
I always hope there is no place
for bugbears in my database
and wish that no one ever sees
a bugbear in my foreign keys.
So bugbear go! for I don’t need’ya
bugging up my stored procedure
causing table locks, and things
suddenly truncating strings,
endless loops and other terrors
like rogue spids and rounding errors.
Bugbears causing sudden death
in a tested UDF
Routines that have worked for days,
fail in unexpected ways
It’s the bugbears at their game
surely I am not to blame.
Is the database offline?
it’s the bugbears’ fault not mine
– Phil Factor, 2007
When deploying database changes, automated testing is critical to a successful DLM approach. You need to know that a database change does what you want it to do and, more importantly, that you have not introduced any ‘bugbears’, or other unwanted side effects.
Database tests need to prove that the database always meets the requirements defined by the tests. We need database unit tests, to prove that the individual units of code always function as predicted, and return the expected data. We need integration tests to make sure that all the required units work together properly, to implement business processes. We need tests to ensure that the database application performs and scales to requirements, and conforms to all security requirements. As much as possible of all this needs to be automated, and ideally “left-shifted” so that such testing is incorporated in your Database Continuous Integration process.
The point of database testing
The DLM approach to database testing requires that the development team establish a working version of the database very early in the development cycle, and then build a suite a database tests that will verify that it remains in a working state, as they continue to build and refactor the database schema and code. In addition, they need tests to confirm that the application always meets its requirements in terms performance, scalability and security, and that no change they make causes ‘regressions’ in any other part of the application, or in any other connected systems.
Some of this is involves classic ‘black box’ testing of the database interface. For example, does a stored procedure or function always returns the expected data, in the expected structure (correct column names and types), for the whole range of data or parameter values that a user can supply? When inserting or modifying data, do the correct data values always get persisted?
We also need ‘internal’ database tests to ensure that no change made, during development, and no action the user can perform, will violate data integrity. The tests will need to confirm that the PRIMARY KEY and FOREIGN KEY constraints enforce referential integrity correctly, and avoid ‘orphaned’ data values, and that CHECK constraints and other rules exist to ensure that no part of the application can insert data values, or modify them, such that they fall outside the valid domain of values defined by the business. Using automated testing, we need to prove not only that a database persists the correct data but that it also rejects incorrect data from being stored.
In addition, database load and performance tests must demonstrate how the application will behave under real, concurrent access conditions when other transactions may be updating data in a table at the same time as your transaction wants to read it.
Finally, the testing regime must, as far as possible, account for complex interdependencies that exist in real, enterprise database systems, where the same table may be accessed by several OLTP applications, as well as a reporting application, ETL processes, replication processes, change capture processes, and so on. Often, one seemingly small change to a data structure during development can have myriad potential consequences in the enterprise database system. Tests must be in place to catch such ‘breaking changes’ as early as possible in the development cycle.
Special challenges of database testing
This section briefly summarizes just a few of the key challenges of testing databases effectively, compared with ‘normal’ application testing.
Tests need to verify database ‘migrations’
A typical application consists of pre-compiled binaries. Replacing an old version of code with a new version means shutting down the application, making the switch, then restarting. This is not generally possible with a database. Instead, you need to ‘migrate’ the state of the existing database to match the desired state, without compromising or losing any of the existing data.
Whether you write database migration scripts manually, or use a tool, we must test them thoroughly to make sure that the final database state, including the data, is exactly as we expected. The only way to make rapid changes safely is to have automated tests verify that the verify the database state, post change, is exactly as expected, and therefore that the change is safe.
Tests need to account for complex database interdependencies
When working on data and code in a database, the developer is effectively working on a set of public objects, much like working with a public API. While, hopefully, permissions are in place to restrict access to base tables, the fact remains that in many cases, database objects, including tables can be accessed by several applications including a front-end website, an ETL process, ad-hoc reporting by users, and so on.
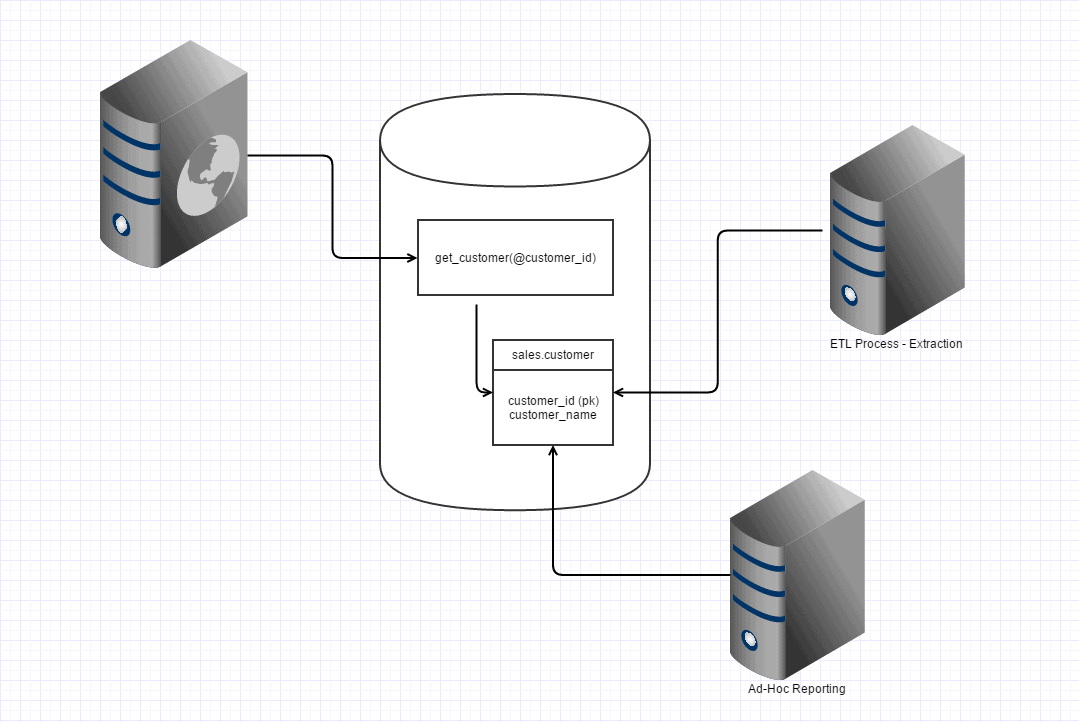
Figure 1
In the example shown in Figure 1, any change to the sales-customer table could, potentially, break one of the dependent processes or applications. If, for example, we have a set of tests that cover the change to the structure of the table, then as we make changes to the table and we break other parts of the system we are aware of those issues as and when we run the tests.
