
Deep Learning is the most sought-after field of machine learning today due to its ability to produce amazing, jaw-dropping results. However, it was not always the case, and there was a time around 10 years back when deep learning was not a field considered by many to be practical. The long history of deep learning shows that researchers proposed many theories and architectures between the 1950s to 2000s. However, training large neural networks used to take a ridiculous amount of time due to the limited hardware support of those times. Thus, neural networks were deemed highly impractical by the machine learning community.
Although some dedicated researchers continued with their work on neural networks, the significant success came in the late 2000s when researchers started experimenting with training neural networks on GPUs (Graphics Processing Unit) to speed up the process, thus making it somewhat practical. It was, however, the 2012 Imagenet challenge winner Alexnet model which was, trained parallelly, on GPUs, that inspired the use of GPUs to the broader community and catapulted deep learning into the revolution seen today.
What is so special about GPUs that they can accelerate neural network training? And can any GPU be used for deep learning? This article explores the answers to these questions in more detail.
CPU vs GPU Architecture
Traditionally, the CPU (Central Processing Unit) has been the leading powerhouse of computers responsible for all computations taking place behind the scenes on the computer. The GPU is special hardware that was created for the computer graphics industry to boost the computing-intensive graphics rendering process. It was pioneered by NVIDIA who launched the first GPU Geoforce 256 in 1999.
Architecturally, the main difference between the CPU and GPU is that a CPU generally has limited cores for carrying out arithmetic operations. In contrast, a GPU can have hundreds and thousands of cores. For example, a standard high performing CPU generally has 8-16 cores whereas NVIDIA GPU GeForce GTX TITAN Z has 5760 cores! Compared to CPUs, the GPU also has a high memory bandwidth which allows it to move massive data between the memory. The figure below shows the basic architecture of the two processing units.
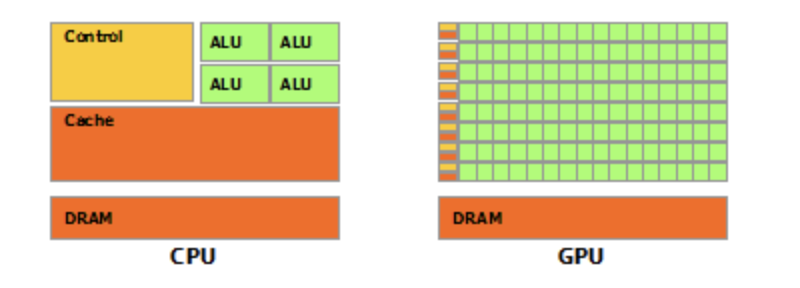
CPU vs GPU Architecture
Why is the GPU good for Deep Learning?
Since the GPU has a significantly high number of cores and a large memory bandwidth, it can be used to perform high-speed parallel processing on any task that can be broken down for parallel computing. In fact, GPUs are incredibly ideal for embarrassingly parallel tasks that require no effort to break them down for parallel computation.
It so happens that the mathematical matrice operations of the neural network also fall into the embarrassingly parallel category. This means GPU can effortlessly break down the matrice operation of an extensive neural network, load a huge chunk of matrice data into memory due to the high memory bandwidth, and do fast parallel processing with its thousands of cores.
A researcher did a benchmark experiment by running the CNN benchmark on the MNIST dataset on GPU and various CPUs on the Google Cloud Platform. The results clearly show that CPUs are struggling with training time, whereas the GPU is blazingly fast.
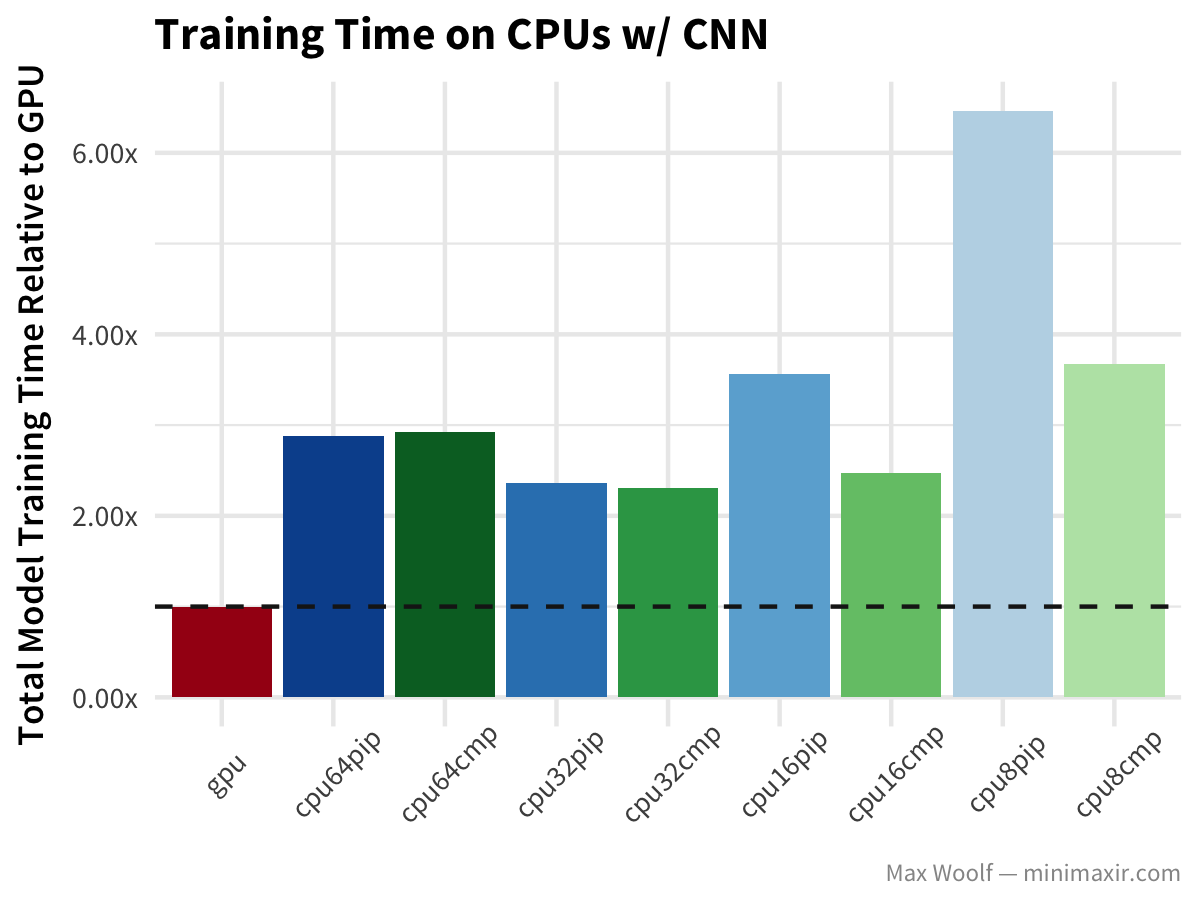
GPU vs CPU performance benchmark (Source)
NVIDIA CUDA and CuDNN for Deep Learning
Currently, Deep Learning models can be accelerated only on NVIDIA GPUs, and this is possible with its API called CUDA for doing general-purpose GPU programming (GPGPU). CUDA which stands for Compute Unified Device Architecture, was initially released in 2007, and the Deep Learning community soon picked it up. Seeing the growing popularity of their GPUs with Deep Learning, NVIDIA released CuDNN in 2014, which was a wrapper library built on CUDA for Deep Learning functions like backpropagation, convolution, pooling, etc. This made life easier for people leveraging the GPU for Deep Learning without going through the low-level complexities of CUDA.
Soon all the popular Deep Learning libraries like PyTorch, Tensorflow, Matlab, and MXNet started incorporating CuDNN directly in their framework to give a seamless experience to its users. Hence using a GPU for deep learning has become very simple compared to earlier days.

Deep Learning Libraries supporting CUDA (Source)
NVIDIA Tensor Core
By releasing CuDNN, NVIDIA positioned itself as an innovator in the Deep Learning revolution, but that was not all. In 2017, NVIDIA launched a GPU called Tesla V100, which had a new type of Voltas architecture built with dedicated Tensor Core to carry out tensor operations of the neural network. NVIDIA claimed that it was 12 times faster than its traditional GPUs built on CUDA core.
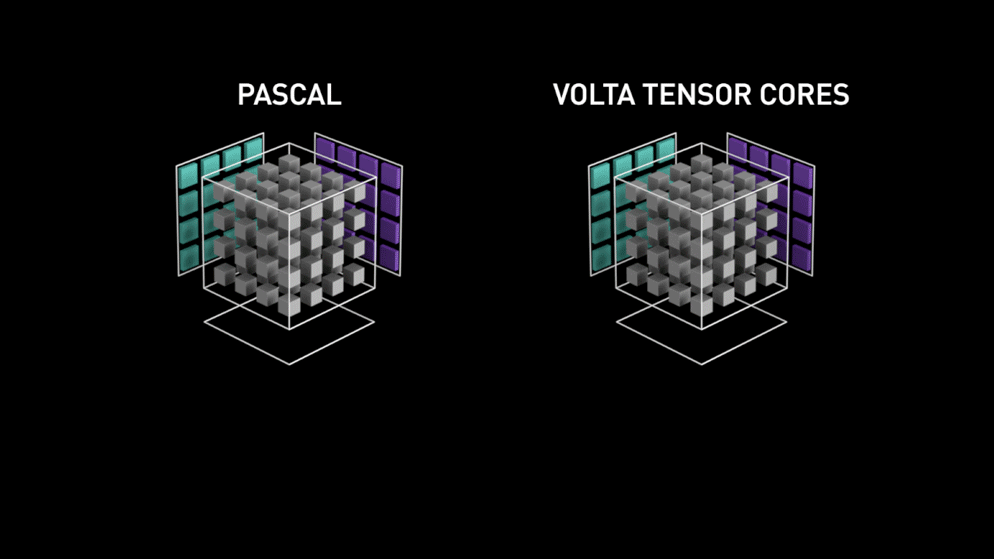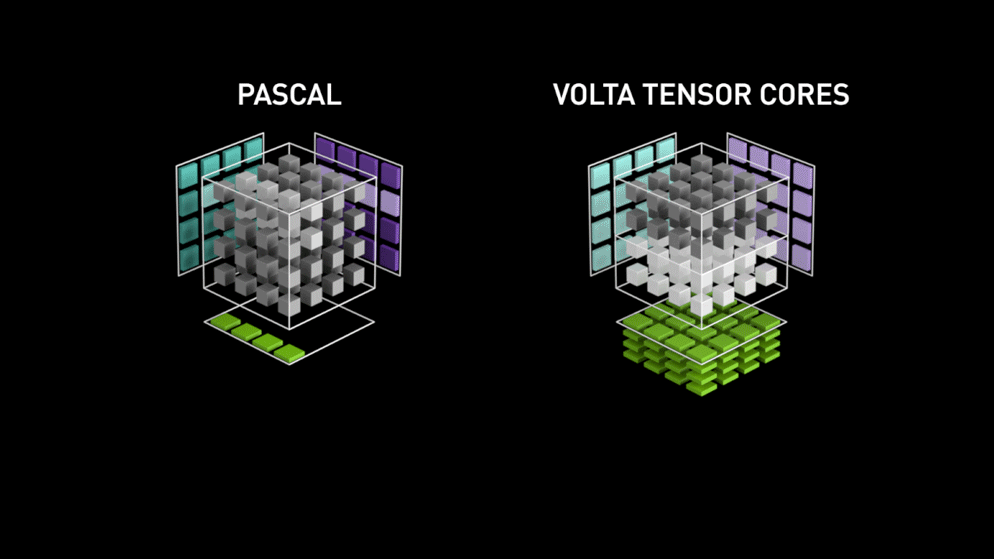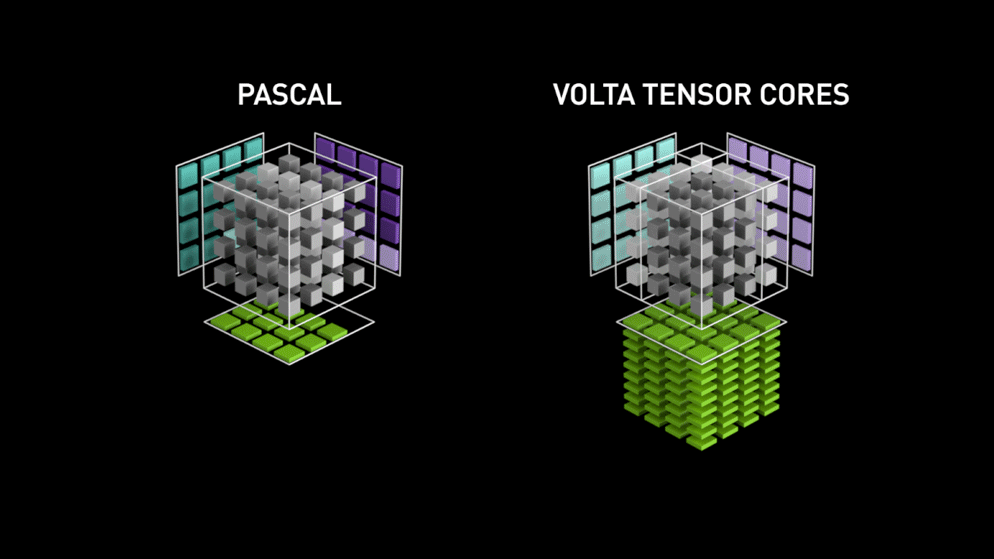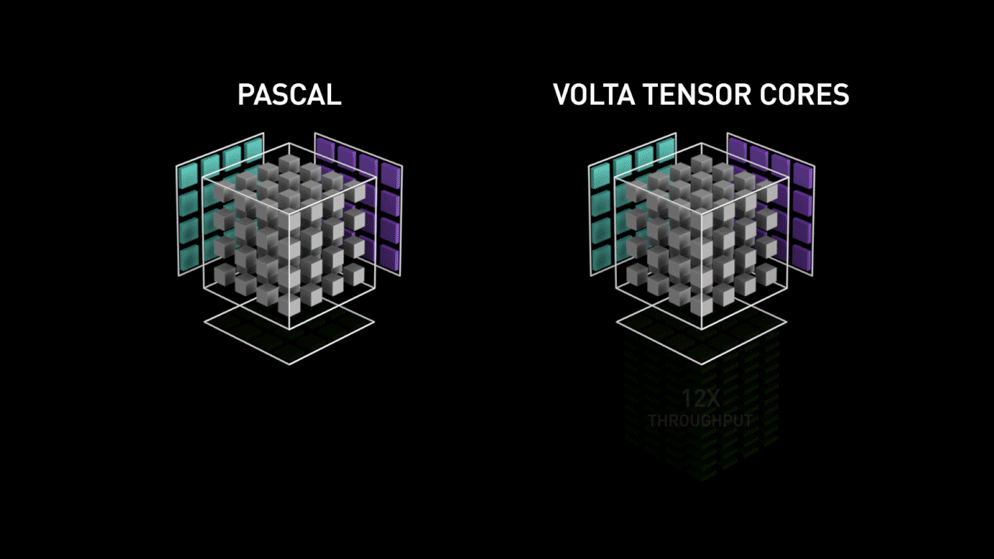
Voltas Tensor Core Performance (Source)
This performance gain was possible because its Tensor Core was optimized to carry out a specific matrice operation of multiplying two 4×4 FP16 matrices and add another 4×4 FP16 or FP32 matrices. Such operations are quite common in neural networks; hence an optimized Tensor Core for this operation could boost the performance significantly.
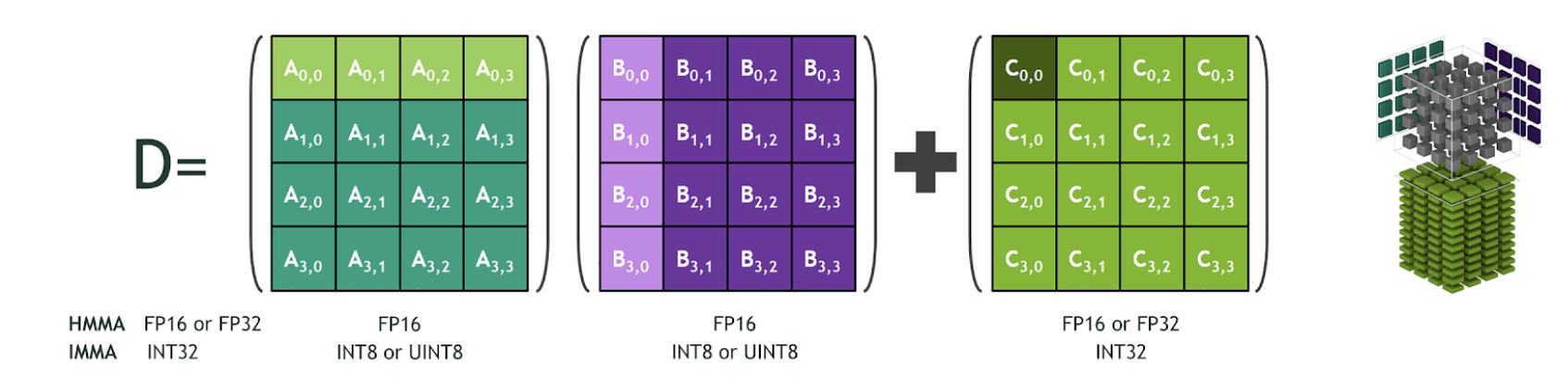
Matrice Operation supported by Tensor Core (Source)
NVIDIA added support for FP32, INT4, and INT8 precision in the 2nd generation Turing Tensor Core architecture. Recently, NVIDIA released the 3rd generation A100 Tensor Core GPU based on Ampere architecture with support for FP64 and a new precision Tensor Float 32 which is similar to FP32 and can deliver 20 times more speed without code change.
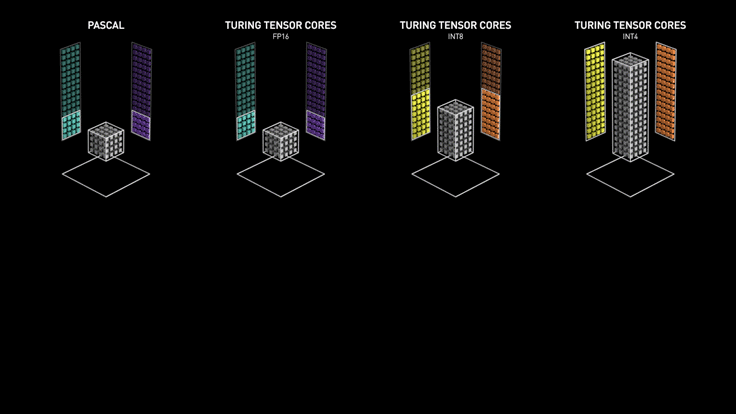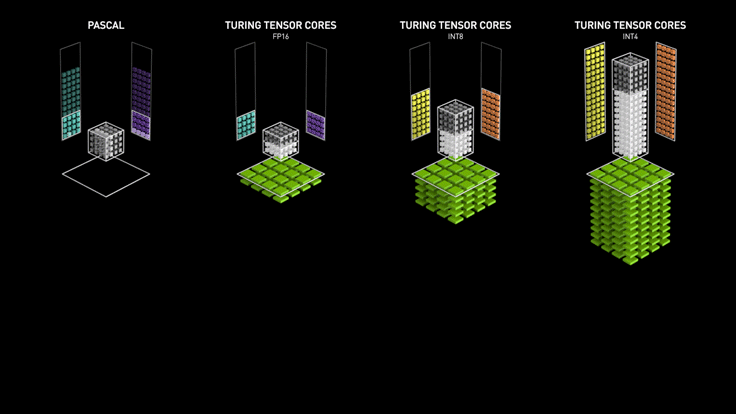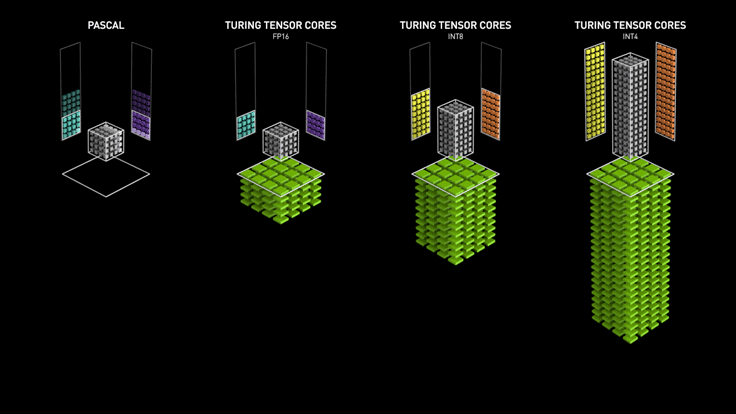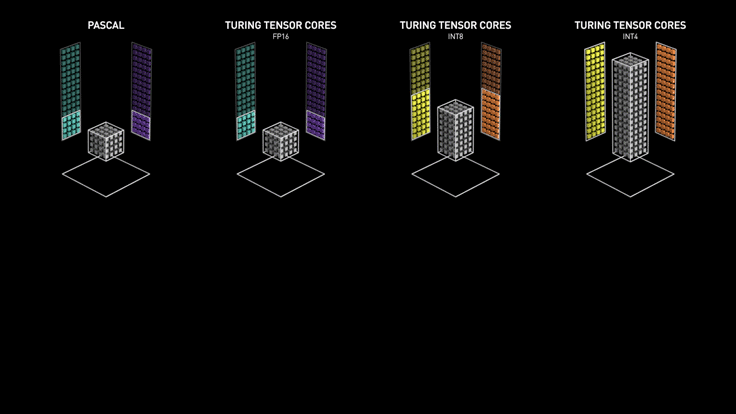
Turing Tensor Core Performance (Source)
Hands-on with CUDA and PyTorch
Now take a look at how to use CUDA from PyTorch. This example carries out multiple operations both on CPU and GPU and compares the speed. (code source)
First, import the required numpy and PyTorch libraries.

Now multiply the two 10000 x 10000 matrices with CPU using numpy. It took 1min 48s.

Next, carry out the same operation using torch on CPU, and this time it took only 26.5 seconds

Finally, carry this operation using torch on CUDA, and it amazingly takes just 10.6 seconds
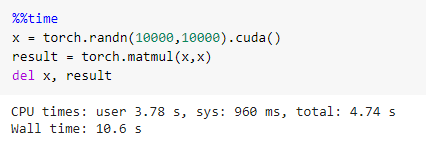
To summarize, the GPU was around 2.5 times faster than the CPU with PyTorch.
Points to consider for GPU Purchase
NVIDIA GPUs have undoubtedly helped to spearhead the revolution of Deep Learning, but they are quite costly, and a regular hobbyist might not find it very pocket friendly. It is essential to purchase the right GPU as per your needs and not go for high-end GPUs unless really required.
If your needs are to train state of the art models for regular use or research, you can go for high-end GPUs like RTX 8000, RTX 6000, Titan RTX. In fact, some of the projects may also require you to set up a cluster of GPUs which will require a fair amount of funds.
If you intend to use GPUs for competitions or hobbies and have the money, you can purchase medium to low-end GPUs like RTX 2080, RTX 2070, RTX 2060 GTX 1080. You also have to consider the RAM required for your work since the GPUs come with different RAM sizes and are priced accordingly.
If you don’t have the money and would still like to experience GPU, your best option is to use a Google Colab that gives free but limited GPU support to its users.
Conclusion
I hope this article gave you a very useful introduction into how GPUs have revolutionized Deep Learning. The article made an architectural and practical comparison between CPU and GPU performance and also discussed various aspects that you should consider while choosing GPU for your project.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments