
Introduction
Almost all current Programming languages model their data in terms of objects while the relational databases use entities and relationships for the same purpose. LINQ to SQL is the first stage of LINQ technology, the aim of which is to bridge the gap between the two different ways of representing data entities. Before the introduction of LINQ, it was a common practice to devise database abstraction layers that translated the information between the relational representation of the database and the application’s domain-specific object models.
The aim of LINQ to SQL, which is another component in the ADO.NET family, was to provide a run-time infrastructure for managing relational data as objects without losing the facility of being able to query data, and use stored procedures. It does this by translating language-integrated queries into SQL for execution by the database, and then translating the results back into objects defined by the application domain. The application can manipulate the objects while LINQ to SQL stays in the background, tracking changes to the data automatically. LINQ does not aim to circumvent a data abstraction layer at the database level, based on stored procedures; in fact it makes their use easier for the programmer.
When an object is linked to relational data, it receives attributes to identify how properties correspond to columns within the database. This mapping is done by translating the relational database schemas into object definitions, and can be done automatically by design-time tools.
LINQ to SQL can be used by any .NET language that has been built to provide Language-Integrated Query.
This article discusses how LINQ to SQL can be used to design a data access layer and lists some best practices that can help to improve the performance of the application.
When to go for LINQ to SQL?
There are several ways to design a data access layer. .NET Framework 3.5 introduced several LINQ providers, including LINQ to SQL. This was intended to provide LINQ over relational databases but was implemented only for SQL Server. .NET 3.5 SP1 added the Entity Framework. This allowed the use of LINQ alongside any database including SQL Server, Oracle, DB2, MySQL, etc.
In .NET 4.0, the Entity Framework will be the strategic data access solution for applications that require a conceptual data model with strongly typed data, inheritance and relationships, to a whole range of relational database sources. However, LINQ to SQL will be supported for Rapid Application Development with a SQL Server back end.
Designing a Data Access Layer
Layered architectures are generally preferred for applications because of the code reuse, flexibility, performance and maintainability. In a layered architecture, the data access layer is mainly responsible of communicating with the database, whereas the business layer focuses on business logic and business rules. The presentation layer, of course, concentrates on the UI.
Choosing the data representation & transferring format between layers
LINQ to SQL works by mapping relational database schema to .NET classes. This mapping is provided in the Data Context which is the main source used to perform all query operations against the database. Classes modelled to map database tables with in the data context are known as Entity Classes. Properties of entity classes maps to table columns and each instance of the entity class represents a row with in the database table. These in-memory objects or entities are used as a transferring media of data via layers, but restricting the data context scope with in the class library. (Northwind.Products.Data: in sample)
Determining which layer(s) should access data
Since the data access layer is the only layer that communicates directly with the data base, any other layer is expected to communicate with the database via this layer; therefore this layer can be used to define methods that will use the data context to perform operations within the database. (Northwind.Products.DAL: in sample)
The following diagram elaborates the structure of the solution in the sample application.
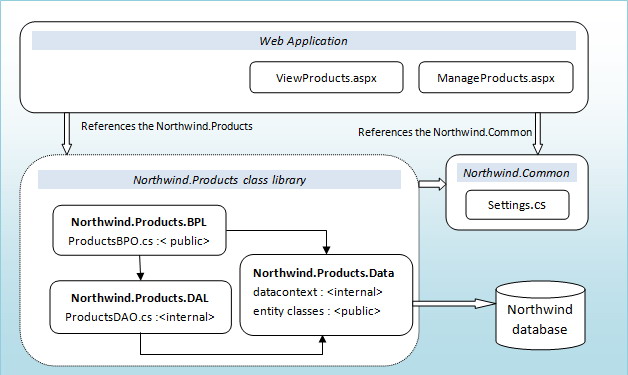
Designing Entities
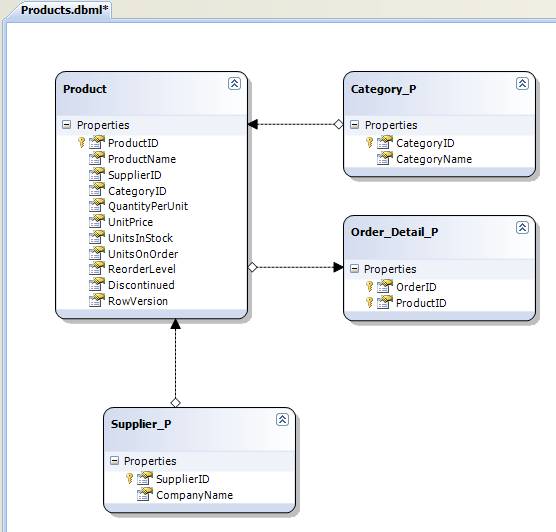
The choice of the entities to populate within the data context depends on the requirements. In our example, the purpose of Northwind.Products class library is to provide an interface to manipulate the product related information. Therefore, the related tables such as Categories, Suppliers and Order Details were populated with the Product table. A postfix of ‘_P’ is used to avoid naming conflicts when used with in multiple class libraries. (Products.dbml in Northwind.Products: in sample)
Managing the Data Context
The data context object consists of the information of its entity classes, their tracking information and the mapping information. To load and persist the data context object in memory consumes a considerable amount of memory, so it is instantiated and used within the method scope and disposed of after use. (ProductsDAO.cs in Northwind.Products: in sample)
Managing database connections
The connection string is required at every instantiation of a data context instance. It is therefore read at the application start and stored in a common global variable that can be accessed throughout the application. (Settings.cs in Northwind.Common: in sample)
Manipulating Data using LINQ to SQL
There are many ways of manipulating data in LINQ to SQL. There is no restriction in using tables, stored procedures, views or functions. All are possible, and the choice is purely an implementation decision. One way to implement Create, Read, Update, and Delete (CRUD) operations is to configure the behavior on the entity class at design time by specifying the stored procedures, or to use base tables directly, as follows.
Using Base Tables
In this example, a RowVersion column with a timestamp type is added to each table, to identify the row status (modified/not) and to handle concurrency conflicts.
C# Code: Perform an insert/update on Product table.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
//Insert/Update Product. internal bool SaveProduct(Product oProduct) { ChangeSet changeSet = null; int changeCount = 0; using (ProductsDataContext productDC = new ProductsDataContext(Settings.ConnectionString)) { productDC.DeferredLoadingEnabled = false; if (oProduct.RowVersion == null) { productDC.Products.InsertOnSubmit(oProduct); changeSet = productDC.GetChangeSet(); changeCount = changeSet.Inserts.Count; productDC.SubmitChanges(); } else { productDC.Products.Attach(oProduct, true); changeSet = productDC.GetChangeSet(); changeCount = changeSet.Updates.Count; productDC.SubmitChanges(); } } if (changeCount > 0) { return true; } else { return false; } } |
First, the rowversion of the product entity is checked to identify whether to insert or update. Then, to insert a new product, the InsertOnSubmit method is called on the Products entity, with the new entity instance passed to it. For updating, the Attach method is called by parsing the entity with changed values, and this sets the modified status to true, indicating that the entity has been modified.
The GetChangeSet method call on the data context provides a ChangeSet instance to track down the changes such as insert counts, update counts and delete counts. Finally, the SubmitChanges computes the changes to be made on the database and is executed to implement those changes.
Using Stored Procedures (SPs) & Functions to Query Data.
When a Stored Procedure or a SQL Function is added to a data context, it is marked as FunctionAttribute and its parameters are marked as ParameterAttributes, this identifies the procedure or Function as a method within the datacontext.
LINQ to SQL introduces various ways for handling Stored Procedures with known results; those with return results that change at execution according to parameters passed, and those that return data as output parameters. We can’t hope to cover all the permutations here, so this article will just show how Stored procedures are used with a minimum number of entities within the data layer, by mapping its return type to a particular entity.
When a SP is dragged on to a data context in the IDE, it automatically creates its return type which can be identified by the postfix ‘Result’ (ex: Orders_SelectByShippedDateResult). Instead, if we know the return type of the Stored Procedure, we can drag the Stored Procedure on to the entity within the IDE or change the Return Type property of the SP after adding the SP on to data context. It will result as follows.

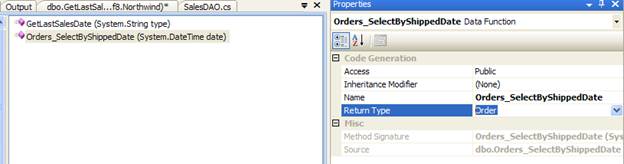
C# Code: Using a SP to query data.
|
1 2 3 4 5 6 7 8 |
internal List<Order> GetOrdersByShippedDate(DateTime ShippedDate) { using (SalesDataContext sales = new SalesDataContext(Settings.ConnectionString)) { sales.DeferredLoadingEnabled = false; return sales.Orders_SelectByShippedDate(ShippedDate).ToList(); } } |
C# Code: Using a SQL Function to query data.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
//GetLastSalesDate is a scaler valued function added to the data context. internal DateTime GetLastDate(string Type) { using (SalesDataContext dcSales = new SalesDataContext(Settings.ConnectionString)) { DateTime? _date; _date = dcSales.GetLastSalesDate(Type); if (_date.HasValue) { return _date.Value; } else { return new DateTime(); } } } |
(ProductsDAO.cs, SalesDAO.cs in Northwind.Products: in sample for more examples)
Handling Transactions
Though it is possible to define our own database transactions to group a set of database operations, it is always wiser to use the System.Transactions model, for it will take care of resources grouped under a single transaction and operations on multiple databases. Therefore these operations need to be scoped with the use of the Transactionscope object within the Business Layer, since a single unit of operation needs to be completed as a one business process. In the event of an error, it will rollback the entire operation, whereas Complete will commit the operation if successful. (ProductBPO.cs in Northwind.Products: in sample)
C# Code:
|
1 2 3 4 5 6 7 8 9 10 11 |
public bool SaveProduct(Product oProduct) { using (TransactionScope transcope = new TransactionScope()) { ProductsDAO dao = new ProductsDAO(); bool status = dao.SaveProduct(oProduct); transcope.Complete(); return status; } } |
Handling Concurrency Conflicts
During an update, each field is checked for concurrency conflicts, this checking frequency is controlled by the Update Check property of each field that can be set to ‘Always‘ or ‘WhenChanged‘. We will use a rowversion of a timestamp column in a table in order to detect concurrency conflicts. Within the data context, the concurrency conflict exceptions are caught as a ChangeConflictException. The ChangeConflicts property of the data context exposes the collection of objects that caused the conflicts while SubmitChanges executes.
C# Code:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
try { productDC.SubmitChanges(); } catch (ChangeConflictException cex) { foreach (ObjectChangeConflict conflictObject in productDC.ChangeConflicts) { // expose the neccessary information. } } |
Features of the Data Context
Here are some of the most important features of the Data Context
Object Identity
The data context is intelligent enough to track the entities that were loaded already, so if a request was made for the same object again, it would not result in two entity instances being loaded but only one. This behaviour of maintaining the uniqueness of the identity of the loaded objects in the data context is called Object Identity. This ensures that in-memory objects are not duplicated.
