
In part one of this series, I built a state machine which runs in the background to process uploaded resumes via step functions in C#. The overall process took seconds to complete, and this made it unsuitable for actual users who demand immediate (or at least, subsecond,) results.
To recap, the state machine executed two lambda functions: one to create a pre-signed URL to download the resume from S3, and one that uses Textract to find the GitHub profile in the resume. The result went to SQS for quick asynchronous consumption.
In this take, I will build a client facing API that can return resume data in real time using AWS lambda functions. The API will have three endpoints, POST, GET, and DELETE to handle these processed resumes.
The POST endpoint will upload the resume to S3 and kick off the asynchronous process via the state machine. This happens without logically blocking the API. The GET will query SQS for pending messages in the queue and quickly return processed information. Lastly, the DELETE endpoint will purge the queue once a recruiter is done reviewing resumes.
If you get lost with the code samples, be sure to check out the codes which is up on GitHub. This repo has the step functions from the previous part and this new API.
Continuing with Step Functions
Be sure to have the latest AWS CLI tools for .NET. If you are following from the previous post then you should already have the .NET 6 SDK, and the AWS CLI tool. The CLI tools are constantly evolving so I recommend upgrading to the latest available.
|
1 2 |
> dotnet tool update -g Amazon.Lambda.Tools > dotnet new install Amazon.Lambda.Templates |
This makes a list of templates available to you so you can spin up AWS projects. Because this is for an API, use the serverlessEmptyServerless template and create a new project inside the main project folder.
|
1 2 |
> dotnet new serverless.EmptyServerless --region us-east-1 --name Aws.Api.ResumeUploader |
This creates the scaffolding to build an API using lambda annotations. Lambda annotations bridge the gap between the lambda programming model and a more idiomatic .NET model already familiar to .NET developers.
This approach also takes care of creating a separate lambda for each endpoint. This means that the AWS Gateway routes the HTTP request and fires the lambda without ASP.NET or any reverse proxy in .NET doing the heavy lifting. This technique helps with cold starts and minimizes the work the lambda must do, which can help keep latencies low. The API itself is meant for real time consumption so keeping responses as quick as possible is ideal.
Because the scaffold is a bit silly and puts files and folders all over the place. I recommend restructuring your app in the following way. Simply flatten the folders and put them all under the main project like so.
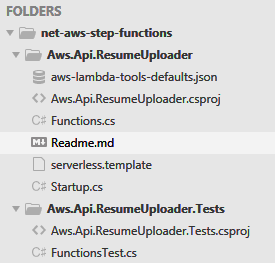
Figure 1. Folder structure
These new projects can coexist with the previously created step functions. Be sure to add these new projects to the main solution file.
|
1 2 3 |
> dotnet sln add Aws.Api.ResumeUploader\Aws.Api.ResumeUploader.csproj > dotnet sln add Aws.Api.ResumeUploader.Tests\Aws.Api.ResumeUploader.Tests.csproj |
Now, do a dotnet build, and double check that project references between the unit test and the API project are correct. The files created by the scaffolding are all the files you are going to need for this API.
Because this is using lambda annotations, the serverless.template template file is automatically updated and generated for you.
Build the API
Time for some coding fun. These are the NuGet packages you are going to need to flesh out the entire solution.
- Amazon.Lambda.Annotations: idiomatic approach to creating AWS lambda APIs in .NET
- AWSSDK.S3: S3 bucket client to upload resumes from the API itself
- AWSSDK.StepFunctions: step functions client to kick off the asynchronous process without blocking the API
- AWSSDK.SQS: simple queue service for reviewing processed resumes and purging old ones
- Moq: for the unit test project only, this is an object mocking tool in spite of a recent snafu with mishandling developer emails
All these dependencies, except for Moq, go in the API project. The lambda annotations dependency comes preinstalled via the scaffold. Be sure to upgrade all your NuGets to the latest version, this eliminates snags you might run into with the tooling.
API Skeleton
There should be a Functions.cs file with a Functions class. Gut the entire class and put this skeleton in place.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
public class Functions { private readonly IAmazonS3 _s3Client; private readonly IAmazonStepFunctions _sfnClient; private readonly IAmazonSQS _sqsClient; private const string S3BucketName = "<s3-bucket-name>"; private const string StateMachineArn = "<state-machine-arn>"; private const string SqsUrl = "<sqs-url>"; public Functions( IAmazonS3 s3Client, IAmazonStepFunctions sfnClient, IAmazonSQS sqsClient) { _s3Client = s3Client; _sfnClient = sfnClient; _sqsClient = sqsClient; } [LambdaFunction(Policies = "AWSLambdaBasicExecutionRole", MemorySize = 1024, Timeout = 5)] [RestApi(LambdaHttpMethod.Get, "/")] // GET endpoint public Task<IHttpResult> Get(ILambdaContext context) { throw new NotImplementedException(); } [LambdaFunction(Policies = "AWSLambdaBasicExecutionRole", MemorySize = 1024, Timeout = 5)] [RestApi(LambdaHttpMethod.Post, "/")] // POST endpoint public Task<IHttpResult> Post( [FromBody] string fileContent, // raw binary string [FromQuery] string fileName, ILambdaContext context) { throw new NotImplementedException(); } [LambdaFunction(Policies = "AWSLambdaBasicExecutionRole", MemorySize = 1024, Timeout = 5)] [RestApi(LambdaHttpMethod.Delete, "/")] // DELETE endpoint public Task<IHttpResult> Delete(ILambdaContext context) { throw new NotImplementedException(); } } |
The lambda annotations set the basic settings for each lambda function like the memory size and timeout. This also injects dependencies using dependency injection without a default constructor. Notice the POST endpoint takes the file content as a raw string instead of binary data like a byte array. Be sure to specify your own S3 bucket name, state machine ARN, and the SQS URL, you will find these settings at the top of the class.
Unit Tests Skeleton
Open the FunctionsTests.cs file in the test project. Gut the entire class and put this in place.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
public class FunctionsTest { private readonly Mock<IAmazonS3> _s3Client; private readonly Mock<IAmazonStepFunctions> _sfnClient; private readonly Mock<IAmazonSQS> _sqsClient; private readonly Functions _functions; public FunctionsTest() { _s3Client = new Mock<IAmazonS3>(); _sfnClient = new Mock<IAmazonStepFunctions>(); _sqsClient = new Mock<IAmazonSQS>(); _functions = new Functions( // inject mock dependencies _s3Client.Object, _sfnClient.Object, _sqsClient.Object); } } |
You should have a working build now. Build the entire solution and open the serverless.template file. In each generated lambda function configuration, add the following configuration.
|
1 2 3 4 5 6 |
"Properties": { "Architectures": [ "arm64" ], "FunctionName": "resume-uploader-api-<verb-name>" } |
Under the FunctionName make sure that this matches the endpoint verb. For example, resume-uploader-api-post for the POST endpoint and so on. This makes it much easier to find your lambda functions in the AWS console.
The ARM architecture uses the Graviton2 chip by AWS and it is recommended for most use cases. Luckily, .NET supports both Linux and ARM so there is nothing to worry about.
TDD
Next, to follow TDD (Test Driven Development) write the unit tests first then the implementation. This forces you to think of a succinct solution before diving into more complex uses cases. Think of it like drawing a painting, you start with abstract strokes like the background, sort of like the unit tests. Then, work your way into complex details in the foreground, sort of like the gory details to pass the tests.
The POST, GET, and DELETE endpoints must all use the AWS clients provided so simply verify these clients are being used, and assert the status code of the response. At this point, the emphasis is not necessarily the gnarly implementation details.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 |
[Fact] public async Task PostReturns201() { // arrange var context = new TestLambdaContext(); const string fileContent = "TWFueSBoYW5kcyBtYWtlIGxpZ2h0IHdvcmsu"; // assume base64 const string fileName = "test-file-name"; // act var response = await _functions.Post(fileContent, fileName, context); // assert Assert.Equal(HttpStatusCode.Created, response.StatusCode); _s3Client.Verify(m => m.PutObjectAsync( It.IsAny<PutObjectRequest>(), CancellationToken.None)); _sfnClient.Verify(m => m.StartExecutionAsync( It.IsAny<StartExecutionRequest>(), CancellationToken.None)); } [Fact] public async Task GetReturns200() { // arrange var context = new TestLambdaContext(); _sqsClient .Setup(m => m.ReceiveMessageAsync( It.IsAny<ReceiveMessageRequest>(), CancellationToken.None)) .ReturnsAsync(new ReceiveMessageResponse { Messages = new List<Message> { new() {Body = "stuff"} // the body is all I care about } }); // act var response = await _functions.Get(context); // assert Assert.Equal(HttpStatusCode.OK, response.StatusCode); } [Fact] public async Task DeleteReturns202() { // arrange var context = new TestLambdaContext(); // act var response = await _functions.Delete(context); // assert Assert.Equal(HttpStatusCode.Accepted, response.StatusCode); _sqsClient .Verify(m => m.PurgeQueueAsync( It.IsAny<PurgeQueueRequest>(), CancellationToken.None)); } |
Note in the POST endpoint, I am assuming that the body is a C# string in base64 format. This is because it really should be a byte array, or a stream. But since this is coming from the web, and specifically the AWS Gateway, this must be a string.
The GET endpoint simply takes the body property of the SQS messages and sends that back to the API client.
To pass these tests flesh out the implementation with these basic requirements from the unit tests.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
[LambdaFunction(Policies = "AWSLambdaBasicExecutionRole", MemorySize = 1024, Timeout = 5)] [RestApi(LambdaHttpMethod.Get, "/")] public async Task<IHttpResult> Get(ILambdaContext context) { var result = await _sqsClient.ReceiveMessageAsync (new ReceiveMessageRequest { QueueUrl = SqsUrl }); return HttpResults.Ok(result.Messages.Select(m => m.Body)); } [LambdaFunction(Policies = "AWSLambdaBasicExecutionRole", MemorySize = 1024, Timeout = 5)] [RestApi(LambdaHttpMethod.Post, "/")] public async Task<IHttpResult> Post( [FromBody] string fileContent, [FromQuery] string fileName, ILambdaContext context) { var byteArray = Convert.FromBase64String(fileContent); using var inputStream = new MemoryStream(byteArray); await _s3Client.PutObjectAsync(new PutObjectRequest { BucketName = S3BucketName, Key = fileName, InputStream = inputStream // upload an actual binary stream }); await _sfnClient.StartExecutionAsync(new StartExecutionRequest { Input = JsonSerializer.Serialize (new {storedFileName = fileName}), StateMachineArn = StateMachineArn }); return HttpResults.Created(); } [LambdaFunction(Policies = "AWSLambdaBasicExecutionRole", MemorySize = 1024, Timeout = 5)] [RestApi(LambdaHttpMethod.Delete, "/")] public async Task<IHttpResult> Delete(ILambdaContext context) { await _sqsClient.PurgeQueueAsync(new PurgeQueueRequest { QueueUrl = SqsUrl }); return HttpResults.Accepted(); } |
The one perilous implementation detail here is having to take the raw string from the request body and turn it into a C# stream so the PDF file can be properly uploaded to S3.
Lastly, hook up all dependencies using the IoC container provided for you in the Startup file.
|
1 2 3 4 5 6 |
public void ConfigureServices(IServiceCollection services) { services.AddAWSService<IAmazonS3>(); services.AddAWSService<IAmazonStepFunctions>(); services.AddAWSService<IAmazonSQS>(); } |
If you get compilation errors, there a NuGet package you will need to make this magic possible. Simply add AWSSDK.Extensions.NETCore.Setup to the project.
Deploy the API
With the codes taking shape, you should have a good build and passing unit tests. Change directory into the Aws.Api.ResumeUploader project and run the following command.
|
1 |
> dotnet lambda deploy-serverless |
The prompt should ask you for a name of the CloudFormation stack. Simply pick a name, I went with resume-uploader-api. The tool will also prompt for an S3 bucket to upload the zip files into before it deploys the lambda functions. Pick something like resume-uploader-api-upload. Keep in mind S3 bucket names must be unique, so if you are not able to use this name just pick a different one.
After the deploy tool successfully deploys, go into the AWS console and find IAM. Each endpoint has an execution role attached to it and they will need permissions to access AWS resources like SQS, S3, and Step Functions. If you have a hard time finding the execution roles, you can go via the lambda function. The execution role is listed under the Permissions in the Configuration tab.
Make sure the following permissions are specified for each endpoint.
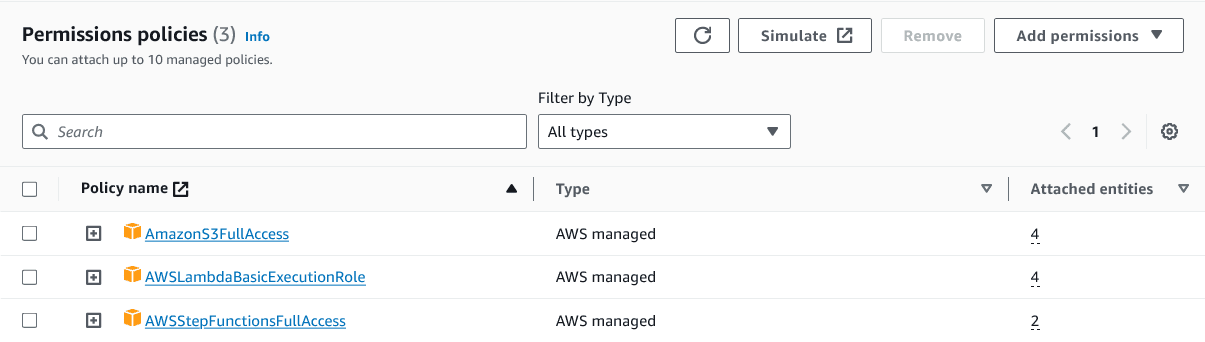
Figure 2. POST endpoint permissions
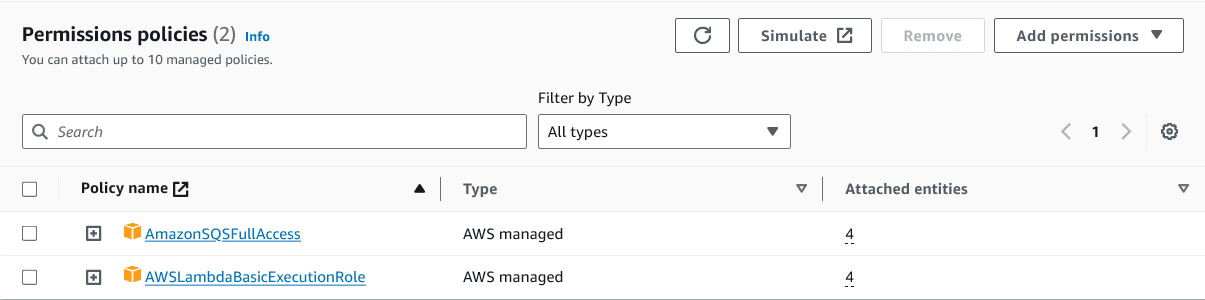
Figure 3. GET endpoint permissions
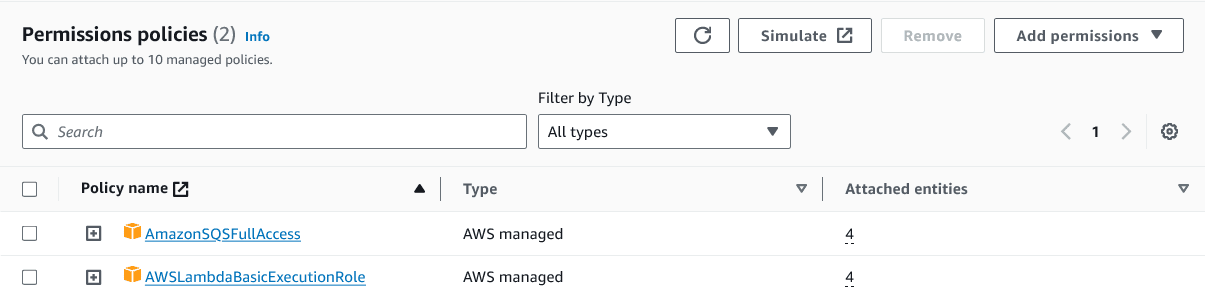
Figure 4. DELETE endpoint permissions
This is what the list of API lambda functions looks like.
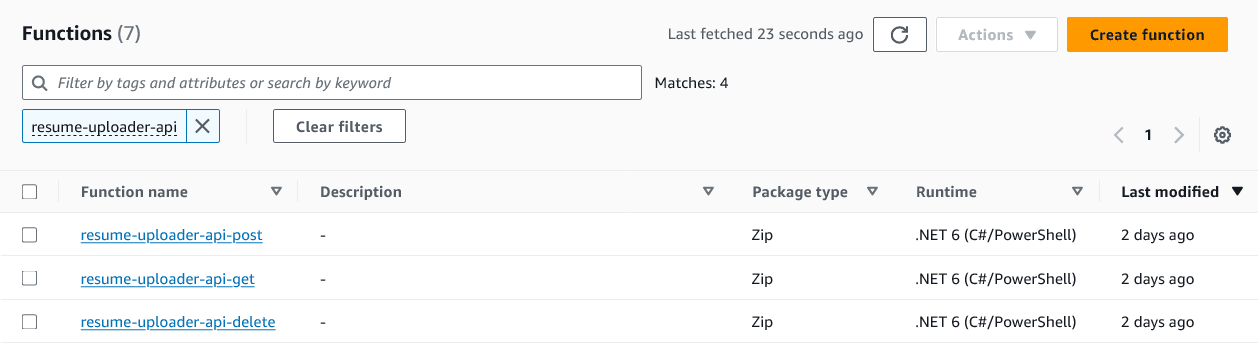
Figure 5. API lambda functions
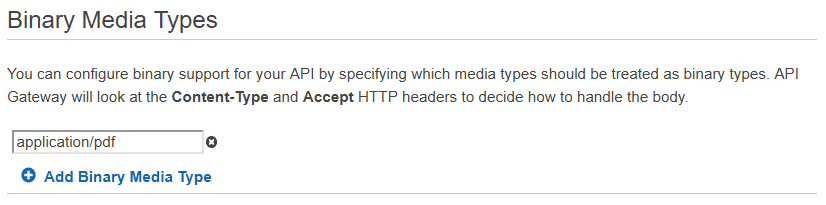
Lastly, before we can upload PDF files to our API the AWS Gateway must be configured to convert the binary format into a base64 string.
Go to the AWS console and click on the API Gateway. Find your API, it should match the name you specified in CloudFormation. Then click Settings and add application/pdf to the list of Binary Media Types. This is what allows you to assume that the file content is a string in base64 format in your lambda function.
Call the API
The API is now able to handle binary files directly and has permissions to execute step functions. This gets you over the hurdle I ran into earlier because it was not possible to simply kick off step functions from an S3 bucket event.
To kick off the state machine and upload a resume via the API.
|
1 2 3 |
> curl -i -X POST -H "Content-Type: application/pdf" --data-binary "@ExampleResume.pdf" https://<GATEWAY-API-ID>.execute-api.<REGION>.amazonaws.com/Prod/?fileName=ExampleResume.pdf |
Be sure to specify the whack at the end of the URL like /. The AWS Gateway is sometimes sensitive to this and returns a 403 Forbidden when it is missing. This CURL command assumes that the ExampleResume PDF file is under the current folder.
You should see a 201 Created response when the lambda function completes execution. Keep in mind that the latency should remain fast because all this does is upload a file and kick off a background process.
Give it a few seconds, then follow up the previous command with a call to the GET endpoint. If everything went well, you should have items in the SQS queue.
|
1 2 3 |
> curl -i -s -X GET -H "Content-Type: application/json" https://<GATEWAY-API-ID>.execute- api.<REGION>.amazonaws.com/Prod/ |
If there is still nothing in the queue, check in CloudWatch or Step Functions. Luckily, AWS has some really nice monitoring tools to figure out what went sideways. Also, be sure to check the S3 bucket and make sure that the file uploaded is a proper PDF file.
Finally, once you are done, the DELETE endpoint purges the queue entirely.
|
1 2 |
> curl -i -s -X DELETE -H "Content-Type: application/json" https://<GATEWAY-API-ID>.execute- api.<REGION>.amazonaws.com/Prod/ |
Conclusion
Step functions in C# embrace everything you already know about building complex back-end systems. When latency is a concern, an asynchronous process can run in the background and allow APIs and other customer facing solutions to remain responsive.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved




Load comments