For example, let’s say we have a unit test that verifies that when we pass in a customer_id to the get_customer procedure, we get back the one customer we expect. Effectively, this test puts in place a contract that says:
- When we call
get_customer- We pass in a
customer_id - We want back the one
customer_namethatmatches_thatcustomer_id
- We pass in a
If any changes are made anywhere in the system that breaks this contract, then the unit test will fail and the developer knows there and then that they will need to fix that before moving on. Ideally, the build system for the database would also have tests that cover each of the interfaces used by any dependent systems. If a ETL processes reads 10 columns from the customers table, there should be a test that reads those 10 columns
By building up a suite of such tests, any developer who uses the database can be sure that their changes will not affect the rest of the system, without having to have an in-depth knowledge of the entire system. This has the added advantage that developers can work on areas of the system that they do not necessarily have an in-depth knowledge about which reduces code ownership and the need to defer all work to a subject matter expert.
For enterprise databases, the dependencies get more complex, and each change to a table has potential impact on many dependent objects and processes, both at the database level (replication and CDC processes, indexes, triggers and so on), as well as at the server level (jobs, linked servers, database mirroring processes and so on). Whilst larger databases are going to require a significant investment in the test code, it will always pay dividends over manual testing in terms of time to test and risk associated with each release.
Effective database testing requires real data
When we write a function or method in application code, we know exactly how this code will be called, exactly how it will be executed when called, and therefore how it will behave when called concurrently from multiple end-user processes. It also means we can reason more easily about the likely impact on other processes running concurrently on the machine.
Database programming is declarative. The SQL Programmer does not decide how the relational database engine executes the submitted code, only what data set we would like that code to return. A component of that engine, called the optimizer, devises an execution plan that sets out exactly how the execution engine should execute the code. The optimizer examines the text of the SQL we submit, the available database structures, and uses statistical knowledge of the volume and distribution of data in the database to determine how many rows are likely to be retuned, and to make decisions such as:
- Which indexes will be used to access the data, and how
- Where data needs to be joined together, the method of joining data
- How data is filtered and ordered and aggregated
The execution engine executes the submitted query, per the optimizer’s plan, and takes care of reading and writing data to memory and disk, controls what locks need to be taken, and so on. If our queries take a long time to complete, monopolize processing time, cause locks to be held longer than necessary, then it means our code will not only perform and scale poorly, but will also ‘block’ and disrupt other processes attempting to access the same data.
All this means that how our SQL code executes depends not only on the logic of our data access methods, but also on the optimizer’s choices, which in turn depend on its knowledge of the data, and on the volume and profile of the data.
Traditionally, the database is ‘mocked’ during data access testing, though there is an increasing understanding of the benefits of testing with realistic volumes of “real” data, as early as possible in the development cycle so that the team can properly understand the execution characteristics of their code.
It also allows developers to gain a proper understanding of the data their applications generate and use, and its inter-relations, and to build tests that accrual reflect the true execution characteristics for their code, for whatever unexpected or ‘outlier’ data values their applications may provide.
The need for repeatable testing
Without repeatable testing, we would need to ensure that the entire system still works correctly, after every change or set of changes, and so the time it takes to test database changes is a combination of:
- The complexity of the system
- The complexity of the database
- The complexity of the change
- The knowledge of the system, in that if the developer and tester are SME’s on the database then they will have a higher confidence in knowing what to test
- The knowledge of the data, will they easily be able to tell if data is incorrect or corrupt?
Considering the potential complexity of an enterprise database, and all its upstream and downstream interdependencies, it’s clear that manually testing each change would be a time-consuming process. Similarly, if the team make a whole bunch of changes then manually tests everything to ensure no regressions, then testing becomes laborious, and it’s harder to track down what change caused the problem.
There will always be the need for some manual database testing, but generally developers will want to automate their tests as far as possible, and integrate them into the build and deployment process. There ought to be automated unit tests for every routine, tests for data quality and integrity, integration tests for processes, which include performance tests, scalability test, security and access-control tests and many others.
With automated tests in place, during testing the developer and tester simply need to work together to decide:
- Can the change be unit tested?
- Can the change be integration tested?
- Can the change be acceptance tested?
- If none of these or the change is high risk, then manual testing may be required
The payoff for developers
It takes sustained effort to build, automate and maintain the unit tests, integrations tests, performance tests, and so on, required to test a database effectively. Even more effort is required to be sure that for any database change, these tests capture all the effects on other components processes in the database system.
So, what are the rewards?
Immediate feedback
One of the most obvious is that an effective and automated testing gives the developers immediate feedback on any change they make. They will know what change caused what problem, and can fix it quickly. Developers first write the tests will prove that a small new piece of functionality works. They then implement the code to make the tests pass. When the tests pass, they commit the code to the shared version control system, confident that it can be merged without causing bugs that will disrupt the work of other developers.
