils.Where(p => (searchModel.FirstName == null || p.FirstName == searchModel.FirstName) && (searchModel.LastName == null || p.LastName == searchModel.LastName) && (searchModel.City == null || p.LastName == searchModel.City) && (searchModel.PostalZipCode == null || p.PostalZipCode == searchModel.PostalZipCode) ) .Take(100) .ToList(); |
It’s tempting to hope that the LastName, City, and PostalZipCode clauses, which all evaluate to true because in this case they are null, will be optimized away in .NET, leaving a query along the lines of …
|
1 2 3 4 5 6 7 8 |
DECLARE @p__linq__0 NVARCHAR(20) = 'Ben' SELECT TOP 100 PupilId , FirstName , LastName, etc... FROM dbo.Pupils WHERE FirstName = @p__linq__0 |
We’ll be disappointed – this isn’t how EF query generation works. If we inspect the actual query executed, it looks like this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
-- Generated by ANTS Performance Profiler -- Executed against .\SQL2014 USE [EFSchoolSystem] DECLARE @p__linq__0 NVarChar(4000) SET @p__linq__0 = 'Ben' DECLARE @p__linq__1 NVarChar(4000) SET @p__linq__1 = 'Ben' DECLARE @p__linq__2 NVarChar(4000) SET @p__linq__2 = '' DECLARE @p__linq__3 NVarChar(4000) SET @p__linq__3 = '' DECLARE @p__linq__4 NVarChar(4000) SET @p__linq__4 = '' DECLARE @p__linq__5 NVarChar(4000) SET @p__linq__5 = '' DECLARE @p__linq__6 NVarChar(4000) SET @p__linq__6 = '' DECLARE @p__linq__7 NVarChar(4000) SET @p__linq__7 = '' -- Executed query SELECT TOP (100) [Extent1].[PupilId] AS [PupilId] , [Extent1].[FirstName] AS [FirstName] , [Extent1].[LastName] AS [LastName] , [Extent1].[Address1] AS [Address1] , [Extent1].[Adderss2] AS [Adderss2] , [Extent1].[PostalZipCode] AS [PostalZipCode] , [Extent1].[City] AS [City] , [Extent1].[PhoneNumber] AS [PhoneNumber] , [Extent1].[SchoolId] AS [SchoolId] , [Extent1].[Picture] AS [Picture] FROM [dbo].[Pupils] AS [Extent1] WHERE (@p__linq__0 IS NULL OR [Extent1].[FirstName] = @p__linq__1) AND (@p__linq__2 IS NULL OR [Extent1].[LastName] = @p__linq__3) AND (@p__linq__4 IS NULL OR [Extent1].[LastName] = @p__linq__5) AND (@p__linq__6 IS NULL OR [Extent1].[PostalZipCode] = @p__linq__7) |
For any LINQ statement, a single SQL query is generated, and everything is handled by SQL Server. This query itself looks pretty messy, but since that’s hidden from you, why should it matter? After all, the query runs quickly.
When SQL Server runs a query, it uses the values of the provided parameters along with stored statistics about your data to help estimate an efficient execution plan. These statistics include information about the uniqueness and distribution of the data. Because generating the plan has a cost, SQL Server also caches this execution plan so it doesn’t have to be created again – if you run an identical query in the future (even with different parameter values), the plan will be reused.
The problem caused by caching the plan for these sorts of generic statements is that Entity Framework will then run an identical query, but with different parameter values. If the query is too generic, a plan which was a good fit for one set of parameter values (when searching against FirstName) may be a poor choice for a different type of search. For example if all pupils live in either New York or Boston, the city column will have very low selectivity and a plan originally generated for pupils with a far more selective LastName may be a poor choice.
This problem is called ‘Bad Parameter Sniffing’, and there are far more thorough explanations available elsewhere. It’s worth noting that although these kinds of overly-generic queries make it more likely to hit this kind of issue, it can also occur if a simple query is first run with unrepresentative parameters. For example, imagine that 99% of pupils live in New York, and 1% live in Boston. We might write a simple statement like this:
|
1 |
var pupils = db.Pupils.Where(p => p.City = searchModel.City).ToList(); |
If the first time we run this query, we’re looking for pupils in Boston, then a plan will be generated which may be horribly inefficient for the remaining 99% of pupils (i.e. the remaining 99% of times the query runs).
There are different approaches you can take to resolve this. The first is to make the LINQ statements themselves less generic, perhaps by using logic like this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
if (searchModel.City == null) { pupils = db.Pupils.Where(p => (searchModel.FirstName == null || p.FirstName == searchModel.FirstName) && (searchModel.LastName == null || p.LastName == searchModel.LastName) && (searchModel.PostalZipCode == null || p.PostalZipCode == searchModel.PostalZipCode) ) .Take(100) .ToList(); } else { pupils = db.Pupils.Where(p => (searchModel.FirstName == null || p.FirstName == searchModel.FirstName) && (searchModel.LastName == null || p.LastName == searchModel.LastName) && (searchModel.City == null || p.LastName == searchModel.City) && (searchModel.PostalZipCode == null || p.PostalZipCode == searchModel.PostalZipCode) ) .Take(100) .ToList(); } |
An alternative is to make SQL Server recompile the plans each time. This will add a few milliseconds more CPU on each execution, which would likely only be a problem if the query is one that runs very frequently, or the server is CPU-limited already.
Unfortunately there’s no easy way to do this in EF, but one option is to write a custom database command interceptor to modify the EF-generated SQL before it’s run, to add a “option(recompile)” hint. You can write a class a little like this:
|
1 2 3 4 5 6 7 8 9 10 11 |
public class RecompileDbCommandInterceptor : IDbCommandInterceptor { public void ReaderExecuting(DbCommand command, DbCommandInterceptionContext<DbDataReader> interceptionContext) { if(!command.CommandText.EndsWith(" option(recompile)")) { command.CommandText += " option(recompile)"; } } //and implement other interface members } |
And use it like this:
|
1 2 3 4 |
var interceptor = new RecompileDbCommandInterceptor(); DbInterception.Add(interceptor); var pupils = db.Pupils.Where(p => p.City = city).ToList(); DbInterception.Remove(interceptor); |
Note that this interception is enabled globally, not for the specific instance of the context, so you probably want to disable it again so that other queries aren’t affected.
If you really need to remove a bad existing plan from cache, you can get the plan_handle for the plan by querying the sys.dm_exec_cached_plans Dynamic Management Object (covered shortly) and then manually remove just that particular plan from the cache, using: DBCC FREEPROCCACHE (<insert plan_handle here>).
Bloating the plan cache
Sample application: button 7
In spite of the previous example, the reuse of execution plans is almost always a good thing because it avoids the need to regenerate a plan each time a query is run. In order for a plan to be reused, the statement text must be identical, which as we just saw, is the case for parameterized queries. So far we’ve seen that Entity Framework usually generates parameterized queries when we include values through variables, but there is a case when this doesn’t happen – when we use .Skip() or .Take().
When implementing a paging mechanism we might choose to write the following:
|
1 2 3 4 5 |
var schools = db.Schools .OrderBy(s => s.PostalZipCode) .Skip(model.Page * model.ResultsPerPage) .Take(model.ResultsPerPage) .ToList(); |
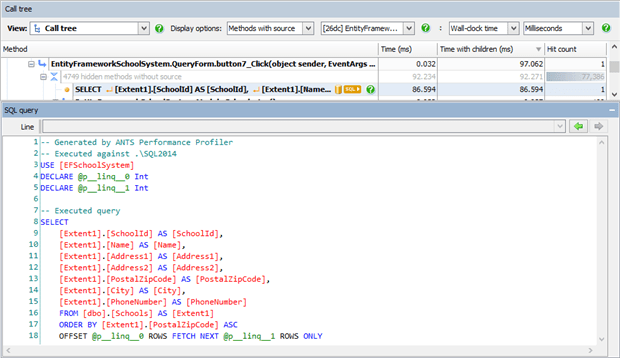
Looking at the executed query we see that the ResultsPerPage (100) and Page (417*100) integers are part of the query text, not parameters. Next time we run this query for, say, page 567, a very slightly different query will be run with a different number, but it will be different enough that SQL Server won’t reuse the execution plan.
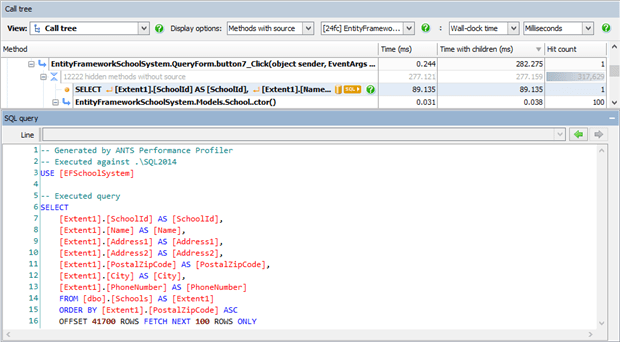
We can look at everything in the plan cache by running the following query (it may help to first empty the cache by running DBCC FREEPROCCACHE). Inspecting the cache after each execution, we’ll see a new entry each time.
|
1 2 3 4 |
SELECT text, query_plan FROM sys.dm_exec_cached_plans CROSS APPLY sys.dm_exec_query_plan(plan_handle) CROSS APPLY sys.dm_exec_sql_text(plan_handle) |
This is bad for several reasons. Firstly it causes an immediate performance hit because Entity Framework has to generate a new query each time, and SQL Server has to generate a new execution plan. Secondly, it significantly increases the memory used both by Entity Framework, which caches all the extra queries, and in SQL Server, which caches the plans even though they are unlikely to be reused. Even worse, if the plan cache becomes large enough SQL Server will remove some plans, and it’s possible that as well as removing these unneeded ones it will also remove unrelated plans, such as the plan for a business-critical reporting query, causing a problem elsewhere.
There are two things you can do about this. Firstly, it’s useful to enable a SQL Server setting called ‘optimize for ad-hoc workloads‘. This makes SQL Server less aggressive at caching plans, and is generally a good thing to enable, but it doesn’t address the underlying issue.
Secondly, the problem occurs in the first place because (due to an implementation detail) when passing an int to the Skip() and Take() methods, Entity Framework can’t see whether they were passed absolute values like Take(100), or a variable like Take(resultsPerPage), so it doesn’t know whether the value should be parameterized. But there’s an easy solution. EF 6 includes versions of Skip() and Take() which take a lambda instead of an int, enabling it to see that variables have been used, and parameterize the query. So we can write the following (you need to ensure you reference System.Data.Entity):
|
1 2 3 4 5 6 |
int resultsToSkip = model.Page * model.ResultsPerPage; var schools = db.Schools .OrderBy(s => s.PostalZipCode) .Skip(() => resultsToSkip) //must pre-calculate this value .Take(() => model.ResultsPerPage) .ToList(); |
Upon rerunning this, we see the results are parameterized, resolving the issue.
Inserting data
When modifying data in SQL Server, Entity Framework will run separate INSERT statements for every row being added. The performance consequences of this are not good if you need to insert a lot of data! You can use a NuGet package, EF.BulkInsert, which batches up Insert statements instead, in much the way that the SqlBulkCopy class does. This approach is also supported out of the box in Entity Framework 7 (released Q1 2016).
If there’s a lot of latency between the application and the database, this problem will be more pronounced.
Extra work in the client
Sometimes the way we access data causes the client application to do extra work without the database itself being affected.
Detecting Changes
Sample application: button 8
We might want to add new pupils to our database, which we can do with code like this:
|
1 2 3 4 5 6 |
for (int i = 0; i < 2000; i++) { Pupil pupil = GetNewPupil(); db.Pupils.Add(pupil); } db.SaveChanges(); |
Unfortunately this takes a long time, and in ANTS’ timeline we can see high CPU usage during this period.
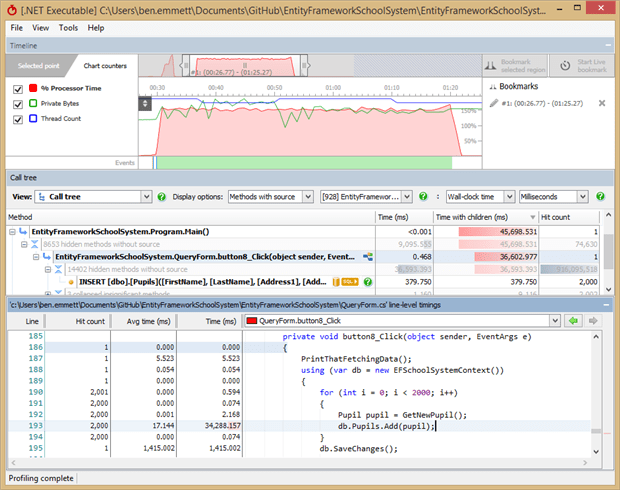
It would have been tempting to assume that the 2,000 insert SQL statements are the problem, but this isn’t the case. In the line-level timing information, we can see that almost all of the time (over 34 seconds in total) was spent in adding Pupils to our context, but that the process of actually writing changes out to the database took a little over 1 second (of which only 379ms was spent in running the queries).
All the time is spent in System code, and if we change the filtering to see where, it’s mostly spent in children of a method called DetectChanges() which is part of the Data.Entity.Core namespace. This method runs 2,000 times, the same number of times as the records we’re trying to add to the database.
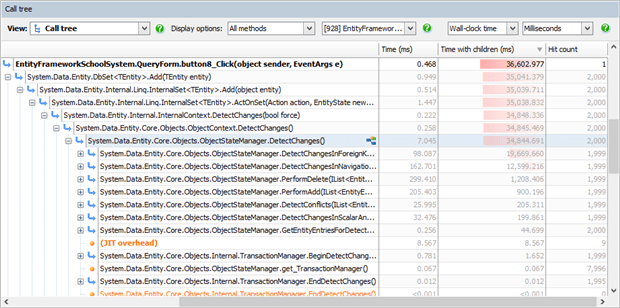
So the time is all being spent tracking changes. Entity Framework will do this by default any time that you add or modify entities, so as you modify more entities, things get slower. In fact the change detection algorithm’s performance degrades exponentially with the number of tracked objects, and hence adding 4,000 new records would be significantly more than twice as slow as adding the 2,000 records as above.
The first answer is to use EF 6’s .AddRange() command, which is much faster because it is optimized for bulk insert. Here is the code:
|
1 2 3 4 5 6 7 8 |
var list = new List<Pupil>(); for (int i = 0; i < 2000; i++) { Pupil pupil = GetNewPupil(); list.Add(pupil); } db.Pupils.AddRange(list); db.SaveChanges(); |
In more complex cases, such as bulk import of multiple classes, you might consider disabling change tracking, which you can do by writing:
|
1 |
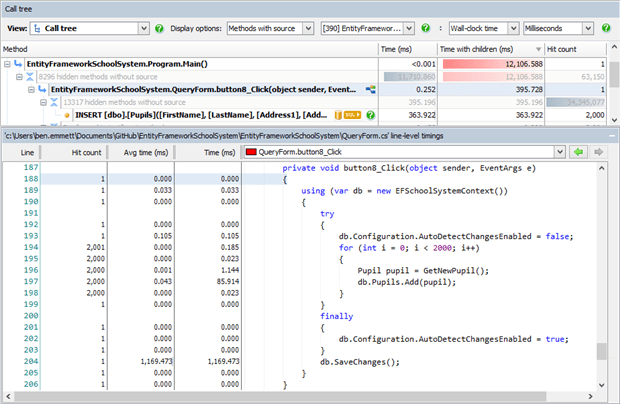
db.Configuration.AutoDetectChangesEnabled = false; |
It’s essential that you re-enable change-tracking afterwards, or you’ll start seeing unexpected behavior, so it usually makes sense to do this in a finally block in case there’s an exception adding the entities. Rerunning with that change in place, we can see that saving changes to the database still takes a little over a second, but the time spent adding the entities to the context has been reduced from 34 seconds down to 85 ms – a 400x speed boost!
Change tracking
When you retrieve entities from the database, it’s possible that you will modify those objects and expect to be able to write them back to the database. Because Entity Framework doesn’t know your intentions, it has to assume that you will make modifications, so must set these objects up to track any changes you make. That adds extra overhead, and also significantly increases memory requirements. This is particularly problematic when retrieving larger data sets.
If you know you only want to read data from a database (for example in an MVC Controller which is just fetching data to pass to a View) you can explicitly tell Entity Framework not to do this tracking:
|
1 2 3 4 5 6 |
string city = "New York"; List<School> schools = db.Schools .AsNoTracking() .Where(s => s.City == city) .Take(100) .ToList(); |
Startup Performance
The importance of startup time varies by application. For a web application which is expected to run for long periods, fast startup is typically not very important, especially if it’s part of a load-balanced environment. On the other hand if a user had to wait two minutes to load a desktop application it wouldn’t look great.
There’s another consideration too: as a developer a slow-starting application becomes tedious, waiting a long time after every debugging iteration. Fortunately there are some things we can do to get EF starting up quickly.
Precompiled views
Ordinarily, when EF is first used, it must generate views which are used to work out what queries to run. This work is only done once per app domain, but it can certainly be time consuming. Fortunately there’s no reason this has to be done at runtime – instead you can use precompiled views to save this work. The easiest way to do this is with the Entity Framework Power Tools VS extension. When you have this installed, right click on your context file, then from the Entity Framework menu, choose Generate Views. A new file will be added to your project.
Of course there’s a catch: this precompiled view is specific to your context, and if you change anything you’ll need to regenerate the precompiled view – if you don’t, you’ll just get an exception when you try to use EF and nothing will work. But this one is well worth doing, particularly for more complex models.
Note: for an in-depth article on precompiling views, including a way to precompile in code, then see this article. There is also a useful NuGet package called EFInteractiveViews that you might like to look at.
Giant contexts
Even if you precompile views, Entity Framework still has to do work when a context is first initialized, and that work is proportional to the number of entities in your model. For just a handful of tables it’s not a lot to worry about.
However, a common way of working with EF is to automatically generate a context from a pre-existing database, and to simply import all objects. At the time this feels prudent as it maximizes your ability to work with the database. Since even fairly modest databases can contain hundreds of objects, the performance implications quickly get out of control, and startup times can range in the minutes. It’s worth considering whether your context actually needs to know about the entire schema, and if not, to remove those objects.
NGen everything
Most assemblies in the .NET Framework come NGen‘d for you automatically – meaning that native code has been pre-JITted. As of Entity Framework 6, the EF assembly isn’t part of this, so it has to be JITted on startup. On slower machines this can take several seconds and will probably take at least a couple of seconds even on a decent machine.
It’s an easy step to NGen Entity Framework. Just run commands like the following:
|
1 2 3 4 |
%WINDIR%\Microsoft.NET\Framework\v4.0.30319\ngen install "C:\Path_To\EntityFramework.dll" %WINDIR%\Microsoft.NET\Framework\v4.0.30319\ngen install "C:\Path_To\EntityFramework.SqlServer.dll" %WINDIR%\Microsoft.NET\Framework64\v4.0.30319\ngen install "C:\Path_To\EntityFramework.dll" %WINDIR%\Microsoft.NET\Framework64\v4.0.30319\ngen install "C:\Path_To\EntityFramework.SqlServer.dll" |
Note that you have to separately NGen the 32 and 64 bit versions, and that as well as NGenning EntityFramework.dll it’s also worth NGenning EntityFramework.SqlServer.dll.
Note: For an in-depth view of using NGen with EF see this article.
Unnecessary queries
We start to get into small gains at this point, but on startup EF can run several queries against the database. By way of example, it starts with a query to find the SQL Server edition which might take a few tens of milliseconds.
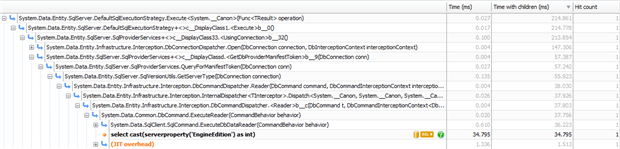
Assuming we already know what SQL Server edition we’re running against, it’s not too hard to override this. We just need to create a class which inherits from IManifestTokenResolver with a method ResolveManifestToken(), which returns our known SQL Server edition. We then create a class which inherits from DbConfiguration, and in its constructor, set the ManifestTokenResolver to our custom class.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
public class CustomDbConfiguration : DbConfiguration { public CustomDbConfiguration() { SetManifestTokenResolver(new CustomManifestTokenResolver()); } } public class CustomManifestTokenResolver : IManifestTokenResolver { public string ResolveManifestToken(DbConnection connection) { return "2012"; } } |
There are various other queries which will also be run if you’re using Migrations, many of which can be eliminated. I won’t go into the details as these typically aren’t very important but you might check them out if every millisecond counts in your application.
Note: I recommend looking at the article ‘Reducing Code First Database Chatter‘ written by the EF Program Manager, Rowan Miller.
Other tips
Disposing
It’s essential to dispose contexts once you’re done with them. It’s best to do this by only creating contexts in a “using” block, but if there are good reasons, you can manually call Dispose() on the context instead when you’re done with it.
If contexts aren’t disposed they cause performance-damaging work for the Garbage Collector, and can also hog database connections which can eventually lead to problems opening new connections to SQL Server.
Multiple result sets
Entity Framework supports Multiple Result Sets, which allows it to make and receive multiple requests to SQL Server over a single connection, reducing the number of roundtrips. This is particularly useful if there’s high latency between your application server and the database. Just make sure your connection string contains:
|
1 |
MultipleActiveResultSets=True; |
Caching
This one isn’t to be taken lightly, because in all but the most trivial cases, getting caching right can be hugely difficult without introducing edge case bugs.
That said, the performance gains can be tremendous, so when you’re in a tight spot it’s always worth considering whether you actually need to hit the database.
Consider Using Async
Support for C#5 Async in Entity Framework 6 is great – all relevant methods which will result in hitting the database have Async equivalents, like ToListAsync, CountAsync, FirstAsync, SaveChangesAsync, etc.
For an application only dealing with one request at a time, using Async isn’t going to affect performance much (and could even make it slightly worse!), but for (eg) web applications trying to support lots of concurrent load, Async can dramatically improve scalability by ensuring that resources are returned to the ThreadPool while queries are running.
For desktop apps, it’s also a really intuitive way to make sure that database access is done off the UI thread.
Note: For an in-depth view of async/await, including example of using Entity Framework async commands, see this article.
Read also: IAsyncEnumerable in C# for streaming large Entity Framework result sets
Upgrade
It’s easy to get behind on versions of libraries, but the Entity Framework team has focused hard on improving performance, so you could see big benefits simply by upgrading. Make sure you’re not missing out!
Test with Realistic Data
In most data access scenarios performance will degrade with the volume of data, and in some cases time taken can even rise exponentially with data volumes. Therefore when performance testing, it’s important to use data which is representative of a live environment. There’s nothing worse than things working fine in a simple dev environment, and breaking in production.
To generate test data for these scenarios I used Redgate’s SQL Data Generator because it makes it fast and easy, but you might be able to just use a backup of production or create data using another technique. The important thing is ensuring you aren’t testing with 20 rows and expecting it to scale happily to a million on deployment day!
Occasionally, EF isn’t the answer
Entity Framework is optimized for accessing relatively small amounts of entity-key-like data, but isn’t usually a great choice for complex reporting or BI applications. There may also be times when you need to fall back to stored procedures (which can be run by Entity Framework), or even different technologies entirely.
Summary
Teams often run into performance difficulties with Entity Framework, particularly when starting out. Some will even consider abandoning the technology entirely, often after relatively little time trying to get it to work well.
It’s worth persisting! Start with a performance profiler that lets you understand both what your application code is doing, and what database queries it runs. Next, combine what it shows you with an understanding of the problems we’ve discussed to identify areas for improvement. Remember that many of these suggestions have their own downsides, so be confident you’re actually suffering from the issue before implementing the change – and of course, you may have no issues at all!
When you’re ready, you can download a free trial of ANTS Performance Profiler.
FAQs: Entity Framework Performance and What You Can Do About It
1. What is the Entity Framework N+1 select problem?
The N+1 problem occurs when EF executes one query to retrieve N entities and then executes N additional queries to load related entities – one per parent record. For example, loading 100 pupils and then accessing each pupil’s School property triggers 100 separate queries for the School table. Fix with eager loading: use .Include(p => p.School) to JOIN the related entity in a single query. Alternatively use explicit loading (.Load()) for cases where you don’t always need the related entity, or projection (.Select()) to retrieve only the columns you need.
2. How do I fix slow Entity Framework startup performance?
EF builds internal model metadata on first use – expensive for large contexts. Fixes: (1) Precompile views by running the EF Power Tools View Generation command, saving the view definitions as a compiled class. (2) Split giant DbContexts into smaller, focused contexts – EF’s startup cost scales with context size. (3) Warm up EF at application startup (e.g., in a background service) rather than on the first user request. (4) Apply NGen to the EF assemblies if they haven’t been pre-JIT’d. These gains are more impactful for desktop or short-lived applications than for long-running web servers.
3. How does change tracking affect Entity Framework performance?
EF tracks every entity returned by a query by default, taking a snapshot of each property value to detect changes for SaveChanges(). For large result sets this creates significant memory and CPU overhead even when you never intend to modify the entities. Disable tracking for read-only queries: use .AsNoTracking() on the query, or configure the context with context.ChangeTracker.QueryTrackingBehavior = QueryTrackingBehavior.NoTracking. Only use tracked queries when you plan to modify the entities and call SaveChanges().
4. When should I not use Entity Framework?
EF is optimised for entity-key-based access to moderate amounts of data – it is not a good fit for: bulk INSERT/UPDATE/DELETE of large datasets (use SqlBulkCopy, EF Extensions, or raw SQL); complex reporting queries that involve aggregations across many tables (use Dapper, raw ADO.NET, or a reporting-specific tool); read-heavy analytical workloads (consider IAsyncEnumerable with raw SQL or Dapper for streaming); and scenarios requiring full control over SQL – specific query hints, temp tables, or non-standard SQL constructs. EF excels at CRUD operations on well-modelled relational data.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments