
Over the next few years, your users will begin replacing their current computers with newer machines containing increasing numbers of of multi-core processors, and they’ll expect your software to make that investment pay off. Although concurrent programming and the tools associated with it has traditionally been an arena reserved only for the true gurus of our field, the advent of Parallel Extensions in .NET 4.0 has brought these same tools to the masses. This article will serve as the first step on your path to learning how to use these new parallel tools, and also provide resources for more advanced topics when you’re ready to go a bit deeper.
While this article will introduce you to some of these extensions, and show how you can quickly incorporate them into your own applications to take advantage of all of those additional processors that your users are now loading up on, bear in mind that this is merely a taste of the parallel power now available to you. Our goal is to introduce you to the concepts of Parallel Extensions, not turn you into a Concurrent Programming Ninja from scratch. We’ll start by taking a look at PLINQ, which is an easy way to work with the new extensions, and then we’ll dig deeper and take a look at the library which drives it all.
PLINQ
Most .NET developers today are familiar with LINQ, the technology that brought functional programming ideas into the object-oriented environment. Parallel LINQ, or ‘PLINQ’, takes LINQ to the next level by adding intuitive parallel capabilities onto an already powerful framework.
|
1 2 3 4 5 6 7 8 |
var customers = new[] { new Customer { ID = 1, FirstName = "John", LastName = "Smith" }, new Customer { ID = 2, FirstName = "Suzy", LastName = "White" }, new Customer { ID = 3, FirstName = "Robert", LastName = "Johnes" } }; var results = from c in customers.AsParallel() where c.FirstName == "John" select c; |
With the simple addition of the AsParallel() extension method, the .NET runtime will automatically parallelize the operation across multiple cores. In fact, PLINQ will take full responsibility for partitioning your data into multiple chunks that can be processed in parallel. PLINQ partitioning is a bit out of the scope of this article, but if you’re curious about the inner workings of it, this blog post from Microsoft’s own Parallel Programming team does a great job of explaining the details.
All of this sounds easy, right? Well mostly it is, but there are a few limitations to be aware of. One such limitation is that PLINQ only works against local collections. This means that if you’re using LINQ providers over remote data, such as LINQ to SQL or ADO.NET Entity Framework, then you’re out of luck for this version. However, if you’re working against objects in memory, then PLINQ is ready to go, with a caveat; In addition to being in-memory, the collection on which you’re operating must support the extension methods exposed by the ParallelEnumerable class. As of .NET 4.0, most common collections in the framework already support these methods, so this will likely only be an issue if you’re working with arcane collections or collections of your own design.
Let’s try another example; in our previous query, we simply left it up to the runtime to decide how to best parallelize our query given the resources available, but sometimes we want a bit more control. In these cases, we can add the WithDegreeOfParallelism() extension method to specify across how many cores we’d like to scale our query…
|
1 2 3 |
var results = from c in customers.AsParallel().WithDegreeOfParallelism(3) where c.FirstName == "John" select c; |
By now, you’re probably starting to realize that PLINQ makes parallelizing most of your queries an almost trivial matter. In fact, you may be wondering why you wouldn’t just parallelize everything from now on. Well, before you jump headfirst into parallelization bliss, you need to know that concurrent programming isn’t appropriate for everything. In fact, there are certain situations where parallelization can even have some downsides. We’ve already mentioned the fact that PLINQ only works against in-memory collections, but let’s take a look at a few more pitfalls of PLINQ.
Things to Bear in Mind
Since PLINQ chunks the collection into multiple partitions and executes them in parallel, the results that you would get from a PLINQ query may not be in the same order as the results that you would get from a serially executed LINQ query.
To be fair, this is probably less a pitfall, and more something that you just need to be aware of. Since the two sets are still perfectly equivalent, this won’t be an issue in many cases, but if you’re expecting your results as a series ordered in a specific sequence, then this may lead to a bit of a surprise! However, you can work around this by introducing the AsOrdered() method into your query, which will force a specific ordering into your results. Keep in mind, however, that the AsOrdered() method does incur a performance hit for large collections, which can erase many of the performance gains of parallelizing your query in the first place:
|
1 2 |
var results = from i in ints.AsParallel().AsOrdered() where i > 100 select i; |
Since the runtime must first partition your dataset in order to execute it in parallel, parallelizing your query naturally does incur a slight amount of overhead. This overhead is also incurred by the additional management required to synchronize the results from the multiple tasks. For complex operations, this overhead is usually negligible compared to the benefits, but for simple operations this added overhead may quickly outweigh any gain you receive from parallelization. Therefore, it’s a good idea to only introduce parallelization after you’ve noticed a CPU bottleneck. This will prevent you from prematurely optimizing your code and, in the process, doing more harm than good.
MSDN also has a great list of some additional “things bear in mind” when parallelizing your code. Periodically skimming this list to keep these pitfalls fresh in your mind can save you hours of agonizing debugging down the road.
Cancellation Control
Everything we’ve discussed thus far assumes that you’ll always want your queries to finish, but what if you need to cancel an already-running query? Luckily, PLINQ has provisions for that as well.
To cancel a running query, PLINQ uses a cancellation token from the Task Parallel Library (which we’ll look at in a moment), in the form of the CancellationTokenSource object. The code below demonstrates this object in action…
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
var cancellationSource = new CancellationTokenSource(); var results = from i in ints.AsParallel().WithCancellation(cancellationSource.Token) where i > 100 select i; //Elsewhere... cancellationSource.Cancel(); try { results.ForAll(Console.WriteLine); } catch (OperationCanceledException ) { // Handle the exception... } |
The example above warrants a bit of explanation: The OperationCanceledException is thrown when a parallel operation is canceled by the holder of a cancellation token, but you may be wondering why we are wrapping only the results in a try/catch, rather than the actual PLINQ query – This is due to the fact that LINQ queries are evaluated lazily.
Simply speaking, a lazily evaluated query is one that is never executed until we attempt to enumerate the results object, even though we created it at the beginning of the code sample. This is why the OperationCanceledException is actually thrown from the results object, not the query itself. You can see this lazy evaluation in action when attempting to view the results of a LINQ query in the Visual Studio debugger…

Figure 1. Lazy evaluation in action.
Although these tokens allow us to cancel an already-running query from another thread, it’s important to note that PLINQ will not pre-emptively cancel a running thread. Rather, it will continue to poll the cancellation token at various points through the process, thus avoiding the unexpected cancellation issues previously found with Thread.Abort. In actuality, it will wait for the current task to complete before terminating the overall query. In other words, cancelling a PLINQ query simply tells the runtime not to begin any new iterations after a cancellation token has been issued.
The Task Parallel Library
Now that we’re starting to get an understanding of the parallel capabilities of PLINQ, let’s dig a bit deeper into the framework that supports and drives it. Also included in the Parallel Extensions is the Task Parallel Library, or TPL, which is an advanced concurrent library that’s appropriate for those scenarios when you need more fine-grained control. To be fair, PLINQ is really built on top of the TPL, and is an easier means of using it, but you can dig into the TPL directly if you need to do some serious tinkering.
Working with Tasks
The fundamental building block of the TPL is known as a Task, which is conceptually very similar to threads in earlier versions of the .NET Framework. In fact, Tasks are actually implemented under the hood using the standard CLR ThreadPool, which has been optimized to handle Tasks starting in .NET 4.0.
Let’s take a quick look at some of the simple things you might need to do with tasks, just so you can see how easy the new extensions are to work with. Tasks are small, self-contained units of work, and can often be expressed by a single method or even a lambda expression. Once a Task has been encapsulated in this way, we can begin its execution by wrapping it in the StartNew() method…
|
1 |
Task.Factory.StartNew(() => Console.WriteLine("This is a task!")); |
Sometimes we may be interested in the results of a Task, as well, and in these cases we can retrieve the results of the Task through its Result property, which waits until the value is available…
|
1 2 3 |
var task = Task.Factory.StartNew<string>(() => string.Format("Today's date is {0}", DateTime.Now.ToShortDateString())); Console.WriteLine(task.Result); |
Note the use of the generic type arguments on the StartNew() method; this denotes to the compiler that our task will return a value of type string.
Much of your work with the TPL will likely focus on individual tasks, but sometimes it’s useful for a Task to beget other Tasks. In these situations, Tasks can be arranged in a parent-child relationship…
|
1 2 3 4 5 |
var parentTask = Task.Factory.StartNew(() => { Console.WriteLine("In the parent..."); Task.Factory.StartNew(() => Console.WriteLine("In the child..."), TaskCreationOptions.AttachedToParent); }); |
Finally, starting Tasks is easy, but what if you need to cancel one? Luckily, since PLINQ is built on the TPL, cancelling Tasks in the TPL uses the exact same mechanism as in PLINQ. By passing a CancellationTokenSource to a Task when it’s created, the holder of the cancellation token can cancel that Task from anywhere else in the application…
|
1 2 3 4 5 6 7 8 9 |
var cancellation = new CancellationTokenSource(); Task.Factory.StartNew(() => { for (var i = 0; i < 1000; i++) { cancellation.Token.ThrowIfCancellationRequested(); Console.WriteLine("In the loop..."); } }, cancellation.Token); |
When we request a cancellation via our token, we’ll break out of the loop above at the beginning of the very next iteration.
These are just a few examples of how to make use of the TPL, but if you’d like to get a deeper understanding of the underlying concepts behind parallelism then this article from MSDN Magazine is an excellent start.
AggregateExceptions
With all of the power available to PLINQ and the TPL, you may be wondering what happens when something goes wrong. Luckily, functionality has been added to the framework to handle the special problems that can arise when working with concurrent programming.
The AggregateException is a new exception type that is thrown when an error occurs in the context of one of the new concurrent operations available in the framework; it records all exceptions that occur across all threads, and combines those into a single, aggregated exception. This rather neatly allows you to locate errors that occurred in any thread comprising a single operation…
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
var task = Task.Factory.StartNew(() => { Task.Factory.StartNew(() => { Console.WriteLine("In the first task."); throw new Exception("Exception from the first task"); }, TaskCreationOptions.AttachedToParent); Task.Factory.StartNew(() => { Console.WriteLine("In the second task"); throw new Exception("Exception from the second task"); }, TaskCreationOptions.AttachedToParent); }); try { task.Wait(); } catch (AggregateException e) { DisplayInnerExceptions(e); } private static void DisplayInnerExceptions(AggregateException e) { foreach (var exception in e.InnerExceptions) { var aggregate = exception as AggregateException; if (aggregate != null) DisplayInnerExceptions(aggregate); else Console.WriteLine(exception.Message); } } |
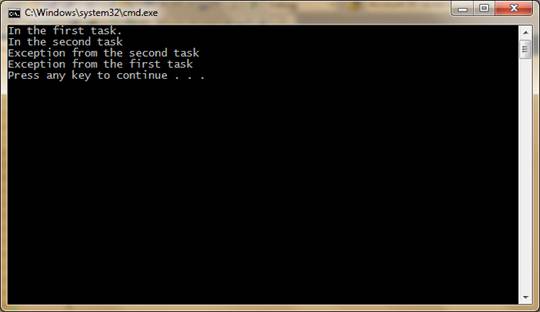
Figure 2. A simple exception handing demonstration.
However, it you recall, a Task can parent multiple other tasks, and since it’s entirely possible for both a parent Task and a child Task to each throw exceptions, it’s also possible to receive an AggregateException that, in itself, contains other AggregateExceptions. In this case it would become necessary to recursively walk the exception tree to ensure that we find all exceptions that were thrown…
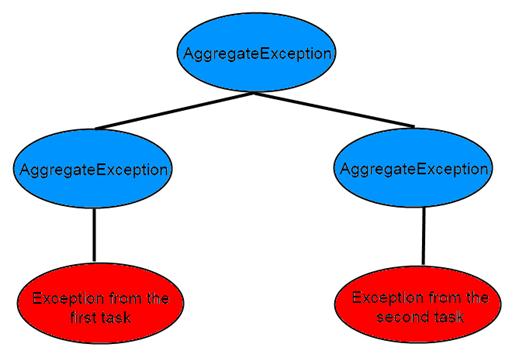
Figure 3. The potentially nasty AggregateException tree
That could quickly become a bit of a headache, but luckily the .NET framework provides a convenient method that performs this operation for us, flattening all of the exceptions into a series of individual exceptions…
|
1 2 3 4 5 6 7 8 9 |
try { task.Wait(); } catch (AggregateException e) { foreach (var exception in e.Flatten().InnerExceptions) Console.WriteLine(exception.Message); } |
The code above produces the exact same output as before, only in a more elegant way. In fact, the Flatten() method hides the complexity of recursively walking the exception tree entirely.
What Lies Ahead
As the comparatively free lunch provided by Moore’s Law for so many years of steadily draws to a close, developers will be forced to adapt their methods to take advantage of evolving hardware. This almost inevitably means that you will be parallelizing your code in the future in order to take advantage of the explosion of processors sure to begin materializing in all levels of consumer hardware. Although concurrent programming has long been a relatively black art, new frameworks such as PLINQ (and the TPL that drives it) promise to bring this once-arcane skill within the grasp of developers everywhere. Once you master these skills, you can rest assured that your code won’t be left behind by this new wave of processing power.
If this taste of the parallel power now available in .NET has whet your appetite for more, then there are a multitude of great resources available to help you dive deeper, both online and in print. A particularly great book is Adam Freeman’s Pro .NET Parallel Programming in C#. Also of value is Joseph and Ben Albahari’s C# 4.0 in a Nutshell; in fact, Joseph and Ben have been kind enough to make their chapter on threading available online, in its entirety, for free. This should serve as a great jump-start to not only PLINQ, but to the .NET threading model in general, so I wholeheartedly suggest you take a look!
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments