
If you have only lived in the tranquil world of client-server version source control systems, inhabited by such predictable beasts as SVN and TFS, your first encounter with a distributed version control system (DVCS) might prove frustrating and scary. While both client-server and distributed systems share many commands, icons and menus they work quite differently.
This article introduces a few DVCS concepts using Mercurial, a popular version control system, as an example.
The Next Generation
Many experts consider today’s distributed version control systems, such as, GIT, Mercurial or Veracity, to be the latest generation of version control software. Their architecture goes beyond that of the previous generations’ client-server designs, and it isn’t surprising that they demand a different mindset to use them effectively.
Risky Business
Labeling a vendor’s version control product as either distributed or client-server is a risky business. Many of them claim to support both architectures. For example, when Microsoft announced a DVC-Team Foundation Server (TFS) solution did that make TFS a client-server, distributed or a hybrid version control system?
Architecture
Version control exists in order to allow several users to edit the same set of text files with minimum pain. There are many ways to accomplish this. The more traditional Client-server version control solutions use file locking, whereas distributed version control solutions prefer repository change coordination as shown below.
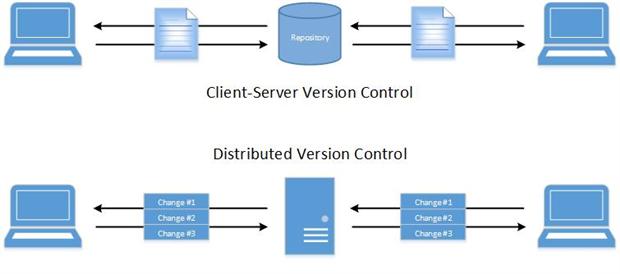
Distributed Means Distributed
Our article presents a relatively modest “centralized distributed version control” layout. Distributed Version Control Systems in the Enterprise explores several more complex layouts. Despite the simplicity of our layout it may very well be one of the most common in today’s enterprise.
The first Version Control systems used File-locking within a centralized repository. This involves explicitly checking out a file, and then checking it in after you’ve finished editing it. Such an approach ensures that only one user can change a specific file, but it also means that other users cannot change it until you’ve checked it in. This has developed into an ‘optimistic’ model where the system attempts to merge the contents of any file that has been worked on by two different people at the same time.
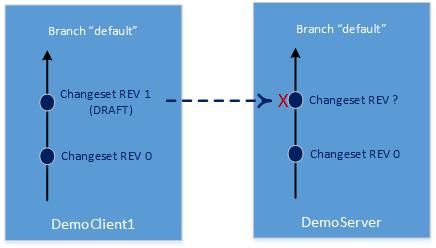
Distributed version control systems build on this idea. Users still check files in and out of a repository except that now the repository is local and unshared. This essentially eradicates any file locking issues. It also introduces a new challenge: Instead of checking in a file users now must synchronize their local repository with the central repository, as this graphic shows.
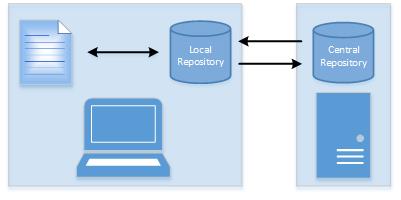
It’d be nice to just lock them both and overwrite the older one. However, not even Client-server Version Control systems do that nowadays. It defeats the reason for team-based version control. To help overcome this synchronization obstacle, distributed version control systems use the concepts of changesets and branches.
DVC tools bundle up all changes, such as files and folders, into a changeset. The changeset is then forwarded to the appropriate repository branch.
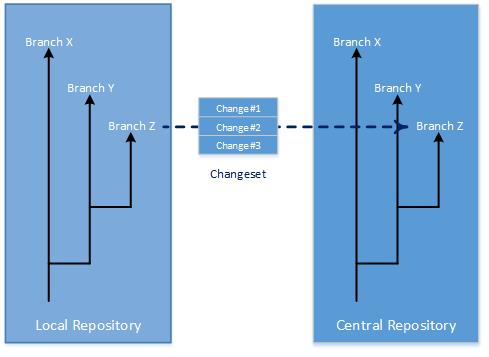
To apply the changeset to its branch, you need one other piece of information. Where in the branch does the changeset belong? Distributed version control systems answer this question by remembering the identity of the changeset from which the new one started.
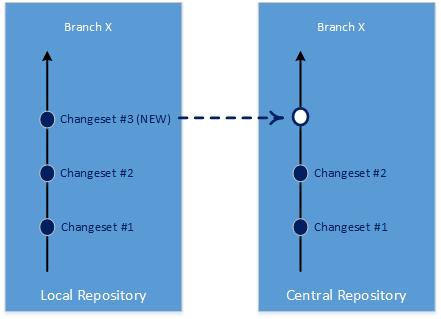
The changeset architecture serves another helpful function. It allows two repositories to efficiently synchronize with each other in most situations by only exchanging some changesets, thereby rather than having to copy an entire repository.
Technically speaking…
Distributed version control systems manage changesets as a directed acyclic graph. Relating changesets in this fashion allows for adding a new one without altering the repository before the addition.
Distributed version control does not avoid one substantial pain point of the client-server variant. Files within a changeset that don’t match the central repository’s version have to be reconciled. Users still need to merge their files’ changes with the central repository’s files.
Changing Mindset
Distributed repositories are very different to work with than server-managed files.
To begin with, client-server source control tools such as Team Foundation Server (TFS) expect users to execute “get latest” when refreshing their local copies of files. Distributed tools, such as Mercurial, expect a “pull” command to obtain any changesets from the central server that their local repository does not possess.
To commit changes to a local file, a user must first check it out from the client-server source control repository, and then check it in. Distributed tools involve a two-step process. First, users commit their changes to their local repository which creates a changeset. Second, they “push” this new changeset to the central repository.
Distributed version control tools place another, subtler demand on users. Every changeset is bound to a specific antecedent changeset along a specific branch. Therefore, whenever a user initiates a change they must establish that point. In technical parlance, users must set the “rev”, “revision” or “tip” that they’re working.
Basic Operations
Let’s start our review of basic operations with an existential crisis. Our imaginary software developer cannot get their local committed changes to the Mercurial central repository. We will work through how they discover and address the problem via Hg Workbench.
The scenario involves two developers, Client 1 and Client 2. Each of these developers sport their own repository, DemoClient1 and DemoClient2 which synchronize with the central repository DemoServer. Client 1’s inability to push their latest changes to DemoServer kicks off the crisis…
Note: Our basic operations chat begins where a tutorial covered later in this article ends. This backward approach is not accidental. The tutorial covers product and command line details readers may not find too interesting. Our current discussion focuses on basic distributed version control tool activities.
Push
Client 1 completed the process of updating File1.txt and committed the changes to the local repository DemoClient1. The tragedy begins with the launching of the Hg Workbench and clicking the push button ( ). The central repository’s harsh, pink highlighted response informs Client 1 that the request cannot be executed and is therefore aborted. It informs the user why; the two repositories, DemoCleint1 and DemoServer, are not synchronized. The pink window also suggests two fixes.
). The central repository’s harsh, pink highlighted response informs Client 1 that the request cannot be executed and is therefore aborted. It informs the user why; the two repositories, DemoCleint1 and DemoServer, are not synchronized. The pink window also suggests two fixes.
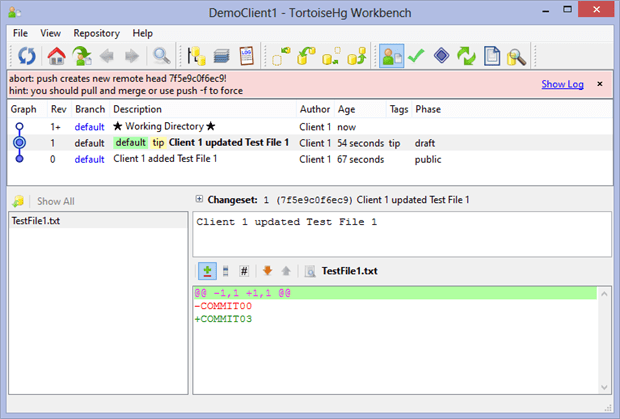
The pink window recommends that Client 1 either “pull and merge” or “push -f to force” in order the get the gray highlighted Rev 1, “Client 1 updated Test File 1” changeset into DemoServer. Since anyone would be right to regard the notion of forcing change as being scary Client 1 elects the first recommendation.
Before pulling anything, it helps to visualize the likely explanation for the cause of the Version Control system aborting Client 1’s “push”. Using our earlier branch-changeset graphic, you can guess that that another changeset node has jumped into the DemoServer‘s default branch before Client 1’s Rev 1 arrived.
Pull
Clicking the pull button,  , updates the Workbench’s ‘Revision Graph Details’ window as shown.
, updates the Workbench’s ‘Revision Graph Details’ window as shown.
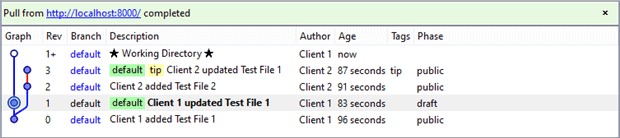
Our node diagram confirms our suspicions. Client 2 pushed changesets Rev 2 and Rev 3 into the central repository leaving our Rev 1 changeset adrift of it in the antecedent node. Client 1 needs to merge Rev 1 with the latest collection of changesets.
Note: The automatic splitting of the default branch into two branches as depicted by the Revision Graph Details windows confuses some first-time DVCS users. This confusion applies especially to developers reared on a client-server tool where branching had the pariah status of development option of last resort.
Merge
Merging begins with Client 1 switching their context to the latest changeset node. In Mercurial parlance, Client 1 “updates” their local version of source-controlled files to those of DemoServer by right-clicking the blue dot of Rev 3. Workbench reflects Client 1’s decision by changing the tip or “Rev” to the highlighted changeset as shown below.
Mercurial’s merge process begins with Client 1 right-clicking the Rev 1 changeset and executing the “Merge with local…” menu item. This kicks off a wizard-like exercise walking Client 1 through a series of steps which includes resolving any file differences. If Client 1 successfully works through these steps, then the Revision Graph Details window as shown below displays a new changeset that captures these implicit merge edits.
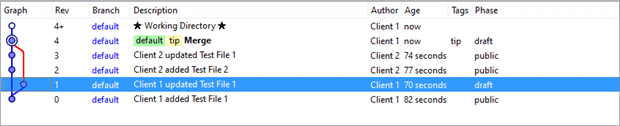
Merging Still Matters
Some enterprises adopt a distributed version control solution in the belief that it simplifies the process of merging different source code branches. The changeset-node architecture along with the state of the art merging algorithms found in most DVC tools surely ease the worst of merge madness. But figuring out what stays and what goes when two files must become one remains a headache.
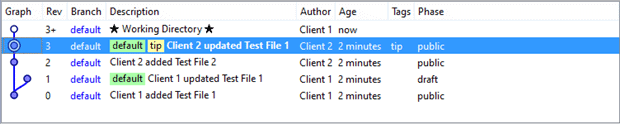
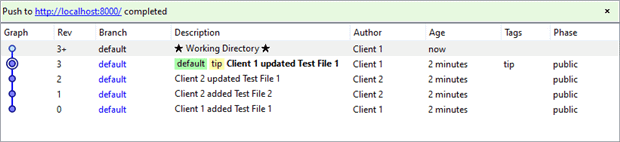
With both the local and server repositories synchronized, Client 1 is then ready to “push” once more, except this time with two changesets, the original Rev 1 and the merge Rev 4. Assuming Client 2 did not change something since the last “pull”, the “push” command succeeds as shown below in Client’s Workbench.
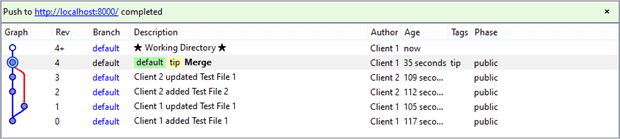
Client 1’s crisis has ended. The central repository, DemoServer, now includes the Rev 1 changeset which initiated the crisis. Workbench confirms the fact with the green window’s text along with the “Phase” grid column of the two changesets. Before the push, the changesets’ exhibited a “draft” phase. Afterwards the phase they became “public” and available to any repositories working with DemoServer.
Rebase
Some users find this merge process cumbersome if not graphically unappealing. Why bother creating a second merge changeset and a short-lived branch just because another changeset jumped in? Couldn’t Client 1 simply update the DemoClient1 repository and reapply the Rev 1 changeset? The short answer is yes; the supporting magic goes by the name “Rebase”.
The decision to rebase occurs temporally and graphically at the same point as the “Merge with local…” option joined the fray as shown below.
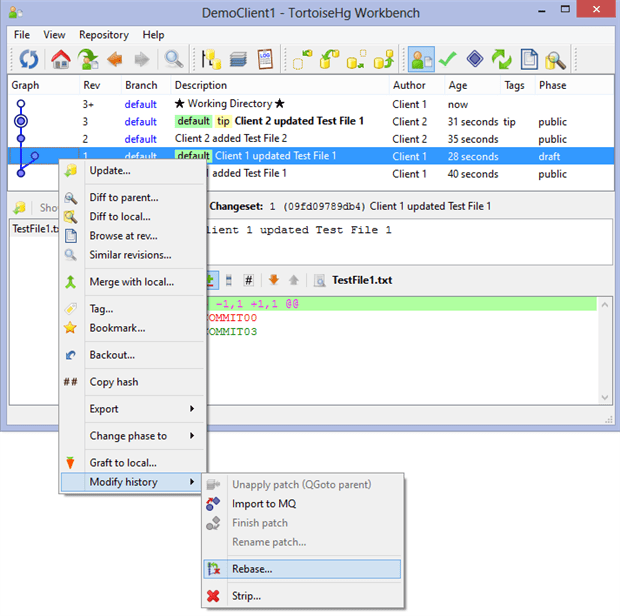
As with the “Merge with local…” menu, “Rebase…” initiates a wizard-like workflow that helps the user to resolve any file differences. The difference is that, this time, when the wizard finishes, the Workbench displays a cleaner Revision Graph Details window.
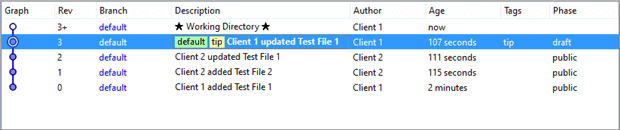
Our simpler node graph happens after the rebase process tricks the local repository into believing that Client 1’s original changeset began with the central repository’s latest changeset, Rev 2. It does so by helping Client 1 to synchronize repositories and then quietly recreate the original changeset with the appropriate antecedent. You’d be able to confirm the story by carefully comparing the graphs that followed clicking “Merge with local…” versus “Rebase…” menus. (Hint: Look at the Rev 1 changeset.)
By pushing the rebase changeset to DemoServer, we leave Client 1 emotionally uncompromised as well as artistically uncluttered: as show below.
Merge or Rebase?
Developers often ask whether it is better to merge or rebase. Ignoring artistic biases for linear or bumpy changeset graphs and complex technical minutiae, experience suggests a simple rule. If possible, rebase draft changesets; always merge public. Put another way, once a changeset hits the central server do not rebase – it’ll likely confuse other developers.
Tutorial Time
Rather than letting you struggle to learn distributed version control basics with a production repository, I’ll describe in this section the process of setting up and playing with Mercurial on a Windows computer. Our discussion covers several of the more ubiquitous ideas and line commands.
Installation
Readers expecting pain when installing a server product on their computer will be disappointed. Installing and running Mercurial borders on fun. Start the exercise by downloading the appropriate OS version.
Note: The discussion that follows used the “Mercurial 2.5.1 MSI installer – x86 Windows” install.
After downloading the installation executable, unblock and click it. You are unlikely to endanger life by choosing any of the various installation options or defaults. The defaults should be fine for most requirements. Now run Mercurial via the command window.
Initialization
Here are the commands used to create a local “server” repository and a local “client” repository.
Starting from the root, which for this discussion will be C:\, we will create the required directories and repositories. All of the commands are either DOS, in upper case, or Mercury, in lower case. All Mercury commands begin with the hg prefix. (Why “hg”? It’s the periodical table identifier for the Mercury element.)
|
1 2 3 |
MD HgDemo hg init c:\HGDemo\DemoServer hg init c:\HGDemo\DemoClient1 |
The init command creates directories and files for the “DemoServer” and “DemoClient1” repositories. Before going we need to attend to some further minor configuration information.
First, visit the C:\HgDemo\DemoServer\.hgdirectory. Once there create the file hgrc (no extension!) with your text editor and paste in these lines.
|
1 2 3 |
[web] push_ssl=False allow_push=* |
The two settings, push_ssl and allow_push enable our DemoServer repository to behave as a centralized repository.
Warning: The above [web] settings are unsuitable for production, but they are perfect for experimenting locally with Mercurial. For example, push ssl=False allows any user to push and pull changes to DemoServer without permission.
Next, visit the C:\HgDemo\DemoClient1\.hg directory. There, create another hgrc file and paste in the below.
|
1 2 3 4 5 6 7 |
[paths] default = http://localhost:8000/ [ui] username = Client 1 <client1@test.com> [extensions] rebase = mq = |
The first setting, default, links Client 1’s repository to DemoServer. The obvious username property gives DemoClient1 a default user when working other repositories. The last two settings expose DemoClient1 users to the rebase functionality as discussed earlier in this article.

With this file structure in place the repository can now be started with this serve command.
|
1 2 |
CD c:\HGDemo\DemoServer hg serve |
If we have configured everything properly, then http://localhost:8000/ displays an empty DemoServer repository. Closing the command window or pressing CONTROL+C within will stop the server.
Now that our initialization efforts are wrapped up, it is time to put the DemoServer repository to work.
Working with DemoClient1
Client 1’s work begins with a new command window. Inside of it we will add TestFile1.txt; commit it to the DemoClient1 repository; and push it to the DemoServer repository.
|
1 2 3 4 5 |
CD C:\HgDemo\DemoClient1\ ECHO COMMIT00 > TestFile1.txt hg add hg commit -m "Client 1 added Test File 1" hg push |
The hg command, add, notifies the DemoClient1 repository of the new TestFile1 file. Client1 can then commit it to the DemoClient1 via hg commit. The -m parameter prefaces the required comment when committing a change. The last hg command, push, forwards the changeset to the DemoServer repository.
Working with DemoClient2
With a populated central repository, Client 2 joins the fray by copying the DemoServer repository. Whereas Client 1 manually performed this task by configuring the path to DemoServer, Client2 takes a quicker and more typical route via the clone command within a new command window.
|
1 2 3 |
MD C:\HgDemo\DemoClient2\ CD C:\HgDemo\DemoClient2\ hg clone http://localhost:8000/ |
The hg clone command performs two tasks. First, it automatically populates the C:\HgDemo\DemoClient2\ directory with TestFile1.txt file. Second, it creates the C:\HgDemo\DemoClient2\.hg\hgrc file with the text “[paths] default = http://localhost:8000/”.
Before performing any work though, Client 2’s DemoClient2 repository needs a little more configuration information akin to that of DemoCient1. Open C:\HgDemo\DemoClient2\.hg\hgrc and add the below after the existing [paths] default = http://localhost:8000/ text.
|
1 2 3 4 5 |
[ui] username = Client 2 <client2@test.com> [extensions] rebase = mq = |
With DemoCient2 configured, Client 2 may now work with their local repository and DemoServer. The next four commands add the file, TestFile2.txt, with the text “Committ01” and push it to the central repository.
|
1 2 3 4 |
ECHO COMMIT01 > TestFile2.txt hg add hg commit -m "Client 2 added Test File 2" hg push |
Client 2 is a busy developer and now updates the original TestFile1.txt with the below.
|
1 2 3 |
ECHO COMMIT02 > TestFile1.txt hg commit -m "Client 2 updated Test File 1" hg push |
Working (again) with DemoClient1
Client 1 was not slacking while Client 2 hammered away. Client 1 stayed busy editing and committing TestFile1.txt changes.
|
1 2 3 |
CD C:\HgDemo\DemoClient1\ ECHO COMMIT03 > TestFile1.txt hg commit -m " Client 1 updated Test File 1" |
Some readers might wonder why the last command did not generate some kind of warning. How can both Client 1 and Client 2 alter and commit changes to TestFile1.txt? It turns out that Client 1’s repository does not know about Client 2’s edits which were committed to both DemoClient1 and DemoServer repositories. As discussed in the earlier Basic Operations section of this article, Client 1 will need to resolve the different edits.
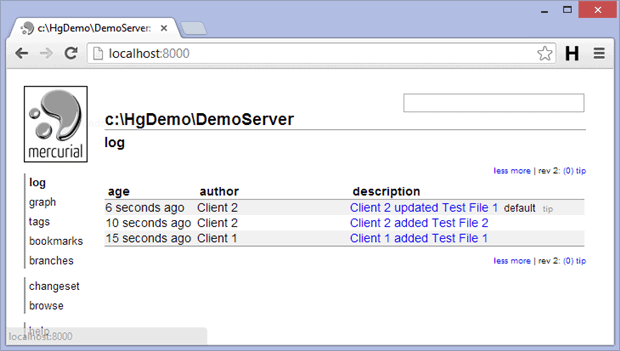
Readers successfully completing this tutorial and visiting their local DemoServer‘s web site should see a page similar to that displayed below.
Conclusion
Our introduction ends with three points. First, we only skimmed the surface of distributed version control systems with Mercurial. Readers wishing to dive further may find Learn Mercurial worth exploring. Second, many Mercurial users don’t find all the built-in tools productive. For example, they might catch a lift with PowerShell scripts like Posh-Hg. Lastly, personal thanks to my friends at Thomson Reuters. Still amazes me that Barnabas H, Chad A, Rob G and Troy D never stopped providing intelligent answers to my many dumb questions. Thank you.
Load comments