
‘I know that’s a secret, for it’s whispered every where’
“Love for Love” by William Congreve 1670-1729
It is a never-ending struggle to create a custom solution for properly authenticating users. The alternative of applying yesterday’s secure best practices today borders on negligence. As fast as the industry invents reasonable authentication techniques, older established techniques become compromised. A few years ago developers saved plaintext passwords in a database, today they only use a hash-based representation. Yesterday developers created hashes with MD5, today PBKDF2 sits atop the hierarchy of hashing algorithms.
This article demonstrates how developers can apply Open Web Application Security Project (OWASP) recommendations for handling user’s password hashes with the .NET Cryptography library. It also reviews some related concepts that developers who are new to cryptography may find helpful.
Making a Hash of Things
In the beginning, the process of authenticating users merely involved asking them for their name and password and comparing it to information saved in a datastore, such as, Microsoft SQL Server. It turns out that hackers and thieves loved this arrangement, too. The task of illegally accessing and reading a database table did not prove that tough for the highly-motivated hacker when accessing a table with lax access-control. Thus began the race to symmetrically encrypt passwords. Although this was a step in the right direction, any mistake in the implementation exposed user credentials or, almost as bad, made it impossible to authenticate users. A better solution was required in order to authenticate users effectively and efficiently.
The big breakthrough for many applications and enterprises that needed custom authentication came when it became no longer necessary to store user passwords. Authentication became a more modest exercise when it became possible to create and save a one-way representation of passwords for comparison checks.
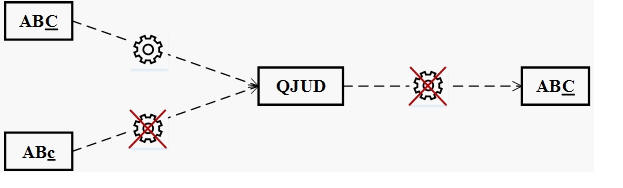
There are three important requirements for a secure one-way representation of passwords.
- The same text always creates the same representation. For example, the calculated representation of “ABC” is always “QUJD”.
- Two different texts cannot generate the same representation. For example, the calculated representation of “ABc” cannot equal “QUJD”.
- Even if you know the representation of a password, it doesn’t expose the password itself. For example, someone knowing the representation “QUJD” should not be able to determine the password “ABC”.
Cryptographic hash functions meet these requirements with a high degree of success.
.NET exposes a family of some of the more well-known of these hashing algorithms. We explore two of them in the next section.
Happy Path
Before we talk code, we ought to summarize the underlying “happy path” of authentication with hashes. The exercise starts when our new user provides a name and password. With this information we then calculate the password’s hash representation and store it in a database.
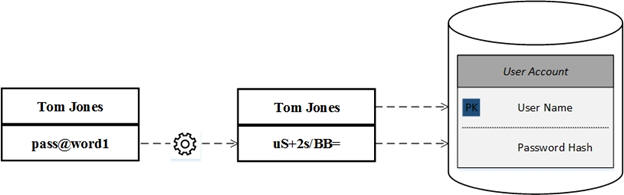
When the user returns, the authentication process calculates a hash of the provided password and compares it to the hash representation of it stored in the database for the given user name. If the hashes match, the user has successfully authenticated.
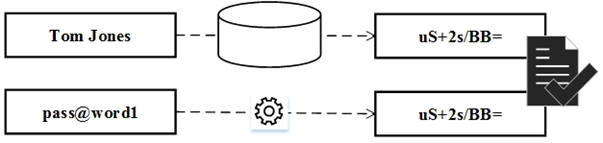
It bears repeating that (1) the database never stored the password, only its representation, and (2) only when a user provided the same text that they provided the first time around would the hashed values match.
So far, so good? Maybe.
What if several users employed the same password? If one of them is a bit mischievous they might try authenticating any and all users with their password. Given time and a little luck our misbehaving user might find those other users with matching passwords and log into their accounts.
There’s another problem. What if someone accessed a saved user’s hash value? By simply comparing that hash against a list of well-known password-hash combinations they could quickly find the password which generated the user’s hash. Turns out this scenario is neither fantastic nor original. It’s so common there’s even a pleasant sounding name for the attack, the rainbow table.
Hashing provides an easy fix for these vulnerabilities.
Adding a Little Salt
Appending some random information to the password before hashing minimizes the risks associated with matching passwords. Doing so only requires appending some random information to a password before hashing. This extra data is commonly referred to as a salt.
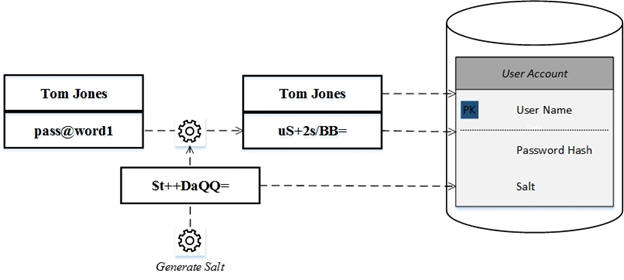
Authentication involves retrieving a user’s saved hash and salt values. Then including their salt when calculating the hash for the password they just provided and comparing it to the saved hash as shown below.
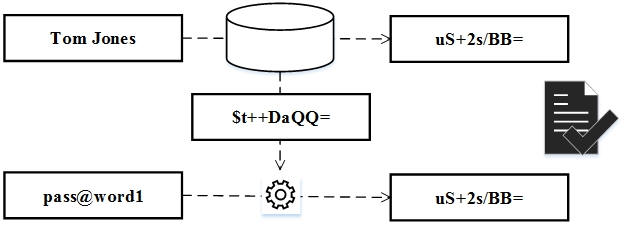
Finally, avoid common or application-wide salt values. The idea may be applicable for other security use-cases but definitely not for password hashing. While an application-wide salt may be easier to manage, a successful rainbow table attack only needs that one morsel of information to succeed. Given that most data breaches happen as ‘insider jobs’, singular salts won’t be too hard to ferret out.
Tale of Two Implementations
System.Security.Cryptography contains many tools. When it comes to hashing passwords, two base classes come to the fore. The first, HashAlgorithm, supports a few well-known hashing algorithms. The other, DeriveBytes, parents the latest algorithms provided by .NET. The discussion that follows focuses on an implementation from each of these base classes. It begins with the least secure, MD5, and ends with most, Rfc2898DeriveBytes.
Implementation #1: MD5
Possibly the oldest, most popular and least secure of the HashAlogrithms is MD5. Our first snippet contains two functions which together calculate a password hash. The code relies on the MD5 class and some encoding helper methods.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
static string CreateMD5(string password) { return Convert.ToBase64String( CalculateHash( Encoding.UTF8.GetBytes(password))); } static byte[] CalculateHash(byte[] toHash) { using (var md5 = MD5.Create()) { return md5.ComputeHash(toHash); } } |
After calling CreateMD5 with a password, a developer might complete the first leg of the happy path by saving both user name and password hash for subsequent comparison. When the users return, the following methods complete the journey. The task involves getting the bytes for both the saved hash and the provided password, calculating their hashes as an array of bytes and wrapping up with a byte-by-byte check of the two hashes.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
static bool MD5HashMatches( string savedHash, string providedPassword) { var savedHashBytes = Convert.FromBase64String(savedHash); var computedHashBytes = Convert.FromBase64String(CreateMD5(providedPassword)); return ArrayMatch(savedHashBytes, computedHashBytes); } static bool ArrayMatch(byte[] first, byte[] second) { if (first.Length != second.Length) return false; for (var i = 0; i < first.Length; i++) if (!first[i].Equals(second[i])) return false; return true; } |
We can simulate a complete happy path with our MD5 implementation by skipping the data storage portion of the journey. Our code calculates the first time hash as storedHash. Next, it compares that hash with one computed from the recently-provided password.
|
1 2 3 4 5 6 7 |
var password = "pass@word1"; Console.WriteLine("\tPassword: {0}", password); var storedHash = CreateMD5(password); Console.WriteLine("\tStored hash as Base64: {0}", storedHash); Console.WriteLine("\tStored hash and password match: {0}", MD5HashMatches(storedHash, password)); |
The above code produces the below expected output.
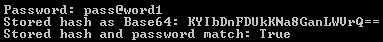
Our implementation suggests that the only challenge faced by the developers when building their own MD5-based authentication solution is the proper encoding of inputs. It can get confusing. For example, storedHash holds the password’s byte array hash converted to a base64 string for dehydrating and rehydrating. It is not a base64 encoding of the password text.
Despite successfully navigating the encoding straits, security rocks abound. We will explore a few of them before coding a safer solution.
Timing Attacks
Several years ago folks from Stanford University uncovered an interesting SSL vulnerability. The weakness stemmed from analyzing encryption processing time, hence the flaw’s name, timing attack. Our MD5HashMatches exposes the same flaw within the ArrayMatch method. If attackers pushed many authentication requests of varying passwords for the same user to our application they could record the time that each of these different checks consumed. With this timing information in hand they could, potentially, compute the correct password.
Fixing ArrayMatch to plug such a breach requires a little counter-intuitive programming. It involves ensuring that the byte by byte check consumes the same amount of time for a user. SaferArrayMatch does just that by working through every byte despite any failed equality check.
|
1 2 3 4 5 6 7 8 9 10 11 |
static bool SaferArrayMatch(byte[] first, byte[] second) { if (first.Length != second.Length) return false; var match = true; for (var i = 0; i < first.Length; i++) match = match && (first[i].Equals(second[i])); return match; } |
Missing Salt
Forgetting to add salt as discussing earlier to our hashing recipe is a not so subtle failure. In fairness to any developer who is coding their first authentication solution, it’s an understandable error. The .NET ComputeHash algorithms do not demand spicing.
To add salt, you must random bytes to the password’s bytes before calculating a hash. Our solution achieves that goal with two methods. The first, CreateSalt, takes a seed which helps randomize the salt value via the .NET Random class.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
static byte[] CreateSalt(int seed) { if (seed > 0) { var saltBytes = new byte[32)]; (new Random(seed)).NextBytes(saltBytes); return saltBytes; } else { return new byte[0]; } } |
Constructing saltBytes‘ with 32 bytes is a somewhat arbitrary decision. Nonetheless, this approach guarantees that most passwords will sport a hard-to-crack hash.
AddSalt serves as a helper for appending salt to a password. It leverages LINQ to concatenate the byte arrays.
|
1 2 3 4 5 6 7 |
static byte[] AddSalt( IEnumerable<byte> password, IEnumerable<byte> salt) { return password.Concat(salt).ToArray(); } |
ExploreMD5 adds the salt to our MD5 solution. It also helps visualize different scenarios by outputting text to the console.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
static void ExploreMD5( string testDescription, bool addSalt, int saltSeed, string password) { Console.WriteLine("\n\t{0}", testDescription); var passwordBytes = Encoding.UTF8.GetBytes(password); var saltBytes = addSalt ? CreateSalt(saltSeed) : new byte[0]; var saltBase64 = Convert.ToBase64String(saltBytes); Console.WriteLine("\tSalt:\t{0}", saltBase64); var hashBase64 = Convert.ToBase64String( CalculateHash(AddSalt(passwordBytes, saltBytes))); Console.WriteLine("\tHash:\t{0}", hashBase64); Console.WriteLine("\tHashes Match: {0}", HashMatches( Convert.ToBase64String(passwordBytes), saltBase64, hashBase64)); } |
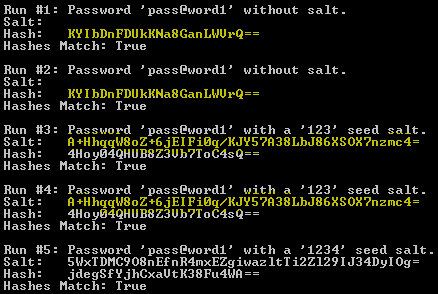
The first scenario demonstrates why adding salt is so important. They show how two different users with same password end up with the same hashes. Runs #3 and #4 exhibit the unsatisfactory impact of adding salt with the same random number generator seed value.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
ExploreMD5( "Run #1: Password 'pass@word1' without salt.", false, 0, password); ExploreMD5( "Run #2: Password 'pass@word1' without salt.", false, 0, password); ExploreMD5( "Run #3: Password 'pass@word1' with a '123' seed salt.", true, 123, password); ExploreMD5( "Run #4: Password 'pass@word1' with a '123' seed salt.", true, 123, password); ExploreMD5( "Run #5: Password 'pass@word1' with a '1234' seed salt.", true, 1234, password); |
Run #5 demonstrates why we add salt based on a different seed when computing a hash. It computes a different hash for the same password.
Faux Random
Calculating random values for some salt demands something rather more sophisticated than the run-of-the-mill, .NET Random.NextBytes function. While it is not the worst choice for generating random bytes, its values are predictable when given the same seed. Predictable seed values lead to predictable salts and that allows for hacking hashes.
Even instantiating the Random class with some seemingly obscure seed may not save the day. For example, seeding with the current time millisecond value is a common technique as shown within our ExploreMD5 method. The following code demonstrates how similar hashes might be generated with .NET time.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
ExploreMD5( "Run #1: Password 'pass@word1' & time-based seed.", true, DateTime.Now.Millisecond, password); ExploreMD5( "Run #2: Password 'pass@word1' & time-based seed.", true, DateTime.Now.Millisecond, password); Console.WriteLine("\n\tSleep for a second..."); System.Threading.Thread.Sleep(1000); ExploreMD5( "Run #3: Password 'pass@word1' & time-based seed.", true, DateTime.Now.Millisecond, password); ExploreMD5( "Run #4: Password 'pass@word1' & time-based seed.", true, DateTime.Now.Millisecond, password); |
Executing the above code several times will likely generate some fascinating results. One of these results outputted the below. In Run #1 and #2 things worked as expected. The same password generated different hashes. But after giving the .NET clock a pause the same password created the same hashes in Runs #3 and #4.
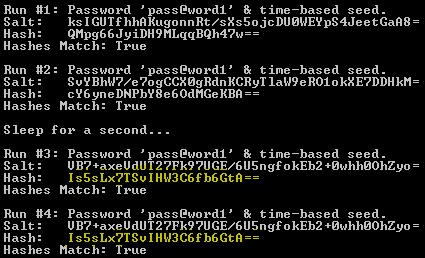
Time-based randomization introduces another problem. What happens if an intruder determines the exact time that a new user was created by reading the application or web logs? They could then calculate the user’s salt and begin checking different password-hash combinations as before.
If time-based hacking seems far-fetched or sound crazy? Read How One Man Hacked His Way Into the Slot-Machine Industry for a high tech version of this attack.
System.Security.Cryptography provides an excellent remedy to our salt headaches with the RandomNumberGenerator class. Replacing Random.NextBytes with it in CreateRandomBytes obviates the need for dodgy randomization techniques.
|
1 2 3 4 5 6 7 8 9 |
public static byte[] CreateRandomBytes(int length) { using (var csp = new RNGCryptoServiceProvider()) { var saltBytes = new byte[length]; csp.GetBytes(saltBytes); return saltBytes; } } |
By updating ExploreMD5 and CreateSalt with CreateRandomBytes you end up with a simpler and more effective solution. Youll notice that there is no explicit seed value for randomization for constructing a salt. RNGCryptoServiceProvider only wants to know how many bytes the developer desires, that is, a length.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
static byte[] SaferCreateSalt(int length) { if (length > 0) return CreateRandomBytes(length); else return new byte[0]; } static void ExploreMD5( string testDescription, bool addSalt, int saltSeed, string password) { Console.WriteLine("\n\t{0}", testDescription); var passwordBytes = Encoding.UTF8.GetBytes(password); // var saltBytes = addSalt ? // CreateSalt(saltSeed) : new byte[0]; var saltBytes = addSalt ? SaferCreateSalt(32) : new byte[0]; var saltBase64 = Convert.ToBase64String(saltBytes); Console.WriteLine("\tSalt:\t{0}", saltBase64); // and the rest... |
As before the choice of salt length remains arbitrary. Some experts posit that 32 bits, as employed above, will foil a rainbow dictionary assault. Others note it depends on the underlying algorithm. Some others simply say bigger is better. I suspect they’re all correct.
Busted
The last obvious problem is not so easy to remedy. Experts cracked MD5 back in 1996 with new cracks appearing every few years. And switching to a later generation of a fundamentally similar hashing algorithm, such as, secure hash algorithm (SHA), may not help. SHA-1 was cracked in 2012 and experts believe SHA-2 will prove lacking shortly. The demise of these algorithms has led some security experts to prefer a completely different algorithm, such as, PBKDF2. Rfc2898DeriveBytes is the .NET version of it and found in our second implementation.
Implementation #2: Rfc2898DeriveBytes
Underneath the covers, Rfc2898DeriveBytes works differently from hashing algorithms like MD5 and SHA. Internally it uses another hashing algorithm and among other things reapplies it many times in strange ways to make guessing the original password nearly impossible with today’s hardware.
Our updated implementation of the CalculatedHash and HashMatches methods leverages Rfc2898DeriveBytes. Aside from the new hash class the additional parameter iterations stands out as the notable change from our MD5 implementation. As might be guessed it controls how many times Rfc2898DeriveBytes reapplies its internal hashing algorithm with more iterations producing a more secure hash.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
static byte[] CalculateHash( string password, string salt, int iterations) { var saltBytes = Convert.FromBase64String(salt); using (var deriveBytes = new Rfc2898DeriveBytes(password, saltBytes)) { deriveBytes.IterationCount = iterations; return deriveBytes.GetBytes(20); } } static bool HashMatches( string password, string salt, int iterations, string hash) { var computedHash = CalculateHash( password, salt, iterations); var providedHash = Convert.FromBase64String(hash); return SaferArrayMatch(providedHash, computedHash); } |
As the above updates suggest working with Rfc2898DeriveBytes can be easy. Complications quickly appear when electing to customize it. For example, in the above code why GetBytes(20) and not GetBytes(21)? Answering such a question is not easy and don’t expect much help from the API. To gain an understanding of GetBytes consider digging into RFC 2898 and reading about dkLen.
Explicitly controlling hash complexity of Rfc2898DeriveBytes via the iterations parameter raises the obvious question, what’s the best value? Like most crypto questions, the answer is not so simple. While more iterations makes for a more secure hash it also consumes more time. Calling the ExploreRfc2898DeriveBytes method below with a few different iteration values suggests how much longer.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
static void ExploreRfc2898DeriveBytes( string testDescription, string password, int iterations) { Console.WriteLine("\n\t{0}", testDescription); var stopWatch = new Stopwatch(); stopWatch.Start(); var hashBase64 = Convert.ToBase64String( CalculateHash( password, Convert.ToBase64String(SaferCreateSalt(32)), iterations)); Console.WriteLine("\tHash:\t{0}", hashBase64); stopWatch.Stop(); Console.WriteLine("\tElapsed milliseconds: {0}", stopWatch.ElapsedMilliseconds); } |
The displayed output from these runs reinforces the old adage that everything costs. While 10,000 iterations required a negligible amount of time, a million consumed nearly 5 seconds.
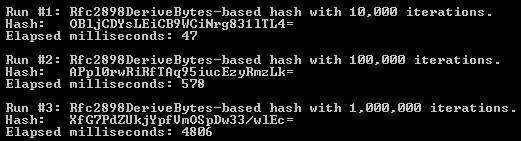
The good housekeeping seal of approval for secure password hashes fortuitously recommends 100,000 iterations for ExploreRfc2898DeriveBytes. But even this recommendation requires a noticeable half a second!? More importantly, will it be good enough tomorrow as faster hardware options appear? Such an inevitability suggests it best to consider building into any custom authentication solution a capacity for change.
Future Proofing
The decision whether to add the capacity for seamless change into a custom authentication solution is a thorny one. It almost resembles that of buying insurance. Why should people buy something they believe unnecessary and expensive? Fortunately, unlike buying insurance, deciding to build an adaptable authentication solution is simpler. First, it will be needed. History informs us that secure authentication mechanics change. Second, costs are manageable. Implementation can be as simple or complex as the following discussion suggests.
One of the simplest ways to future-proof a custom authentication solution is to allow for changes to algorithm parameters. If we return to our earlier ExploreRfc2898DeriveBytes-based implementation we could store the number of iterations required for new password hashes in a datastore and save both iteration and salt values for each user. We now have the ability to create more complex hashes for new users while authenticating existing users with obsolescent iteration values.
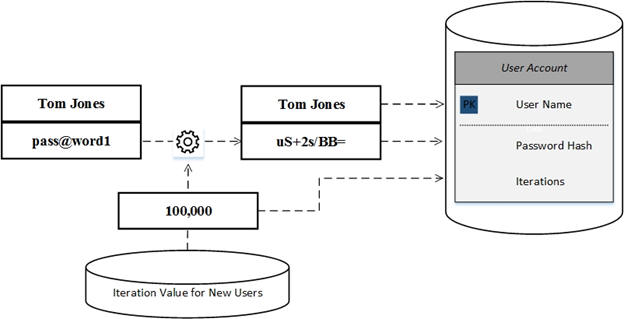
The next logical step in future-proofing a custom solution might entail dynamically changing the underlying algorithm itself. Such a feature suggests writing code that is able to apply any set of parameters to any algorithm without prejudice, not a simple exercise.
Inherent in any future-proofing capability is to ask users to update their password in order to apply the updates. (Did you forget we never store passwords and hashes can’t be reversed?) The good news on this front is that most users have been trained to change their passwords periodically by most security conscience applications. Nonetheless, such a feature still needs implementation and some users may not like being either prompted or required to change their password.
Conclusion
We explored a few techniques for building a custom authentication solution with .NET that incorporates the latest OWASP recommendations. Along the way we encountered several deeper cryptographic questions developers will likely ask. We wrapped up with some ideas for keeping a custom solution responsive to changing threats and hacks. As I said in the beginning, there is no chance of having a permanent solution to providing safe authentication. It is an ongoing battle against the dark side of the internet, and it is one that takes constant vigilance, cooperation, and learning from the mistakes of others.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments