
Introduction to Machine Learning with Accord.NET and F#
How many times have you heard the expression Machine Learning as something common, but at the same time so unknown, even if you’re an experienced developer? How many times have you told yourself that a machine alone learning something is a reality very far from yours – a REST-CRUD-like world. And what about the languages (R, e.g.) these ‘too-scientific’ programmers use to, well, program?
Every time you see a personalized ad or a recommendation in your favorite retailer website based on your previous activities, what you’re seeing, in fact, are machine learning algorithms running behind the scenes. From your latest song suggestion on Spotify, the last face recognition made on your Facebook picture, to the risk analyzed by PayPal on each of your payment transactions, machine learning is everywhere, helping all sorts of companies to personalize their user experience on a large scale.
What is Machine Learning?
To understand the term, you need to remember how our own brains work. We were born with no information about the world and, as we grow, the continuous exposure to more and more data makes us comprehend that putting a finger in the socket is not a good idea. Of course, we have the act of committing mistakes as our main fuel to the learning process, but we also learn a lot just paying attention to the other things that surround us. That’s how machine learning works.
With no need to be updated, a machine learning software solution is programmed once and learns by itself progressively after receiving more inputted data. It means that, if we provide the strings Yellow Square, White Square and Black Rectangle to a machine learning software application, for example, after inputting an image of each geometric form, when we ask the computer what the image of a black square is, it is going to answer: Black Square.
Just like humans, the younger the system, the more susceptible to errors it will be. The goal is to let the program read a large amount of data over time in a way it can improve its predictions and decisions. In other words, machine learning can be translated into functions. Mathematically, its algorithms are represented as a single function like that:
|
1 |
y = f(x) + e |
Where the elements are basically:
- y, the result. What are you trying to predict here?
- f, the function itself. What we’re really trying to discover that makes things happen based on…
- x, the input data;
- e, error. It says that, no matter how hard we try to guess how things would happen (prediction), we’ll never have enough inputs to perfectly go from x to y.
Linear regressions
Inside this functional universe, some models, like regressions, are specialized in number predictions, quantities to be more specific. For example, imagine an algorithm where we always input the same data (let’s say ‘a’) and it returns some results after six attempts:
|
Input |
Result |
|
a |
1.0 |
|
a |
2.0 |
|
a |
1.5 |
|
a |
1.5 |
|
a |
1.4 |
|
a |
1.5 |
What would you say is the next possible result if we input a seventh ‘a’? Probably you’d go with 1.5, because your mind automatically calculates the value of 50% of the total results, or at least some value between 1.5 and 2.0.
What your brain did just now is called regression, linear regression. Its goal is trying to get the formula we’ve seen and find the least number of variables that substantially impact determining f(x) with the highest correct percentage possible the value of y.
Now, imagine you’ve opened a small cupcakes shop, and you want your clients to being able to order cupcakes online via a website. Then, you decided that it would be interesting to collect a rating (1 to 5 stars) for each type of cupcake available for purchase. After searching a little bit, some behaviorist articles also said that, when users are confronted with products of low ratings, most of them abandon the purchase. It’s a good practice to prevent this by showing a prefilled approximate value as shown in Figure 1 of how many product items (cupcakes, in this case) the clients usually order for each type (considering, mainly, the low-rated ones). Linear regression is going to provide the perfect solution to your needs.
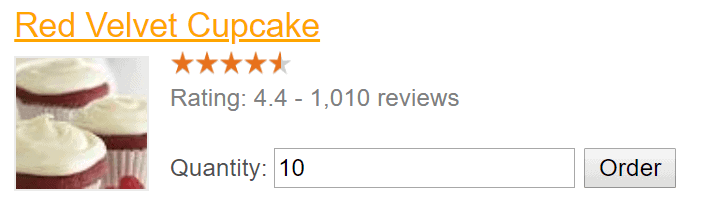
Figure 1. The cupcake order page
This example will use F# as the main functional language. It integrates with Accord.NET, one of the best .NET machine learning frameworks, specialized in statistical implementations. Combined, they are a great fit for writing linear regression on the .NET platform, as you’ll learn next.
Setting up the project
Everything you’ll need to follow along with this article is the latest version of Visual Studio (the Community edition is just fine). However, most .NET developers complete the installation selecting only the single options available for .NET desktop development and the Universal Windows Platform for C#. In this case, you’ll also need to select the Data science and analytical applications workload, as you can see in Figure 2. This option will install the data science languages (R and F#) you will need to implement the machine learning code. It’s available during the VS installation process only (if you already have VS installed, you can run the installer again and select the proper workload).
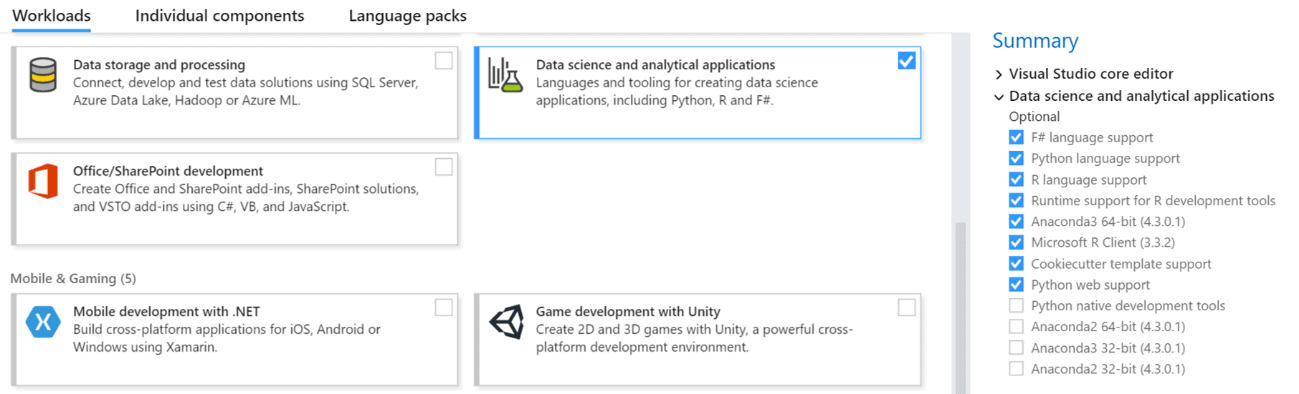
Figure 2. Installing the data science workload.
Once the workload is installed, open Visual Studio and go to menu File > New > Project…. Select the Installed tab, select the options Visual F# > Console Application and type a name for your project, Cupcake Sales Regression (Figure 3). If you have trouble finding the right type of application template, you can also search for F#.
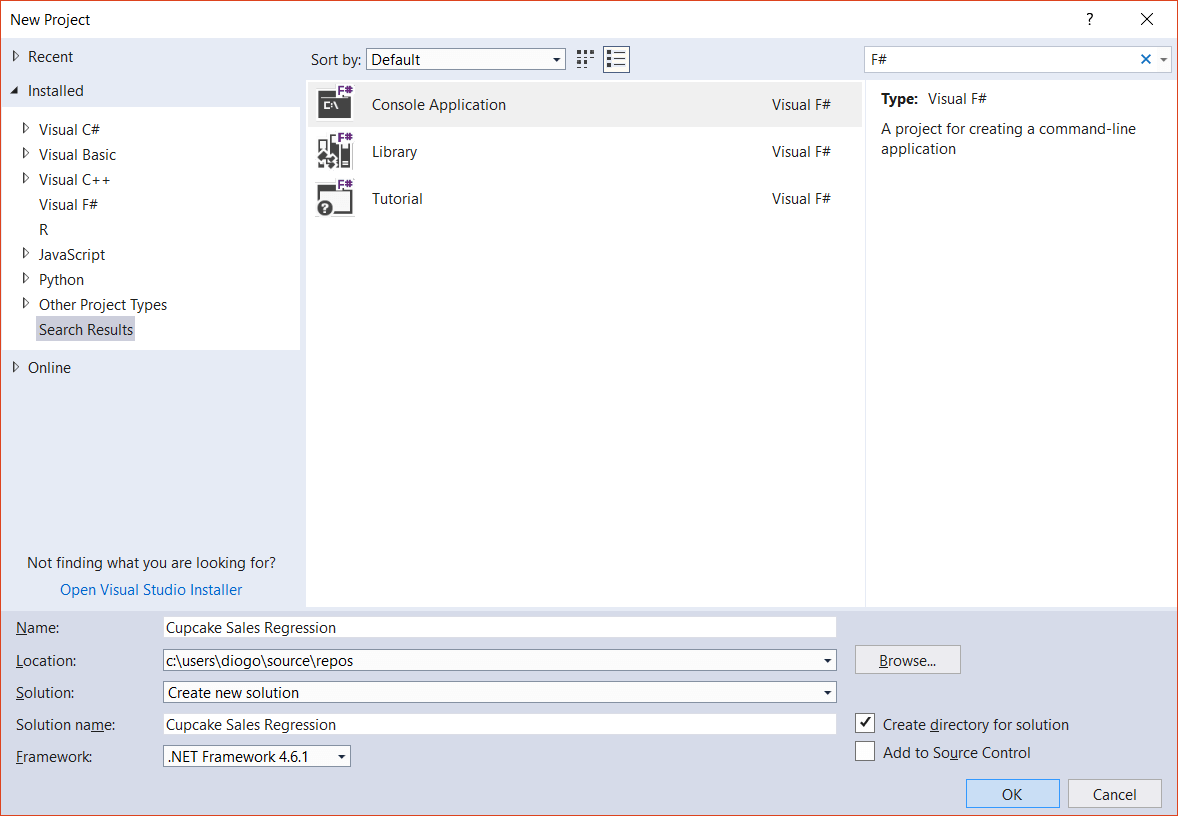
Figure 3. Creating a new Visual F# project.
Once it’s finished creating the project, Visual Studio will open a file called Program.fs, the main file of the program. The extension fs comes from F-sharp and represents the source files for F#, which can be compiled as part of any .NET project. However, for simplicity, this example is going to use files of fsx extension, which comes from F-sharp scripts. They are independent, and individual F# files are intended to run as a script (most of the time for test purposes only). Go to the project in Solution Explorer window, right click it, and select Add > New Item…, then search for F#, select the option F# Script File and give it the name CupcakeSalesRegression.fsx.
You will also need to set up the two dependencies of Accord.NET via NuGet Package Manager for the project: the core and statistics dependencies, as well as the FSharp.Data package (which, among other things, manages providers for working with structured file formats, like CSV). For this, go to menu View > Other Windows > Package Manager Console and run the following commands:
|
1 2 3 |
install-package Accord install-package Accord.Statistics install-package FSharp.Data |
Pay attention to the logs and make sure it ends with the message Successfully installed …. You should see the following new items added to the References section as shown in Figure 4:

Figure 4: The project references
F# is a scripting as well as a REPL language. REPL comes from Read-Eval-Print Loop, which means that the language processes single steps one at a time like reading the user inputs (usually expressions), evaluating their values and, in the end, returning the result to the same user. All that happens in a loop until the loop ends. Visual Studio provides a great F# Interactive view that runs the scripts in REPL mode and shows the results. Take the following Hello World example:
|
1 |
let hello = "Hello World" |
This code just creates a single variable (let keyword) and assigns a string value to it. When you run this code (select all the code text and press Alt + Enter), you’ll see the following result in the F# Interactive window (Figure 5):
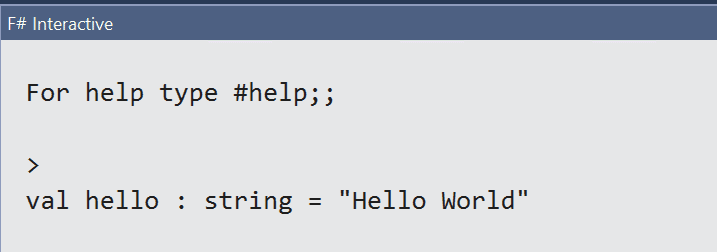
Figure 5: The results of a “Hello World” script
Look at how F# infers the types. In the end, this is a function called hello that receives no arguments and returns a string (in this case, a hardcoded one). But the language is even more flexible to allow a common mix of arguments with the code block itself. Replace the previous statement by the following and run the code again. The results are shown in Figure 6:
|
1 |
let hello s = s + "Hello World" |
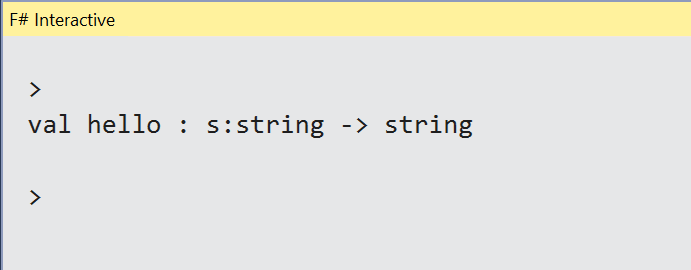
Figure 6: The result of running the hello function
This means that the same function now receives an argument called s of type string and returns another string (in this case, not hardcoded anymore). The -> operator tells you that what’s next is the result structure.
The Cupcake Sales Regression
The first step towards creating this regression is to understand how the data is organized in a business model way. That is, what is the real entity model representing the sales, each rating and the total of purchased items? Take a look at the following CSV data:
|
1 2 3 4 5 6 7 8 9 |
CupcakeId,Type,Price,CustomerId,Rating,Total 1,pumpkin,4.25,105,2,1 1,pumpkin,4.25,57,1,2 1,pumpkin,4.25,40,2,2 1,pumpkin,4.25,66,3,1 2,vanilla,4.25,59,5,10 3,white chocolate,4.25,81,1,2 4,red velvet,4.25,167,5,3 … |
You can download the full file here. Then, import it to your project root folder by copying and pasting the file into Solutions Explorer. If you see errors in the import code (shown later in the article), open the file in VS and make a small edit to get VS to process the file.
Observe, too, the following scatter plot representing the cupcake sales model data. Accord.NET linear regression is going to map all the sale ratings averages and cross them with the average of the total of orders for each type of cupcake. In the end, its purpose is to try to balance the information in both axes (x and y) and determine a line that tries, at its best, to approximate to each point of the graph. That’s the magic of the linear regression shown in Figure 7.
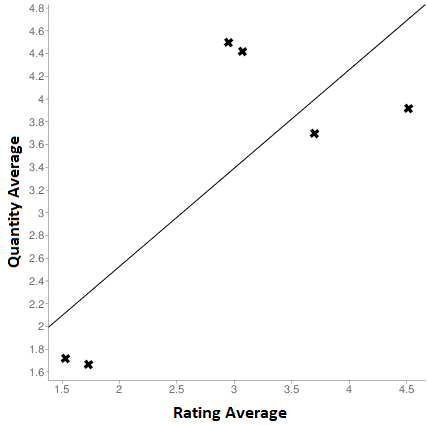
Figure 7: The linear regression
Just like you would have in a CSV file showing real data, the data will increase over time and help the algorithm to be smarter. However, in order to use the power of Accord.NET in the fsx file, you must first import the corresponding libs (dlls) of its main packages. These are going to be the first lines of your fsx file (you can download the completed script here):
|
1 2 3 4 5 |
#r "../packages/FSharp.Data.2.4.6/lib/net45/FSharp.Data.dll" #r "../packages/Accord.3.8.0/lib/net40/Accord.dll" #r "../packages/Accord.Statistics.3.8.0/lib/net40/Accord.Statistics.dll" #r "../packages/Accord.Math.3.8.0/lib/net40/Accord.Math.dll" #r "../packages/Accord.Math.3.8.0/lib/net40/Accord.Math.Core.dll" |
The directive r#, in F#, comes from reference and is used to load external library references that were previously installed in the project. These dlls are:
- FSharp.Data: F# default library to deal with everything related to accessing data in F# applications: from CSV, JSON/XML files to remote data parsing/manipulation;
- Accord: the core of the framework. Stores general exceptions and other libraries extensions;
- Accord.Math: for all basic mathematical operations, that library is needed, once it contains data science principal functions and numerical algorithms;
- Accord.Statistics: it’s the home of the linear regression statistical models and a whole bunch of components and statistical methods/functions like variances, deviations, averages, etc.
To call the classes in the Accord.NET linear regression module in your code without having to use their fully qualified names, you must import it right after the dlls references:
|
1 2 |
open Accord.Statistics.Models.Regression.Linear open FSharp.Data |
In F#, the CSV model can be implemented as follows:
|
1 2 3 4 5 6 7 |
type CupcakeSale = {CupcakeId : int; Type : string; Price : float; CustomerId : int; Rating : float; Total: float} |
A type in F# represents a class in C# or other object-oriented languages. This way, you can define the name and types of your object attributes (which is also a variable).
Once you’re dealing with a large amount of records, you’ll create a resizable list, import the local CSV file, iterate over its content and add its elements to the list just to simulate the data a real application would supply:
|
1 2 3 4 5 6 7 8 9 10 |
let sales = ResizeArray<CupcakeSale>() type CupcakeSalesCSV = CsvProvider<"cupcake_sales.csv", ","> let csv = new CupcakeSalesCSV() for row in csv.Rows do sales.Add({CupcakeId = row.CupcakeId; Type = row.Type; Price = (float) row.Price; CustomerId = row.CustomerId; Rating = (float) row.Rating; Total = (float) row.Total}) |
Further, you can increase the number of inputs in this list to achieve more accuracy with the algorithm result. Or, if you prefer, you can get the data from a data source or even a web service.
The next step is to group the data in a way to have the rating average values (as the x in the formula) vs the average of the total of times each cupcake was ordered (the y, the most important information).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
let filterByRating = [(fun (x : CupcakeSale) -> x.Rating)] let filterByTotal = [(fun (x : CupcakeSale) -> x.Total)] let groupedByRatings = sales |> Seq.groupBy(fun x -> x.CupcakeId) |> Seq.map(fun (key, values) -> (key, [for prop in filterByRating -> values |> Seq.averageBy prop])) |> Seq.toArray let groupedByTotals = sales |> Seq.groupBy(fun x -> x.CupcakeId) |> Seq.map(fun (key, values) -> (key, [for prop in filterByTotal -> values |> Seq.averageBy prop])) |> Seq.toArray |
The variables filterBy-Something are only a condition attached to the grouping + filtering made upon groupedBy-Something variables. The operator |> (pipe-forward) allows you to pass an intermediate/temporary result (on the leftmost side) to the next function (on the closest right side).
The function groupBy gets the given list (sales) and returns a sequence of tuples containing the unique key (the cupcake id) and all the elements that key matches within another sequence. The next function, map, receives these tuples mapped to key/value variables. Then, the lambda expression iterates over the values to apply an averageBy function against the filterBy-(Rating/Total) condition you’ve seen before and finally returns an array containing each tuple of id/(rating and total averages). Check the following REPL result as shown in Figure 8.
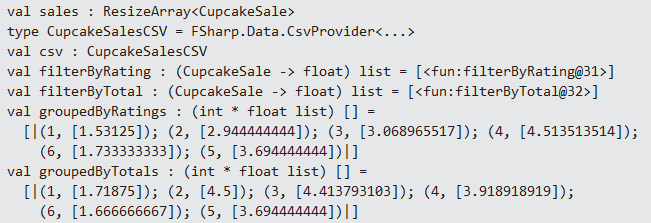
Figure 8: Calculating the averages and totals
Tuples are represented by parentheses and the first element is called key (or left), the second is value (or right).
The linear regression object is created from the x and y values which, in turn, must be represented as arrays with each index of each array corresponding to the respective values and total. Because of that, the code iterates over the array of tuples (of both groupedBySomething variables) to extract this correlated data:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
let cupcakeIds = Array.create groupedByRatings.Length 0 let x_averages = Array.create groupedByRatings.Length 0.0 let y_totals = Array.create groupedByRatings.Length 0.0 for i in 0..groupedByRatings.Length - 1 do let averageTuple = Array.get groupedByRatings i let totalTuple = Array.get groupedByTotals i let _id = fst averageTuple let _average = (snd averageTuple).[0] let _total = (snd totalTuple).[0] Array.set cupcakeIds i _id Array.set x_averages i _average Array.set y_totals i _total |
Array.create is a function that creates a new array with the given length and fills it with the given values. The reserved words fst and snd are used to access the first and second values of a tuple in F#, respectively.
Finally, you can review the linear regression code:
|
1 2 3 4 5 6 7 8 9 |
let ols = OrdinaryLeastSquares() let regression = ols.Learn(x_averages, y_totals) // Let's say you received this value from the web form let purchasedCupcakeId = 1; // A shortcut to find the corresponding sale of the provided cupcake id let findIndex arr elem = arr |> Array.findIndex((=) elem) let i = findIndex cupcakeIds purchasedCupcakeId let result = regression.Transform(Array.get x_averages i) System.Console.WriteLine("Suggested quantity: {0}", System.Math.Round(result)) |
OrdinaryLeastSquares (OLS) is the standard linear regression approach used by the Accord.NET library. It is based on the famous least-squares procedure that, in turn, models a single and continuous variable response (y) predicted by another variable recorded on an interval (x) through a linear relationship. In other words, OLS is the most basic and common mathematical representation of the linear regression formula: y = f(x) + e. Its function called Learn is responsible for receiving the x/y arrays and so learn by them (more and more every time you increase the arrays) resulting in the regression itself. Once you have seen the model digested by the regression function, all you need to do is to provide a cupcake rating average of a specific cupcake type and the suggested value will be generated as result in the beginning of the F# Interactive output shown in Figure 9. Note that the value was rounded since the user won’t be able to buy a fraction of a cupcake :
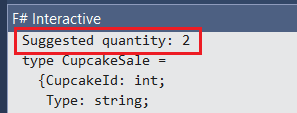
Figure 9: The suggested quantity
Now, try it yourself. Feed your algorithm by increasing the number of cupcake sales to the list and analyzing how the linear regression calculates the best fit for (low) user reviews versus the total of number of orders.
Conclusion
Using .NET libraries to accomplish machine learning algorithms not only makes it possible to use the power of data science to help predict different sort of things, but also allows you to integrate code easily in all .NET projects/technologies. Of course, it goes further: It provides fast ways to export code to dll’s that can be imported into other languages that know how to translate one type of object into another.
The code in this article is, perhaps, the simplest type of linear regression that can be built with machine learning. Fortunately, its official website is full of awesome content, more complex examples of regression, classification, tests of hypotheses and even image/audio manipulation. With regard to F#, both the official project and the .NET support documentation pages are well documented in a way that is extremely easy to understand. All of that is available to help you to take bigger steps as you learn.
Load comments