
Let the journey begin
There is a skill that I particularly admire in a developer: It is being able to recognize correctly that something, whether code or process, is no longer working well. It is useful because a project will so often start with right architecture and design but, over time, travels in unexpected direction. Without this skill, the project is liable to cross the ‘fit-for-purpose’ border and enter into ‘big-ball-of-mud’ land. Why? The project has changed, but the architecture hasn’t. No architecture is suitable for all types of software development project, yet we, who are assumed to be specialists, tend to be too eager to use the same solution for different problems. As in so many of life’s problems, ‘one size does not fit all’.
Many solutions start as mainly routine CRUD requirements (Create, Read, Update and Delete) but usually with some specific part that has considerable complexity. Software architecture should address those two areas separately. DDD (Domain-driven design) might seem a perfect tactic to address complex requirements, but it relies on access to domain experts and a shared intent to focus primarily on the domain and refine it iteratively.
Even when these prerequisites aren’t available, DDD might still be an inspiration for structuring code in these more complex areas of a development project because, in large part, it is plain good OOP. Such an approach, without defined context, ubiquitous language or even communication benefits, is called DDD-lite. It concentrates on technical-side patterns and concepts. Of course, it doesn’t mean that we forget about domain or communication – those elements are still present, but they are not at such a high level; nor are they explicit enough to warrant calling the approach ‘DDD’.
Aggregated root and action classes
Let’s look at how complexity may creep in your model, and how DDD concepts may help. Imagine we are implementing a classic ASP.NET MVC application with following layers:
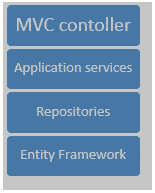
MVC controllers execute business logic that is kept in the domain and this logic is exposed through a façade of application services, which use repositories to access the database. Entity Framework’s DbContext is internally used to implement repositories.
For the sake of example, let’s assume that we start with the following model:
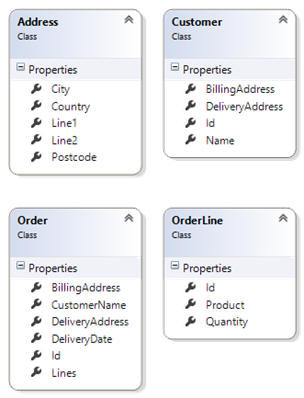
We have a customer with a name and addresses. A customer can create orders – each one has delivery date, addresses and set of ordered products.
Initially our code may look similar to this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
public class OrderRepository { public IList<Order> Find(Customer customer)... public Order Get(int id)... public void Save(Order order)... } public class OrderLineRepository { public IList<OrderLine> Find(Order orderline)... public OrderLine Get(int id)... public void Save(OrderLine orderline)... } public class OrderService { public IList<Order> Find(Customer customer)... public Order Get(int id)... public void Save(Order order)... } |
Two repositories, Order and OrderLine, give access to the respective tables through a set of base operations. Order service combines those and exposes logic to higher layers. A Find method on service, for example, could be as simple as calling Find on OrderRepository and returning only order headers. The Save method, on the other hand, invokes Save on OrderRepository and iterates over order lines to persist each of them with the OrderLineRepository class: All reasonably good so far.
Now, let’s imagine that the customer changes his mind or we suddenly find out that the save operation is more complex. Depending on the order status, we have to perform a basic or more sophisticated validation. I often witnessed service evolving into something like that:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
public class OrderRepository { public IList<Order> Find(Customer customer)... public Order Get(int id)... public void Save(Order order)... } public class OrderLineRepository { public IList<OrderLine> Find(Order orderline)... public OrderLine Get(int id)... public void Save(OrderLine orderline)... } public class OrderService { public IList<Order> Find(Customer customer)... public Order Get(int id)... public ValidationResult Save(Order order)... public ValidationResult Submit(Order order)... private void SaveOrder(Order order)... private ValidationResult ValidateOnSave(Order order)... private ValidationResult ValidateOnSubmit(Order order)... } |
There is a new public method to submit an order. Save and Submit internally call the appropriate private method to do the validation (ValidateOnSave or ValidateOnSubmit). As the actual logic of order saving is common it is extracted into separate private method (SaveOrder).
If developer writing this piece of code would know DDD better, a solution might look like this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
public class OrderRepository { public IList<Order> Find(Customer customer)... public Order Get(int id)... public void Save(Order order)... } public class OrderLineRepository... public class OrderValidator { public ValidationResult ValidateSave(Order order)... public ValidationResult ValidateSubmit(Order order)... private void ValidateCustomerLimits()... private void ValidateOtherLimits()... } public class OrderService { public IList<Order> Find(Customer customer)... public Order Get(int id)... public ValidationResult Save(Order order)... public ValidationResult Submit(Order order)... } |
One of key technical concepts of DDD is aggregated root. This is the parent entity, which controls access to its children, defines their lifetime and takes care about concurrent access to the same objects. This way, aggregate root can ensure the integrity of aggregates as a whole. All repositories should operate at aggregated root level. No other entities should be exposed directly through the methods of repository. That is the reason why OrderLineRepository has been removed. With the full logic of saving Order and OrderLine in the repository, there is no need to have a separate SaveOrder method on OrderService – this kind of logic is better kept at repository, where it is easily mockable and testable.
One addition – there is a new class, OrderValidator, named after an action and replacing logic that was kept previously in the private methods of OrderService. Contrary to what we have learned during Computer Science studies, it is better to not only call your classes after nouns, but also verbs. In our case, all the logic that is related to order validation is now kept in a separate class with single responsibility. Sub-validations, constituting on full validation, can be kept is private methods of OrderValidator (e.g. ValidateCustomerLimits). If we would need access to other areas of domain model inside OrderValidator, we can easily inject dependencies into that class without increasing overall class coupling too much and still have testability at the same level.
Domain events
Next, the customer might express a requirement to send an email notification to its recipients, and for legal reasons might need to generate an invoice at the time of order submission. A sufficient implementation, which often comes to mind could looks like this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
public class OrderRepository... public class EmailTemplateRepository { public EmailTemplate Get(EmailTemplateType type)... } public class InvoiceRepository { public void Save(Invoice invoice)... } public class OrderValidator... public class OrderService { public IList<Order> Find(Customer customer)... public Order Get(int id)... public ValidationResult Save(Order order)... public ValidationResult Submit(Order order)... private void SendEmailNotification(Order order)... private void CreateInvoice(Order order)... } |
We have new repositories:
- First to access email templates (EmailTemplateRepository)
- Second to create invoices (InvoiceRepository)
Two new private methods on OrderService are called inside Submit to meet the customer’s requirements. Again the problem is with embedding the logic mostly in the OrderService class and, again, the DDD concept comes to the rescue.
Event-based programming is popular, but we habitually think about it only in terms of the user interface. Domain events are events that signal a change in the domain that we care about. They are especially important when multiple aggregate roots need to interact. What if we try to use it here to reduce the coupling? Let’s see.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
public class OrderRepository... public class EmailTemplateRepository... public class InvoiceRepository... public class OrderValidator... public interface IDomainEvent {} public class OrderPlaced : IDomainEvent { public Order Order { get; set; } } public static class DomainEvents { public static void Raise<T>(T args) where T : IDomainEvent... } public interface Handles<T> where T : IDomainEvent { void Handle(T args); } public class OrderPlacedNotificationSender : Handles<OrderPlaced> { public void Handle(OrderPlaced args)... } public class OrderPlacedInvoiceGenerator : Handles<OrderPlaced> { public void Handle(OrderPlaced args)... } public class OrderService { public IList<Order> Find(Customer customer)... public Order Get(int id)... public ValidationResult Save(Order order)... public ValidationResult Submit(Order order)... } |
Domain events can be implemented in many ways, but I am here following Udi Dahan’s recommendations. An empty IDomainEvent interface is used to mark the domain events – OrderPlaced in our example. The Event class has all the information related to the event (Order property). All events are pumped through central hub (DomainEvents static class), which finds subscribers by looking for classes implementing Handles<T> interfaces. We’ve got two of those for our OrderPlaced event: one is responsible for email notifications and the other one for invoices. The names of handlers have been chosen to best describe their intention. Unnecessary private methods on OrderService have been deleted.
It is worth mentioning that true domain events should be named in the past tense. The table below shows a few different conventions for naming events, of which domains are most legible.
|
Event name |
Comments |
|
CustomerAddressChanged |
Domain event |
|
OrderPlaced |
Domain event |
|
CustomerUpdated |
CRUD-ish event |
|
CustomerInserting |
Trigger-like event |
Table1- Examples of events
In my example, events are processed synchronously, but there are other viable alternative approaches. They could be assembled during actions and processed either right before transaction-commit or send to the queue to be handled asynchronously by background workers.
From the technical perspective, implementation may vary. My sample is based on the global event hub by Udi Dahan, but instead we could:
- Use plain Old .NET events
- Use recent Reactive Extensions framework
- Simply return events from domain methods (which is easiest to test).
Factories
Finally, our customer may request an operation to clone an order. Naturally we may want to place such a simple operation inside OrderService.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
public class OrderRepository... public class EmailTemplateRepository... public class InvoiceRepository... public class OrderValidator... public interface IDomainEvent... public class OrderPlaced... public static class DomainEvents... public interface Handles<T>... public class OrderPlacedNotificationSender... public class OrderPlacedInvoiceGenerator... public class OrderService { public IList<Order> Find(Customer customer)... public Order Get(int id)... public ValidationResult Save(Order order)... public ValidationResult Submit(Order order)... public Order CloneOrder(Order originalOrder)... } |
But, what if it’s not that easy? What if some fields are omitted during cloning? What if we require access to additional repositories to fulfil the process? Do we have to impose those needs on OrderService and make it more difficult to test?
IoC (Inversion of Control) containers are very popular and this may have blinded us to the idea of writing custom factories. If our order cloning could be implemented as a factory, then that would relieve us from all the problems above. In this scenario, OrderService would be what it meant to be i.e. a façade over our business logic with nothing complex inside.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
public class OrderRepository... public class EmailTemplateRepository... public class InvoiceRepository... public class OrderValidator... public interface IDomainEvent... public class OrderPlaced... public static class DomainEvents... public interface Handles<T>... public class OrderPlacedNotificationSender... public class OrderPlacedInvoiceGenerator... public class OrderCloneFactory { public Order CloneOrder(Order originalOrder)... } public class OrderService { public IList<Order> Find(Customer customer)... public Order Get(int id)... public ValidationResult Save(Order order)... public ValidationResult Submit(Order order)... public Order CloneOrder(Order originalOrder)... } |
Takeaways
I have shown you how DDD concepts of aggregated root, action classes, domain events and custom factories can help you in everyday work to avoid transaction scripts for complex logic. Definitely not all elements of your system will be so complicated as to require those patterns, but you should generally follow a ‘thin application service, fat domain’ paradigm.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments