
When a database table becomes unmanageably large, it is time to break it up using horizontal or vertical partitioning. After horizontal partitioning, you will have several tables that have the same columns, but contain distinct sets of rows. When you union these tables together, you will get back the original data. SQL Server 2005 has built-in support for this. Vertical table partitioning, also known as table splitting, involves replacing your large table with two tables, but these two tables will not have the same columns. Unfortunately, in contrast to horizontal partitioning, it is very tedious to set up.
But there is help available. The most powerful, most complex and probably the least frequently used refactoring tool in SQL Refactor is ‘Split Table’. This article describes what this ‘Split Table’ tool can be used for, and how to use it.
Vertical Partitioning
Vertical partitioning, or table splitting, is generally used when your database design requires you to split a table into two tables, and store some of the old table columns in only one of these new tables. Among the reasons for splitting the table this way are:
- The table rows are very large, and performance could be improved if large but rarely used fields are moved to a separate table. If this is done, the frequently used data is stored in a much smaller table, and the rarely used data is looked up when required. The performance hit caused by occasionally looking up a second table is well compensated by having the frequently used data in a smaller table, possibly on a single physical disk.
- The database design is changing, and an entity is separated into two with a 1:N or M:1 relationship. For example, it is fine to store address information for a person together with the name of the person in a single table, if a person has only a single address. However, with time this may change, and a new requirement may state that a person can have several addresses. Our current table needs to be broken up into two tables, one for the name information, and one for the address information.
- Domain restriction needs to be added retrospectively. For example, in an addresses table that has the names of the American states we would like to create a table that contains all of the states, and via referential integrity (foreign keys) ensure that no other state name can be used. This is not strictly part of vertical partitioning, but lookup tables to enforce domain restrictions form a very similar demand for setting up a second table.
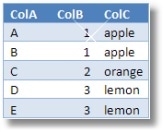
In order to visualize how vertical partitioning works, let’s consider the following abstract example. We have a table with three columns: ColA, ColB and ColC.
In this particular table there seems to be a functional dependency; the value of ColB determines the value of ColC. Assuming that this will hold for all the future data it would be preferable to split this table into:
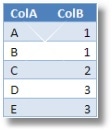 and
and 
When these two tables are joined together they will result in the original table.
Deciding on the table structure is a design time decision. However, as requirements change, the database schema may need to be altered after the database has been deployed and populated with production data. Introducing vertical partitioning at this stage requires a lot of work. The main steps include the following:
- Create the new table (secondary table)
- Create a primary key on this new table (this can be determined automatically based on the shared fields)
- Copy or move the indexes, and split indexes if they refer to shared columns
- Move and duplicate table and column level extended properties and permissions
- Populate the secondary table with unique data
- Handle table level check constraints
- Delete the relevant columns from the original table
- Rewrite all the referencing stored procedures, functions and views to use either a join that uses both of the new tables or only one of these tables if only columns from one of the tables are referenced. These updates need to be performed in the correct dependency order.
- Rewrite triggers
This is a rather tedious process, and this is where SQL Refactor could help. SQL Refactor is an add-in to Microsoft’s Management Studio. It contains over a dozen refactorings like formatting code, renaming objects, and not last, splitting tables or vertical partitioning. The ‘Split Table’ refactoring generates a script that does the above steps (and more).
Example: Functional Dependency in an Existing Table
To see how ‘Split Table’ works, let us consider an example table that stores information for a computer support company. This table is called ServiceCases. It stores the history of services provided to customers. This includes the date when the customer reported the problem, the resolution to the problem, the default charge and the actual charge for the service. In this company all the resolutions are categorised, and have a standard code assigned to them.
The table looks like:
( CaseID INT IDENTITY(1, 1)
NOT NULL
CONSTRAINT PK_ServiceCases PRIMARY KEY CLUSTERED
, CustomerID INT
CONSTRAINT FK_Incidents_Customers
REFERENCES dbo.Customers ( CustomerID )
, IncidentDate DATETIME NOT NULL
, ResolutionDate DATETIME NULL
, ServiceCode CHAR(3) NOT NULL
, ServiceDescription NVARCHAR(200) NOT NULL
, DefaultCharge MONEY NOT NULL
, ActualCharge MONEY NULL
)
For every service code there is a service description column available, in the practice however, the support engineers just used the explanation for the service code from their manuals. This has become company practice. This company practice introduced a non-trivial functional dependency, as the ServiceCode column now determines the value of the ServiceDescription column. The ServiceCode is not part of the primary key for the ServiceClasses table, so this table no longer satisfies the third normal form. Data is stored in a redundant way. Also, at this company, it has been realised that the default charge for the various services has never changed, and due to the relative short lifetime of a service, it never will change. This also introduces a new unwanted functional dependency. We could solve this issue by splitting the table into two, one for the service cases, and the second for storing the information about individual services, their descriptions and the amount of the default charge for this service.
To see how SQL Refactor works, let us also set up a very simple view on this table:
AS SELECT *
FROM dbo.ServiceCases
Note that this is not production quality code. Using select * is against best practices, but I used select * to illustrate how SQL Refactor handles such views.
Let us split this table with SQL Refactor. A wizard walks us through the following steps:
In the first step we need to provide the name of the secondary table. The original table will remain having the same name; only some of its columns will be moved to the secondary table.
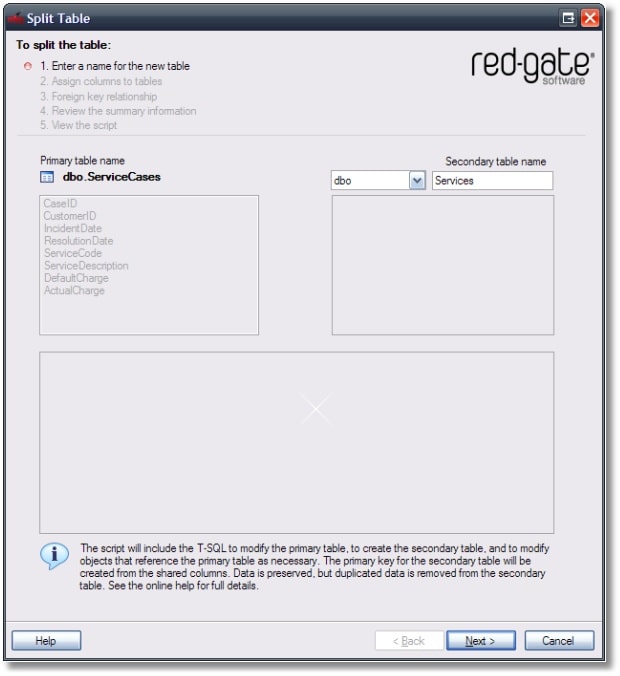
Having chosen the name Service for the secondary table, we need to specify the columns that will be part of the two new tables.
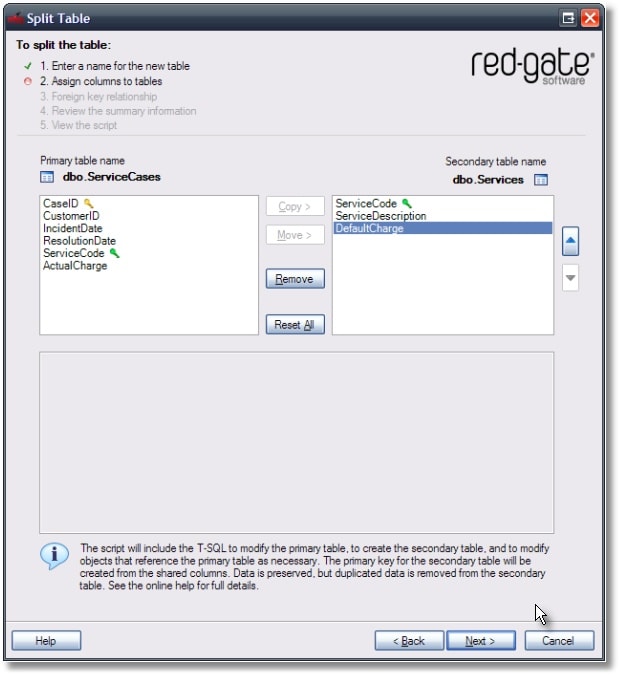
The ServiceCode column will be shared, since we want to keep the service information in the Services table, and be able to find the service details for a service code in the ServiceCases table. The ServiceDescription and DefaultCharge columns therefore needs to be only in the Services table, and can be looked up in queries based on the service code.
Note that SQL Refactor automatically chooses the ServiceCode column to be the primary key in the secondary table. It determines this based on the fact that this column is shared by both of the tables. The green key icon next to the ServiceCode column in the secondary table indicates that this column will be selected as the primary key. In the primary table this column is also marked with the same icon, in order to show that this column is the link between the two tables.
In the next step SQL Refactor asks about the relationship between the two tables. Based on the location of the primary key of the original table SQL Refactor can decide what possibilities for relationships there are. In our case it determines that this table split is for 1:1 and M:1 relations only, and sets up the foreign key on the primary table.
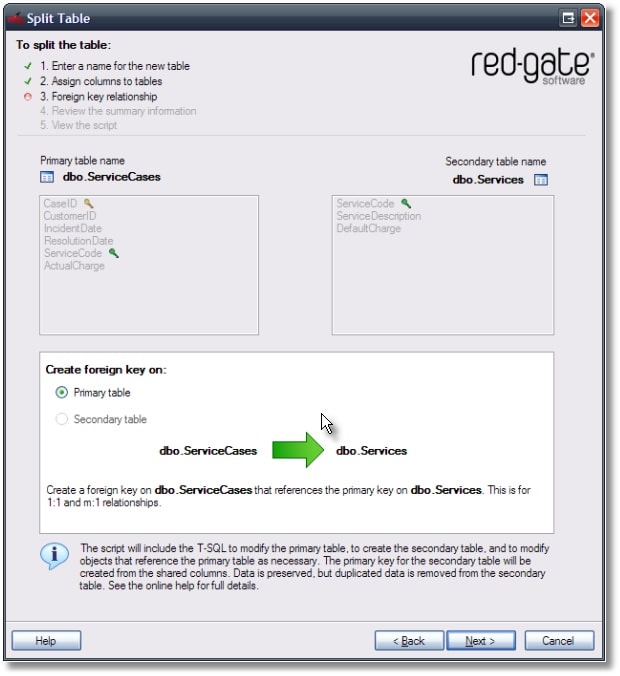
The next step shows an overview of what the generated script will do. This page also includes warnings if there are any.
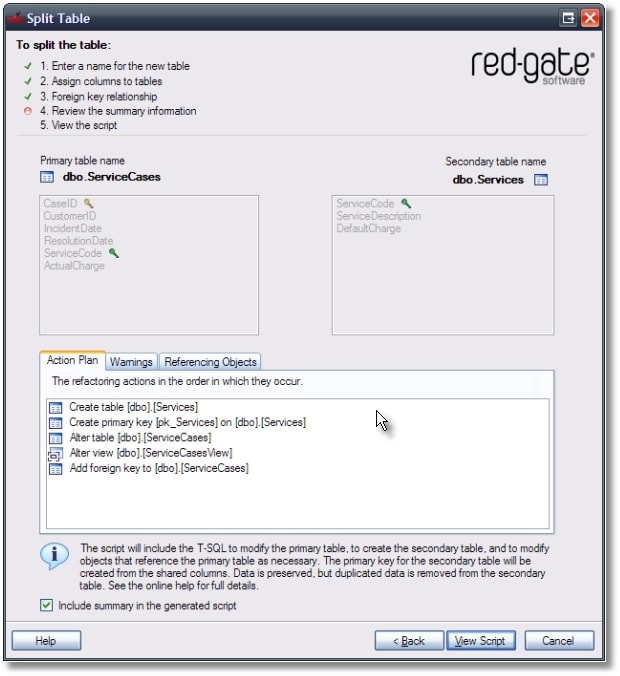
Note that it has identified the dependent view, and will modify it as needed.
The generated script will create the new table like:
( [ServiceCode] [char](3) COLLATE SQL_Latin1_General_CP1_CI_AS
NOT NULL
, [ServiceDescription] [nvarchar](200) COLLATE SQL_Latin1_General_CP1_CI_AS
NOT NULL
, [DefaultCharge] [money] NOT NULL
)
ON [PRIMARY]
GO
ALTER TABLE [dbo].[Services]
ADD CONSTRAINT [pk_Services] PRIMARY KEY CLUSTERED ( [ServiceCode] )
ON [PRIMARY]
GO
It populates it with distinct data like:
( [ServiceCode]
, [ServiceDescription]
, [DefaultCharge]
)
SELECT DISTINCT
[ServiceCode]
, [ServiceDescription]
, [DefaultCharge]
FROM [dbo].[ServiceCases] GO
It will also create the foreign key on the original table like:
ADD CONSTRAINT [fk_ServiceCases_Services] FOREIGN KEY ( [ServiceCode] )
REFERENCES [dbo].[Services] ( [ServiceCode] )
GO
Also, the dependent view is rewritten as
AS SELECT ServiceCases.CaseID
, ServiceCases.CustomerID
, ServiceCases.IncidentDate
, ServiceCases.ResolutionDate
, ServiceCases.ServiceCode
, Services.ServiceDescription
, Services.DefaultCharge
, ServiceCases.ActualCharge
FROM ( dbo.ServiceCases
INNER JOIN dbo.Services ON ServiceCases.servicecode = Services.servicecode
)
GO
Note that the select * has been expanded, and the reference to the ServiceCases table has been replaced with a join statement.
This is an oversimplified example, but there are many other things that are considered by SQL Refactor, such as extended properties, permissions, table partitioning, filegroups, schemabound objects that are referencing the table or any of its dependents, etc.
Example: 1:N Relationships
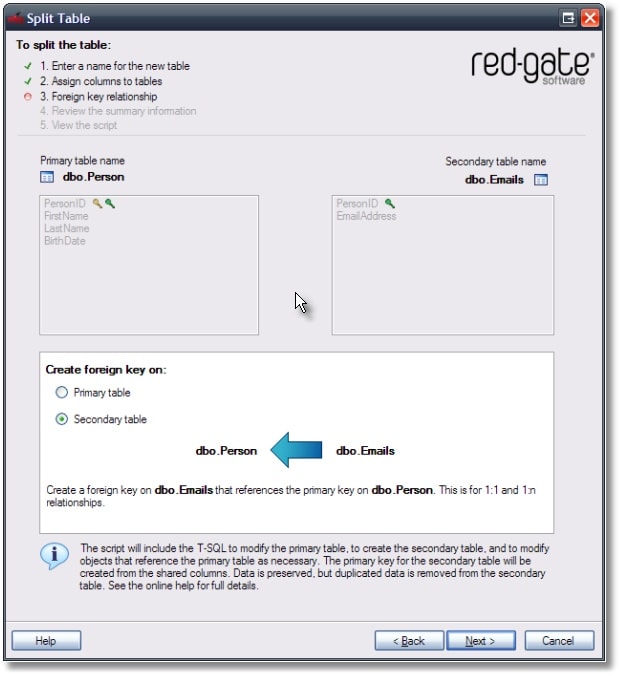
The previous example has shown a M:1 relationship; a post code may be used in many addresses. I will next show an example for a 1:N relationship:
( PersonID INT NOT NULL
IDENTITY(1, 1)
CONSTRAINT [PK_PersonID] PRIMARY KEY CLUSTERED
, FirstName NVARCHAR(50) NOT NULL
, LastName NVARCHAR(50) NOT NULL
, EmailAddress NVARCHAR(50) NOT NULL
, BirthDate datetime NOT NULL,
)
This table represents basic information about a person, and assumes that a person has a single email address. However, if a person may have more than one email address, the table will need to be split into two. The secondary table, let’s call it Emails, will obviously include the email address column. It will also reference the PersonID column, if we assume that an email address is not reused by others, and a person may have several email addresses. SQL Refactor, based on the columns that are selected to be split will determine this automatically, and allow both 1:N, M:1 and 1:1 relationships to be set up:
Example: If There Are No Shared Columns
In the previous examples the table had at least one column that could be used as the shared column. This column or columns are required for vertical partitioning, since they are the basis for the link between the two tables. Sometimes such columns are not available. An example for such a situation is in the following table:
( Person2ID INT NOT NULL
IDENTITY(1, 1)
CONSTRAINT [PK_Person2] PRIMARY KEY CLUSTERED
, FirstName NVARCHAR(50) NOT NULL
, LastName NVARCHAR(50) NOT NULL
, HouseNameOrNr NVARCHAR(30) NOT NULL
, Line1 NVARCHAR(50) NOT NULL
, Line2 NVARCHAR(50) NOT NULL
, City NVARCHAR(50) NOT NULL
, PostCodePart1 CHAR(4) NOT NULL
, PostCodePart2 CHAR(3) NOT NULL
, BirthDate datetime NOT NULL,
)
We would like to create an Addresses table that would contain an address id, and the address. First of all, this would allow more than a single address per person to be stored.: Second, the table for the person will have shorter rows and, if the address is rarely looked up, the query will have a better performance. But there is no address id column.
In the UK, a post code together with either a house number or a house name uniquely identifies a house. However, postcodes do change sometimes, so we may decide that we need a new surrogate primary key column for the addresses table. We would need to add this manually to the persons table, and then perform a table split. This is not a trivial task, as we would like every unique address to get the same value in the new column. The easiest way to do this is by using a temporary table under SQL Server 2005. SQL Server 2005 has a ROW_NUMBER () function that can be used to create the temporary table with unique addresses. This ROW_NUMBER column then can be used to set the value of a newly shared column in the Person2 table. Once the shared column is ready, SQL Refactor can once again generate a script to split the two tables.
Limitations
Among the most timesaving tasks that SQL Refactor’s ‘Split Table’ refactoring will do is to rewrite dependent objects. First of all it will identify these dependent objects. This, alone, is a great help but suffers the limitation that it can only identify the dependent objects within the same database. If you use cross-database queries, the external databases will need to be modified manually. Also, tables may be referenced by external applications directly, and not only via views and stored procedures. These applications need to be modified as well. The same applies to dynamic SQL.
Some types of SQL statement, such as an INSERT or UPDATE statement referring to both of the new tables, cannot be rewritten automatically. These too will need the attention of the database developer.
Triggers can cause a problem. SQL Refactor tries to guess the impact of the trigger, i.e. it will check the columns the trigger is using, and move the trigger if necessary. However, imagine an instead of trigger on the original table, a trigger that uses columns that would be not shared by the two new tables and would be from both of the tables. Most of the time such triggers cannot be rewritten automatically.
SQL Refactor however does a very good job at doing the initial work for vertical partitioning, and produces a script that can be used to fine tune the table split. SQL Refactor does this in seconds, as opposed to weeks. This large amount of time this refactoring can save, despite the relatively low frequency it would be used, allowed it to be part of SQL Refactor.
Summary
Vertical table partitioning is not the simplest of the database tasks. It is time consuming, and requires careful thought about how dependent applications and database objects will be affected. SQL Refactor can save a lot of time by generating a script that can perform the table split. This script can be used to partition the database in the majority of the cases, but can also be used as a starting point for vertical partitioning of complex databases.
Load comments