

DevOps, Continuous Delivery & Database Lifecycle Management
Version Control
How should we do change-control when developing database applications? In order to prevent chaos, I believe that we need to follow these general requirements:
- The database must be versioned, so that it is easier to tell which changes have been applied, and when they were applied.
- All database changes must be checked into source-control.
- Every database developer should work on their own version of the database.
- It should be possible to tie database changes to the code changes that they affect, ideally checked into source-control as a part of the same changeset transaction.
- The database changes should be built along with the code changes.
- The database changes should be deployed along with the code changes.
- The continuous-integration server must be able to build and update its own copy of the database, so that it can run automated tests of code and scripts that are checked in at the same time.
You should be able to keep scripts local, with big fat lines between your environments, and handle promotion of database scripts even more thoroughly than your application code. Ensure that you can recreate any database anywhere, anytime. Clearly define your ground rules for how developers are going to merge your changes together. Lean heavily on your build server to enforce as much of this as possible, because a process that is enforced manually is a process that will never be followed.
In this article, I’ll be describing the problems that happen when these guidelines aren’t followed.
The Problem
I’m a pathological job-hopper who is sick of seeing one company after another wasting hidden hours and days on insufficient database change control strategies.
“So how does your company handle database changes?”
I’ve asked this of potential employers many times, and I usually just get blank stares, or a vague answer along the line of “uh… with scripts?” Sometimes, if they are honest, they just reply “poorly.” There’s not even an explicit Joel Test for it. Considering how bad the situation is at most companies, the real test is not whether their database change management is any good, but just whether they are willing to recognize how problematic it really is.
Given how much thought and effort goes into source-code control and change-management at many of these same companies, it is odd that so much less progress has been made on the database change management front. Many developers can give you a 15 minute explanation of their source-code strategy, why they are doing certain things and referencing books and blog posts to support their approach, but when it comes to database changes it is usually just an ad-hoc system that has evolved over time and everyone is a little bit ashamed of it. The vast majority of companies I’ve seen were not even in the ball park.
I’ve seen some companies that have had home-grown utilities that come close to a satisfactory solution, but in the end they all fell just a little bit short of what’s needed.
Some of you are probably asking, “Doesn’t Visual Studio Team System” do this? Yeah, I think so. Probably, but who knows. Honestly I tried working with it a few times, and it caused me nothing but problems. Sure, I could spend a lot of time mastering all the quirks, but I’m looking for something a little bit more accessible here. The underlying concepts are hard enough; we need an approach that simplifies it, and I just don’t think that VSTS accomplishes that. More importantly, and also along the lines of accessibility, VSTS costs a fortune, and so most developers will never have access to it, so it is no good for the other 95% of developers out there that are stuck with having to use reasonably-priced tools.
The Impedance Mismatch
Why aren’t Database DML and DDL subject to the same level of source-control as the application? Why don’t developers think about databases the same way that they think about source-code?
The most obvious reason is that database changes are fundamentally different in many ways. While source-code is usually just a collection of files that are recompiled, versioned, and released at any given time, databases are much more temperamental. They have existing data, and they have history. Sure, source-code has history, which you can review for reference purposes, but in databases the historical lineage of a table is actually very important. In C#, if you added a field to a class, and then a week later someone else changed the type, and then a month later someone else changed the name, it usually doesn’t really matter too much when or in what order those changes happened, all that matters is the current state of the code and that everything builds together and works in its latest state. However, if you were to do the same thing to a new field in a table, it definitely makes a difference, because there are data implications at every step of the way. This alone scares a lot of developers away from maintaining the database.
To many developers, there is something fundamentally uncontrollable about databases. They don’t fit into the safe model that we’re use to. Managing those changes is definitely introduces new challenge, and many developers just don’t want to be bothered. Another major reason for the difference is just cultural. Developers want the database to work well, and they may even like tinkering around with some stored procedures from time to time, but at the end of the day they like to be able to wash their hands of anything that slightly resembles being a “DBA”.
Developers often see themselves as the general of a utilitarian army of code that they build and train and then order off to carry out their mission, and they usually won’t hesitate to trash it all and replace it if it proves itself unable to complete the mission. DBAs on the other hand are used to dealing with a gentle lion that could easily lose it temper and kill everyone in the room if it’s not treated with kindness and respect. Developers often have the option to wipe the slate clean and start over, and usually want to, especially when they are dealing with someone else’s code. DBAs however are stuck with the original version and they need to keep it alive and make it work until the point that the data can be migrated to a better system, and we all secretly know that is never going to happen.
Silently Killing Software Quality
Let’s take a fictitious example: At some internal IT department, a group of developers is toiling away on a set of dull yet fabulously ‘enterprise-y’ software that no more than five people will ever use. Jimmy checks his code changes into his company’s version-control system of choice, where it is automatically held at the gates until it is code-reviewed by a senior developer, and then it is checked into the team’s current release branch. Meanwhile the continuous-integration build server will download, compile, package, and unit-test the code to make sure that Jimmy hasn’t broken anything, and that nobody else’s changes broke Jimmy. The package code is then migrated through an integration environment, QA environment, UAT environment, and staging environment on its way to production. All the while, as the changes are validated from one environment to another, version numbers are automatically assigned to allow anyone to trace back the exact revision for a given build, and the corresponding code changes slowly work their way towards the code-release Promised Land, the Main Trunk. Those branches can get pretty damned complicated, even when everything is going smoothly, which it never does.
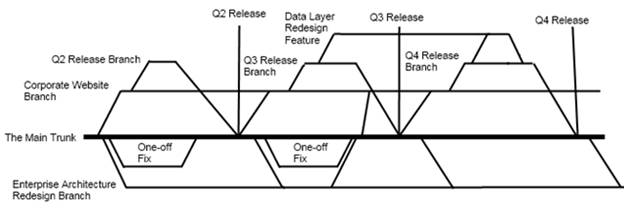
Hopefully this is a process that Jimmy’s company evolved out of mixture of necessity and forethought over the years. The other, less attractive, and far more common scenario is that the company hired an astronaut trapped in a developer’s body, bored with his work and not bound by any sense of urgency, who assured the company that he was going to implement a lot of big complicated processes because that’s just want professional companies do.
In the end, a whole lot of people are paying a whole lot of attention to managing the source code. Hopefully at your company, you are paying attention to this to.
The Catch
Let’s imagine that all database changes need to be checked into an isolated directory in source-control; we’re not savages after all. However, since they don’t really “build” a database from the source files, that directory will be ignored by their continuous-integration server. This in turn breaks the unit tests that are pointing to the integration database server, so Jimmy then needs to run those scripts manually in the integration environment.
In this process, Jimmy sees other database scripts that were checked in recently in the same source-control directory, but he has no way to know which scripts have already been applied to the integration server. For the briefest moment, Jimmy considers applying those scripts as well, just to make sure that the integration server is fully up-to-date, but then he realizes that he can’t be sure which scripts have already been run without manually comparing the schema and scripts to see which have been applied, and this would make Jimmy the de facto owner for any issue that arise because of it. With his own tasks and deadlines to worry about, Jimmy doesn’t have the time or patience for this silliness, so he just deploys his scripts, forgets about the others, and hopes for the best.
This is something that can silently kill software quality. A motivated developer just tried to make things a little better, but the process was so frustratingly inadequate that it was impractical for him to do so. Software companies depend on their developers taking the initiative to improve things, and when they are discouraged from doing so, either by person or by process, the company will slowly slide backwards into mediocrity, and it will drag every developer’s morale with them.
So now when Jimmy makes the changes to the integration server database, that then breaks things for some other developers that have been using that server for their development. Those developers now need to stop and download the latest code changes to get back in sync, cursing Jimmy’s name the whole way.
Anyhow, during the next deployment to QA, someone needs to remember that these specific changes need to get deployed. Since there is no defined strategy for tying database changes to code changes, every time code is deployed there is a little bit of confusion around
- exactly which database changes need to be released
- which changes were already released
- the order the scripts need to be run in.
Jimmy is getting upset.
Another darker possibility is that instead Jimmy needs to submit his changes to the database review board, a collection of detached idealists, college professors without the college, who will criticize every aspect of the scripts in order to justify their existence, but will not really offer any true value because they don’t understand the business problem that needs to be solved, nor do they appreciate the application considerations beyond the database that need to be satisfied.
One of the long term impacts of this is that Jimmy will look for any possible way to accomplish what he is trying to do without making database changes, because it is too much trouble. If he does indeed need to change the database, he’ll try to accomplish it just by changing stored procedures, because changing table schemas are even worse. In the end, he’s definitely not trying to find the appropriate solution to the problem; instead he backed into a situation of finding a “good-enough” solution that will just minimize his hassle, regardless of the downstream impacts.
From now on, he’ll look for any way he can accomplish it by only changing stored procedures and not changing the underlying schema. If he’s lucky (sort of), he’ll find a way that he can just kludge the stored procedures to work around the problem for now, and let it be someone else’s problem to solve later. He has long since given up trying to find the “right” solution, because it is so exhausting the current state of things is so busted up that it’s not even worth trying anymore.
Further complicating the issue, some developers and DBAs make one-off changes in the QA and production environments without going through source-control. Either they need to make an emergency fix in one of the environments and forget to go back and add the scripts to source-control, or worse they just don’t believe that databases should be under source-control at all. I’ve seen this attitude far too often from some DBAs, because they can’t stand the idea of being forced to use a source-control system managed by some other developers, just so that they can make changes to their own database. Pretty soon, every environment is a perverted branch of the one true database, and trying to identify why a test works in one environment and fails in another quickly becomes a nightmare.
The problems of developing on a single Development Database Server
Often, a development team has a single database server in their development environment that they share, and everyone is developing application code locally while simultaneously making changes to a shared database instance. Bad, bad, bad.
Developing Application code Locally
These days, most every application programmer develops their code locally. That’s just what you do. Many developers have learned the hard way that this is important, and won’t tolerate any divergence. And for the less experienced developers who are doing it just because they are told to, eventually they will make the same mistakes and learn from them too. This is such an easy lesson to learn that you don’t see too many people violate it intentionally.
Even if you are obliged to develop on a server environment, you’ll probably at least find a way to isolate yourself. For example, SharePoint developers tend to avoid installing the SharePoint platform on their local machines, mostly because it requires a server OS, but also because SharePoint is pure, unadulterated evil that will steal the very soul of any machine it comes into contact with. Nonetheless, in those cases where a local machine is not practical, the developer will install the SharePoint software onto a virtual machine so that they can still work in isolation.
This local development approach is critically important to any form of version-control or change management. For all practical purposes, developers must have a workable environment that they can fully control and work in peace. From there, developers check their code into source-control, and hopefully it gets built from source-control before being deployed to another server. This gives each developer a degree of control over how much the other developers can screw them up, and more importantly it ensures that every change is traceable back to a date and time and person responsible.
This approach is so ingrained in so many developers, that often we take it for granted. Just try to remind yourself regularly how awful it was that time that everyone was working directly on the same developer server, and nobody can keep track of who changed what when. Or better yet, how fired up everyone got the last time somebody sneaked directly into the production server and started mucking around.
Surprisingly, developers go to such trouble to isolate their local application development environment, and then point their local application code to a shared development database server that the whole team is working on.
If you never need to make database changes, and nobody on your team needs to make database changes, this can certainly work. In that case, the database behaves like a third party service, rather than an actively developed part of the system.
However, if you are ever making database changes, you need to isolate your database for the exact same reasons that you need to isolate your application code.
Isolating your development database
Imagine that you working on a project that involves several layers of DLLs communicating with each other. Because you are in active development, you and your team are constantly making changes that affect the interfaces between those DLLs. The result in is that you continually need to check in your changes in a whole batches; you can’t just check in a few files here and there because you will be breaking the interfaces for anyone else working in that code.
The same rules must apply to the databases as well, for all of the same reasons. At any given point in time, anyone should be able to pull the code that is in source-control, build it, and run it. However, if I’m making a series of changes to my local code and the shared development database, my crazy C# changes are isolated on my local machine, but coworkers are getting my database changes as they happen, so their systems will stop working all of the sudden, and they won’t even know why, or worse yet they will know exactly why and I’ll be the guy “who busted everything up.”
Better yet, after a few days of wasting time on a bad design, I give up on it, and with one or two clicks I can undo all of my code changes and roll back to the main development code stream. However, there is no one-click rollback to the database schema, and so now those changes need to be manually backed out. Hopefully I kept a good list of the changes so I can do this without missing anything, but we all know that a few things will get missed, and now the development database becomes even more of a mutant branch of the true database schema, full of changes that nobody remember or owns, and it is all going to blow up and make us all look like fools when we are rushing to deploy it into QA next month.
This leads to one of the core rules of source code management: If you are manually keeping track of any changes, you are doing it wrong, period.
Distributed Version-control Systems
Distributed Version-control Systems like Git and Mercurial are the fun new fad in version-control, and everyone seems to think that they are so much cooler than more traditional and linear systems like Vault. To me, it seems to grossly overcomplicate an already difficult issue by exacerbating the most problematic concepts, namely branching and merging. But I’m a crusty old conservative who scoffs at anything new, so maybe (and even hopefully) I’m wrong. I was quick to dismiss it as a new toy of bored astronauts, but with DVCS platforms being built by former critics like Joel Spolsky and Eric Sink, I have to figure that I’m probably wrong and will change my mind eventually. But in the meantime there is one idea in DVCS systems that I can already get on board with, and that’s the idea that everyone is working in their own branch. As we’ve discussed, you simply cannot be working in the same sandbox as everyone else, or you will have intractable chaos. You should stay plugged into what everyone else is doing on a regular basis, usually through version-control, but you must also isolate yourself, and you must do so thoroughly.
And here’s the thing (and this may very well be the idea that eventually opens my path to DVCS enlightenment): your local machine is branch. Granted, it is not a very robust branch, because it only has two states (your current state and the latest thing in source-control), but you are still essentially branched until you check in, in which case you will have to merge. It might be a really small merge, because the changes were small or backwards compatible, or because you were not branched off locally for that long, or you are the only one working on a feature, or because you’ve been communicating with the rest of your team, or because you are the only person who actually does any work, but you are merging nonetheless.
What does this have to do with databases? Branching is all about isolation. You must isolate your development environment, and you must so thoroughly. If you think of your machine as simply a branch of the source code, it crystallizes the idea that everything you are doing locally is a full stream of code, and it must contain everything needed to run that code, and must represent all of the changes in that code, including the database. In a broader view, if you were to branch your code to represent a release or a patch or feature, you obviously should be branching your database code at the same time (assuming of course that your database is under version-control). If that is the case, and if the code on your local machine is nothing more than a primitive branch of what is in source-control, then your local machine should also have its own copy of the database.
The joy of Database Scripting.
Database scripting is tiresome, I know. It may make your life a little harder to develop locally, and then write up all of the scripts necessary to push those changes to the dev server, but it is definitely worth it. This is not a theoretical improvement that will hopefully save you time in the distant future, when design patters rule and everybody’s tasks are on index cards hanging on the wall and you’ve achieved 100% code coverage in your unit tests. No, this is a real, tangible, and immediate benefit, because you will save yourself effort when you deploy it to the next stage, namely QA or production. At that point, you’ll already have everything organized and listed out, and you did so when you were still working on the code and everything is still fresh in your mind. I believe that this is a much more maintainable process than everyone just trashing around in a wild-west development database, and then after it all spending days trying figure out which schema differences need to be included to release which features, because the change of getting that right consistently are almost non-existent.
Running with a Local development database.
Hopefully I’ve convinced you that you should have your own copy of the database for your local development. No matter how hard you try, if you have a whole development team working in a single database, you will inevitably run into conflicts. Just recently a client of mine followed this pattern of shared development databases, and our team was constantly breaking each other because the code and database was out of sync, even though we were just a small team of 3 experienced and practical developers sitting together in a single office right next to each other, working together well and communicating all day, but the lack of database isolation made the issues unavoidable.
Of course, you can run a local copy of the database. SQL Server Express Edition is free. Sure, it has some limitations, like the lack of a SQL profiler, but there are great free tools out there like the one from AnjLab. And if you still need a full-featured copy, the developer edition costs less than $50. Can you or your company not spare $50 for something like that that could have save your hours of debugging? Really? How little do you figure your time is really worth?
Or maybe your machine doesn’t have enough memory. It’s true, SQL will eat up memory like nobody’s business and if you have Visual Studio 2008 and Outlook 2007 running, it can be pretty heavy. But I’ve found that as long as you have 3 or 4 GB of RAM, it works pretty well, and doesn’t everyone have that these days? Sure, a lot of you are stuck with crappy old machines that your employer gave you because he considers you to be a high-priced janitor, and he can’t justify in his mind spending a few hundred extra to make help you be more productive, but in that case you have bigger problems than anything we’re going to solve here. I would say, if possible, you should even shell out a few hundred and get some more memory for your machine, even if it’s a work machine and they won’t reimburse you for it. I know plenty of people who would be opposed to this just out of principle, but those people and their principles can go have their own little pity party and see who comes.
However there is certainly one potential problem that can be difficult to overcome. What if your existing database is just too damn big to run locally? One recent client had a production database which was used for a million unrelated purposes, and it was 30GB. Another recent client had the vast majority of their of their business data spread across two databases that were each about 300 GB. Sometimes, the database is just too big to copy down to your local machine.
There are a few ways to deal with the problem. Sometimes the best option is to separate the schema and the data. Strip down the data, get rid of the 300 GB, and get the minimum amount of sample data necessary to run your applications. Maybe clear it out entirely, and have some scripts or automated tests that generate a batch of sample data. Often times this will require a lot of analysis to determine what is necessary, and what all of the data is being used for, but that’s not an entirely bad thing. If you get a good and portable development database out of it, while also getting a better understanding of how the data is being used, then that has a lot of benefits. Granted, this is not easy by any stretch, but it may be do-able. It all depends on your situation.
Another option is to setup a single high-powered development database server, and give each developer their own instance of the database on the server. This approach can have its own problems as well, such as people getting confused about which database instance belongs to who, and having enough disk space to store the inevitable terabytes of data.
The End… ?
And in the end, it is all about productivity. Much like every other aspect of development, your approach should not be dictated by what you enjoy, or your religious language preferences, or office politics, or any of that other junk that just serves as a distraction. In the end, the only really important criteria is whether your approach is going to help you and your team get more done in less time.
So please work to improve your database source-control. Think of the children. At least, the ones that will have to grow up and deal with your legacy crap. And yes, no matter how good of a job you do, they will vilify you anyway.
But in your quest to improve, keep an objective eye on your progress. If you come up with a system that introduces a little bit of overhead but greatly reduces integration issues and deployment-time debugging, great. But however if your process introduces more overhead and doesn’t actually reduce integration issues (and this will be the case most of the time), you have to be grownup enough to admit it and change what you are doing. Experienced developers tend get stuck in a rut of what they are used to doing, and refuse to change because it inevitably implies that they were wrong, and the company and their career suffers from the resulting mediocrity. One of the true tests of a developer’s wisdom is how readily they will objectively admit, to themselves and everyone else, that their grand idea completely sucked and should be thrown out. So to wrap up, here are the key things to remember: keep it scripted, keep it source-controlled, keep it trackable, and keep it local. Draw big fat lines between your environments, and handle promotion of database scripts even more thoroughly than your application code. Ensure that you can recreate any database anywhere, anytime, and use that create separate databases for every single environment, especially local development environments. Be aware of the politics and work around them the best you can, but don’t get pulled into them yourself. Clearly define your ground rules for how developers are going to merge your changes together. Lean heavily on your build server to enforce as much of this as possible, because a process that is enforced manually is a process that will never be followed.
There are a million ways to approach this, some of them good, most of them not, but only you can determine what will fit your organization. So no matter what, keep working at it constantly. Like the rest of your code base and the rest of your development processes, you are either constantly working to improve it, or you are letting it get worse. Start small, take on responsibility yourself, make some minor improvements, lead by example, show people how much easier things can be. Good luck

DevOps, Continuous Delivery & Database Lifecycle Management
Go to the Simple Talk library to find more articles, or visit www.red-gate.com/solutions for more information on the benefits of extending DevOps practices to SQL Server databases.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments