
It is rare for a technical interview to end without a recursion question being asked of the candidate. Despite this, recursion rarely shows up in production code. It seems that experienced object oriented developers tend to favor loops in their production code. Why?
This article explores this conundrum, as well as recursion and its use in C#.
Recursion
Before you can understand recursion as a programming technique, you need to understand it; and appreciate the main alternative – iteration. Iteration has to be understood over and over again.
Definition
Computer science provides a modest explanation of recursion, the decomposition of a problem’s solution into subsets of the same solution. In other words, the coding of a method which calls itself with smaller inputs to find an answer. Whatever way we define recursion though, we need to mention the two elements underlying recursive solutions. Firstly, methods call themselves. Secondly, and most importantly, each subsequent call will involve smaller chucks of the initial problem until it can be solved without further recursion.
Two canonical examples of recursion are frequently found in the programming textbooks. The first and simpler one is that of calculating a factorial. Here, as an example, is a C# version. Recursion contains the two requisite elements of calling itself with ever decreasing input values. The bounds check, if (input < 2) , ensures exit as the input parameter decreases.
|
1 2 3 4 5 6 |
public static int Recursion(int input) { if (input < 2) return 1; return input * Recursion(input - 1); } |
Variants of our next example, the node-finder, permeates computer science algorithm studies and differs meaningfully from calculating numerical values. The code searches for a specific node contained within a simple tree data structure.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
public class BinaryNode { public int Value { get; set; } public BinaryNode Smaller { get; set; } public BinaryNode Larger { get; set; } public static BinaryNode Find(BinaryNode node, int value) { if (node == null) return null; if (node.Value == value) return node; if (node.Smaller != null && node.Smaller.Value >= value) return Find(node.Smaller, value); return Find(node.Larger, value); } } |
Unlike our previous factorial example, there is no explicit coding of that element of recursion that involves the winnowing-down of the problem set with each recursive call. Find assumes that the underlying tree structure is built as visualized below, with every node having one parent and a parent that only optionally references two child nodes. Also, traversing the tree from the bottom always ends at the root; going down always reaches a null; and there’s only one path between nodes.
Recursion Versus Iteration
According to computer science theory, any recursive method can be re-written iteratively. We can easily demonstrate this when we are computing factorials. The similarity between the Loop method and its recursive brethren is striking. It, too, repeatedly calls a similar piece of code, result *= i , while whittling down the problem via a for-each loop.
|
1 2 3 4 5 6 7 8 9 10 11 |
public static int Loop(int input) { if (input < 2) return 1; var result = 1; for (var i = 2; i <= input; i++) result *= i; return result; } |
The larger volume of code of the iterative solution becomes obvious when you compare the different forms of computation. Loop contains more code to prepare and execute it’s for-each, as well as the seemingly superfluous return statement. In addition to requiring fewer keystrokes, some might even argue that if code can smell then the recursive factorial method has a beautiful fragrance.
Computer science does not tell us when to employ either recursion or iteration. By revisiting our BinaryNode ‘s FindLoop method, we soon get a hint why it does not. The recursive factorial is shorter and sweeter than its iterative twin, and likewise the iterative tree-Node finder, FindLoop looks more awkward than its recursive peer.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
public static BinaryNode FindLoop(BinaryNode node, int value) { var current = node; while (current != null) { if (current.Value == value) return current; if (current.Smaller != null && current.Smaller.Value >= value) current = current.Smaller; else current = current.Larger; } return current; } |
Whatever importance you attach to the looks of the code, both versions of Find get the same results without significant differences. Recursion does not seem, at first glance, to offer any intrinsic benefits over iteration beyond the elegance of the code. Most developers who face the choice between recursion and iteration will usually fall back on personal preference.
Preferences
It is tricky to try to explain preferences. As this article’s opening comments suggest, people can apparently hold opposing positions at the same time. Developers often show that they favor recursion by the relish with which they ask recursion-based interview questions, yet they rarely employ recursion in their applications. A recent academic study by Gunnar R. Bergersen and Dag I.K. Sjøberg, Evaluating Methods and Technologies in Software Engineering with Respect to Developers’ Skill Level, indirectly suggest explanations for this apparent paradox.
Bergersen and Sjøberg begin their paper recounting an earlier study highlighting developer-preferences for recursion over iteration. Only one problem though: the developers questioned for the study were all computer science students in school, and we all know that nobody leaves an algorithms course without an uncritical love of recursion. Their more recent study targeted, in contrast, experienced developers. There the results differed dramatically.
They discovered that inexperienced programmers tended to write noticeably buggier, albeit better performing, code when employing iterative techniques compared to recursion. Experienced programmers on the other hand wrote significantly less error prone and faster routines with iteration. It looked as if skilled professionals lost their youthful passion for recursion when faced with quality and delivery deadlines. And therein lies an explanation for the observed paradox. Developers learn and admire recursion’s theoretical promise, so they ask job applicants about it, but they learn over time that it’s a tough promise to deliver upon when compared to iteration. Maybe they also ask the question to make sure the applicants were awake during their college course.
Pitfalls
Recursion’s fall from the esteem that it gets from academics begs the obvious question: What are the pitfalls? What follows are some of the more likely ones.
Size
Repeated arithmetic calculations can generate big values. While recursion isn’t unique in suffering from the consequences of this, it is prone to overflow exceptions and incorrect output due to not setting explicit bounds. Calculating the factorial for 30 with our sample recursive factorial routine highlights this risk. The correct answer equals 265,252,859,812,191,058,636,308,480,000,000; which far exceeds the modest limits of our Recursion method’s parameter, variables, and the output value’s size limit.
We can solve this by adding the following methods to our Factorial class. The first allows us to catch the OverflowException via a checked block. Adding it forces the typically configured .NET complier to not ignore such exceptions.
|
1 2 3 4 |
public static int RecursionChecked(int input) { checked { return input < 2 ? 1 : input * Recursion(input - 1); } } |
The next method gives our class the capability of handling data types larger than an int for a correct factorial value. It leverages the BigInteger struct, contained within the System.Numerics namespace which was first provided by .NET 4.0
|
1 2 3 4 |
public static BigInteger RecursionBig(BigInteger input) { return input < 2 ? 1 : input * RecursionBig(input - 1); } |
When running all three flavors of our recursive method, the size issue jumps out. Note the unchecked version, Recursion , happily eats the OverflowException ; truncates any intermediary values; and returns the incorrect 1,409,286,144.

Bad Data
Our BinaryNode sample provides its own cautionary tales when working with complex object-based structures. While iterative code can suffer the same fate as recursion when computing values, recursion can make you particularly vulnerable to hazardous assumptions about the underlying data. While we only examine two common issues associated with trees, many others exist.
The first potential problem happens regularly in the field and involves trees containing a node referencing a second parent. While looping structures lend themselves to a simple explicit exit condition to avoid such potential runaway searches, recursive methods by their nature do not. Our Find method will go merrily searching for node 42 until a StackOverflow exception pops.
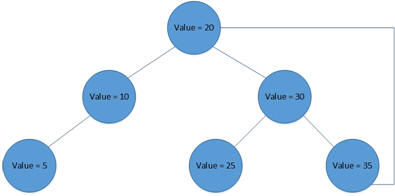
A subtler problem involves tree structures not conforming to expectations. The unbalanced tree stands out as a classic example of this phenomena. An unwary developer could easily assume that all node trees to be balanced with a limited number of levels. What if the tree is unbalanced as pictured below? Searches will not break, they just may take considerably longer than expected.

When Recursion Rocks
Navigating questionable data structures hints at one of recursion’s more successful use cases. When the same recursive code creates the underlying structure, then reading it is not nearly as risky. This “create and read” pattern gives play to many well-known algorithms, such as, QuickSort and MergeSort, where recursive ‘divide and conquer‘ algorithms shine.
Performance
Recursion does not guarantee acceptable performance. In fact, the very usage of recursive algorithms in managed code exacts a small performance penalty. Whether this penalty is worth it is a discussion best left to the same folks concerned with the costs and benefits of garbage collection. Unsuspecting developers though can easily create their very own significant performance issues.
Consider the following implementation of a Fibonacci number. It applies recursion in a somewhat straightforward, simplistic fashion.
|
1 2 3 4 5 6 7 8 9 |
public static class Fibonacci { public static int Recursion(int input) { if (input < 1) return 0; if (input < 2) return 1; return Recursion(input - 1) + Recursion(input - 2); } |
Adding crude execution time checks to the above provides some scary results. Graphing input values ranging from 20 to 45 against the Recursion method’s execution times suggests performance problems exist with our implementation as shown in the exponentially increasing execution time versus linearly growing input values.
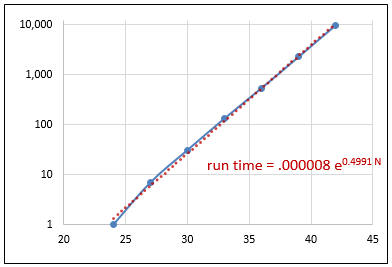
Given that Recursion calls itself twice the exponential slope on the logarithmic graph seems reasonable. Avoiding fast breeding recursive calls when calculating a Fibonacci numbers via recursion requires a little less theory and more practical concerns as demonstrated in RecursionPragmatic .
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
public static int RecursionPragmatic(int input) { if (input < 1) return 0; if (input < 2) return 1; return RecursionTail(input, 0, 1); } private static int RecursionTail(int input, int first, int second) { if (input < 3) return first + second; return RecursionTail(input - 1, second, first + second); } |
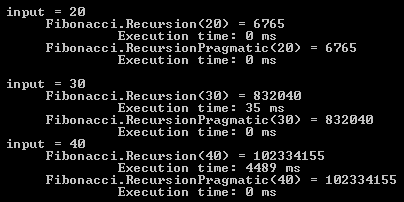
A few timing comparisons with Recursion and RecursionPragmatic confirm the payoff of incorporating some practical touches into a recursive method.
Tail Call
Experienced functional programmers long ago developed techniques for managing state via parameters. The technique, generally known as a tail call, solves other troubling problems too but its effectiveness depends on the runtime and complier. For example, F# fully exploits .NET’s tail call optimizations whereas C# demands a little coaxing as noted in MSDN.
RecursionPragmatic owes its success to the fact that RecursionTail drags around all required state for computation via its parameters. This practical approach limits the RecursionPragmatic’s stack footprint to a minimal collection of pointers.
Before leaving this discussion, savvy readers will have noticed that the code samples are only sketches. They aren’t satisfactory. Calculating Fibonacci numbers under more severe real-world scenarios demands complex techniques, some of which leverage recursion in an equally complex fashion.
Debugging
Unraveling a deep call stack to find that errant instance of a recursive method can be painful. Experience suggests injecting logging similar to that demonstrated in RecursionBlowup as the only foolproof defense.
|
1 2 3 4 5 6 7 |
public static int RecursionBlowup(int input) { if (input == 7) throw new Exception(string.Format("Hit by a {0}!", input)); return input < 2 ? 1 : input * RecursionBlowup(input - 1); } |
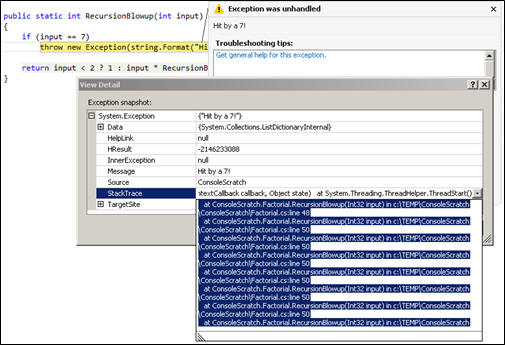
Only one trouble with logging. Developers must know beforehand what to watch out for in order to properly log it. Imagine we did not know the dangers of being seven? The sample debugging screen shot below promises a long walk down stack trace lane..
Avoiding Pitfalls
Given the above pitfalls, here are a few suggestions for avoiding them when working with recursion.
- Manipulating large values or complex objects will likely require explicit type, and boundary, checks such as those found within an iterative implementations.
- Applying simplistic recursive thinking without care may lead to incorrect results and performance issues.
- Maintaining state within a deep recursive call chain may demand refactoring or workarounds, such as, tail calls.
- Debugging difficulties that are encountered when using non-trivial recursive methods may dictate logging and perseverance.
Conclusion
Our recursion excursion covered a good deal of practical ground. We reviewed recursion and explored why experienced developers talk ‘recursion’ but code ‘iteration’. And while definitive guidelines for writing recursive methods must remain implementation-specific, some well-known pitfalls that I’ve described should suggest to you about when to use recursion.
Finally and hopefully, the article’s abstemiousness with recursion jokes compensated the reader for whatever its code lacked in correctness or beauty.
Load comments