All of this reduces the time it takes to develop and to test changes, meaning that changes can be deployed more rapidly, which is ultimately the aim of taking the DLM approach to database changes. It gives the team more confidence to make changes, to refactor or improve individual components. Over time, it gives the organization more confidence that they can allow database changes without fear of disruption.
Faster bug fixing in production
Automated database testing also reduces the time to fix any bugs that are discovered, once the application is in production use, especially if the automated testing is integrated into the DLM pipeline. In response to a reported bug, the team run an automated build of the latest version of the database, provision it with data, reproduce the bug conditions, write failing tests, and then implement and document a fix. The new tests ensure that the bug cannot recur without immediate detection.
A better understanding of how to write maintainable code
The additional payoffs, in my experience, come from adoption of “test-driven” approach to database testing. When a developer writes database tests, especially when they write tests before the code, they must think not only about the logic of the function or procedure they need to implement, but also:
- How each type of object in the database is used and how they interact with each other
- How to specify any required parameters, and what data should be returned, and in what form
- How to setup the data that the test uses to prove that the code is correct
Writing tests forces developers to think beyond writing the code, to how the code will be used, tested and maintained. They must understand how the code they write will interact with the data in the database.
Simpler database code
Generally, the need to think about how to write simple tests that will prove their code works tends to lead developers to write simpler database code, each piece with a singular, specific purpose. For example, let’s say a developer needs to devise code that will:
- Retrieve a set of customer records showing their daily spending
- Run a calculation on those records to get the average daily spend
- Add an entry to an audit trail containing the result
- Return the result
The temptation might be to simply write a single stored procedure to do all the work and return the results. Consequently, you’d then need to write a test that also does a lot of work, to prove the right records are returned, that the calculation is correct, that we always get an entry to the audit trail. If the failing test does lots of things it is often hard to see what exactly what caused the failure.
However, if we think about how to write simple tests that verify just one thing, we tend to break the task down into manageable units, for example, writing a procedure to return the result, another to add an audit log entry, an inline function to perform the calculation, and so on. Each piece of code has a singular purpose and therefore so does each corresponding test, simply needing to verify that it does exactly what it is supposed to do. Being able to test each piece of code in isolation means that we also often get much more maintainable code, as instead of having a single procedure to do everything we can separate our code and re-use in other places.
Types of developer tests
When writing automated database tests, it is important to understand the different types and where some are more useful than others. The best database testing strategy will consist of a mixture of unit tests, integration tests and acceptance tests, which together cover all the functionality of your application, and verify its behavior under all conditions. Integration tests can be sub-divided into functionality, performance and scalability, and security tests.
|
Type |
Description |
Example |
|
Unit tests |
Verify that one object does one thing |
Does the |
|
Integration tests |
Verify that a set of objects work together |
When a new user is created, does a user object get saved to the database along with the users default settings and an email is sent to the user welcoming them to the project? |
|
Acceptance tests |
Verify the behavior of the application, usually in a format that non-technical users can understand |
Unit tests and test-driven development
When people refer to using test driven development, or TDD, what they often mean in practice is that they write unit tests. In other words, they write unit tests first, then write or modify the code, and then use the tests to verify the code works. When writing unit tests, this ‘test first’ approach is useful but you do not have to be practicing TDD to write unit tests and, conversely, if you are writing unit tests you are not necessarily practicing TDD.
Unit tests are pieces of code that verify that another piece of code functions correctly, independently of any other code. Unit tests should just test one property, or behavior, per test and should be fast enough that they can be run by any developer on their own machines, every time they make a change. For unit tests that require access to data, developers should use a local copy of the database, loaded with minimal data.
Let’s return to our earlier example, where we need to calculate a customer’s average daily spend, and write an audit trail entry. Let’s say we break this task down into a combination of stored procedures and inline table functions, as shown in Listing 1.
|
1 2 3 4 5 6 7 8 9 10 |
CREATE PROCEDURE get_customer_summary (@customer_name VARCHAR(25)) AS DECLARE @result MONEY = ( SELECT ds.average_daily_amount AS average_daily_spend FROM Customers c CROSS APPLY dbo.daily_spend(c.customer_id) ds WHERE c.customer_name = @customer_name ); EXEC add_audit_entry 'get_customer_summary', @@username, @result; SELECT @result; |
Listing 1
We have a series of unit tests that each do one thing only:
- Does
get_customer_summaryreturn the correct result? - Does
get_customer_summarycalladd_audit_entry? - Does
dbo.daily_spendreturn the correct result? - Does the audit log get written to by
add_audit_entry?
What we are trying to do is create enough tests so that we cover all the likely outcomes, but at the same time identify the precise cause of an issue quickly. If we mock out the call to add_audit_entry in get_customer_summary, so that if a bug in add_audit_entry causes only the tests for add_audit_entry fail, we know where to start looking. If the tests for add_audit_entry and get_customer_summary all fail, then it points to a broader issue, beyond the scope of the tests, such as a database running out of disk space.
In this manner, what we would like to end up with is a set of unit tests that, firstly, prove that every part of our code is correct and returns the right result, but also stop other changes breaking our code, and offer examples of how the code is used and so provides a level of documentation for the code.
Proving code correctness
This is often the first thing people think of and it is true that this is very important. When you write some code, you need to demonstrate that it does what you want it to do. A typical unit test will prove that, given some known inputs, which could either be parameters or data you have setup in a table, that you always get the correct outputs.
Stop other changes breaking our code
Out unit tests on a given piece of code will help us detect breaking changes to the objects this code calls, to the objects that use this code as a dependency, or indeed to this piece of code.
Let’s say someone was to change the name of a column in a table, or even drop a table on which our code, such as a stored procedure, relies. SQL Server has a feature where you can deploy code that references objects which are yet to be created, or lets you drop or rename objects, without anything more than a warning. If such changes get deployed without running any tests, then you’re only going to find out about the problem at the point someone tries to execute the stored procedure on the database, and gets an error message. Instead, if you ran the code via tests, you would see immediately that the tests failed and that there was a problem that needed to be addressed.
Of course, unit tests hep detect problems with accidental changes, as well as deliberate ones. For example, sometimes a developer will unwittingly check in the wrong code files, or delete the wrong line of code. A good set of unit tests mean that such mistakes are spotted immediately, and we can reduce the chance of causing problems later.
Unit tests as documentation
The third main benefit of unit tests is a controversial one and there aren’t many people who advocate relying only on tests as documentation. Nevertheless, having a good set of tests, with actual examples of how code is used, as well as tests which describe how and when they are used, is excellent living documentation for code.
Unit testing frameworks
Unit testing frameworks fall broadly into two categories:
- Test written in application code – for example, in Microsoft Visual Studio we can use MSTest to write tests in C# or VB.NET, and DBUnit allows developers to write tests in Java.
- Tests written in the language of the database – for example, for Microsoft SQL Server, we can write tests in T-SQL using the tSQLt framework, writing the in T-SQL.
Most developers prefer to write unit tests in their native application language, but it is worth bearing in mind that tSQLt has some additional features that make database testing simpler.
Using tSQLt as a test runner
With tSQLt, you define a list of tests in your code and tSQLt will run all your tests and report the status of each one. It also provides various helper procedures such as tSQLt.AssertEquals, which takes two variables and compares them to make sure that they are the same. You can optionally pass in a parameter to display a specific message, for example about which specific assert failed. This is useful, especially when tests are included in automated builds as you get details.
tSQLt will return the result of any tests that either pass or fail. If a test fails, then an exception is raised, so that you can easily run the tests as part of a manual or automated process. If you can run a command against SQL Server, then you can run tSQLt tests.
Mocking tables in tSQLt
tSQLt makes it very easy to mock a table, which makes setting up test data significantly easier, for a normalized database. Let’s say that we have a database schema that looks like Figure 2.
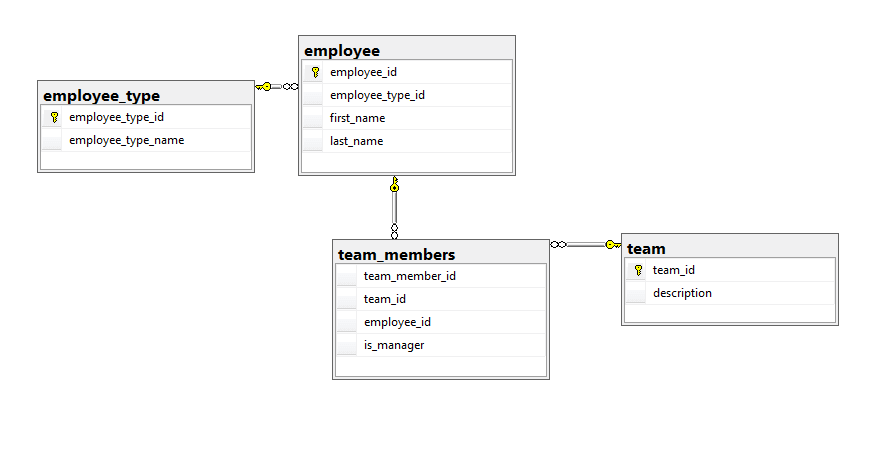
Figure 2
We write a get_employee stored procedure that looks as shown in Listing 2.
|
1 2 3 4 5 6 |
CREATE PROCEDURE get_employee (@employee_id INT) AS SELECT first_name, last_name FROM employee WHERE employee_id = @employee_id; |
Listing 2
We want to write a unit test to check that the get_employee stored procedure always returns the correct employee. For this test, we are interested only in the employee table and only in three columns in that table, employee_id, first_name and last_name.
Since we’re using tsqlt, we write the test itself as a stored procedure (called get_employee_tests). The first thing it needs to do is pre-load some test data so that we have a set of rows that we know exist in the table. The problem with this is that, depending on the relationships and the constraints that exist on the tables, setting up test data can become quite a burden. Our test stored procedure would need to insert into the three other tables row values that complied with the existing keys and constraints. If another developer subsequently adds a new, non-NULL column to any of these tables, but doesn’t define a DEFAULT constraint, then our tests will start failing at the point it tries to insert data, even though the change is potentially unrelated to the object we’re testing.
To help avoid these sorts of problems, tSQLt can specify that a table is going to be used as part of a test and for the lifetime of that test the constraints, including any FOREIGN KEYs are dropped. When the tests finish, the constraints are re-enabled. The process looks like this:
- In the test code call “
exec tSQLt.FakeTable 'TableName', 'SchemaName'“ - Inside a transaction, tSQLt renames the existing table and creates a new table with the same definition but without triggers or defaults
- If you want to re-enable a specific constraint or trigger, then you can call
tSQLt.ApplyTriggerortSQLt.ApplyConstraint. This gives you the ability to test only specific parts of the application. - In your test code, insert the test data you need. It is advisable to add a row that you do want returned, and one that you do not want returned, so you can be sure that not only are you getting the values you do want but you are not getting the values you do not want.
- In your test code, call the stored procedure you want to test and validate the results
Listing 3 shows an example of a tSQLt test for the get_employee stored procedure.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
CREATE PROCEDURE [get_employee_tests].[test correct employee is returned] AS EXEC tSQLt.FakeTable 'employee', 'dbo'; INSERT INTO employee ( employee_id, first_name, last_name ) VALUES (1, 'ignore', 'me'), (2, 'find', 'them'), (3, 'no one', 'here'); CREATE TABLE #results ( first_name VARCHAR(MAX), last_name VARCHAR(MAX) ); INSERT INTO #results EXEC get_employee 2; DECLARE @record_count INT = ( SELECT COUNT(*) FROM #results ); EXEC tSQLt.AssertEquals 1, @record_count; SELECT @record_count = ( SELECT COUNT(*) FROM #results WHERE first_name = 'find' AND last_name = 'them' ); EXEC tSQLt.AssertEquals 1, @record_count; |
Listing 3
In Listing 3, we can see that all we need to do is to call FakeTable for any table that we are going to use as part of the test, and ensure it only has the data that it requires for the test.
This approach makes it simple to setup test data, which makes it easier to write and maintain tests. It also makes the developer think about which tables and columns and rows are required for the test.
Mocking stored procedures with tSQLt
When unit testing, we want to be able to test an object without testing its dependencies. If one object uses another then we want to show that each piece works individually using unit tests, and then use integration tests to show that they work together.
As well as mocking, or faking, tables, tSQLt allows us to mock procedures. When testing code that calls a stored procedure, we can replace that call to a “spy” procedure that simply returns some known values. Interestingly, this means that we can be sure that the code we are testing gets a valid value, even if the stored procedure it is calling is broken. This means that the unit tests on the broken stored procedure should fail but all other unit tests will continue to work.
Listing 4 shows a new version of our get_employee stored procedure.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
CREATE PROCEDURE get_employee (@employee_id INT) AS DECLARE @access_allowed INT; EXEC @access_allowed = security.verify_access @employee_id; IF @access_allowed = 1 BEGIN SELECT first_name, last_name FROM employee WHERE employee_id = @employee_id; EXEC auditing.add_audit_log 'get_employee', @employee_id; END; GO |
Listing 4
We can setup spy procedures for verify_access and auditing.add_audit_log. For example, we can replace the verify_access procedure with a spy procedure that simply returns a value appropriate for that test. This allows us to perform ‘happy’ and ‘not-happy’ path testing without having to set up a lot of test data. The idea is that we should verify both that the procedure works as expected (returns the employee when access is granted), and that it does not work, or do anything unexpected, when we expect it to not work.
Listing 5 shows a sample test for the get_employee stored procedure
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
CREATE PROCEDURE [get_employee_tests].[test results returned when access granted] AS BEGIN EXEC tSQLt.FakeTable 'employee', 'dbo'; EXEC tSQLt.SpyProcedure N'security.verify_access', N'return 1'; INSERT INTO employee ( employee_id, first_name, last_name ) VALUES (1, 'ignore', 'me'), (2, 'find', 'them'), (3, 'no one', 'here'); CREATE TABLE #results ( first_name VARCHAR(MAX), last_name VARCHAR(MAX) ); INSERT INTO #results EXEC get_employee 2; DECLARE @record_count INT = ( SELECT COUNT(*) FROM #results ); EXEC tSQLt.AssertEquals 1, @record_count; SELECT @record_count = ( SELECT COUNT(*) FROM #results WHERE first_name = 'find' AND last_name = 'them' ); EXEC tSQLt.AssertEquals 1, @record_count; SELECT @record_count = ( SELECT COUNT(*) FROM security.verify_access_SpyProcedureLog WHERE employee_id = 2 ); EXEC tSQlt.AssertEquals 1, @record_count; END; |
Listing 5
When a procedure is mocked using spy procedure, a table is created that is available inside the test that is the name of the procedure with "_SpyProcedureLog" appended to the end. This table contains the calls to the procedure and the parameters passed in, so we can query it, as demonstrated toward the end of Listing 5, to verify that the verify_access procedure was called exactly once and the employee_id passed in was “2”.
Using MSTest
MSTest is the testing utility that comes with Visual Studio. The unit tests are implemented using C# code that uses the Visual Studio testing framework, so running tests and including tests in a build process becomes simple. It also means that the tests can run alongside any application unit tests that you might have in the same Visual Studio solution.
If you also have SQL Server Data Tools installed then you get a set of templates to add “SQL Server Unit Tests”, which allow you to setup test data, run some tests and then verify the results. The tests themselves have a basic UI to help develop code and they integrate with the Visual Studio test runner so you can run your tests from within Visual Studio. You do not have to have your database in SSDT to use MSTest to create your tests, and there is no dependency on SSDT database projects.
When you create the SSDT unit tests, Visual Studio will generate C# code as well as T-SQL scripts; the C# code calls the T-SQL scripts to run:
- Before your test
- Your actual test
- After your test
The first step is to ensure you have the correct data set up. So, for example, before running our previous test for the get_employee stored procedure, we’d run a pre-test script that looks like Listing 6.
|
1 2 3 4 5 6 7 8 9 10 11 |
TRUNCATE TABLE employee; INSERT INTO employee ( employee_id, first_name, last_name ) VALUES (1, 'ignore', 'me'), (2, 'find', 'them'), (3, 'no one', 'here'); |
Listing 6
Then the test code is simply exec get_employee 2;. To validate the results, there are many test conditions that you can configure, such as checking that there is a non-empty result set, or that the test returns a specific scalar value. You can use a wizard to generate a checksum for a result set, and include this in your test, so you can be certain that the result is exactly as you expect.

Figure 3
Other unit testing frameworks
A full description of every unit testing framework on the market is out of the scope for this chapter but this is an overview of some of the ones available:
|
Name |
Url |
Overview |
|
SQLUnit |
https://sqlunit.sourceforge.net/ |
Tests are defined using XML and run from Java. These work with any RDBMS that has a JDBC client. |
|
DBUnit |
https://dbunit.sourceforge.net/ |
Cross platform framework for deploying test data and running tests |
|
tSQLt |
|
Microsoft SQL Server specific framework. Includes mocking support. |
|
Visual Studio SQL Server Unit Test |
https://msdn.microsoft.com/en-us/library/jj851212.aspx |
Microsoft Visual Studio templates for creating unit tests that are a mixture of C# and T-SQL |
Integration Testing
Where unit tests aim to verify that each distinct unit of code works in isolation, integration tests validate that all components work together, and the interfaces between them are correctly configured and deployed. Integration tests validate that entire processes or process flows work as expected. For example, you may have an integration test that validates that when a user attempts to logon, if the correct username and password are supplied then access is granted, and an audit log is updated.
When writing integration tests, it is important to take a view of the whole application, and decide what is important and what should be tested. Each application will have its own set of unique tests but there are some general categories of tests that we can start to identify:
- Functionality test – does the process work as expected
- Performance and scalability tests – if performance is important, what are the desired metrics? Does the application process meet those?
- Security tests – Can we prove that the application process is secure?
Having identified the key areas of the application to test, often the hardest part of writing integration tests is creating the infrastructure and framework to run the actual tests.
For example, we need a quick way to generate enough test data in the correct state. What I typically do is have a generic C# class, shown in Listing 7, to represent a table. It takes the table name as a parameter and exposes a “clear” method that deletes all the data in the table, and in any tables that reference the table, by way of a FOREIGN KEY. Each table that inherits from this class implements its own columns as properties that can be used by an ORM such as dapper.net to quickly and easily translate the table object into SQL.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 |
using System; using System.Collections.Generic; using System.Data.SqlClient; using System.Linq; using Dapper; namespace STIntTest { [TestFixture] //nunit tests public class Orders_Table_Tests { [Test] public void Order_Is_Added_For_Customer() { var ordersTable = new OrdersTable("server=.;integrated security=sspi;initial catalog=VSTS"); ordersTable.DeleteAllData(); ordersTable.AddRows(1000); ordersTable.Write(); //execute code.... var rows = ordersTable.GetRows(); Assert.True(rows.Any(p => p.CustomerID == "a_unique_id")); } } public class Table { private readonly string _connectionString; private readonly string _tableName; protected readonly List<object> Rows = new List<object>(); protected Table(string connectionString, string tableName) { _connectionString = connectionString; _tableName = tableName; } public virtual void AddRows(int count) { } public virtual void Write() { } protected void Write(string columns, string values) { foreach (var row in Rows) { using (var connection = new SqlConnection(_connectionString)) { connection.Execute($"insert into {_tableName}({columns}) select {values}", row); } } } public void DeleteAllData() { var tables = GetReferencingTables(); foreach (var table in tables) { using (var connection = new SqlConnection(_connectionString)) { connection.Open(); connection.Execute($"DELETE [{table}]"); } } using (var connection = new SqlConnection(_connectionString)) { connection.Open(); connection.Execute($"DELETE [{_tableName}]"); } } private IEnumerable<string> GetReferencingTables() { //you will likely need to make this a recursive call... using (var connection = new SqlConnection(_connectionString)) { connection.Open(); return connection.Query<string>("SELECT OBJECT_NAME(object_id) ReferencingTable FROM sys.foreign_keys WHERE OBJECT_NAME(referenced_object_id) = @TableName",new {TableName = _tableName}); } } public IEnumerable<dynamic> GetRows() { using (var connection = new SqlConnection(_connectionString)) { connection.Open(); return connection.Query($"SELECT * FROM [{_tableName}]"); } } } public class OrdersTable : Table { public OrdersTable(string connectionString) : base(connectionString, "Orders") { } public override void AddRows(int count) { for (var i = 0; i < count; i++) { Rows.Add(new { CustomerID = "0000ABC" + i, OrderTotal = 102.11 + i }); } } public void AddRow(string customerID, double orderTotal) { Rows.Add(new {CustomerID = customerID, OrderTotal = orderTotal}); } public override void Write() { this.Write("CustomerID, OrderTotal", "@CustomerID, @OrderTotal"); } } public static class Assert { public static bool True(bool result) { return result; } } } |
Listing 7
This seems like a lot of work but once you have a table class for your main tables you can re-use it, and spend more time writing the actual test code.
Typically, our testing framework, such as NUnit, MSTest, Junit or similar will call the application code and perform the following steps:
- Start/Refresh any required infrastructure
- Deploy the code to be tested
- Run the code
- Run the test
- Gather the results
As an example, let’s consider an ETL process that downloads a .csv file from an FTP site, then runs an SSIS package to load the data. What we might end up with is an integration test that:
- Creates a data.csv file, ideally with a unique value that the test knows about
- Starts a local FTP server
- Copies the csv to the local FTP server
- Clears out the target database
- Starts the SSIS package with a custom configuration (possible using dtexec.exe)
- Reads the database and checks that the unique known test values are present
The code needed to implement this test is likely more than the code required to complete the ETL process, but if each step is made available as a separate component that can be shared amongst other tests and projects, then having these tests can provide massive cost savings in terms of time between writing code and detecting failures and diagnosing bugs.
This method of having an integration test that deploys and runs the code with test data is a great way to diagnose and fix bugs. The interesting part of having integration tests like this is that as well as testing the code itself you also start testing your deployment systems – if you have a PowerShell script that deploys your database and reference data, why not use it as the step that sets up your test database. In that way, some of the most well-tested components of your application are the deployment components!
Performance tests
Many teams don’t find out about performance problems until users complain or are unable to work. The goal of performance tests is to prove that any variation in performance, because of changes to the code, or to the infrastructure, can be measured. If we build automated performance testing into the DLM process, then not only can we be sure that the code performs to expectations, and that subsequent changes do not have a negative impact, but we can also performance test potential fixes to production issues before the code is deployed to production.
As for all tests, we need to know when adding more performance tests, or more complexity to existing tests, makes sense. If the performance of a business process is not critical then typically we will not need explicit performance tests. If performance is critical but volumes of data and number of concurrent users is low, then performance testing is relatively lightweight and easy to set up.
Performance testing becomes very important when the performance of a business process is critical, and when the production database has large data volume and or large number concurrent users. In such cases, many organizations attempt to guarantee performance by “throwing money at the problem” and over-spec’ing the hardware, but the most reliable way to ensure acceptable performance, in the long term, is to be able to mimic those conditions in the integration test environment, and perform performance assessments that prove that the process performs and scale to requirement’s.
Performance tests are often just an extension of an integration test. For example, we might have an integration test that works like the previous ETL example, but with additional requirements:
- We need to understand the difference between the test and production hardware
- We need reliable performance ‘baselines’ for comparison
- We need to be able to load data with a volume and profile that matches the production data
- We need a way to simulate production like concurrent loads
- We need a mechanism to record execution time and system metrics, such as CPU usage
Hardware and physical specs
When using test data, it is important to understand the difference between the test and production hardware. Ideally you should have a test rig that has the same hardware specs as production and the same configuration. If you have a three-tiered application in production, mimic that in your performance tests. If your database is in a different data center to your application tier with a large latency, then you must mimic that latency in test.
If in test you have a set of hardware that differs massively from production, then what typically happens is that performance issues in the test environments are ignored and expected to be fixed when moving to production, but this often masks issues that could be fixed early on. If you test with a similar set of hardware, then any performance issues must be fixed in a test environment and not left until production.
Baselines for comparison
Let’s say that, as part of your integration and performance tests, you deploy the latest database build, fill it with data and run the tests. You compare the results to the results from the last set of performance tests, but how can you be sure that nothing lese changed in the test environment that would skew the results? Ideally, you should be able to deploy the current version and the previous version, and run the tests side-by-side, so you can rule out environmental changes.
The best example of this I saw was a team who nightly ran the previous ten releases and charted the performance of the latest set of changes. The main benefit was that if anything was changed on the test server, such as adding additional RAM, the performance across the ten releases is still comparable. If you only test the latest release, you won’t know if any performance increase is attributable to code improvements, or just more of the test database being cached.
Generating or loading production-like data
We need both a realistic volume and realistic profile of data. This is to ensure that you get as close to production results as possible. As discussed earlier, when our application attempts to query a database, during the performance test, the RDBMS will examine the text of the query and generate a query execution plan, or reuse an existing plan if it has seen the exact same text before and plan for that text is still in the plan cache, based on its statistical knowledge of the data. The plan it chooses will depend on any parameter values submitted with the text, the distribution and volume of data in the tables, available indexes, and so on.
If we’re running tests against small sample data sets and, for example, then the optimizer is likely to choose Nested Loop join operators for joining data. If the same query, on production, needs to join two large datasets, the optimizer might instead choose use a Hash Match join which uses temporary storage, which could spill to disk. In other words, the execution profile of your test will not match what’s seen in production. Likewise, if you run a performance test with a table with mostly NULLs, you will likely get different behavior to production, where the data is mostly non-NULL.
Ideally, test data should be generated to the same volume, distribution, characteristics and datatype as the production data, and each type of test may require different test data sets. There are several ways to get production like data in your test systems such as:
- Restore the production database
- Restore the production database, and overwrite any personally identifiable data (PII)
- Build the latest database version, then generate test data using a tool, such as the Redgate SQL Data generator
- Build the latest database version, then manually load realistic test data – e.g. from ‘native’ BCP format using bulk load
Choosing a way to get realistic test data depends on the environment, there are many database applications where the security requirements are such where copying the production data is unacceptable.
Stats only database
Microsoft SQL Server allows you to copy a database schema plus a copy the statistics using DBCC CLONEDATABASE, so the optimizer generates the same plan as it would when the query was run against the production data. For pre-SQL Server 2014 databases, you can create a statistics only database by scripting out the statistics. This is great for looking at and checking execution plans but it should not be used for tests where you time the results as although the plan has the same cost there is a big difference between processing a few pages and processing a few million pages.
Simulating production like loads
The performance of an RDBMS is also affected by other requests currently executing, as hose other request may hold locks on data your query needs, or monopolize CPU resources, cause disk bottlenecks, hog memory resources and so on. Depending on the transaction isolation levels in use, it’s possible for a query to start returning unexpected results when its running concurrently with other queries that are modifying that data.
Ideally, you’ll be able to simulate a background workload reminiscent of what you expect to see in production to catch such “race condition” bugs. There are various tools available to simulate load from multiple concurrent users such as SQLQueryStress or from Microsoft, the RML utilities and ostress. SQL Server can also record a profiler trace and use the RMS utilities distributed replay client to replay requests.
Record execution time
Our performance tests need to demonstrate clearly how a change has affected performance, either positively or negatively. If we measure, store and chart how long it takes to perform a test then we can easily visualize the performance impact of a change, and so predict how that change will behave in production.
One obvious metric to track is simply how long a test takes to run. In a C# test, we can use the System.Diagnostics.Stopwatch class. This is useful to give us an overall “the test took x long” which is a quick metric that shows overall performance. For T-SQL tests, we can capture IO and timing metrics using either the SET STATISTICS IO/TIME T-SQL commands, or using Extended Events. Phil Factor’s article shows one example of setting up a test hardness that captures these metrics plus the query execution plan.
Record server metrics such as CPU usage
Alongside raw timings, we also need to collect SQL Server performance metrics, so that we can start to understand not only what sorts of changes affect performance, and by how much, but also why. By charting these performance metrics, it will, over time, make troubleshooting future performance issues much easier.
One too we can use is Performance Monitor, or Perfmon, which measures various performance statistics on a regular interval, and allows us to save those metrics to a file or to a SQL Server table. We can collect broad server-level metrics relating to disk, processor and memory usage, as well as specific metrics relating to SQL Server’s consumption of I/O, CPU and memory (disk transfer rates, amount of CPU time consumed, and so on).
When a code change causes a significant change in performance, these metrics will highlight the ‘queues’, i.e. possible areas of resource contention, for SQL Server. Typical PerfMon counters I collect include the following:
PhysicalDisk – Avg. Disk sec/ReadPhysicalDisk – Avg. Disk sec/WriteProcessor - % Processor UsageProcess – sqlservr.exe - % Processor UsageSQLServer:Buffer Manager – Buffer cache hit ratioSQLServer:Buffer Manager – Page Life ExpectancySQLServer:Buffer Manager – Target PagesSQLServer:Buffer Manager – Total PagesSQLServer:Locks – Average Wait Time (ms)SQLServer:Locks – Lock Requests/secSQLServer:Locks – Number of Deadlocks/sec
Sometimes, we’ll use these metrics directly within a test. For example, if the Number of Deadlocks/sec metric is non-zero, the test should fail. Others, as discussed, are useful for understanding why a test took to run was too long
We can automate collection of these metrics, using the Performance Analysis of Logs tool, or by running a script that collects them from the Dynamic Management Views, as demonstrated by Jonathan Kehayias in his article, A Performance Troubleshooting Methodology for SQL Server.
As Jonathan discusses in his article, having located areas of recourse contention, you may need to collect further data to pinpoint the cause of the performance problem. A classic analysis is to correlate the resource metrics (the queues) with wait statistics, describing which SQL Server processes are being forced to wait a significant amount of time, before proceeding with their work, and what is causing them to wait.
As you discover common causes of performance problems with your application, you can add new tests that collect data the system catalogs, DMVs, and elsewhere, and then your tests can fail, the y can provide information that will help you identify quickly what caused the issue. In my experience, this approach can drastically reduce troubleshooting time.
Security tests
Security tests are like performance tests in that each application tends to have different security requirements, and you need to understand your requirements before you start. The security tests required for a database with no external access points and that contains no sensitive data are very different from those required for a database that contains user’s personal details and credit card information. In the latter case, you have a legal responsibility to ensure the data is protected correctly, in all environments and during all activities, including testing.
Typically, however, you will need some basic security tests to ensure that:
- Users do not have extra privileges to data they ought not to see
- Inputs are verified and not executed if they are not exactly as expected, so someone called “
jim o'--\r\n drop database db_name()” does not actually cause any harm. - Users are only able to view or modify data to which they have been granted access or modification rights. You need to be sure that a user has the minimum necessary permissions to the data they need, and aren’t member of, for example, powerful server roles, and can’t gain access to other data by simply changing a query string.
Most the work involved in writing security tests is defining what the requirements are and classifying the data. For example, if you have credit card information or personally identifiable data then you need to make sure that the data is encrypted and or secured appropriately. There are various tools to help you keep your data secure and the technology and approach you use will guide what tests you need to write.
Once you have classified your data, you can ensure that the data is secure and that unauthorized users are unable to get to the data. This approach typically requires two tests, one that checks that a user with the appropriate permissions can access the data and one that verifies that a user without the required permissions is unable to access the data.
We also need tests to check that users are unable to send specially crafted inputs that can access, corrupt or steal data, using SQL injection attacks. It is often wise to protect this at different layers in your application and write tests to prove that SQL injection attacks are not possible, but again it depends on the type of application.
It should be obvious but using production data with sensitive information for your test environments is a bad idea, and instead you should either generate test data or sanitize the data before deploying to your test environment. Sanitizing the data needs to be done with care and in a secure environment.
Test coverage
When writing tests, it is not always obvious how many tests and what type of tests are required. If we must implement a login process for a web application, then we should aim to make sure that we have enough tests to show that the individual parts all work in isolation and that the end to end process works, so we might end-up with:
- Acceptance / UI tests that show that the web page accepts the correct input and logs the user in
- Integration tests that check that the “LogonService” call works with the right username and password
- Unit tests for each of the components such as the stored procedure that validates the username and password
In other words, we’ll usually have one or two acceptance tests, a few more integration tests and a lot more unit tests. Overall, we should have ‘covered’ with tests pretty much every line of code and every statement in the application.
When starting to write tests for an existing application, it is often easier to start first with a few integration tests that validate that critical processes work, and later add unit tests as you modify code. If you do this, you will gain the benefit of having as much of the application covered as quickly as possible with the benefit of being able to add unit and integration tests as you go along.
Summary
A DLM approach to database testing will not only prove that an application works as expected in the development environment, but will also give the team confidence that all requirements will continue to be met, and that all processes will continue to behave reliably and correctly, under ‘production’ conditions.
This requires unit tests to verify that each component works correctly, in isolation, integration tests to prove that these components work together correctly in broader business processes, and that they perform to requirements under production conditions, and that the data is only accessible by those who have permission to see it.
A good database test suite will help the team uncover and fix problems as early as possible in the development cycle, and therefore deploy changes faster, in the knowledge that the changes will work as expected and not have any negative side effects on other application components or system resources.
Ultimately, I’ve found that good database testing helps a team enjoy developing more and worry less. When issues do happen and are missed by the test suite, then you should see it as an opportunity to test your disaster recovery plans and to improve your test suite still further.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments