
This article is taken from Chapter 1 of the book ‘Under the Hood of .NET Memory Management’ by Chris Farrell and Nick Harrison. This can be downloaded as a free PDF eBook from here
Overview
If you think about it, an application is made up of two things; the code itself, and the data that stores the state of the application during execution. When a .NET application runs, four sections of memory (heaps) are created to be used for storage:
- The Code Heap stores the actual native code instructions after they have been Just in Time Compiled (JITed).
- The Small Object Heap (SOH) stores allocated objects that are less than 85K in size
- The Large Object Heap (LOH)stores allocated objects greater than 85K (although there are some exceptions, which we won’t discuss in this overview article but is in chapter 2 of the book)
- Finally, there’s the Process Heap, but let’s not go there just yet
Everything on a heap has an address, and these addresses are used to track program execution and application state changes.
Applications are usually written to encapsulate code into methods and classes, so .NET has to keep track of chains of method calls as well as the data state held within each of those method calls. When a method is called, it has its own cocooned environment where any data variables it creates exist only for the lifetime of the call. A method can also get data from globals/static objects, and from the parameters passed to it.
In addition, when one method calls another, the local state of the calling method (variables, parameters) has to be remembered while the method to be called executes. Once the called method finishes, the original state of the caller needs to be restored so that it can continue executing.
To keeping track of everything (and there is often quite a lot of “everything”), .NET maintains a stack data structure, which it uses to track the state of an execution thread and all the method calls made.
Stack
So the stack is used to keep track of a method’s data from every other method call. When a method is called, .NET creates a container (a stack frame) that contains all of the data necessary to complete the call, including parameters, locally declared variables and the address of the line of code to execute after the method finishes. For every method call made in a call tree (i.e. one method that calls another, which calls another… etc.), stack containers are stacked on top of each other. When a method completes, its’ container is removed from the top of the stack and the execution returns to the next line of code within the calling method (with its own stack frame). The frame at the top of the stack is always the one used by the current executing method.
Using this simple mechanism, the state of every method is preserved in between calls to other methods, and they are all kept separate from each other.
In Listing 1 Method1 calls Method2 , passing an int as a parameter.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
1 void Methodl () 2 { 3 Method2(12); 4 Console.WriteLine("Goodbye"); 5 } 6 void Method2(int testData) 7 { 8 int multiplier=2; 9 Console.WriteLine("Value is " + testData.ToString()); 10 Method3|(testData * multplier) ; 11 } 12 void Method3(int data) 13 { 14 Console.WriteLine("Double " + testData.ToString()); 15 } |
Listing 1: Simple Method call chain
To call Method2 the application thread needs first to record an execution return address which will be the next line of code after the call to Method2 . When Method2 has completed execution, this address is used to call the next line of code in Method1 , which is line 4. The return address is therefore put on the Stack.
Parameters to be passed to Method2 are also placed on the stack. Finally we are ready to jump our execution to the code address for Method2 .
If we put a break point on line 13 the stack would look something like this:
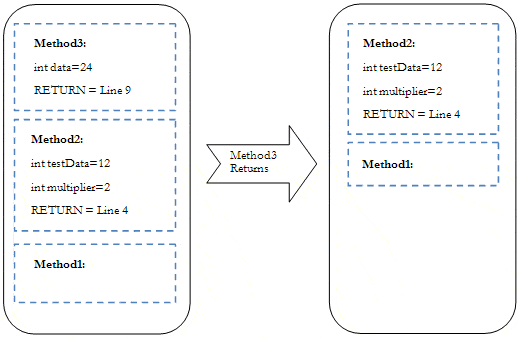
Figure 1: Example of a Stack Frame
Obviously this is a huge simplification, and addresses wouldn’t use code line numbers for return addresses, but hopefully you get the idea.
In Figure 1, stack frames for Methods 1,2 and 3 have been stacked on top of each other, and at the moment the current stack frame is Method3 , which is the current executing method. When Method3 completes execution, it’s stack frame is removed, the execution point moves to Method2 (line 9 in Listing 1), and execution continues.
A nice simple solution to a complex problem, but don’t forget if your application has multiple threads, then each thread will have its’ own stack.
Heap
So where does the Data Heap come into it? Well, the stack can store variables that are the primitive data types defined by .NET. These include the following types:-
- Byte
- SByte
- Int16
- Int32
- Int64
- UInt16
- UInt32
- UInt64
- Single
- Double
- Boolean
- Char
- Decimal
- IntPtr
- UIntPtr
- Structs
These are primitive data types and part of Common Type System (CTS) natively understood by all NET language compilers, and are collectively called Value Types. Any of these data types or struct definitions are usually stored on the stack.
On the other hand, instances of everything you have defined, including:
- Classes
- Interfaces
- Delegates
- Strings
- Instances of “object”
… are all referred to as “reference types”, and are stored on the heap (the SOH or LOH, depending on their size).
When an instance of a reference type is created (usually involving the new keyword), only an object reference is stored on stack. The actual instance itself is created on the heap, and its’ address held on the stack.
Consider the following code:
|
1 2 3 4 5 |
1 void Method1() 2 { 3 MyClass myObj=new MyClass(); 4 Console.WriteLine(myObj.Text); 5 } |
Listing 2: Code example using a reference type
In Listing 2 . a new instance of the class MyClass is created within the Method1 call.
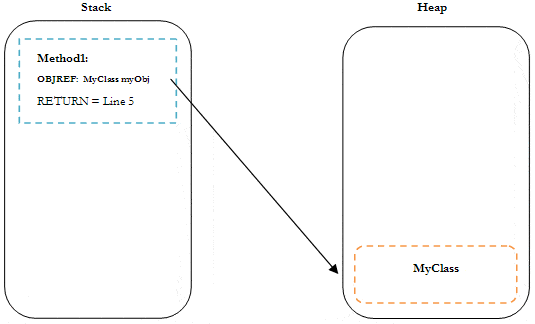
Figure 2: Object Reference from Stack to Heap
As we can see in Figure 2, To achieve this, .NET has to create the object on the memory heap, determine its address on the heap (or object reference), and place that object reference within the stack frame for Method1 . As long as Method1 is executing, the object allocated on the heap will have a reference held on the stack. When Method1 completes, the stack frame is removed (along with the object reference), leaving the object without a reference.
We will see later how this affects memory management and the garbage collector.
More on Value and Reference Types
The way in which variable assignment works differs between reference and value types.
Consider the following code:
|
1 2 3 4 5 6 7 |
1 void ValueTest() 2 { 3 int v1=12; 4 int v2=22; 5 v2=v1; 6 Console.Writeline(v2); 7 } |
Listing 3: Assignment of Value Types
If a breakpoint was placed at line 6, then the stack/heap would look like this :
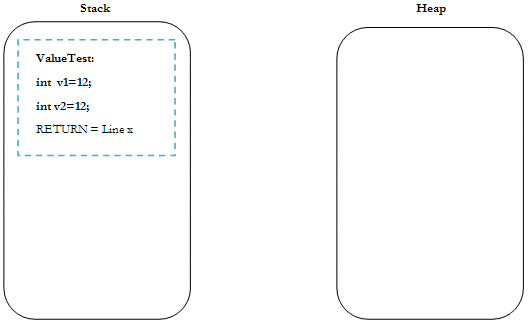
Figure 3: Stack example of value type assignment
There are two separate integers on the stack both with the same value.
Notice there are two stack variables, v1 and v2 , and all the assignment has done is assign the same value to both variables.
Let’s look at a similar scenario, this time using a class I have defined, MyClass , which is (obviously) a reference type:
|
1 2 3 4 5 6 7 |
1 void RefTest() 2 { 3 MyClass v1=new MyClass(12); 4 MyClass v2=new MyClass(22); 5 v2=v1; 6 Console.Writeline(v2.Value); 7 } |
Listing 4: Assignment with Reference Types
Placing a break point on line 5 in Listing 4 would see two MyClass instances allocated onto the heap:
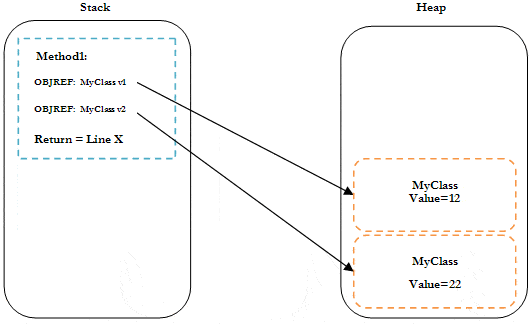
Figure 4: Variable Assignment with Reference Types
On the other hand, letting execution continue, and allowing v1 to be assigned to v2 the execution at line 6 in Listing 4, would show a very different heap:
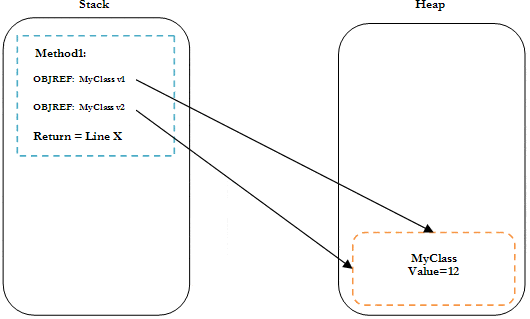
Figure 5: Variable Assignment with Reference Types 2
Notice how, in Figure 5, both object pointers are referencing only the one class instance after the assignment. Variable assignment with reference types makes the object pointers on the stack the same, and so they both point to the same object on the heap.
Passing Parameters
When you pass a value type as a parameter, all you actually pass to the calling method is a copy of the variable. Any changes that are made to the passed variable within the method call are isolated to the method.
Having copies of value types on the stack isn’t usually a problem, unless the value type is large, as can be the case with structs. While structs are value types, and as such are also allocated onto the stack, they are also, by their nature, programmer-definable structures, and so they can get pretty large. When this is the case, and particularly if they are passed as parameters between method calls, it can be a problem for your application. Having multiple copies of the same struct created on the stack creates extra work in copying the struct each time. This might not seem like a big deal, but when magnified within a high iteration loop, it can cause a performance issue.
One way around this problem is to pass specific value types by reference. This is something you would do anyway if you wanted to allow direct changes to the value of a passed variable inside a method call.
Consider the following code:
|
1 2 3 4 5 6 7 8 9 10 11 |
void Method1() { int v1=22; Method2(v1); Console.WriteLine("Method1 = " + v1.ToString()); } void Method2(int v2) { v2=12; Console.WriteLine("Method2 = " + v2.ToString()); } |
Listing 5: Passing parameters by value
Once Method1 completes we would see the following output:
|
1 2 |
Method 2 = 12 Method 1 = 22 |
Listing 6: Output from a parameter passed by value
Because parameter v1 was passed to Method2 by value, any changes to it within the call don’t affect the original variable passed. That’s why the first output line shows v2 as being 12. The second output line demonstrates that the original variable remains unchanged.
Alternatively, by adding a ref instruction to both the method and the calling line, variables can be passed by reference (Listing 7).
|
1 2 3 4 5 6 7 8 9 10 11 |
void Method1() { int v1=22; Method2(ref v1); Console.WriteLine("Method1 = " + v1.ToString()); } void Method2(ref int v2) { v2=12; Console.WriteLine("Method2 = " + v2.ToString()); } |
Listing 7: Passing parameters by reference
Once Method1 completes, we would see the following output (Listing 8):
|
1 2 |
Method 2 = 12 Method 1 = 12 |
Listing 8: Output from a parameter passed by reference
Notice both outputs display “12”, demonstrating that the original passed value was altered.
Boxing and Unboxing
Let’s now talk about that topic you always get asked about in interviews, boxing and unboxing. It’s actually really easy to grasp, and simply refers to the extra work required when your code causes a value type (e.g. int , char etc) to be allocated on the heap rather than the stack. As we saw earlier, allocating onto the heap requires more work, and so is less efficient.
The classic code example of boxing and unboxing looks something like this:
|
1 2 3 4 5 6 |
1 // Integer is created on the Stack 2 int stackVariable=12; 3 // Integer is created on the Heap = Boxing 4 object boxedObject= stackVariable; 5 // Unboxing 6 int unBoxed=(int)boxedObject; |
Listing 9: Classic Boxing and Unboxing example
In Listing 9 an integer is declared and allocated on the stack because it’s a value type (line 2). It’s then assigned to a new object variable (boxed) which is a reference type (line 4), and so a new object is allocated on the heap for the integer. Finally, the integer is unboxed from the heap and assigned to an integer stack variable (line 6).
The bit that confuses everyone is “why you would ever do this?“; it makes no sense.
The answer to that is that you can cause boxing of value types to occur very easily without ever being aware of it.
|
1 2 3 4 5 6 |
1 int i=12; 2 ArrayList lst=new ArrayList(); 3 // ArrayList Add method has the following signature 4 // int Add(object value) 5 lst.Add(i); // Boxing occurs automatically 6 int p=(int)lst[0]; // Unboxing occurs |
Listing 10: Boxing a value type
Listing 10 demonstrates how boxing and unboxing can sneakily occur, and I bet you’ve written similar code at some point. Adding an integer (value type) to the ArrayList will cause a boxing operation to occur because, to allow the array list to be used for all types (value and reference), the Add method takes an object as a parameter. So, in order to add the integer to the ArrayList , a new object has to be allocated onto the heap.
When the integer is accessed on line 6, a new stack variable “p” is created, and its’ value set to the same value as the first integer in the ArrayList .
In short, a lot more work is going on than is necessary, and if you were doing this in a loop with thousands of integers then performance would be significantly slower.
More on the Heap
Now that we’ve had our first look at the heap(s), let’s dig a little deeper.
When a reference type is created (class , delegate , interface , string or object ), it’s allocated onto the heap. Of the 4 heaps we’ve seen so far, .NET uses two of them to manage large objects (anything over 85K) and small objects differently. They are known as managed heaps.
To make it the worry-free framework that it is, .NET doesn’t let you allocate objects directly onto the heap like C/C++ does. Instead, it manages object allocations on your behalf, freeing you from having to deallocate everything you create. By contrast, if a C++ developer didn’t cleanup their allocated objects, then the application would just continually leak memory.
To create an object, all you need to do is use the new keyword; .NET will take care of creating, initializing and placing the object on the right heap, and reserving any extra memory necessary. After that you can pretty much forget about that object, because you don’t have to delete it when you’re finished with it.
Naturally, you can help out by setting objects to null when you’ve finished with them, but most of the time, when an object goes out of scope, it will be cleaned up automatically.
Garbage Collection
To achieve this automatic cleanup, .NET uses the famous (or perhaps infamous ) Garbage Collector (GC). All the GC does is look for allocated objects on the heap that aren’t being referenced by anything. The most obvious source of references, as we saw earlier, is the stack. Other potential sources include:
- Global/Static object references
- CPU registers
- Object Finalization references (more later)
- Interop references (.NET objects passed to COM/API calls)
- Stack references
Collectively, these are all called root references or GC Roots.
As well as root references, an object can also be referenced by other objects. Imagine the classic Customer class, which usually has a collection storing Order classes.
When an Order is added to the order collection the collection itself then holds a reference to the added order. If the instance of the customer class had a stack reference to it as well, it would have the following references:
- A Stack-based root reference for a
Customercontaining:- AA reference to the orders
ArrayListcollection, which contains:- References to
orderobjects.
- References to
- AA reference to the orders
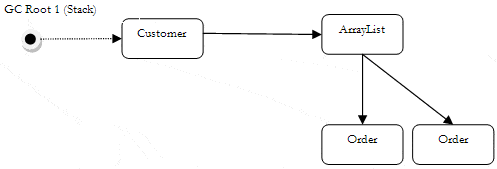
Figure 6: Reference tree for a typical scenario
Figure 6 shows the basic reference tree, with a global root reference to a Customer class that, in turn, holds a collection of Order classes.
This is important because if an object doesn’t ultimately have a root reference then it can’t actually be accessed by code, and so it is no longer in use, and can be removed. As you can see above, a large number of objects can be maintained by just a single root reference, which is both good and bad, as we’ll see later.
Inspection and Collection
To make sure objects which are no longer in use are cleared away, the Garbage Collector simply gets a list of all root references and, for each one, moves along it’s reference tree “marking” each object found as being in use (we’ll come back to what that means in just a moment). Any objects not marked as being in use, or “live”, are free to be “collected” (which we’ll also come back to later).
A simplified version would look something like this:
|
1 2 3 4 5 6 7 8 |
void Collect() { List gcRoots=GetAllGCRoots(); foreach (objectRef root in gcRoots) { Mark(root); } Cleanup(); } |
Listing 11: Simplified GC Collection in pseudo code
The Mark operation adds an object to an “object still in use” list (if it’s not already in there), and then iterates through all of its child object references, marking each one in turn. The result is a list of all objects currently in memory that are still in use.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
VVoid Mark(objectRef o) { if (!InUseList.Exists(o)) { InUseList.Add(o); List refs=GetAllChildReferences(o); foreach (objectRef childRef in refs) { Mark(childRef); } } } |
Listing 12: Simplified GC Mark operation in pseudo code
Once that list is compiled, the GC can then go about cleaning up the heaps, and we’ll now go through how the Cleanup operation works differently for both the SOH and LOH. In both cases, the result of a cleanup operation is a resetting of the “object still in use” list, ready for the next collection.
SOH Cleanup – Heap Compaction
Garbage collection of the Small Object Heap (SOH) involves compaction. This is because the small object heap is a contiguous heap where objects are allocated consecutively on top of each other. When compaction occurs, marked objects are copied over the space taken up by unmarked objects, overwriting those objects, removing any gaps, and keeping the heap contiguous; this process is known as Copy Collection. The advantage of this is that heap fragmentation (i.e. unusable memory gaps) is kept to a minimum. The main disadvantage is that compaction involves copying chunks of memory around, which requires CPU cycles and so, depending on frequency, can cause performance problems. What you gain in efficient allocation you could lose in compactions costs.
LOH Sweeping – Free Space Tracking
The Large Object Heap (LOH) isn’t compacted, and this is simply because of the time it would take to copy large objects over the top of unused ones. Instead, the LOH keeps track of free and used space, and attempts to allocate new objects into the most appropriately-sized free slots left behind by collected objects.
As a result of this, the LOH is prone to fragmentation, wherein memory gaps are left behind that can only be used if large objects (i.e. >85K) of a similar or smaller size to those gaps are subsequently allocated.
For more detail of these managed heaps, you’ll have to look in chapter 2 of the book
Static objects
I’ve already mentioned static/global objects as a source of root references, but let’s now look at that topic in a bit more detail, and with some more background.
Marking a class member as static makes it a class-specific, rather than instance-specific, object. With using non-static members, you would need to declare an instance of the necessary class before you could access its members. On the other hand Static members can be accessed directly by just using the class name.
|
1 2 3 4 5 |
class Person { public int Age=0; public static MaxAge=120; } |
Listing 13: Example of a static member variable
Listing 13 shows both an instance variable (Age ) and a static variable (MaxAge ) on a Person class. The static variable is being used as a piece of general data across the range of Person instances (people aren’t usual older than 120), whereas the instance variable is specific to an instance of the class i.e. an individual person.
To access each member, you would need to write the following code:
|
1 2 3 4 5 6 7 |
Person thisPerson=new Person(); thisPerson.Age=121; ff (thisPerson.Age>Person.MaxAge) { // Validation Failure } |
Listing 14: Accessing Statics
In Listing 14, an instance of a Person is created, and its only via the instance variable that the Age member is accessible, whereas MaxAge is available as a kind of global member on the Person type itself .
In C#, statics are often used to define global variables.
Static Methods and Fields
When you mark a method, property, variable or event as static, the runtime creates a global instance of each one soon after the code referencing them is loaded & used.
Static members don’t need to be created using the new keyword, but are accessed using the name of the class they were defined within. They are accessible by all threads in an app domain (unless they are marked with the [ ThreadStatic ] attribute, which I’ll come back to in a moment), and are never garbage collected because they essentially are root references in themselves.
Statics are a common and enduring source of root references, and can be responsible for keeping objects loaded in memory for far longer than would otherwise be expected.
Listing 15 shows the declaration of a static object and its initialization within a static constructor. Once loaded, the static constructor will execute, creating a static instance of the Customer class, and a reference will be held to an instance of the Customer class for the duration of the application domain (or the thread, if the reference is marked [ ThreadStatic ] ).
|
1 2 3 4 5 6 7 8 9 10 |
public class MyData { public static Customer Client; public static event EventType OnOrdersAdded; static MyData() { // Initialize Client=new Customer(); } } |
Listing 15: Static Reference example
It’s also worth remembering that any classes that subscribe to static events will remain in memory until the event subscription is removed, or the containing app domain finishes.
Static collections can also be a problem, as the collection itself will act as a root reference, holding all added objects in memory for the lifetime of the app domain.
Thread Statics
Sometimes you may want to prevent multiple threads accessing a common set of statics. To do this, you can add the [ ThreadStatic ] attribute to the member, and create multiple static instances of that member – one for each isolated thread (one instance per thread). See Listing 16.
|
1 2 |
[ThreadStatic] public static int NumberofThreadHits=0; |
Listing 16: Marking a member [ThreadStatic]
Summary
Ok, we’ve covered the basics of stacks, heaps, garbage collecting and referencing, and how they all hang together inside the .NET framework. Some of the material we’ve covered in this article has been deliberately simplified so that you get a good “in principal” understanding without being buried under the fine detail.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments