
Although it isn’t yet released, we’ve made no secret about Redgate’s SQL Clone. This is a rather radical new database tool that allows you to take a ‘data image’ of a database, and then rapidly create as many clones of this database as you need. These cloned databases take only a few seconds to create and occupy only about 50Mb each, but have the same schema and data as the original. You can create 10 200GB databases in 60 seconds. I’m a database developer by background, but I’m at Redgate now, managing SQL Clone’s progress as a product through to release.
Copying a database is easy: you just restore a backup onto a different database, maybe on a different server. The chore of copying several databases routinely can quickly descend into a nightmare of wasted time and disk space. SQL Clone was originally envisaged as a way of automating the task of provisioning several test or development servers as part of the delivery pipeline, or to ensure that all developers have a dedicated version of the current database build without cluttering up the disk-space on their own PCs.
When we gave technical previews of SQL Clone to our friends in technical teams working on SQL Server databases, we were amazed by the rich variety of other uses they managed to find for which the tool could be applied, and the real-world problems that could be solved. It seems to be the sort of tool that enables the ideas you already have, but couldn’t previously implement. Many of us working in technology like to play with cool tools, but when it takes your teamwork to the next level as well, that’s a different matter altogether.
In this article, I’m going to show a simple way of using the technical preview of SQL Clone to provision some dedicated databases for your development team to allow them to work with the full version of the current database without requiring a large disk-footprint on their workstations.
Making dedicated database development easy
If you’ve ever worked in a team with a shared database in your development environment, or for that matter delivery environments like UAT, Pre-Production and so on, I expect you’ll already know how time-consuming, awkward, and downright frustrating it can be to provision copies of production databases for development work. (Either that or you’re one heck of a team!).
The pains are all too familiar. Disk space juggling. Ad hoc requests. Developers stuck waiting for backups to restore to a shared copy, then getting in each other’s way when making changes, and requesting new restores so they can revert to the baseline. (Some become so frustrated at having to work with databases, they try to remove them altogether!)
It is important to be able to automate this process until it becomes a simple routine that allows you to be confident that you can, for example, debug a issue caused by an unexpected edge data problem reported only in production
SQL Clone allows database development work to be more like regular software development, where individuals are free to make mistakes, try things out (or hit it until it works), while still benefiting from a realistic server environment and data set.
How it works
SQL Clone uses the Virtual Disk Service in x64 Windows to allow the same bytes (a ‘Snapshot’) to be reused many times – and on multiple SQL Server instances – as ‘Clone’ databases. The changes made on each clone are stored in a differencing disk on that machine, so the Snapshot is immutable, and the provisioning time is only the seconds it takes to set up the .vhd and mount the database, and requires only 40Mb or so of disk space on the instance initially. There are more details in the SQL Clone documentation.
Worked example of database provisioning: The Test Drive
Let’s see how SQL Clone helps in practice. In my example I’ll be using Brent Ozar’s very useful copy of the StackOverflow database, which weighs in at 95Gb; not huge, but big enough to be a pain to copy around. It doesn’t matter what database you use within reason (the reason being that there’s a 2TB limit at present, and Filestream files aren’t currently supported).
In my environment, I’ve installed SQL Clone on several machines as below
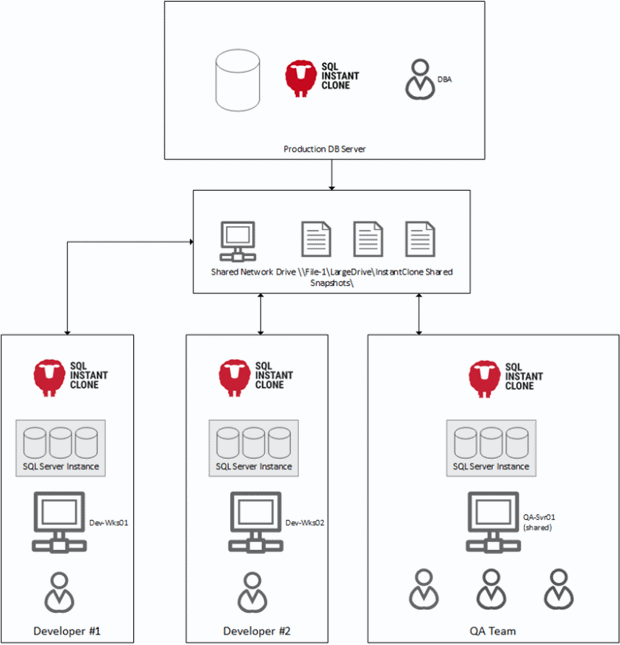
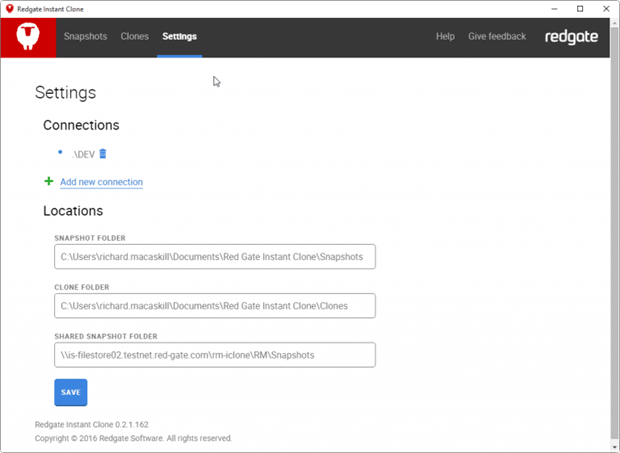
I’ve then configured each instance to use the same Shared Snapshot Folder.
My ‘scenario’ imagines that a DBA is creating a SQL Clone ‘Snapshot’ from the StackOverflow database on Production. This can be done with a click in the SQL Clone user interface, or PowerShell as below using the PowerShell InstantClone module;
|
1 2 3 4 5 6 7 8 9 10 |
# Output my options - in case needed for debugging Show-InstantCloneOptions -Verbose $SourceDatabase = 'StackOverflow' $SnapshotName = 'StackOverflow-Snapshot-20160620' # set a timer $elapsed = [System.Diagnostics.Stopwatch]::StartNew() Write-host "Started at $(get-date) " Save-InstantCloneSnapshot -DatabaseName $SourceDatabase -SnapshotName $SnapshotName -PutInSharedFolder -Verbose Write-Host 'Snapshot created as shared.' Write-host "Elapsed Time: $($elapsed.Elapsed.ToString()) " |
In the technology preview release of SQL Clone, we need to install on all the workstations, but once it’s there, I can use Powershell remoting to ‘push’ clones onto the local instances used by the developers, or they can self-serve by ‘pulling’. If you haven’t enabled remoting on the target machines, you may need to run ‘winrm quickconfig’ as an administrator first.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
$TargetWorkstations = @("Dev-wks01", "Dev-wks02", "QA-Svr01"); $Command = { $SnapshotName = "StackOverflow-Snapshot-20160620" $CloneName = "_StackOverflow_Clone_Hotfix_5082" New-InstantCloneClone -SnapshotName $SnapshotName -NewDatabaseName $CloneName -Verbose } ForEach ($Workstation in $TargetWorkstations) { Try { Invoke-Command -ComputerName $Workstation -ScriptBlock $Command } Catch { "Failed to execute on {0} " -f $Workstation } } |
If you ask the developers to refresh their Databases node in SSMS or SQL Server Object Explorer in Visual Studio, then they’ll see their new databases. They can experiment in isolation while re-using the same bytes on the file share. If they want to revert to the baseline, they can do so in a few seconds without affecting their peers.
SQL Clone is an enabler for many other use cases because it is designed to be used just as easily in PowerShell, as a command-line tool or as a point-and-click application. – I’ll be following up to show how those work in future posts in this series.
A few questions (and sightly fewer answers)
What about the masking? How would I swap out permissions?
Most people want, or need, to change the database in some way. At the moment you’d have to handle that yourself (you could use SQL Data Generator), but later on we’ll be building that facility into the provisioning solution. You can do anything using T-SQL that is possible in Invoke-SQLCMD (such as config in data tables, or swapping out login-to-role mapping per environment) to change the clones after they are mounted in the second script above.
When will SQL Clone be released?
We’re working for an H2 2016 release
How much will it be?
Pricing will be determined closer to release date, in the meantime you can use the technical preview for free (and hopefully let us know what you need to see).
What’s next for SQL Clone?
There is a roadmap on our Product Page.
What’s the catch?
It takes about the same time and diskspace to create the immutable snapshot as it does to take a backup. There is some latency when accessing data on a file share instead of locally. That’s about it, we think.
What’s with the sheep?
The sheep symbol is our tribute to Dolly the Sheep – the first cloned mammal, and a great British technology story.
Where can I get the preview?
Sign up on the Product Page.
Summary
SQL Clone allows you to create copies of either databases or backups. Once you have taken your ‘snapshot’, you can instantly clone copies that take up a small amount of disk space, and share snapshots with your team across your LAN. You can even create new snapshots from your clones to save and share any changes you make to them.
SQL Clone its intended to help to automate your provisioning jobs using PowerShell or from the command line so as to fit in with, and extend, any current system you’re using. Soon, you will be able to schedule when to refresh your clones with up-to-date data
We’ve been listening to all your suggestions about SQL Clone. We reckon that when we are ready to release the tool, you will be able to manage your clones from a single, central UI, It will also be possible to set user permissions and access-control appropriately, Mask sensitive fields with generated, realistic data and subset your clones to save even more diskspace, while maintaining data fidelity
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments