
Dapper is a lightweight micro-ORM for .NET that extends ADO.NET with simple object mapping through extension methods on IDbConnection. Unlike Entity Framework, Dapper gives you full control over your SQL while handling the tedious work of mapping query results to C# objects. This guide covers every major Dapper API method – ExecuteAsync, QueryAsync, QueryFirstAsync, QuerySingleAsync, multi-mapping for joins, stored procedure calls, transactions, and bulk inserts – with async examples you can run against the AdventureWorks database on .NET 6.
Read also: Entity Framework query hints for SQL Server
What is the Data Access Layer (DAL) – and why use Dapper?
The Data Access Layer (DAL) is often the most critical part of any application. Dapper is a micro-ORM built with simplicity, top-notch performance, and ease of use in mind. In this take, I will walk you through what Dapper has to offer and why it has become the tool of choice for many high-demand solutions.
Dapper is a lightweight shim around ADO.NET for data access via extension methods. To keep this relevant to any real application, there is quite a bit of code, which I won’t be able to show, so I recommend downloading the repo from GitHub. The focus here is to walk through the code API and follow best practices for building a DAL. The set of extension methods can feel overwhelming because there is a lot of functionality to cover.
I recommend general familiarity with LINQ and the List<> generic class in C#. This guide can be used as a reference so you can read one section at a time. At each pause, I encourage you to play with the code and allow the information to sink in.
I opted to use only async methods because these are the ones anyone should be using in a production environment. C# and .NET make this relatively painless via async/await, albeit with caveats.
You will need the .NET 6 SDK and a copy of SQL Server preloaded with the AdventureWorks database to run the code sample. The connection string in the repo points to the MSLocalDB instance, which you can get from SQL Server Express. It is also possible to point this to another SQL Server instance via the DataSource property. Fortunately, Visual Studio is not required unless you prefer to use this tool.
ExecuteAsync
Whenever you see the ExecuteAsync method, it is safe to assume this performs a mutation to the backend database. The method returns an int with the number of rows affected by the query. In SQL, this typically means INSERT, UPDATE, or DELETE statements.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
public async Task<int> UpdateSalesOrder(int salesOrderId, byte status) { const string sql = @" UPDATE Sales.SalesOrderHeader SET STATUS = @status WHERE SalesOrderID = @salesOrderId"; var param = new {status, salesOrderId}; using var conn = _db.GetAdventureWorksConnection(); return await conn.ExecuteAsync(sql, param) .ConfigureAwait(false); } |
It is best to nuke any synchronization with the main thread at the data access layer because this can affect scalability. Therefore, it is a good idea to set configure await to false, so this does not wait on the main thread. Unfortunately, C# does not do this automatically for the developer, so it must come from muscle memory. A good rule of thumb is if you are working in the DAL, put ConfigureAwait(false) in every call stack method. If context information is necessary at this level, one technique is sending this data via a method parameter to avoid synchronization.
Failing to await the call in the repository bombs because the connection falls out of scope and gets closed before the task gets awaited. A best practice is to go ahead and do async/await but do it as efficiently as possible. If there are passthrough layers up in the call stack, it is acceptable to return a Task.
Note param is a throwaway POCO that does not need to be strongly typed. The one gotcha here is the property must match the SQL variable in the query. T-SQL isn’t case sensitive, assuming the collation of the database is set this way, and will bind correctly even if there isn’t an exact case match.
QueryAsync
This method gets a list of query results that can be enumerated. Specifying the return type via a generic parameter, i.e., <SalesOrder>, binds the results in managed code. Note if the query result is empty, this method will send back an empty list with a count of zero.
As a side note, binding to a C# record instead of class requires at least a parameterless default constructor otherwise Dapper throws an exception.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
public async Task<List<SalesOrder>> GetSalesOrders() { const string sql = @" SELECT CustomerID, SalesOrderID, ROW_NUMBER() OVER(ORDER BY CustomerID) AS RowNumber FROM Sales.SalesOrderHeader"; using var conn = _db.GetAdventureWorksConnection(); return (await conn.QueryAsync<SalesOrder>(sql) .ConfigureAwait(false)) .AsList(); } |
The result from the query is a weakly typed enumerable with lazy load, and I recommend materializing the list in-memory with AsList. Without this technique, the code runs the risk of remunerating through the result set multiple times, which is inefficient. Unless the plan is to travel through the results one at a time without repeats, the safest option is to stash this in the heap and let the garbage collector do the rest. This technique works like a ToList in LINQ but does not duplicate the underlying list into another block of memory.
Read also: SQL Server subquery patterns
QueryFirstAsync
To pluck the first item in the result set, use the QueryFirstAsync method. Be sure to specify an ORDER BY in the SQL query to make the return object more predictable.
A word of caution here, sorting rows in SQL puts the workload on the SQL Server engine, which may not be ideal. An alternative is to query for the entire list and sort in managed code, which can scale horizontally.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
public async Task<SalesOrder> GetFirstSalesOrder() { const string sql = @" SELECT CustomerID, SalesOrderID, ROW_NUMBER() OVER(ORDER BY CustomerID) AS RowNumber FROM Sales.SalesOrderHeader ORDER BY SalesOrderID"; using var conn = _db.GetAdventureWorksConnection(); return await conn.QueryFirstAsync<SalesOrder>(sql) .ConfigureAwait(false); } |
This method only picks the first item on the list and returns the object. If the query comes back empty, you do not get back a null but a thrown exception. The good news is this at least guarantees a result from the query.
QueryFirstOrDefaultAsync
If getting a nullable object is preferred, this works like LINQ’s FirstOrDefault. The return type Task<SalesOrder?> declares this as nullable. This feature is available in C# +8 and specifies which type may return null. In .NET 6, new projects get this feature enabled by default via the Nullable flag in the project file. What’s nice is the compiler knows as much information as the method API call because queries do not throw when the return object is nothing. This nullable feature makes the compiler fire warnings when the code is at risk of null exceptions.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
public async Task<SalesOrder?> GetFirstSalesOrderOrDefault( int customerId) { const string sql = @" SELECT CustomerID, SalesOrderID, ROW_NUMBER() OVER(ORDER BY CustomerID) AS RowNumber FROM Sales.SalesOrderHeader WHERE CustomerID = @customerId ORDER BY SalesOrderID"; var param = new {customerId}; using var conn = _db.GetAdventureWorksConnection(); return await conn.QueryFirstOrDefaultAsync<SalesOrder>(sql, param) .ConfigureAwait(false); } |
This method API blends seamlessly with the compiler because it knows the code can throw exceptions without proper null checks. I recommend automating this in the compiler so you get feedback on when it’s time to code defensively.
QuerySingleAsync
To grab a single item from the database, use this method.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
public async Task<SalesOrder> GetSingleSalesOrder(int salesOrderId) { const string sql = @" SELECT CustomerID, SalesOrderID, ROW_NUMBER() OVER(ORDER BY CustomerID) AS RowNumber FROM Sales.SalesOrderHeader WHERE SalesOrderID = @salesOrderId ORDER BY SalesOrderID"; var param = new {salesOrderId}; using var conn = _db.GetAdventureWorksConnection(); return await conn.QuerySingleAsync<SalesOrder>(sql, param) .ConfigureAwait(false); } |
Note the query must return exactly a single row. If not, Dapper unwinds the call stack via a thrown exception. This guarantees one object in the return type, so the compiler can assume this is not nullable.
Typically, with these types of queries, expect to see a unique id in the table so it can return one row. If this assumption turns out to be false, then look out for exceptions in the logs. At the very least, this method reinforces data integrity in managed code because of the single object limitation.
QuerySingleOrDefaultAsync
Anytime you see OrDefault in the API method name, it is safe to assume the return type is nullable. A best practice is to let the compiler know this fact via a question mark in the return type. This keeps the feedback loop between compilations full of good information.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
public async Task<SalesOrder?> GetSingleSalesOrderOrDefault( int salesOrderId) { const string sql = @" SELECT CustomerID, SalesOrderID, ROW_NUMBER() OVER(ORDER BY CustomerID) AS RowNumber FROM Sales.SalesOrderHeader WHERE SalesOrderID = @salesOrderId ORDER BY SalesOrderID"; var param = new {salesOrderId}; using var conn = _db.GetAdventureWorksConnection(); return await conn.QuerySingleOrDefaultAsync<SalesOrder>(sql, param) .ConfigureAwait(false); } |
In this method, the query has the option to return nothing without risking a thrown exception in Dapper. This method API returns exactly one object or the default value which is typically null.
QueryMultipleAsync
This method runs multiple queries simultaneously and binds the result via a grid reader. The reader can be strongly typed in C#, which returns a list of enumerable objects. This works like QueryAsync, except it runs multiple queries.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
public async Task<List<SalesOrder>> GetSalesOrders(int customerId) { const string sql = @" SELECT CustomerID, SalesOrderID as [SalesEyeDeed], ROW_NUMBER() OVER(ORDER BY CustomerID) AS RowNumber FROM Sales.SalesOrderHeader SELECT CustomerID, SalesOrderID, ROW_NUMBER() OVER(ORDER BY CustomerID) AS RowNumber FROM Sales.SalesOrderHeader ORDER BY SalesOrderID SELECT CustomerID, SalesOrderID, ROW_NUMBER() OVER(ORDER BY CustomerID) AS RowNumber FROM Sales.SalesOrderHeader WHERE CustomerID = @customerId ORDER BY SalesOrderID"; var param = new {customerId}; using var conn = _db.GetAdventureWorksConnection(); using var query = await conn.QueryMultipleAsync(sql, param) .ConfigureAwait(false); var result = new List<SalesOrder>(); result.AddRange((await query.ReadAsync<SalesOrder>() .ConfigureAwait(false)) .AsList()); result.AddRange((await query.ReadAsync<SalesOrder>() .ConfigureAwait(false)) .AsList()); result.AddRange((await query.ReadAsync<SalesOrder>() .ConfigureAwait(false)) .AsList()); return result; } |
Can you spot the typo? Go back and look for [SalesEyeDeed], unfortunately with these big blobs of SQL text, it is easy to mess these up. I recommend going over the SQL query thrice and making sure it matches the property name in the type without case-sensitivity. In this case, SalesOrderId is an int, so when Dapper can’t bind to anything, it defaults the value type to zero. Dapper does not throw an exception and defaults the property type, which can be undesirable in a production environment because this fails silently.
One alternative is to use a stored procedure, so it’s easier to spot mistakes in SQL. This provides some feedback, and you are not hunting for errors in a wall of text.
Stored Procedure
A stored procedure can be called via the CommandType parameter from System.Data.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
public async Task<List<EmployeeManager>> GetEmployeeManagers( int businessEntityId) { const string sql = "dbo.uspGetEmployeeManagers"; var param = new {businessEntityId}; using var conn = _db.GetAdventureWorksConnection(); return (await conn.QueryAsync<EmployeeManager>( sql, param, commandType: CommandType.StoredProcedure) .ConfigureAwait(false)) .AsList(); } |
Be sure to specify just the stored procedure name in the SQL text because it does not need parameters or the exec statement. Dapper takes care of building the correct query before it gets sent. A common snag is to try to bind parameters manually like in other method APIs which fails.
Transaction
Explicit transactions from the SQL client can be initialized via the BeginTransaction method.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
public async Task<int> UpdateSalesOrderTransaction( List<int> salesOrderIds, byte status) { const string sql = @" UPDATE Sales.SalesOrderHeader SET Status = @status WHERE SalesOrderID = @salesOrderId"; var result = 0; using var conn = _db.GetAdventureWorksConnection(); conn.Open(); using var trans = conn.BeginTransaction(); foreach (var salesOrderId in salesOrderIds) { var param = new {status, salesOrderId}; result += await conn.ExecuteAsync(sql, param, trans) .ConfigureAwait(false); } trans.Commit(); return result; } |
One common gotcha is to forget to Open the connection because all other API methods do this implicitly. Be sure to set the transaction parameter in each individual query. The ExecuteAsync method has an optional transaction parameter, and the default is null. Without explicit transactions, each statement gets executed as a separate transaction. With a transaction, everything gets rolled back automatically if you forget to call the Commit method.
Table Value Parameter
One alternative to sending a bunch of statements with an explicit transaction is to send a TVP instead.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
public async Task<int> UpdateSalesOrdersTvp( List<SalesOrderType> salesOrders) { const string sql = @" UPDATE soh SET soh.Status = tvp.Status FROM Sales.SalesOrderHeader soh INNER JOIN @tvp tvp ON soh.SalesOrderId = tvp.SalesOrderId"; var param = new { tvp = salesOrders .ToDataTable() .AsTableValuedParameter("SalesOrderType") }; using var conn = _db.GetAdventureWorksConnection(); return await conn.ExecuteAsync(sql, param) .ConfigureAwait(false); } |
TVPs are ideal when you have thousands of rows or less. For millions of rows, use Bulk Copy instead for better performance.
If joins against the TVP are necessary, it is possible to add a clustered index on the column of interest, for example, SalesOrderId. If columns in the TVP type are known to be not null, it is best to let the SQL engine know this fact. To boost performance, TVPs can be declared as memory-optimized so that they live in memory instead of tempdb.
Dapper provides the extension method AsTableValuedParameter, which expects a DataTable and the name of the TVP. The ToDataTable method is a custom extension method found in the GitHub repo, so I recommend peeking on your own time since it’s somewhat involved.
In general, the ToDataTable algorithm does the following:
- New up a
DataTableinstance - Loop through property names in the POCO and add them as columns in the data table
- Loop through the values and add them as rows in the data table
Unfortunately, Dapper expects the consuming code to do all this work but this ToDataTable extension method comes in handy when working with TVPs.
Unit Test
Finally, an argument can be made not to include any unit tests in the DAL. The reasoning is this does not actually test the SQL query, which is a valid argument.
If I may rebut, unit tests aren’t integration or functional tests but simple sanity checks to get even faster feedback on the code. What if I forget to pass in the SQL text or param to the extension method in Dapper? What happens when I set a transaction but didn’t mean to? These unit tests work like a safety net when any reasonable developer inevitably makes a dumb mistake.
No business logic belongs in the DAL, but there are exceptions to this rule. I often find conditionals, switches, loops, and somewhat complex logic in the data repository, which deserve test coverage.
The code sample uses Xunit and Moq to unit test the repository. Executing dotnet test in the test project automatically installs these dependencies and runs all unit tests. Your particular test project may not use Xunit, but I find Moq is used consistently throughout most C# test projects.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
[Fact] public async Task GetSalesOrdersMultiple() { // arrange _reader .Setup(m => m.ReadAsync<SalesOrder>(true)) .ReturnsAsync(new List<SalesOrder>()); _db .Setup(m => m.QueryMultipleAsync( It.Is<string>(s => s != null), It.Is<object>(o => o != null), null, null, null)) .ReturnsAsync(_reader.Object); // act var result = await _repo.GetSalesOrders(1); // assert Assert.NotNull(result); } |
You may be wondering, how is this even possible when Dapper is a bunch of untestable extension methods? To make this testable, this DAL puts extension methods in a wrapper class with an interface that can be mocked.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
public async Task<IGridReader> QueryMultipleAsync( string sql, object? param = null, ISqlTransaction? transaction = null, int? commandTimeout = null, CommandType? commandType = null) => new GridReaderWrapper(await _dbConnection.QueryMultipleAsync( sql, param, transaction?.GetTransaction(), commandTimeout, commandType).ConfigureAwait(false)); |
This works much like a lightweight proxy layer that delegates work to the extension method in Dapper. I encourage you to poke around in the code sample to get a better feel for this technique.
Architecture
This data access layer follows Clean Architecture via Inversion of Dependency and composition. Interfaces define what capability is available in Dapper without any guesswork. As a nice bonus, the ISqlConnection interface includes API code comments which pop up in IntelliSense. Most of the code you have seen so far goes in the repository class.
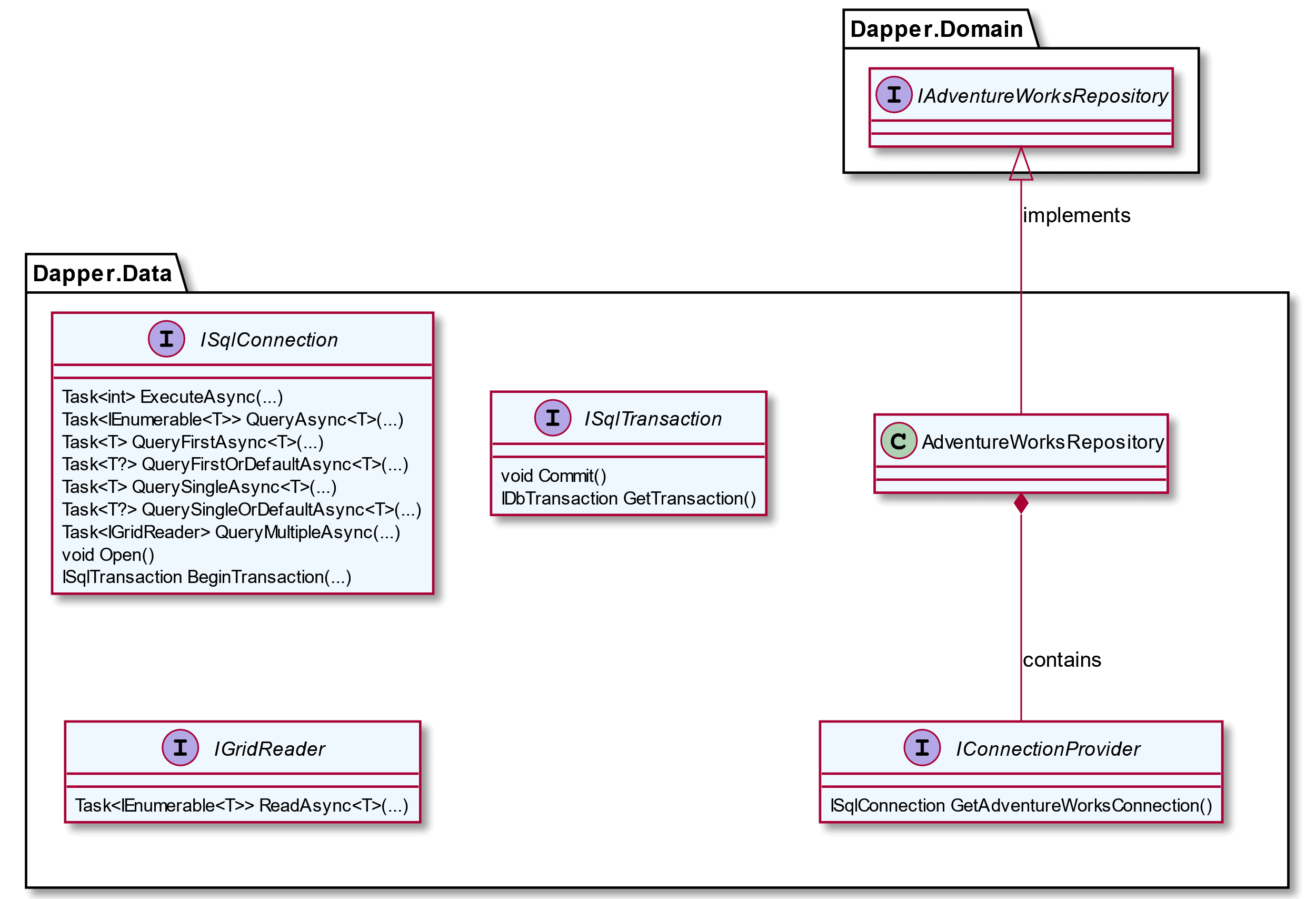
Figure 1. Data Access Layer with Clean Architecture
Note the interface lives in the Domain project, which is the consuming code. By inverting the dependency in this way, the business logic gets to decide what it needs without worrying about implementation details. The Data project then takes on this dependency to fulfil the interface contract.
Conclusion
Dapper gives you a ton of functionality out of the box via ADO.NET extension methods. With a bit of work, it is possible to build a data access layer that is testable, maintainable, and performant.
You may also be interested in…
Temporary Tables in SQL Server
Building a BI dashboard with R and ASP.NET
Save 35% on Redgate’s .NET Developer Bundle
FAQs: A Practical Guide to Dapper
1. What is Dapper and how does it compare to Entity Framework?
Dapper is a micro-ORM that maps SQL query results to .NET objects using extension methods on IDbConnection. Unlike Entity Framework, which generates SQL from LINQ expressions and manages change tracking, Dapper requires you to write your own SQL but gives you full control over query performance. Dapper is significantly faster than EF for read-heavy operations because it has minimal overhead – it’s essentially a thin mapping layer on top of ADO.NET.
2. How do you use QueryAsync in Dapper?
QueryAsync returns a list of typed results from a SQL query. You call it as an extension method on an open IDbConnection: var results = await connection.QueryAsync<SalesOrder>(sql, parameters).ConfigureAwait(false). The generic type parameter binds each row to a C# class by matching column names to property names. Use AsList() on the result to materialize it into a List<T> and avoid re-enumeration.
3. Does Dapper support stored procedures and transactions?
Yes to both. For stored procedures, pass commandType: CommandType.StoredProcedure to any Dapper method. For transactions, use connection.BeginTransaction(), pass the transaction object to each Dapper call via the transaction parameter, then Commit() or Rollback(). Dapper also supports TransactionScope for distributed transactions across multiple connections.
4. Can Dapper handle multi-table joins and complex mappings?
Dapper supports multi-mapping through overloads that accept multiple generic type parameters. For example, QueryAsync<Order, Customer, Order>(sql, (order, customer) => { order.Customer = customer; return order; }, splitOn: “CustomerId”) maps a joined result set to nested objects. The splitOn parameter tells Dapper where to split the column set between types.




Load comments