C# Code:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
internal List<Order> GetOrdersByShippedDate(DateTime ShippedDate) { using (ProductDCDataContext productDC = new ProductDCDataContext(Settings.ConnectionString)) { productDC.DeferredLoadingEnabled = false; DataLoadOptions loadOptions = new DataLoadOptions(); loadOptions.LoadWith<Order>(o => o.Order_Details); productDC.LoadOptions = loadOptions; return productDC.Orders_SelectByShippedDate(ShippedDate).ToList(); } } |
In the above example, load options are used to specify the child entity (Order_Details) that is to be loaded with parent entity (Order) and then the stored procedure (Orders_SelectByShippedDate) is called to filter the Orders. This results in Orders and Order_Details that is filtered by the criteria specified in the SP. Another instance of Order is not required since it is specified in the load options.
Object Tracking and Loading
Once an entity is loaded, the data context will by default, persist its old values and the new values, as indicated by the ObjectTrackingEnabled status being set to true. When retrieving entities with one-to-one, or one-to-many, relationships with other entities, the related entities will also be loaded by default at the time of retrieval. This is indicated by DeferredLoadingEnabled status set to true.
The default behavior is not necessarily the best in every circumstance. It could lead to high memory consumption, which will eventually slow the application. It is therefore better to disable the ObjectTrackingEnabled status when retrieving read-only data, and use Lazy Loading instead. The term ‘Lazy Loading’ means that you opt to load the required enitites only. This is done by explicitly defining the entities to load using the DataLoadOptions instance after disabling the DeferredLoadingEnabled status. Note that DeferredLoading requires ObjectTracking.
DataLoadOptions used with LoadWith<T> specifes which sub-objects should be loaded with the parent object, and AssociateWith<T>specifies the sub-objects and filter criteria on sub-objects to load when loading with the parent object.
C# Code:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
internal Product GetProductDetails(int ProductID) { using (ProductDCDataContext productDC = new ProductDCDataContext(Settings.ConnectionString)) { productDC.DeferredLoadingEnabled = false; DataLoadOptions loadOptions = new DataLoadOptions(); loadOptions.LoadWith<Product>(p => p.Category); productDC.LoadOptions = loadOptions; return (from p in productDC.Products where p.ProductID == ProductID select p).FirstOrDefault(); } } |
In the above example, only the Category entity is loaded at the time of retrieving Products, rather than all the related entities.
Apart from these features, data context also ensures that changes about to be committed do not conflict with the changes already made. This is named as an Optimistic offline lock. As well as tracking the changes made since the entities were loaded, it allows changes to be committed in a transactional manner, known as Unit of work.
Some ‘best practices’ with LINQ to SQL
Simple optimization techniques can be used within the application to improve LINQ to SQL performance.
- Access when needed.
- ‘Heavy’ objects such as data context must be accessed only needed and disposed quickly after use. (Refer: Managing the Data Context)
- Keep things simple.
- To avoid data context being bulky, populate only those entities that are actually required for the current process. (Refer: Designing Entities)
- Turn off tracking if it is not required.
- To avoid unneccessary identity management, when you merely wish to retrieve read-only data, set the ObjectTrackingEnabled status to false. (Refer: Features in the Data context)
- Specify Drilldown data.
- To avoid unneccessary loading of information, use AssociateWith to specifiy the extent of drilldown to just what is required, and no more. (Refer: Features in the Data context)
- Analyze the SQL Queries executed.
- With the use of the ‘LINQ to SQL Debug Visualizer’ that comes in SqlServerQueryVisualizer.dll, you are able to analyse the queries that are executed at runtime and can then optimize the queries as required. Since it is not integrated with .NET framework it needs to be downloaded and installed. (To install and run the SQL Debug Visualizer:)
Conclusion
Although LINQ to SQL was, in many ways, a stop-gap release to give time for the development of Entity Framework, it remains the quickest and most effective way of using LINQ with SQL Server. For this reason, many industry-specific applications will continue to rely on LINQ to SQL. It is simple, performs well, and provides a rich set of features. Therefore I believe that it is going to be useful to know how to design a DAL in LINQ to SQL for some time to come, whatever the strategic direction for LINQ in future releases of .NET
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments